基于大感知域LSTM-Seq2Seq 模型的代码缺陷检测方法
2023-05-30王鹏姚鑫鹏汪克念陈文琪陈曦
王鹏,姚鑫鹏,汪克念,陈文琪,陈曦
(1.中国民航大学a.安全科学与工程学院;b.中欧航空工程师学院,天津 300300;2.民航航空器适航审定技术重点实验室,天津 300300)
随着软件规模与复杂度不断增加,软件缺陷导致的系统失效风险不断提升。系统在执行任务过程中存在的失效风险可能会引起灾难性后果。这一情况在民用航空领域尤为突出。为了在软件投入使用前查找并改正代码中存在的缺陷,需对软件代码的需求符合性、可验证性、正确性、一致性等进行评审分析[1-2]。目前,代码评审[3]主要可以分为人工评审和自动评审两个方向。
对于人工评审过程[4],评审专家会检查软件代码是否存在资源竞争、内存泄漏、缓冲区溢出和结构化查询语言(SQL,structured query language)注入等安全性缺陷。因此,评审过程十分依赖专家经验。由于不同专家的知识领域、活跃度、对评审项目的熟悉程度不尽相同,从而导致项目评审效果参差不齐,且基于专家经验的代码评审过程存在效率低、工作量大等问题[5],这严重影响了软件项目的评审效果。为了提高评审效果,研究者们不断优化搜索算法以推荐最优的项目评审人员。文献[6]提出一种基于贝叶斯个性化排序的BPR-CR2 评审者推荐模型,模型分析了4 种可能会影响评审者评审意愿的因素,在先验知识条件下极大化后验概率,以推荐最适合的评审人员。文献[7]提出一种效力优化的代码评审者推荐模型,通过计算历史评审者的时间效力与内容效力来推荐合适的代码评审人员。上述方法旨在通过优化搜索算法来推荐合适的评审人员,以提高代码评审效率,但未能减少评审人员的实际工作量。
随着深度学习技术的发展,尤其是在自然语言处理领域取得的成就,使其在代码评审领域的应用变为可能。代码本身作为一种语言,有准确的语法规则,其语料库与自然语言语料库有相似的统计特性[8],同类代码缺陷在代码结构及数据流上具有一定的相似特征,可使用深度学习算法挖掘代码样本中的安全性缺陷特征[9-10]。文献[11]提出一种代码分析方法,该方法以代码段与缺陷检测数据为输入,训练深度网络模型,获取代码编码规则与评审建议特征,并基于评审数据库输出评审建议。文献[12]使用查重工具在Stack Overflow 网站上查找与被审代码相似的代码段,然后通过计算文本相似度得到代码缺陷估量,以此来计算代码缺陷概率。上述方法计算的缺陷概率与两段代码相似度有关,通过检测算法输出的评审建议与缺陷概率无法直接反映代码缺陷类型。文献[13-14]提出一种基于卷积神经网络的源代码缺陷检测方法,可以挖掘代码中蕴含的缺陷特征,完成代码缺陷检测工作以实现代码自动缺陷检测。但该方法不能输出与代码缺陷特征相关的评审建议,达不到帮助评审人员实现快速评审的目的。
