基于窗口自注意力网络的单图像去雨算法
2023-06-01文渊博
高 涛, 文渊博, 陈 婷, 张 静
(1. 长安大学 信息工程学院,西安 710064; 2. 澳大利亚国立大学工程与计算机学院,澳大利亚 堪培拉 2600)
雨天场景下获取到的图像会由于雨痕的存在造成目标遮挡、细节模糊和对比度下降等退化问题[1],严重影响后续的计算机视觉任务,如目标检测[2]和语义分割[3]等.同时,雨图中雨痕的分布往往不尽相同,加之单图像是时空静止的[4],这进一步增加单图像去雨的难度.因此,单图像去雨研究具有极大的现实意义.
目前已有的单图像去雨算法主要分为模型驱动和数据驱动两类[5].在基于模型驱动的算法中,传统的滤波器[6]、字典学习[7]、稀疏编码[8]和高斯混合模型[9]等算法无法适应雨痕的多样性,从而导致去雨后的图像中残留大量雨痕.随着深度学习技术的发展,基于数据驱动的单图像去雨方法相比传统方法表现出更大优势.Fu等[10]将雨图分解为基础层和细节层,利用卷积神经网络 (Convolutional Neural Network, CNN) 去除细节层的雨痕,最后与增强后的基础层相加得到去雨图像.Wei等[11]利用有监督的合成雨图训练网络的同时加入无监督的自然雨图,从而提升网络在自然雨图上的泛化性能.Zhang等[12]基于雨痕的密度信息提出一种多流密集连接网络对雨痕进行去除.Yasarla等[13]利用不确定性引导的多尺度残差网络检测雨痕,再通过循环旋转机制得到去雨图像.Li等[14]将压缩激励机制和空洞卷积引入图像去雨网络,利用雨图的上下文信息去除雨痕.Ren等[15]提出一种循环渐进的单图像去雨基线网络,该网络在减小模型参数的同时能够提高去雨图像的质量.Jiang等[16]将不同分辨率尺度的雨图送入网络进行训练,并提出一种多尺度特征融合策略来得到去雨图像.Zamir等[17]将图像去雨分为多个阶段的子任务,利用编解码器网络学习特征,最后通过专门的恢复网络输出去雨图像.但是,现有的深度学习单图像去雨算法多是基于具有平移不变性和局部敏感性的CNN实现,并未有效利用雨图的全局性信息和像素间的长距离依赖关系,从而导致去雨后的图像损失部分细节和结构信息.
为有效解决上述问题以及充分利用雨图的全局性信息,受自注意力网络Transformer[18]的启发,本文提出一种基于窗口自注意力网络 (Swin Transformer) 的单图像去雨算法.该算法的网络输入层是一个上下文信息聚合块 (Context aGgregating Block, CGB),其采用并行多尺度空洞卷积来融合多个感受野的信息,从而在初始阶段使算法适应雨痕分布的多样性.深度特征提取网络利用CNN学习雨图的局部特征,同时利用Transformer学习全局性特征和像素点间的长距离依赖关系,从而获得更加准确的语义表达.此外,为保证去雨图像更加接近无雨图像和人眼的视觉特点,提出一种同时约束图像边缘和区域相似度的综合损失函数.
1 自注意力网络
Transformer是一种由编码器和解码器组成的深度神经网络,主要由多头自注意力机制 (Multi-head Self-Attention, MSA) 和多层感知机 (Multi-Layer Perceptron, MLP) 组成,其输入与输出都是向量.对于输入向量X0∈RN×D,其中N代表向量的个数,D代表向量的维度.在自然语言处理中,X0是句中单词的词符或字符序列.在计算机视觉中,X0则是图像的像素点序列.Transformer的关键在于自注意力机制强化特征学习,可以表示为
(1)
式中:Q,K,V分别为查询向量、键向量和值向量;dK为K的维度;B为可学习位置编码;SoftMax为激活函数;SA为单头自注意力计算结果.同时Q,K,V满足:
Q=X0PQ,K=X0PK,V=X0PV
(2)
式中:PQ,PK,PV分别为Q,K,V的权重矩阵.Transformer利用MSA将多个自注意力的结果进行拼接,
MSA(Q,K,V)=
Concat(SA1, SA2, …, SAn)W0
(3)
式中:W0为权重矩阵;n为MSA自注意力头的个数;Concat代表按通道维度拼接特征图.之后,引入残差连接并进行标准化,
(4)

(5)
式中:X1为Transformer层的输出.
