基于云计算的汉字文化数字化平台建设研究
2023-05-30焦东杰
焦东杰
关键词:云计算;汉字文化;数字化平台
汉字数字化技术涉及研究领域十分广泛,其所包含内容丰富,不仅有汉字本身的数字化信息,还可对汉字文化进行内涵式外延,充分挖掘汉字背后所隐藏的知识;而借助现代信息技术对其进行存储、处理与分析之后再予以呈现,则可让人们对我国的汉字有更深入的了解,激发他们对汉字中所蕴含的传统文化的探究兴趣[1]。因此,本文主要基于云计算、大数据技术,探究汉字文化数字化平台的设计思路以及系统架构。
1基于云计算的汉字文化数字化平台的整体设计思路
汉字文化数字化信息量庞大并仍呈现增长趋势,同时数据格式还非常多元化,属于异构数据类型。比如,对汉字进行释义、历史演义的是文本数据,读汉字的是音频数据,书写汉字这一过程又需要视频数据。这些数据可与用户的行为数据联系起来,借助数据分析技术了解其隐藏的某些规律和内容,继而令数据有了更高的应用价值,引发人们对汉字文化产生更浓厚的兴趣。从本质上来看,汉字文化数字化与大数据所具备的海量、快速、多样以及价值性特征都有着相同之处,所以基于云计算和大数据的设计思路来构建汉字文化数字化平台,理应成为不二之选[2]。在构建该平台时,平台体验系统应由多个不同子系统组成,其中包括汉字演示系统、构字法系统、书写系统等。每个子系统的前端应以Web网页的形式实现,通过人机交互原则和可视化的虚拟现实技术,用户可在浏览器上对所输入汉字产生的文化要素进行人机交互体验。通常而言,子系统要访问的数据大致可分为描述性文本数据、图文数据、音频数据、视频数据等。另外,体验系统在数据管理及分析上还需借助云服务平台,以保障各种基础服务,系统研发人员在设计云服务平台时,应着重考虑平台的高可用性、高拓展性、高伸缩性、高安全性等问题。
2基于云计算的汉字文化数字化平台的构建方案
汉字文化数字化平台应基于云计算构建3层架构模式,分别为IaaS(基础设施即服务)、PaaS(平台即服务)和SaaS(软件即服务)。
2.1平台基础设施层设计
基础设施层可为汉字文化数字化平台提供硬件条件,平台系统可使用IBMLexSystem作为主机,应用VMware虚拟技术,建立虚拟计算机资源池、数据存储池、网络资源池,方便用户对资源进行利用和管理。通过构建虚拟计算机集群,实现可随时灵活使用系统资源的目的。
2.2平台服务层设计
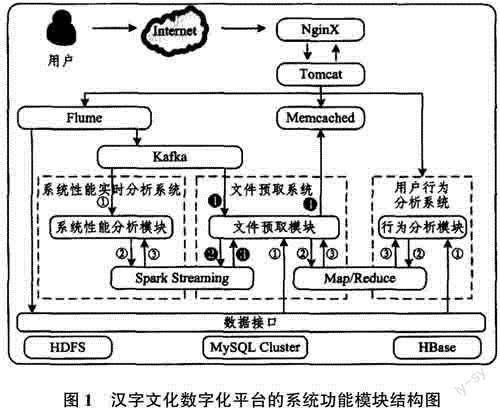
服务层可为汉字文化数字化平台提供数据管理服务以及各种类型计算机服务,促使用户更好地体验系统软件的运行环境。具体各个服务模块之间的关系如图1所示.
2.2.1运行环境
平台体验性利用Java开发的B/S结构Web软件实现,所以在服务层部署应用服务设备,继而给用户体验系统提供运行环境。鉴于Tomcat配置不高,在处理静态文件时效果不好,因此利用动静分离技术部署NginX作为Web服务器应用,以更强的静态文件处理能力处理HTML,JPG格式数据:将Tomcat作为Servlet容器,以处理JSP,servle等动态文件。假如一个Tomcat服务器达到使用上限,还可水平拓展,即重新布置一个新的Tomcat服务器,并借助NginXde的自动负载能力来均衡调节Tomcat的计算资源。
2.2.2数据管理
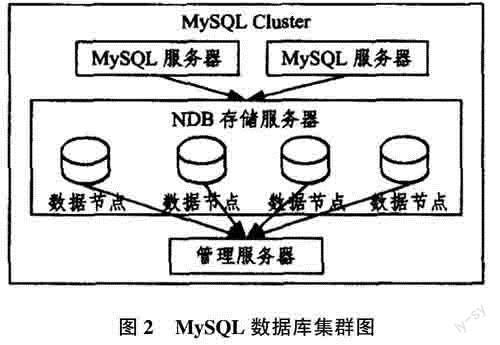
服务层不仅可提供系统运行环境,还可为用户提供数据存储、管理等基础性服务。汉字文化数字化信息一般可分为结构化数据与非结构化数据2种,其中结构化数据以汉字的描述性信息为主,如汉字的历史发展背景、汉字释义,这类数据被保存在关系型数据库,而MySQL则用于管理结构化数据。鉴于对数据高可用性、可扩展性的需求,则利用了MySQL Cluster数据库集群技术管理关系型数据库。具体如图2所示。
MySQL Cluste作为一种分布式存储技术,在存储关系型数据上有着更大的优势:将数据置于NDB存储服务器节点上,通过MySQL Cluste的无共享模式,将分布于不同节点的数据形成一个内存数据库,并利用其中一个管理节点对所有数据节点予以管理。当某个数据节点面临崩溃时,数据就会自动通过其他节点进行复制,再次恢复该节点的高可用性。综合当前数据量以及潜在访问量,通过MySQL Cluste部署2个MySQL Serve节点与4个NDB存储节点。
