应用堆叠融合模型和点云数据的树种分类1)
2023-05-31杨致贤樊仲谋杨森叶芊吴翠沟
杨致贤 樊仲谋 杨森 叶芊 吴翠沟
(福建农林大学,福州,350002)
城市森林资源对维持城市生态环境平衡具有不可替代的作用,对城市森林进行监测管理是推行可持续发展观的重要工作环节[1-2]。树种分类识别,是森林资源经营管理、生物多样性监测评价的重要工作基础。传统意义上的人工调查树种分类识别,工作效率低、调查周期长[3],难以满足森林资源管理的技术要求。而激光点云数据,能够在较大尺度提供综合性强的树木信息参数,如树木相对聚类特征、结构特征、纹理特征等,因此应用激光雷达(LiDAR)点云数据的树种分类是当前树种分类研究的热门[4]。
近年来,支持向量机(SVM)[5]、随机森林(RF)[6]、条件推断森林(CF)模型[7]、卷积神经网络(CNN)[8]等机器学习算法,被广泛应用于激光雷达数据树种分类研究。用于分类的特征参数,涵盖了纹理特征、点云结构信息[9]、冠形结构参数、单木特征、颜色特征等。从已有研究结果看,冠形结构特征和点云结构特征,多依赖于地基三维激光扫描仪,其工作效率较低。在最优特征参数的研究方面,已有研究认为,选择高质量的分类指标比增加分类指标数量更为重要[10]。在机载激光雷达树种识别的研究方面,机器学习的分类准确度,优于传统的监督分类和无监督分类[11];但由于研究对象和分类系统等原因,且单一算法会对部分指标产生偏好,导致同一种算法对于不同树种的分类效果,在精确度方面的表现存在明显的差异性[12],目前尚不能提出一个能适应各种环境及树种的最优分类器。随着各种分类器在树种识别中应用的普及,针对结构复杂、郁闭度高的复杂森林环境,开始尝试将两种或多种分类模型进行组合,使用组合分类器进行树种分类研究,如将K最近邻模型(K-NN)、支持向量机、分析回归树(CART)、随机森林等模型融合,建立面向对象的组合分类器,对树种识别结果进行验证,总体精度和卡帕(Kappa)系数均优于单一模型算法[13]。
为此,本研究选择堆叠(Stacking)融合模型作为分类器,对福州市三江口生态公园激光雷达点云数据进行重采样、去噪、渐进三角网滤波等预处理;应用分水岭算法进行单木分割,对单木分割操作后的树木点云提取地径、树高、枝下高、冠幅面积、冠高、胸径和95%百分位高度7种树木特征参数;使用堆叠融合模型应用激光雷达数据参数因子进行树种分类,分类结果与常用的支持向量机、随机森林、K最近邻模型3种模型分类结果进行对比,分析堆叠融合模型应用点云数据进行树种分类的准确度、卡帕系数、精确率、召回率等;旨在为优化单一分类器的树种分类精度提供参考。