因此,目前自动代码评审方法存在的问题主要可以归结为:在代码评审过程中,现有模型或方法仅对源代码缺陷进行检测,不能自动化地对代码缺陷特征进行分析并给出专家建议,导致在后续修复代码缺陷的工作中,仍需依靠大量基于人工评判的专家经验对模型输出结果进行验证。
为解决以上问题,本文提出了一种基于长短期记忆网络[15](LSTM,long short-term memory)与序列到序列模型[16](Seq2Seq,sequence to sequence)的代码缺陷检测方法。该方法相较于传统代码缺陷检测方法,采用深层LSTM 来学习数据集中的代码缺陷特征与评审建议特征,首次提出基于大感知域的Seq2Seq 模型来建立代码与评审特征间的映射关系,从而实现对未知代码段缺陷的检测、分析和输出评审建议等功能,以辅助评审人员展开代码评审工作。
1 大感知域LSTM-Seq2Seq 算法流程介绍
本文通过改进LSTM-Seq2Seq 模型结构,提升模型对代码缺陷深层特征的捕获能力与感知域,并将其应用于代码缺陷检测任务中,建立代码缺陷自动检测模型。该模型可在代码变更评审[17]、代码整体评审过程中辅助评审人员实现快速评审。本文方法流程图如图1 所示,主要流程包括数据清洗、词嵌入处理、模型训练3 部分。首先,通过数据清洗模块去除数据集中的噪声数据。其次,对数据集进行词嵌入处理,得到相应的词嵌入模型,模型将文本数据转换为词向量数据以训练深度网络模型。最后,采用深层LSTM 网络学习代码缺陷的数据特征与评审建议的数据特征,基于Seq2Seq框架建立代码缺陷特征与评审建议特征间的映射关系,实现评审输出功能。经过训练的深度网络模型可实现检测代码中的缺陷漏洞并给出相应评审建议的功能。本文整体架构基于C 代码数据集实现,针对不同编程语言的代码评审,该方法整体框架不变,可用以解决现有方法中存在的问题。
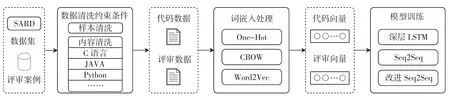
图1 方法流程图Fig.1 The framework of proposed method
1.1 数据清洗
循环神经网络建立数据特征与特征间映射关系的关键在于网络模型能够学习文本的上下文关系,挖掘其中的数据特征,数据集质量严重影响着模型最终的缺陷检测效果。SARD 数据集中存在大量注释信息,实际评审案例中部分样本被用于描述工具版本迭代或代码结构优化,与代码缺陷无关。本文方法为突出数据集中代码缺陷与评审建议特征,首先对数据集中的噪声数据进行清洗。数据清洗过程分为内容清洗与样本清洗,即分别对单个样本包含的噪声数据和数据集中的噪声样本进行清洗。针对数据集中存在的噪声特征编写数据清洗需求如表1 所示。
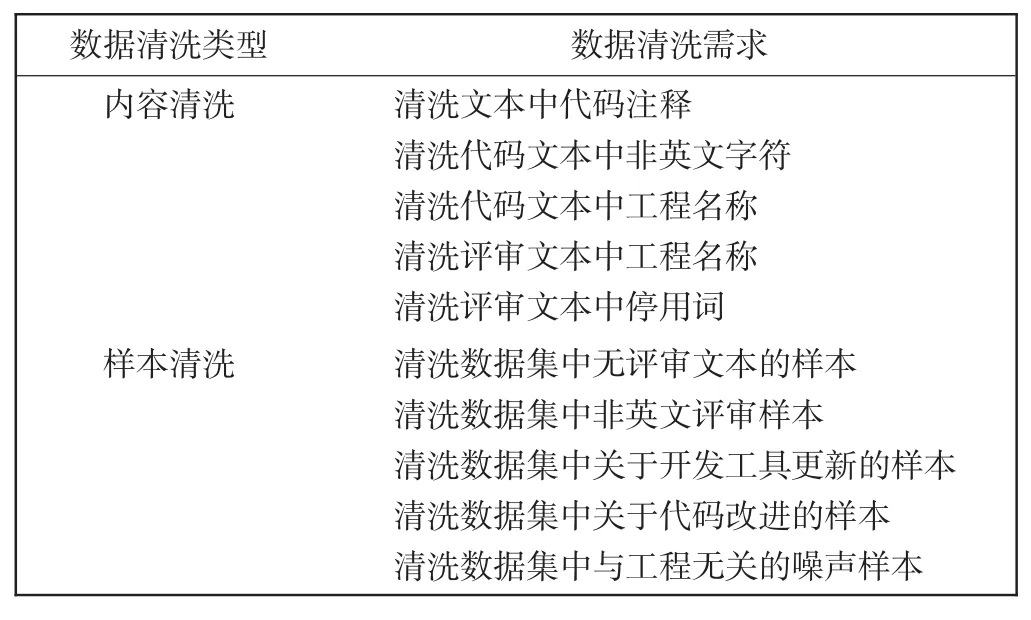
表1 数据清洗需求表Tab.1 Requirement table of data cleaning