近年来Transformer在目标检测和图像分类等领域表现出巨大优势[19].相比CNN,Transformer能够有效提取图像全局性信息和建立像素点间长距离依赖关系,从而可利用较小的网络参数媲美甚至超越CNN的表现.但由于单图像去雨问题输入的分辨率往往很高,而经典Transformer中MSA的计算复杂度与分辨率呈平方关系,严重限制其在单图像去雨这类像素级计算机视觉任务中的应用.
2 本文算法
本文提出的基于窗口自注意力网络的单图像去雨算法的主要结构如图1所示.图中:RSTB为残差窗口自注意力网络块 (Residual Swin Transformer Block, RSTB);Conv为卷积层;D1、D2、D5分别表示该卷积层的扩张因子设置为1、2、5;©表示Concat操作;STL为窗口自注意力网络层 (Swin Transformer Layer, STL).该算法的主要流程为:雨图首先通过适应雨痕分布多样性的CGB进入网络,再通过由CNN和Transformer构成的密集残差窗口自注意力网络 (Dense Residual Swin Transformer, DRST) 来提取深度特征, 最后通过一个引入全局残差的卷积层输出去雨图像.

图1 基于窗口自注意力网络的单图像去雨网络结构Fig.1 Single image deraining network based on Swin Transformer
2.1 上下文信息聚合块
文献[20]中表明,卷积适合Transformer的早期视觉处理,同时有助于稳化训练过程和提高性能,因此本文算法利用卷积将雨图映射到高维特征空间从而提取雨图的浅层特征.但是,由于不同雨图中雨痕的分布存在差异,而普通卷积核要扩大感受野来提取更大范围的雨痕分布信息必须通过增大卷积核、增加步长或池化操作来实现.但增大卷积核会增加网络计算量,增加步长和池化操作会损失雨图的分辨率信息.空洞卷积[21]可以在扩大感受野的同时不损失分辨率信息,其感受野大小r可以表示为
(6)
式中:k为卷积核的大小;d为扩张因子.
本文算法在网络输入层设计一种上下文信息聚合模块CGB,该模块利用空洞卷积扩大感受野来提取不同范围的雨痕分布信息.CGB根据文献[22]中采用扩张因子分别为1,2,5的并行空洞卷积,并将得到的雨图特征进行拼接,最后经过一个1×1卷积来融合特征,从而令算法具有适应不同雨痕分布的能力.因此,CGB一方面将输入雨图映射到高维空间,稳化网络训练过程的同时提高去雨效果;另一方面利用不同扩张因子的空洞卷积来自适应雨痕分布信息,提高网络对雨痕的泛化能力.CGB可以表示为
CGB(x)=W1×1(Concat(W3×3, 1(x)+
W3×3, 2(x)+W3×3, 5(x)))
(7)
式中:x为输入雨图;Wk×k, d表示该层卷积核大小为k,扩张因子为d.
2.2 深度特征提取网络
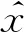

图2 窗口自注意力网络的主要层结构Fig.2 Main layer of Swin Transformer
W-MSA存在的问题是其只在每个分割开的窗口内计算自注意力,不同窗口间未进行信息融合和传递.因此,在W-MSA之后使用移位窗口自注意力 (Shifted Window based on Multi-head Self-Attention, SW-MSA),即将原W-MSA中分割的窗口分别沿直角坐标的两个方向移动半个窗口大小的距离,从而实现相邻窗口间的信息交互.在实际操作中,SW-MSA是将前述窗口移位后得到的大小不一致的分割窗口进行重组,从而保证每个窗口的大小与原W-MSA窗口的大小一致,最后再使用掩膜隔绝不相邻区域来避免特征混淆.SW-MSA对移位窗口的重组示意图如图3所示.