1 研究方法
研究区域为福州市三江口生态公园,位于福州市闽江北巷西南岸沿岸(地理中心坐标26°1′N、119°38′E),绿地面积达126.2 hm2。园区内树木种类繁多,有丰富的优势树种,包括水杉(Metasequoiaglyptostroboides)、小叶榕(Ficusconcinna)、大叶榕(Ficusstipulosa)、朴树(Celtissinensis)、南洋杉(Araucariacunninghamii)以及其他名贵树种,具有较高的研究价值。
1.1 激光雷达点云数据获取
试验数据获取由科卫泰的六旋翼无人机KWT-X6L-15搭载RIEGL VUX-1UAV三维激光扫描仪,于2021年6月份采集完成。为验证点云数据提取参数满足试验要求,本研究随机选取10%试验树木,获取地径地面数据,用于点云数据树木参数提取的验证。地径真实值获取,选择树干距地面0.1 m处,使用围尺测量。
无人机主要参数:空心质量(10.0±0.2)kg、标准起飞质量(21.0±0.2)kg、极限悬停载荷18 kg、最大抗风能力18 m/s、最大爬升速度5 m/s、最大下降速度2 m/s、相对飞行高度3 000 m、工作环境温度-30~55 ℃、图传距离20 km、地面站控制距离、20 km。
三维激光扫描仪主要参数:扫描视场角0~330°、角度分辨率0.001°、发射频率550 kHz、工作温度范围0~40°、输入电压11~32 V、功率50 W。
根据三江口生态公园野外树木调查,选取园区内8种树木作为研究对象,激光雷达数据的试验树种:水杉(Metasequoiaglyptostroboides)57株、小叶榕(Ficusconcinna)58株、大叶榕(Ficusstipulosa)58株、朴树(Celtissinensis)56株、洋紫荆(Bauhiniablakeana)58株、南洋杉(Araucariacunninghamii)53株、桂花树(Oleafragrans)59株、大腹木棉(Ceibaspeciosa)45株,总共样本数444株。
1.2 激光雷达点云原始数据预处理
由于机载激光雷达飞行环境的不确定性、实验仪器的精度等因素,获取的点云数据量大且复杂,需要对原始数据进行预处理,提高后续点云数据处理效率;数据预处理操作使用LiDAR360激光雷达点云数据处理分析软件完成。
①重采样。点云数据冗余会增加树木参数提取的难度,为了提高数据处理效率,使用LiDAR360激光雷达点云数据处理分析软件对原始数据进行重采样处理,减少冗余点云。与四叉树法相比,八叉树[14]遍历点云数据效率更高、速度更快,且便于点云数据管理,因此本研究选用八叉树法进行重采样。