汉字文化数字化信息中包括大量的非结构化数据,如图片、音频、视频等,相较于关系型数据库,这一类文件更适合存储在文件系统中。通过对比几种不同的分布式文件系统,选择Hadoop框架中HDFS文件系统,不仅是因其所具备的高可用性及可扩展性,还有接下来对大数据分析的需求性要求,它与Hadoop,MapReduce编程模型有着极好的兼容性。但是,汉字文化数字化系统中有大量小型文件数据,如一张图片仅有6 MB内存,Hadoop HDFS则更适用于大于64 MB内存的文件,这会在一定程度消耗其系统内存资源,降低文件访问速度。针对此问题,本文提出图1所示的文件预取系统,提前将有关数据进行读取缓存,以扩大文件访问击中率,降低HDFS小型文件的访问压力。
2.2.3缓存策略
在服务层中部署Mem cached缓存服务器,其缓存策略则是基于访问时间进行的LRU算法。因此,应用程序在访问数据时则会先行访问Mem cached服务器来查找所需数据。由于Mem cached在内存中缓存数据及对象,所以数据访问速度较快。
2.2.4日志管理
在汉字文化数字化系统中包括用户行为日志及系统资源日志,分析这些数据可促进系统资源及性能的优化,并实现个性化汉字文化体验的推荐功能。为收集用户行为数据,可利用Apache Flume系统,其扩展性更好,并可将数据发送到HBase数据库保存,同时推给Apache Kafka予以数据分析,此时不同模块的數据需求会存在交集,通过消息订阅模式可在多个模块中同步利用同一数据。
2.2.5数据分析系统
数据分析在汉字文化数字化平台主要用于开展系统资源监管、用户行为分析以及文化预取策略计算[3-5]。云服务平台可提供实时、非实时、半实时数据分析,并分别对应进行系统资源监管、面向用户开展行为分析以及文件预取,以上模块内部流程可参考图1。
(1)系统运维人员可利用实时分析技术发现系统问题并采取应对措施,继而不断优化系统。SparkStreaming有着高可用性与拓展性,能把所接收的实时数据离散为RDD数据块,再对同段时间的数据予以计算处理,而因为这一计算过程是在内存中进行的,所以Spark Streaming的计算速度可实现以秒为单位。
(2)用户行为分析则是对大量历史数据展开分析,并无较高的实时性要求,所以更为侧重分析模块的数据吞吐能力,选择Hadoop MapReduce作为分析算法的编程模型,用户行为分析系统可将用户真正感兴趣的汉字文化进行优先推荐。
(3)文件预取分析系统是通过预取分析模块来计算预取策略,从而获悉所需提前预取的文件。这一流程被分为非实时数据分析、实时数据分析2部分,而且它们是相对独立运行的。首先,针对存入HBase的日志数据采取关联分析算法开展分析,寻找被访问文件的关联性;其次,借助流技術开展实日寸统计,获得文件近期的访问频次;最后,根据文件访问关联性、访问频次进行加权,由此计算出最有可能被用户访问的文件。
2.2.6系统资源管理
通过服务层实现由一个系统资源管理模块来监测汉字文化数字化平台的资源利用与数据管理工作。首先,对系统资源利用情况的检测,应用ClouderaCDH开源平台管理Hadoop系统,在图形界面上嵌入Cloudera Manager的GUI作为大数据的可视化监控界面,除可对CPU利用率、网络I/O、磁盘I/O等系统资源的应用情况进行监测,还可对Hadoop的组件、虚拟机予以可视化管理。其次,MySQL Cluster集群监管是在系统管理模块的GUI界面中嵌入phpMyAdmin作为MySQL Cluster的管理界面,以此监控MySQL服务器的运行情况,并对其所存储的数据进行管理。最后,对HDFS文件系统的管理,HDFS中存储着业务数据以及日志,为安全管理这些数据而开发其文件管理模块,实现对文件的“增减查改”操作。文件安全操作主要从2个方面得以体现:一是对系统管理员严格授权,如有需更新、删减的文件,一定要至少2个超级管理员验证方可通过;二是将有待更新、删减的文件先行备份到另一台服务器上,再从HDFS上进行操作,安全审计人员需要定期检查操作情况,所存在未经允许的操作,则应从备份服务器上对数据再次进行恢复处理。
2.3软件层设计
软件层重点集中在体验系统的设计上,软件系统主要以多租户模式为主,并按用户需求提供服务。多租户模式指的是用户可通用一个或一组程序,在实现方面,遵循SaaS成熟度模型的可扩展、可配置及高效率来设计实例池,默认体验系统程序的多个实例并将其部署在一台Tomcat服务器上,所以租户都可共享这一实例池,实例池可按照实际运营性能(如数据吞吐量)来调整池中计算节点的数量,并进行负载均衡。体验系统通过配置文件实现每个租户专有的UI与使用功能,从而可提供系统资源与功能2方面的按需服务[6]。
3结束语
在该系统平台中充分应用了云计算的虚拟计算机集群技术、实时流计算技术,促使系统资源实现了高可用性,令平台更为安全可靠。在该领域中,系统平台的研究重点依旧在于强化结构的设计层面上,而伴随一些全新体验系统的开发,更多可复用功能可抽象为服务,尤其是今后以SOA云架构为基础必然会提高云服务平台的效率,帮助用户获得更全面、良好的汉字文化数字化体验。