W-MSA的特征图经SW-MSA移位由原来的4个窗口变为9个窗口,且9个窗口的大小不完全一致,不利于后续计算.因此,SW-MSA继续将编号分别为 (6, 4),(8, 2) 和 (7, 9, 3, 1) 的小窗口合并,从而得到新的4个与W-MSA大小一致的窗口,再分别在每个窗口中计算自注意力即可实现不同窗口间信息的交互.因此,STL必须成对存在,可以表示为
(8)
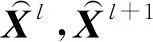
2.2.2密集残差窗口自注意力网络 本文算法在STL末端引入残差卷积来构建DRST的核心模块RSTB.其中,残差连接可以进行雨图高低级特征的融合,确保网络习得特征的准确性和避免梯度弥散问题[24],这符合单图像去雨网络保护分辨率信息的要求.此外,由于Swin Transformer每次移位半个窗口,这严重限制网络中不同窗口间信息的充分交互,在STL末端引入卷积操作可以强化特征学习.同时根据文献[23]可知,将卷积的归纳偏置引入Swin Transformer便于后续不同级别特征的融合.RSTB可以表示为
Xi+1=
Conv(STLm(…STL2(STL1(Xi))))+Xi
(9)
式中:Xi为RSTB的输入;Xi+1为RSTB的输出;m为RSTB中STL的个数.但是由于多个串联的RSTB无法促进特征信息在不同网络层间的流动,因此本文算法在多个串联的RSTB之间间隔地引入密集连接[25]构建密集残差窗口自注意力网络块 (Dense Residual Swin Transformer Block, DRSTB) 来充分融合不同深度的高低级特征,DRSTB中某一阶段的输出可以表示为
Xi=
RSTBi-1(RSTBi-2(Xi-2))+Xi-2+Xi-4+…
(10)
DRSTB的末端引入残差卷积来强化特征学习构成密集残差窗口自注意力网络DRST,从而DRST的末端可以表示为
Xout=Conv(DRSTB(Xin))+Xin
(11)
式中:Xin为DRST中最后一个DRSTB的输入;Xout为DRST的输出.最后通过全局残差卷积输出去雨图像,则本文算法的整体可以表示如下:
y=Conv(DRST(CGB(x)))+x
(12)
式中:y为输出去雨图像.
2.3 损失函数
图像可以分为高频和低频分量,低频分量主要是图像中平滑无突变的区域,高频分量主要是图像中边缘突变的部分,因此图像同时具有边缘性和区域性特点.然而,常用的损失函数如均方误差 (Mean Square Error, MSE) 会模糊去雨图像的边缘细节.本文提出一种同时约束去雨图像y与无雨图像ygt间边缘和区域相似性的综合损失函数,该函数由边缘Edge损失[16]和结构相似性 (Structural SIMilarity, SSIM) 损失[26]两部分组成,其中Edge损失赋予图像边缘的像素点较大权值后再计算MSE,其数学形式为
(13)
式中:Δ(·)为拉普拉斯滤波操作[27];ε=0.001,为维稳常数.
SSIM损失利用图像的区域性特点,分别从亮度、对比度和结构3个角度来综合评价两幅图像的相似程度,其数学形式为
(14)
式中:μy,μygt分别为去雨图像和无雨图像的灰度均值;σy,σygt分别为去雨图像和无雨图像的灰度方差;σyygt为去雨图像和无雨图像的灰度协方差;C1和C2为常数,满足:
C1=(K1L)2,C2=(K2L)2
(15)
根据文献[26]中K1=0.01,K2=0.03;L为图像像素点的灰度范围,一般取值1或255.由于SSIM的值越大表明两图像的相似度越高,所以在训练网络时将最大化SSIM转换为最小化SSIM损失:
LSSIM=1-SSIM(y,ygt)
(16)
进而本文提出的综合损失函数Loss可以表示为
Loss=LEdge+βLSSIM
(17)
式中:根据文献[16]中β的值取0.05.
3 实验结果分析
为验证本文算法的有效性,实验在6个合成雨图数据集和1个自然雨图数据集上进行.合成雨图数据集分别为:文献[10]中提供的Rain14000,其中存在14种不同大小和方向的雨痕,分为 12 600 对训练图像和 1 400 对测试图像;文献[28]中提供的数据集Rain800,其中包括700对训练图像和100对测试图像;文献[29]中提供的两个数据集Rain100H和Rain100L,前者包括5种不同的雨痕,训练图像对和测试图像对分别为 1 800 和100,而后者仅存在一种雨痕,训练图像和测试图像对分别为200和100;文献[12]中提供的Rain1200,其中包括3种雨密度不同的雨痕,分为 12 000 对训练图像和 1 200 对测试图像;文献[9]中提供的Rain12,其中包含12对雨图和无雨图像.自然雨图数据集由文献[30]提供,其中包括300张自然雨图.