②去噪。由于试验数据获取仪器的精度以及森林公园的环境复杂性,获取的点云数据会产生不可避免的噪声,影响树木信息提取。因此,先需要对点云数据进行降噪。本研究使用依据空间分布算法去噪,每个点与K相邻点的平均距离在设定阈值以外,则当作噪点去除。为了提高数据准确性,需要通过目视手动去除部分噪声。
③渐进加密三角网滤波。数字表面模型、数字高程模型、冠层高度模型的生成,要求地面点与非地面点的分离尽可能准确。通常原始数据中地面点占比约60%,如果不能准确分离地面点与非地面点,会导致树簇分割错误。为提高分割效率和准确性,本研究使用渐进加密三角网滤波方法去除地面点。
④生成冠层高度模型。原始数据需要分离地面点、提取树木点。以数字表面模型(DSM)减去数字高程模型(DEM),可得冠层高度模型(CHM,见图1)。完成地面点分离,使用反距离加权插值方法[15]分别对地面点和非地面点插值后,生成数字高程模型、数字表面模型。选择合适的插值网格分辨率,降低后续利用目标检测算法检测树顶点的漏检率,减少树冠边缘信息缺失。本研究设置,图像网格分辨率为1.5 m、插值半径为2.5 m、权重为1.5、最少插值点数为25个。
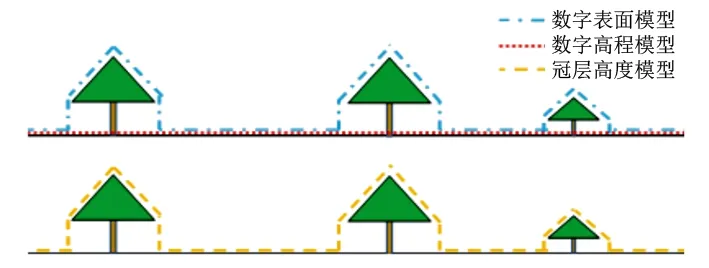
图1 冠层高度模型示意图
⑤单木分割。点云数据单木分割是树木参数提取的必要工作。机载激光雷达获取的树木点云数据进行单木分割,通常有两种方法,一种是直接依据点云通过聚类等方法进行分割,另一种是依据冠层高度模型进行分割,如局部极值法、多尺度分割法、分水岭算法[16]。本研究对比了两类分割方法,其中依据点云聚类分割法正确分割率为77.5%,而依据分水岭算法分割准确度为79.1%,略优于前者。因此,本研究选择依据分水岭算法对点云数据进行单木分割。该方法将监测的局部最小值设为固定值进行分水岭转换,剔除非树冠点。点云冠层高度模型中的树冠边缘梯度值相对较大,树冠顶部梯度值相对较小。使用形态学梯度公式改善树木边缘,实现闭合边缘图形。
g(f)=(f⊕b)-(f⊗b);式中的f为输入的冠层高度模型图像、⊕为形态学“膨胀”运算、⊗为形态学“腐蚀”运算、b为结构元素。
边缘检测生成的树冠边缘闭合图形可以构建分割树冠的范围,使用形态学开闭运算重构冠层高度模型形态学梯度[17],去除噪声点,对区域内的极大值与极小值进行校正。为避免过分分割,需要对冠层高度模型的形态学进行开闭运算,重构冠层高度模型形态学梯度。公式:f*b=ørec(f*b,f)、f·b=Ψrec(f·b,f);式中的*为形态学中的开运算、·为形态学中的闭运算、f为输入的栅格图像、b为结构元素、ørec为膨胀后重构图像、Ψrec为腐蚀后重构图像。