针对每一条数据清洗需求,基于正则表达式编写其相应的数据清洗算法。正则表达式是对字符进行检索、替换的一种逻辑公式,对噪声数据特征建立约束条件,基于约束条件检索并删除数据集中的噪声数据,以实现数据清洗功能。根据数据清洗需求编写算法时,需结合被清洗语言的编码规则进行编写,同时需考虑编程语言编码规则的差异性,本文方法中清洗算法以C 代码编码规则为基础进行编写。
1.2 词嵌入处理
使用Word2Vec[18-19]技术对数据集进行词嵌入处理,在自然语言处理过程中,神经网络通过训练实现对文本的分析任务。Word2Vec 的两种算法模型分别为跳元模型(skip-gram)和连续词袋模型(CBOW,continuous big-of-words):skip-gram 模型以一个词单元为输入预测其上下文关系,此训练方法对低频词的训练效果较好,但训练过程相对缓慢;CBOW 模型以词单元的上下文关系为输入预测词单元本身,模型训练速度较快[20]。本文使用的代码集与评审集属于代码评审领域语料库,低频词占比较小,因此使用训练速度较快的CBOW 模型对语料库进行无监督训练。
1.3 深层LSTM 提取样本特征
传统LSTM 网络由于其短期性问题,对学习长代码序列数据的深层特征仍存在一定局限性,因此本文使用一种深层LSTM 网络结构来学习代码缺陷数据集的深层数据特征,以实现更好的长序列特征记忆效果。
输入层Input 后连接3 层LSTM,每层LSTM 后连接Dropout 层提高模型泛化能力,第3 层Dropout 后连接Dense 全连接层实现分类训练。使用深层LSTM 学习代码缺陷特征,实现代码缺陷检测功能,深层LSTM相较于单层LSTM 可建立更加复杂的特征表示,从而对深层复杂特征有更好的提取效果。
1.4 基于大感知域注意力机制的Seq2Seq 模型
为了解决传统Seq2Seq 模型在回归任务中信息压缩损失问题与注意力(Attention)机制[21]在代码评审项目中的感知域过于集中的问题,提出了一种基于大感知域注意力机制的Seq2Seq 模型,建立代码缺陷特征与评审建议间的映射关系,以实现输出评审建议功能。
Seq2Seq 模型是一种由编码器(Encoder)和译码器(Decoder)组成,实现序列到序列转换的深度网络模型。
Encoder 对代码词向量特征进行提取、压缩并输出至隐藏层状态,作为上下文信息C。Decoder 读入上下文信息C,进行解码、映射并输出评审词向量特征,实现评审输出功能。但Encoder 压缩输出过程是有损压缩过程,当输入序列长度过长时会导致上下文信息中部分特征信息损失。为了解决这一问题,向Seq2Seq模型引入Attention 机制减少由长序列到定长序列转换时的信息损失。
