基于深度学习的艺术类论文分类方法研究
2023-05-30古丽扎达·海沙
古丽扎达·海沙
摘要:艺术类论文是论述艺术创新思想的涵盖音乐、舞蹈、美术和戏剧等学科的论文。以艺术类论文分类为目的,解决了以下两大难题:一个是没有大量的细分类论文语料库,以及语料的不足导致系统性能下降;另一个是参与分类任务的输入文本较短,无法提取有用的语义特征。具体地,构建数据集,通过基于弱监督同义词替换方法增强数据集;训练并测试基于类别关键词注意力机制的神经网络模型。通过实验证明,关键词的注意力矩阵能够强化论文摘要表达的语义信息,在艺术类论文分类任务中效果较好,该方法也可以在其他领域中应用。
关键词:论文分类;注意力机制;关键词;同义词;艺术类
中图分类号:G254.1文献标志码:A文章编号:1008-1739(2023)02-67-5

0引言
在海量的文献数据中,通过论文分类获取有价值的论文资源是一项重要的研究。随着发表的论文数量越来越多,论文的分类研究在论文管理系统中起着至关重要的作用,尤其是论文的细分类问题。论文自动分类是指正确地划分论文学科类别,解决文献检索不便的问题,提高研究者的工作效率,同时也是论文管理系统的重要组成部分。论文分类方法一般将论文的标题、摘要及关键词等信息作为分类目标[1-4]。论文摘要是以提供论文内容为目的的短文本。短文本是一类单词数少于200的文本[5],它具有文本长度较短、语义特征不完整、缺乏上下文信息等特点。现有的短文本分类方法主要采用基于深度学习的卷积神经网络(Convolutional Neural Network,CNN)来完成,但是這类方法中存在语义特征信息不足的问题。本文初步对论文数据进行分析并发现容易被错判的论文和被正确分类的论文之间的区别,再根据问题寻找优化模型的方法。即首先通过同义词替换的方法增强分类数据集。此外,针对短文本的特点和现有深度学习的特点,提出了基于关键词注意力机制的论文分类模型,以期得到一个理想的分类模型。
1相关研究
论文分类一般是通过文本分类来完成,很多学者对此进行了研究并提出了诸多解决办法。当今,文本分类任务包括基于传统机器学习方法和深度学习方法。支持向量机(Support Vector Machine,SVM)模型是传统的机器学习方法,通常采用组合若干个相同特征的二分类方法来处理多分类问题[6]。董放等[7]采用LDA主题模型与SVM分类连用的方法解决了论文分类的问题。康蔷等[8 ]利用加权的K最近邻(K-Nearest Neighbor,KNN)分类器对中文论文进行分类。
得益于神经网络强大的非线性拟合能力,基于深度学习的方法已经被证明能够挖掘文本的深度信息,因此,许多学者利用深度学习的研究方法解决文本分类问题。目前,CNN、循环神经网络(Recurrent Neural Network,RNN)及RNN的变体模型和预训练表征BERT[9]等网络模型在分类任务中广泛使用。田文洪[10]设计了一种基于注意力长短期记忆RNN模型完成对各章节内容进行加权数据表征,然后进行整篇论文质量分类。路永和等[11]分别在词级和句级使用双向门控循环单元(Bidirectional Gated Recurrent Unit,BiGRU)对写作需求和参考文献进行语义建模并计算论文引用关系类别。深度学习算法虽然取得了较好的效果,但仍存在一些问题。对于短文本,上下文提供的特征是有限的,特征不能有效地利用,导致一些文本的特征不能被模型完全掌握。近几年,有学者提出预训练模型[2]来解决这个问题,将文本作为BERT的输入,然后根据[CLS]位置将输出的向量与候选实体的起始位置和结束位置向量进行分类。然而,由于BERT模型提取的特征相对广泛且有噪声,本文认为该任务的性能还可以进一步提高。