提取冠层高度模型标记。从研究区域的局部极小值点开始,对所有极小值小于或等于d的集水盆都被分配唯一标识记录,设当前值为d+1,若d+1的邻域已经有标记的像元点,则将d+1与此标记点划分为一类标记;若其邻域内没有一个像元被标记,则将记为一个新标记点,重定一个新的集水盆。重复该步骤,直至研究区的每一个像元都被标注,完成分水岭变换。通过分水岭变换,得到围绕树顶点周围的封闭的、连贯的树冠轮廓。单木分割得到的典型树种点云对比见图2。

图2 典型树种点云对比图
1.3 树木特征参数提取
(1)树高提取。本研究用狄洛尼(地形拟合方法[18])生成不规则三角网(TIN),将数字表面模型获取的树顶点坐标对应至不规则三角网中提取的地面点高程,树顶点与地面点高程值之差为树高。
ZG=z1-[(xi-x1)(y21z31-y31z21)+(yi-y1)(z21x31-
z31x21)]/(x21y31-x31y21);
H=zi-ZG。
式中:(xi,yi,zi)为树顶点坐标;ZG为树顶点对应的地面点高程;xj1、yj1、zj1,分别为xj-x1、yj-y1、zj-z1,j=2、3;H为树木高度。
(2)冠幅提取。Edelsbrunne et al.[19-20]提出散点轮廓(Alpha Shape)算法用作点云的边界划分,即有一点云集P,存在一个半径为α的圆点云集P内的任意两点,且点云集P内其他点不在该圆域内,则圆上两点的连线即为点云轮廓的一条边(见图3);以参数α为半径的圆,遍历点云边界后,该圆运动的轨迹即为点云集的轮廓。①将树木点云投影到X-Y平面,在平面上的点云表示树冠形状,首先将点云的Z坐标值设置为0;②调整α参数,使得树木边界形成闭合图形,且能够表现树冠结构特征;③计算树木边界点云集M至树干的距离,求其平均值即为树木的冠幅。
di=[(xi-x0)2+(yi-y0)2]1/2;
式中:xi、yi为点云集M的任意一点,x0、y0为树木基点坐标,Dc为树木冠幅,n为点云集M的数量。
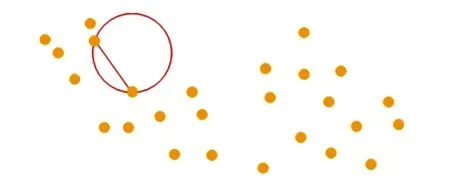
图3 散点轮廓提取示意图
(3)冠幅面积和冠长提取。冠幅面积是指树木树冠垂直投影到地面上的平面面积。本研究中,树木冠幅面积的提取,采用易康(eCongition)软件与目视解译相结合的方法进行。提取冠幅面积主要包括2个步骤:①使用易康软件,依据多尺度算法进行树冠的初始自动分割;②将切割结果图导入地理信息系统软件(ArcGIS)中,使用目视解译法将未处理好的部分进行手工去除,获得最佳的提取效果。