在Decoder 对特征编码进行解码时,使用Attention机制根据解码位置信息对Encoder 提取的字符级局部数据特征重新进行加权,组成具有解码位置权重信息的局部特征编码。引入Attention 机制后,Seq2Seq 模型中Decoder 输入量不再是单一的上下文信息,而是带有序列转换位置权重的上下文信息,进而解决Seq2Seq模型在长序列转换时的信息压缩损失问题。但Attention机制应用于评审输出任务时仍存在一定不匹配问题。由于字符级局部特征无法决定整段评审特征的变化趋势,Decoder 解码过程中注意力不应聚焦于单个代码词单元的局部特征上,应该更加聚焦于由多个代码词单元组成的代码段特征之上。因此,向Seq2Seq 模型中引入代码段长度系数L,在进行上下文信息的权重计算前,将长度系数为L 的字符级局部特征进行数据融合,输出代码段级局部融合特征。将其代码段级局部特征作为Attention 机制权重计算对象,重新计算分配权重给上下文信息,以提高模型整体感知域,改进后的Seq2Seq 模型如图2 所示。
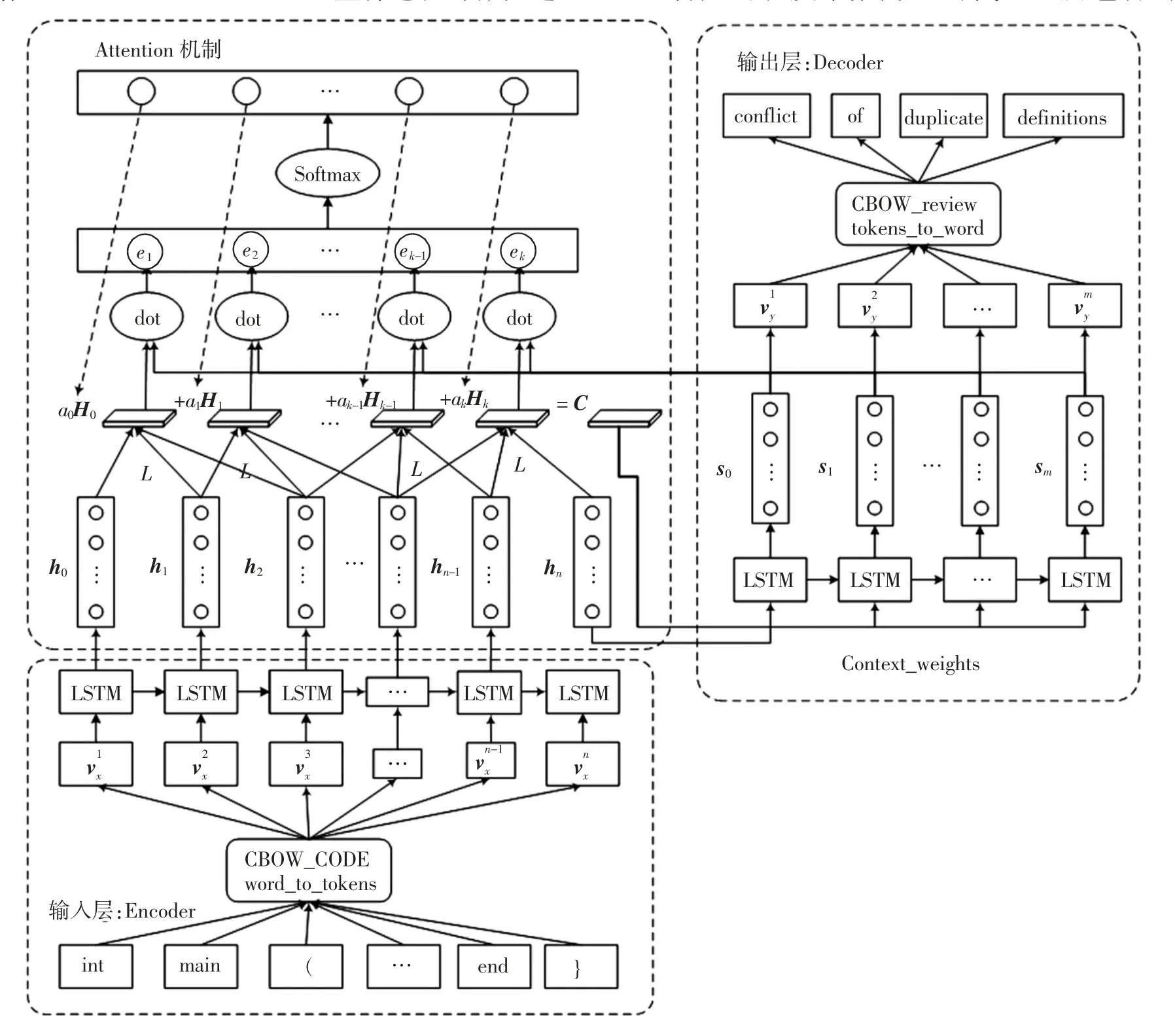
图2 大感知域Seq2Seq 结构图Fig.2 Seq2Seq structural model with large perception
首先对长度系数为L 的代码段所包含的数据特征进行数据融合处理得到代码段级局部特征
式中hk表示字符级局部特征。
其次,计算解码器特征与每一个代码段级局部特征间的相关度
式中sj表示解码器第j 步预测出的词向量。
eij通过Softmax 函数映射至0~1,并作为代码段级局部特征影响解码器解码输出的权重aij,局部特征与解码器特征间的相关度越大,局部特征的影响权重越大,aij表示如下
经过aij分配权重后,Decoder 得到代码段级局部特征加权平均后的Encoder 隐藏层状态,并将其作为上下文信息,即
改进后的上下文信息Ci包含的注意力信息从字符级局部特征转移至代码段级局部特征中,进而提升了模型输出评审效果。
2 实验与分析
2.1 实验数据
SARD 标准数据集[22]是国内外代码自动评审领域广泛应用的公开数据库。数据集覆盖了13 660 个测试程序,40 031 个代码评审样本,105 类代码缺陷漏洞。数据集中代码缺陷漏洞通过“OMITBAD”进行标注,同时对漏洞进行修复后的正确代码段使用“OMITGOOD”进行标注,错误代码段中使用“POTENTIAL FLAW”对漏洞相关属性进行标注,注释对代码缺陷漏洞可能产生的相关危害进行了说明,可作为代码评审数据。为了增强模型的泛化能力,向数据集中引入实际工程代码作为数据集的补充,对实际工程代码样本进行数据清洗及预分类,通过整理筛选最终得到28 936 份代码缺陷及其评审文本数据。
对所有数据集进行标准化处理,文本统一为小写数据,并进行分词处理。经过数据清洗后的数据集相较于原始数据,其噪声数据大幅减少,缺陷特征更加清晰,对应特征之间相关度显著增加。