3.1 数据集设置
现有的单图像去雨算法大多是在单一数据集上分别进行训练与测试,不利于去雨效果和算法泛化性能的对比.本文依据文献[16]中对6个合成雨图数据集的训练样本和测试样本进行重新划分,进而将训练样本组合成一个统一的融合训练数据集,具体的数据集设置如表1所示.因此,实验使用的训练集包括13 712对雨图像和无雨图像,测试集分为5部分,分别是Test2800[10],Test100[28],Rain100H[29],Rain100L[29]和Test1200[12].

表1 单图像去雨数据集的划分与重命名
3.2 实验环境与训练设置
本文所有的实验均在Windows操作系统下进行,CPU为Intel(R) Xeon(R) Gold 5218,GPU为双NVDIA Quadro RTX 4000,深度学习框架为Pytorch 1.7.上下文信息聚合输入块CGB输入卷积核大小为3×3,空洞率分别为1, 2, 5,特征图的通道数为32.深度特征提取网络DRST包含3个DRSTB和一个残差卷积,每一个DRSTB包括2个RSTB,每个RSTB包括4个STL和一个残差卷积.其中卷积核的大小为3×3,W-MSA和SW-MSA的自注意力窗口大小为8×8,自注意力头的个数为6,中间特征图的通道数为96,激活函数LeakyReLU的泄漏值设为0.2.本文算法的训练次数为200,每次参与训练的图像为16对,大小为64像素×64像素.梯度优化算法AdamW的初始学习率为0.001,在训练过程中当训练次数为90, 130和160时学习率分别降为之前的20%.
3.3 消融实验
3.3.1网络组成 为验证本文算法相比其他网络组成进行单图像去雨的优势,消融实验针对不同网络组成的去雨结果进行分析.主要包括:浅层特征提取模块选用CGB与单卷积;深度特征提取网络部分首先选用骨干网络残差网络 (Residual Network, ResNet)[24]与Swin Transformer;其次选用在成对的STL末端引入残差卷积的RSTB与未引入的STB;之后选用在间隔的RSTB引入密集连接的的DRSTB与未引入的RSTB;最后对比在DRSTB末端是否引入全局残差卷积对最终去雨图像质量的影响.网络组成消融实验的对比结果如表2所示,图像质量评价指标选择峰值信噪比 (Peak Signal of Noise Ratio, PSNR)[31]和SSIM,其值越大表明去雨图像质量越高.
由表2可知,在同一训练条件下,骨干网络Swin Transformer相比ResNet在PSNR和SSIM上分别提升1.94 dB和4.26%,这表明Swin Transformer相比ResNet能更好地去除雨痕.当在STB和DRSTB末端引入残差卷积后,网络的去雨图质量在PSNR上分别提升1.59 dB和1.88 dB,这证明本文利用Swin Transformer和CNN结合学习雨图全局性特征和局部特征相比Swin Transformer单独使用更加具有优势.本文算法在深度特征提取网络中引入密集连接,实验表明密集连接使网络去雨图像质量在PSNR和SSIM上分别提升1.33 dB和2.03%.在网络输入层,实验表明CGB相比单卷积能使网络产生更好的表现,具体在PSNR上提升2.68 dB,在SSIM上提升1.32%.因此,实验证明本文算法网络结构的设计是合理的.
3.3.2损失函数 为验证所提综合损失函数的有效性,实验将本文的单图像去雨网络分别由MSE损失、Edge损失[16]、SSIM损失[26]、MSE损失与SSIM的组合 (MSE, SSIM)以及Edge损失与SSIM的组合 (Edge, SSIM) 训练得到的去雨图像质量进行对比.损失函数消融实验的对比结果如表3所示.

表3 测试数据集Test1200[12]上的损失函数消融实验对比结果
实验表明,由Edge和SSIM综合损失训练的网络性能与单独使用MSE, Edge和SSIM相比,在PSNR指标上分别上升5.26,5.59,4.15 dB,在SSIM指标上分别上升4.52%,3.70%,2.33%.同时比现有算法常用的MSE与SSIM综合损失在PSNR和SSIM指标上分别提升2.04 dB和0.87%.因此,本文提出的综合损失函数能够很好地保持图像细节和结构信息,相比其他常用损失函数具有更好的表现.