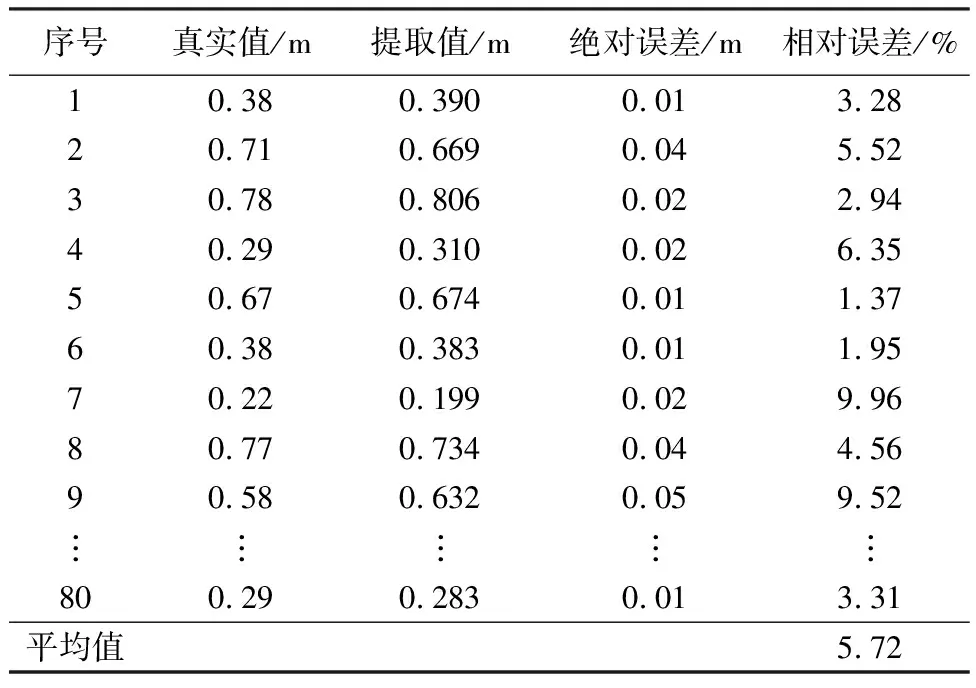
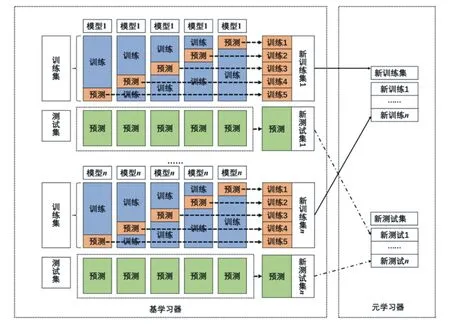
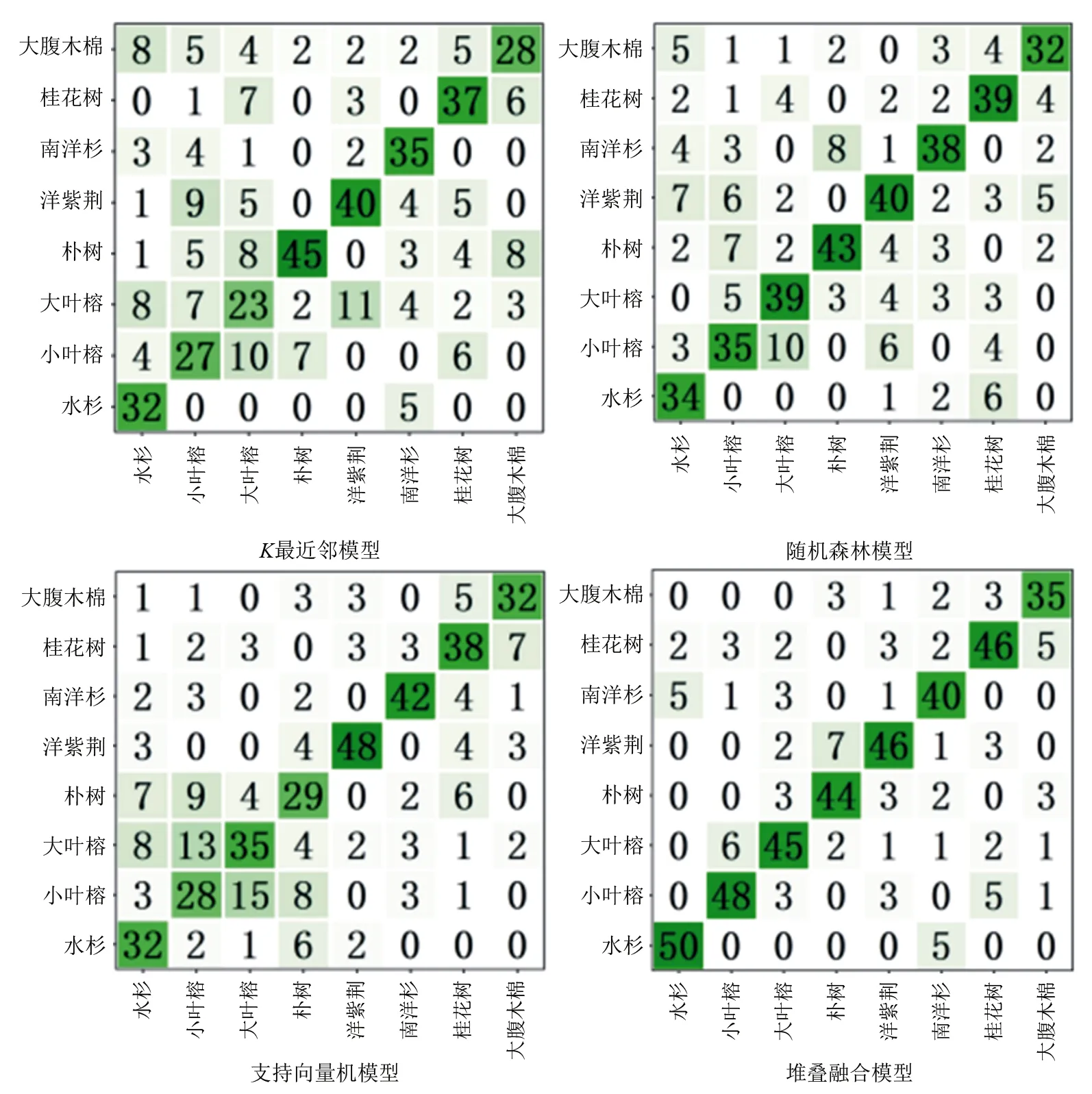
(4)枝下高与地径面积提取。枝下高获取方法——①从树干底部开始,将树木的点云分为n层,层高设定为h(本研究选择5 cm),逐层以该层内点云为对象进行地径(Dg)拟合,依次存储为Dg,1、Dg,2、…、Dg,n。②依次计算第n层与第n-1层之间的直径比,根据以下条件选择合适阈值(K),最终判断树干高度,即:若(Dg,n/Dg,n-1) 根据地径面积的计算,参照地径数据,采用圆面积公式计算并记录。 (5)地径提取。从点云块中采集的树木点云,依次获取树木的地径提取值。基本原理:①1.5 m以下的树木点云属于树干,但由于实际情况,树木生长很少与地面垂直,如果直接将树干点云投影到地面并拟合,提取地径,则会导致获取的地径值大于真实值;森林资源调查,地径通常选测树木0.1~0.2 m高度处测量[21];本研究依次选取每棵树木高程在0.1~0.2 m的点云,并对其进行二维平面投影。②树干点云高差值较小时,点云投影可近似为圆,因此,按照投影结果依次对每棵树的树干点云采用最小二乘拟合,并将拟合的结果提取每棵树木的地径大小,记为Dg,i(i=1、2、3、…、n),n为树木的棵数。 图4 枝下高提取示意图 (6)95%百分位高度提取。对点云数据进行高程归一化,单木点云按高度值从最低到最高进行排序,然后提取总高度95%处的高度值。 (7)胸径提取。胸径通常指的是树干距离地面1.3 m处的直径值。本研究采用分片裁剪的方法,在矩阵实验室(MATLAB)中提取胸径。首先对提取的单木树干点云进行切片分层,并投影到水平面,使用随机抽样一致性(RANSAC)[22]算法拟合成圆;然后将圆心逐一连接,对连接线进行平滑处理,用平滑后的圆心重新拟合一个圆,计算出其直径即得胸径值。 本研究以地径参数值误差分析为例,随机选取10%试验树木进行地面数据获取,测得地径真实值,检验点云数据提取的参数是否符合试验要求。通过地面样本数据对比,试验树木地径参数提取平均误差为5.27%(见表1),满足试验要求。 表1 提取激光雷达数据树木地径的参数值误差 本研究使用堆叠融合模型对提取的树木几何参数进行分类。集成学习是将多种机器学习模型融合在一起,融合模型的算法包括引导聚集算法(Bagging)、提升算法(Boosting)、混合算法(Blending)、堆叠算法(Stacking)[23]等。