使用Word2Vec 进行词嵌入工作为实验做准备,使用代码数据与评审数据训练CBOW 模型。滑动窗口大小window 设置为5,词最小出现数min_count 设置为5,分4 个线程,workers 设置为4 开始训练,训练完成后得到两组Word2Vec 转换模型,以对代码和评审文本进行重新编码。
为了统一数据格式,重新编码过程中固定代码段中最大代码单元个数为500。对所有样本按照4 ∶1 的比例划分为训练数据集和测试数据集,通过reshape函数将数据集格式整理至与网络结构格式相同后,将其输入至神经网络中进行训练。
2.2 实验环境
搭建模型实验环境,软件环境:windows10、CUDA 10.1+cudnn7.60、PyCharm2020.2 平台、Tensorflow2.2、Keras2.4.3、Tensorboard2.2.2、nltk3.5、numpy1.18.5;硬件环境:AMD R7-4800H CPU@2.9 GHz、16 GB 内存、NVIDIA GeForce GTX1650 GPU。
模型参数设置:根据功能划分将训练过程分为深层LSTM 训练与改进的LSTM-Seq2Seq 模型训练。其中LSTM 隐藏层维度为256维,Dropout 设置为0.3,编译模型使用Adma 优化器,输出层激活函数采用Softmax,损失函数使用交叉熵损失;Seq2Seq 模型中Encoder 与Decoder 使用双层256 维LSTM 组成的循环神经网络,使用Relu 作为激活函数,编译模型使用Adma 优化器,使用均方差损失MSE 为损失函数,完成配置,进行回归训练。
经过样本数据训练,模型学习代码缺陷特征与评审特征间的词向量映射关系,可针对代码缺陷特征进行评审输出。
2.3 评价指标
首先,对模型缺陷检测效果进行质量评价,检测效果好坏决定整个缺陷检测方法是否处于可用状态,需通过评判指标量化本方法的缺陷检测效果。混淆矩阵是机器学习领域通用的性能指标,可以直观反映模型预测性能。通过计算得到准确率Aaccuracy、召回率Rrecall和F1值等具体评估指标,对比模型在不同网络参数下的训练效果。评估指标计算方法如下
式中:真阳性(TP,true positive)表示错误代码被判别为错误的样本个数;真阴性(TN,true negative)表示正确代码被判别为正确的样本个数;假阳性(FP,false positive)表示正确代码被判别为错误的样本个数;假阴性(FN,false negative)表示错误代码被判别为正确的样本个数。使用与训练集无交集的数据集进行测试,检测准确率和召回率高的网络模型其泛化误差较小,模型泛化能力较强,预测结果置信度高。