3.4 算法性能对比
3.4.1合成雨图 为验证本文算法在合成雨图去雨上的优势,实验将DerainNet[10],SEMI[11],DIDMDN[12],UMRL[13],RESCAN[14],PReNet[15],MSPFN[16],MPRNet[17]与本文算法的去雨性能进行比较.不同算法在合成雨图上的定量对比结果如表4所示.表中:在各测试数据集上指标最高的数据加粗表示;排名第2的数据加下划线表示;G为本文算法与其他算法相比所得去雨图像在当前指标上提升的比例.
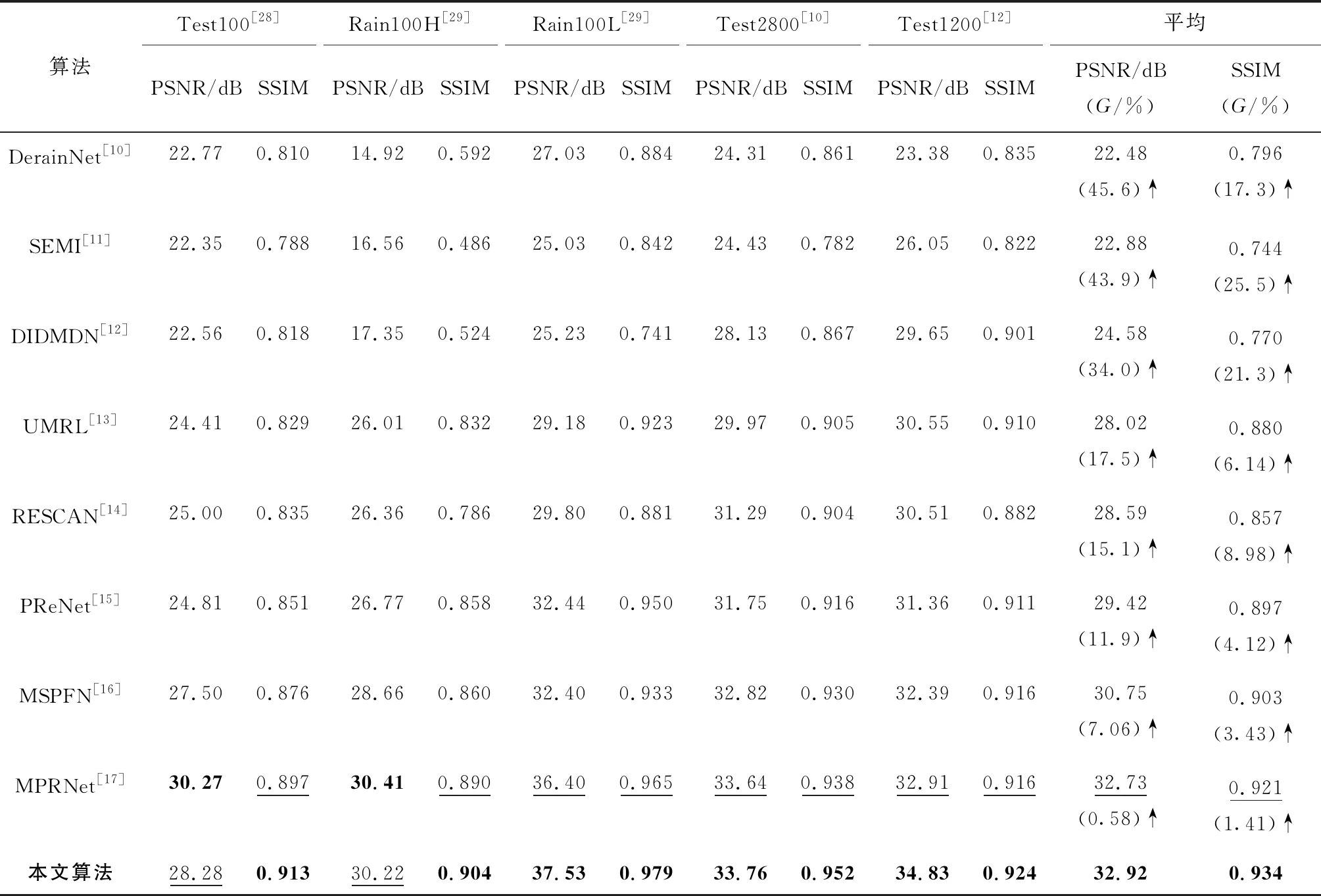
表4 不同算法在合成雨图测试数据集[28-29, 10, 12]上的定量对比结果Tab.4 Comparative results of different methods on synthetic datasets[28-29, 10, 12]
实验表明,本文算法相比其他8个算法在测试数据集Test100[28],Rain100H[29],Rain100L[29],Test2800[10]和Test1200[12]上的平均PSNR和SSIM分别提高0.19~10.44 dB,1.41%~25.5%.具体而言,本文算法在5个测试数据集上的PSNR均获得提升或接近最好,尤其是SSIM均获得明显提升,分别为1.71%~12.7%,1.57%~52.7%,1.45%~10.7%,1.49%~10.6%和0.87%~12.4%.同时,本文算法的合成雨图去雨效果与RESCAN[14],PReNet[15],MSPFN[16]和MPRNet[17]算法的视觉对比结果如图4所示.从图中可以发现,本文算法在雨痕分布密集的第2幅和分布稀疏的第3幅雨图上都有良好的表现,而其他算法如PReNet[15]无法有效适应分布不同的雨痕.进一步发现,本文算法在第7幅雨图上准确区分雨痕和背景信息,相比其他算法更加彻底地去除雨痕.另外,其他算法在第2幅雨图上使马腿产生不同程度的虚化,而本文算法可以很好地保持图像细节信息,从而令去雨图像更加接近无雨图像.因此,本文算法相比其他算法能彻底去除分布不同的雨痕,得到的去雨图像细节更加丰富.

图4 其他算法[14-17]与本文算法在合成雨图[10,12,27-28]上的视觉对比结果Fig.4 Visual comparative results of other methods[14-17] and proposed method on synthetic rainy images[10,12,27-28]