堆叠算法是异质融合,将两个或多个不同的弱分类器结合起来,生成一个性能优于其组成的分类器的模型。堆叠融合模型过程见图5。 图5 堆叠融合模型示意图 本研究选用5折交叉法[24]验证得到的分类结果,其中4折用于训练,1折用于验证。同时在矩阵实验室中分别使用支持向量机、K最近邻模型、随机森林进行分类,与堆叠融合模型分类效果进行对比分析。取80%的试验树木作为样本进行分类器训练、20%的树木数据作为验证样本,得到树种分类结果后,选择检验样本对结果进行精度评价,与堆叠融合模型分类结果对比。 以激光雷达点云数据多参数因子,选取树高、地径、枝下高、冠幅面积、冠高、胸径、95%百分位高度7个单木特征参数组成影响因素因子集,以研究区树种作为评价指标,用测试集测试训练好的分类模型实现精度验证分析分类结果,获得混淆矩阵、准确度、卡帕系数、精确率、召回率评价指标,评价堆叠融合模型、支持向量机模型、K最近邻模型、随机森林模型树种分类的准确度和可靠性(见图6、表2)。 由表2可见:堆叠融合模型分类结果中,水杉与南洋杉容易发生误分,朴树和洋紫荆容易发生误分。其中,水杉对南洋杉的误分率8.7%,即8.7%水杉误分为南洋杉,南洋杉对水杉的误分率为9.6%;朴树对洋紫荆误分率为12.5%,洋紫荆对朴树误分率为5.2%。 表2 不同模型对激光雷达点云多参数因子树种分类结果 横坐标轴为测试集的真实类,纵坐标轴为测试样品的预测类。主对角线数据为真实类与预测类一致,其数值为分类准确的树木数量。主对角线外则为分类错误,其数值为分类错误数量。 本研究使用无人机载激光雷达获取树木点云数据作为数据源,提取树高、枝下高、冠高、冠幅、地径、胸径、95%百分位高度,使用Stacking融合模型对树种进行分类得到分类精度,并使用K最近邻模型、随机森林模型、支持向量机模型3种常用模型进行树种分类,与Stacking融合模型分类结果进行对比,结果表明:①堆叠融合模型树种分类的效果,整体优于K最近邻模型、随机森林模型、支持向量机模型3种常用模型,其分类精度可达79.72%,K最近邻模型分类效果最差(分类准确度只有60.14%)。②堆叠融合模型对水杉、小叶榕、朴树、南洋杉的识别效果更好,对水杉分类精确率达到90.91%,对小叶榕、朴树、南洋杉的分类精确率也能达到80%。③不同树种分类模型对同一种类树木的分类精度,存在明显差异;在本研究所选试验树种中,堆叠融合模型适用性更高。 由于研究区内各树种数量较少,导致本研究所选样本量偏少。堆叠融合模型分层训练过程需要大量训练样本支持,若进一步提高分类效果,满足更复杂的森林树种识别需求,需要增加训练样本量。
1.4 树木特征参数提取值误差检验
2 结果与分析
3 结论