对模型评审输出效果进行质量评价。词嵌入向量是文本数据映射到高维向量空间的表示,词向量之间的余弦相似度越大,其所表示的词性、词义越接近。因此,为了量化模型输出的评审质量,使用Word2Vec 编码计算模型输出评审与人工评审文本间的余弦相似度,以余弦相似度模拟模型输出评审与代码缺陷特征之间的相关程度[23],并作为模型输出质量的评判标准。关于文本相似度计算方法,可定义模型输出评审的词向量矩阵为
专家经验评审文本的词向量矩阵为
模型评审与人工评审词向量单元之间的余弦相似度为
式中mu、nv为高维词向量。模型输出评审与人工评审之间的文本相似度为
式中Z 表示整数域。
使用与训练集无交集的数据集对模型效果进行测试,记录模型评审与人工评审的文本相似度。
2.4 实验结果与分析
为了验证深层LSTM 网络的有效性,使用SARD 标准数据集对模型性能进行测试,在相同软硬件与实验环境下与SySeVR[9]、TextCNN[14]、DCR[11]方法中使用到的网络结构进行对比。首先对不同网络训练过程进行对比分析,模型训练过程中验证集测试Loss 曲线如图3所示。
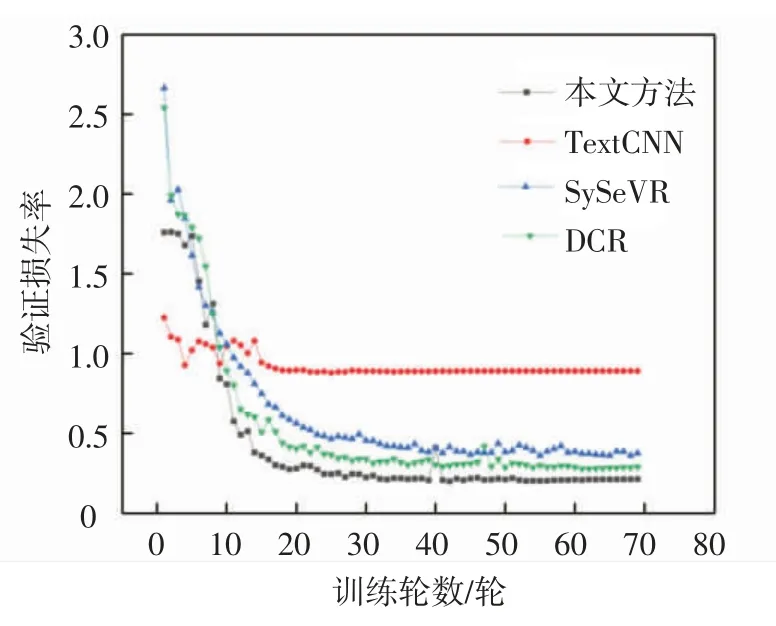
图3 Loss 曲线Fig.3 Loss curve
由图3 可知,本文方法在训练过程中,前期Loss曲线下降较慢,但经过长时间训练后,本文方法对数据集特征的学习效果较好,训练Loss 下降最低,模型与真实数据拟合程度较好。
模型训练过程中验证准确率变化曲线如图4 所示,DCR 方法在训练过程中Loss 表现优于SySeVR,但验证精度表现始终差于SySeVR。本文方法模型验证准确率上升趋势表现与其Loss 下降趋势表现一致,由于其训练参数相对较多导致训练过程缓慢,但本文方法模型可以学习到代码数据中更深层次的数据特征,从而将代码漏洞特征进行高维抽象表示并提取映射至输出层,进而在验证准确率方面表现最好。本文方法在训练过程中,模型验证准确率稳步上升达到了93.60%,高于对比方法的代码缺陷检测模型。
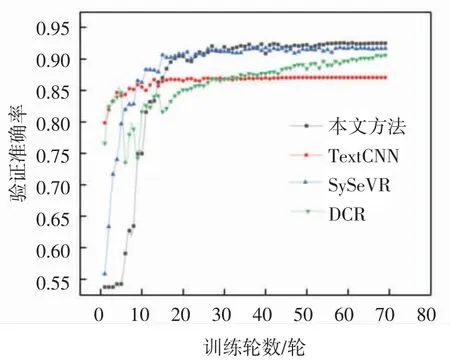
图4 验证准确率Fig.4 Verification accuracy rate
本文方法在检测到代码缺陷后可对其输出评审意见,需比较不同模型在评审输出任务中的性能表现,经过SARD 标准测试集测试后不同方法性能表现如表2 所示。
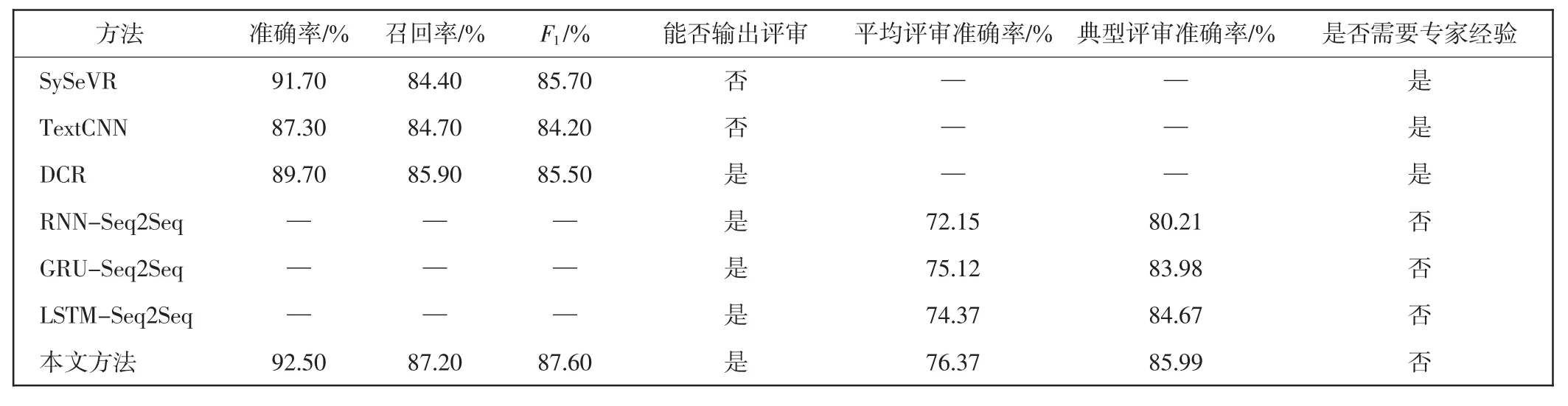
表2 不同方法缺陷检测效果对比Tab.2 Comparison of defect detection effect for different methods