3.4.2自然雨图 为进一步验证算法在自然雨图去雨效果中的泛化性能,实验将RESCAN[14],PReNet[15],MSPFN[16],MPRNet[17]和本文算法的去雨表现进行对比.去雨图质量评价指标采用自然度图像质量评估器(Naturalness Image Quality Evaluator, NIQE)[32]和空间-光谱熵质量 (Spatial-Spectral Entropy-based Quality, SSEQ)[33],其值越小表明去雨图像的质量越高.不同算法在自然雨图上的定量分析对比结果如表5所示.

表5 不同算法在自然雨图数据集[30]上的定量对比结果
实验表明,相比RESCAN[14],PReNet[15],MSPFN[16]和MPRNet[17]算法,本文算法去除自然雨图雨痕的效果在NIQE和SSEQ指标上均达到最小,分别为4.946和18.93.不同算法的自然去雨图像的视觉对比如图5所示.从图中可以发现,相比其他算法,本文算法在雨痕分布稀疏的第1, 5, 6, 7幅自然雨图上和雨痕分布密集的第2, 3, 4, 8幅自然雨图上得到的去雨图像分别在雨痕去除效果和细节保持两方面都表现最佳.因此,本文算法在自然雨图上具有更好的泛化性能.
3.4.3算法效率 为进一步验证本文算法的效率,实验将目前单图像去雨表现优秀的MSPFN[16],MPRNet[17]和本文算法的参数量、浮点运算次数与前向传播平均耗时进行对比,输入选用100张大小均为64像素×64像素的雨图.不同算法处理雨图的效率对比结果如表6所示.

表6 不同算法处理图像的效率对比结果
由表6可知,本文算法的参数量为2.381×106,相比MSPFN[16]下降84.95%,相比MPRNet[17]下降34.53%.浮点运算次数略高于MPRNet[17],但前向传播平均耗时减少31.25%. 因此本文算法的效率优于其他两种算法.
4 结语
针对现有的单图像去雨算法未有效利用雨图的全局性信息,进而导致去雨图像损失部分细节和结构信息的问题,提出一种基于Swin Transformer的单图像去雨算法.首先,该算法利用并行多尺度空洞卷积作为输入层来适应不同雨痕的分布多样性.其次,将Swin Transformer引入单图像去雨研究,并结合卷积神经网络来提取局部信息和全局性信息,进而强化特征学习.此外,在深度特征提取网络中引入密集连接和全局残差卷积,从而实现不同抽象级特征的充分融合与信息交流.最后,提出一种新的综合损失函数,其可以同时约束去雨图像与无雨图像间的边缘和区域相似性,从而进一步提高去雨图像的质量.在未来研究中,本文作者将继续深入研究雨图局部信息与全局性信息的特点,从而进一步设计出更高效的单图像去雨网络.