SySeVR、TextCNN、DCR 在对代码缺陷进行检测的任务中取得了较好的效果,但未能对缺陷特征进一步分析并输出评审建议。Seq2Seq 模型在代码缺陷检测任务中实现了输出评审建议的功能,由于组成编码器、解码器的网络结构不同,模型运行效果存在差距。在实验过程中基于传统RNN(recurrent neural network)网络的Seq2Seq 模型,训练参数表现稳定整体波动较小,基于GRU(gate recurrent unit)[24]网络的Seq2Seq 模型训练速度相对较快。但从实验结果来看,基于LSTM 网络的Seq2Seq 模型在评审文本相似度方面的表现明显优于基于传统RNN 网络和GRU 网络的Seq2Seq 模型,LSTM 3 个门控单元在训练过程中对数据特征的分筛、吸纳更加灵活,LSTM 网络相较于其他循环神经网络在本文方法中应用优势更加明显。因此,本文方法以LSTM-Seq2Seq 模型为基础,针对代码数据特征对Seq2Seq 模型进行改进,改进后的模型对长序列代码漏洞特征输出评审时有更好的性能表现。
通过与现有代码缺陷检测方法比较,本文方法可对源代码中隐含的代码缺陷进行检测分析并输出评审建议,模型对安全性缺陷进行分析并输出的评审结果与专家先验知识相似度为76.37%。由于模型不确定性与数据不确定性的干扰增大了部分评审结果的不确定度,为了减小数据不确定度对模型测试性能的影响,最终在测试集中人工筛选了具有典型缺陷特征的评审样本对模型评审输出性能进行验证,选取漏洞类型包括SQL 注入、CWE122、CWE-114 等。模型对人工筛选出的典型代码缺陷样本进行评审,其输出评审文本与专家评审文本相似度达85.99%。
根据测试结果,本文方法可以有效地帮助评审人员确定缺陷类型,快速完成评审工作,与现有基于深度学习的代码缺陷检测方法相比,其在对评审结果进行分析验证的过程中减少了对专家经验意见的依赖。
3 结语
本文针对现有代码缺陷检测方法无法输出评审建议的问题,提出了一种改进的代码缺陷检测方法。该方法基于大感知域注意力机制LSTM-Seq2Seq 模型建立代码缺陷检测模型,实现对未知代码的缺陷检测和输出评审功能。该方法基于SARD 数据集与实际评审样本进行训练,基于SARD 标准测试集测试,模型对代码安全性缺陷检测准确率达92.50%,召回率达87.20%,F1评估参数达87.60%,达到了较高的水平。缺陷检测模型对具有典型缺陷特征的代码样本进行测试,输出的评审文本与专家评审的文本相似度达到85.99%。测试结果表明代码缺陷特征与评审特征间具有显著的相关关系,且深度网络模型可以通过训练建立其数据特征及映射关系,输出评审建议。
本文方法在评审输出方向改进了现有的代码缺陷检测方法,在实际应用中能辅助评审人员提高评审效率。在训练及测试验证过程中发现,训练数据对代码安全性缺陷数据特征的覆盖不够完整,实际评审样本中存在噪声数据,导致模型结果产生了模型与数据的不确定性,且无法对不确定度进行准确评估。接下来,考虑将Seq2Seq 模型与贝叶斯神经网络相结合计算评审置信度,以更好地辅助评审人员展开代码评审。