现有的艺术类论文语料库规模有些小,不能满足各种场景下文本分类模型对语料库的需求,本文采用数据增强方法扩充数据。同时,针对论文摘要的文本数量有限,训练模型中的语义特征信息的不足等问题,采用关键词注意力机制的深度学习模型来提取文本的有效语义特征。
2基于同义词替换的数据集增强
2.1问题的描述
在文献的摘要中,文本信息在形式和措辞上有不同的表达方式,这使得很难确定摘要所属的类别。有些句子具有相同的语义,但表达方式却不同。例如,要表达某种舞蹈的特征,可以有很多的表达方式:“苗族舞蹈具有较高的艺术价值”“苗族舞蹈具有独特的艺术特色”;又可以将“苗族舞蹈”替换为其他的舞蹈类型,如:“蒙古舞”“朝鲜舞”“民间舞”“古典舞”“芭蕾舞”“踢踏舞”“爵士舞”“铁环舞”“萨玛舞”“打鼓舞”等等。这些句子都可以表示属于舞蹈类论文的句子。仅仅依靠人力资源来收集和总结所有可能情况下的所有问题语料库是不现实的。
2.2数据增强方法
同义词替换(Synonym Replacement,SR)方法[12]是从句子中随机选取个不属于停用词集的单词,并随机选择其同义词替换它们。这种方法保证了用更大的概率选中与原始单词更相似的近义词。基本思想是,首先计算每个类别论文中特征词的TF值,过滤出反映类别的特征的核心词作为关键词;然后,将关键词替换为同义词词典中的同义词。基于弱监督学习的数据增强过程引入近义词词典,进行同义词替换,获得大量的类别数据集。为了强化数据集,设计了如下算法。
算法1基于弱监督学习的数据增强算法
(1)选择特定类型(舞蹈类文本)的数据集,进行分句、分词、删除停止词等预处理操作;
(2)计算预处理后的文本的TF值,根据TF值对其进行排序,取前个关键字;
(3)使用同义词字典对个关键字进行字典匹配,选取与每个关键字语义相似的个单词;
(4)替换原句子中的个关键词,生成更多语义相同但表达不同的句子。
2.3同义词字典和超参数选择
本文使用的同义词词典是哈尔滨工业大学信息检索研究室提供的《同义词词林扩展版》,按照树状的层次结构把所有收录的词条组织到一起,把词汇分成大、中、小三类。每个小类的词又根据词义的远近和相关性分成了若干个词群,词群由若干行组成,同一行的词语义要么相同,要么非常接近。例如,“卡通”“动画”“卡通片”“木偶剧”“动画片”在同一行;“电影”“影戏”“影”“影片”“影视”“录像”在同一行。另外,“风景画”“山水画”“人物画”“肖像画”“宗教画”“花鸟画”“图案画”也在同一行,这些词语义不同,但很相关。
超参数的设置是上文提到的和的选择。合理選择和是提高文本数据质量的有效方法。为了确定这2个超参数,本文做了很多实验。首先计算某一个类别(如美术类)的所有输入样本的词频(Term Frequency,TF)值,然后对其进行排序,确定的取值范围。通过实验发现TF值最高的18个关键词对分类效果影响较大,因此,值取为(1,18),是一个比较合理的范围。值主要取决于同义词词典的规模,通过对同义词词典的观察发现,同一行的近义词中前1~5个词较好地反映原文的意思,因此,取值(1,5)是合理的。
3分类模型
3.1模型结构
本文提出一种论文类别关键词注意机制与深度学习模型CNN-GRU相结合论文分类模型。具体结构如下:模型的输入层包含2个通道,一个通道是Word2vec训练单词的词向量矩阵,另一个是获取关键词注意力矩阵;再将从2个通道中学习到的特性进行合并;然后通过CNN学习文本中每个单词的高维度局部特征;最后,利用GRU网络提取全局文本语义特征。模型总体流程如图1所示。
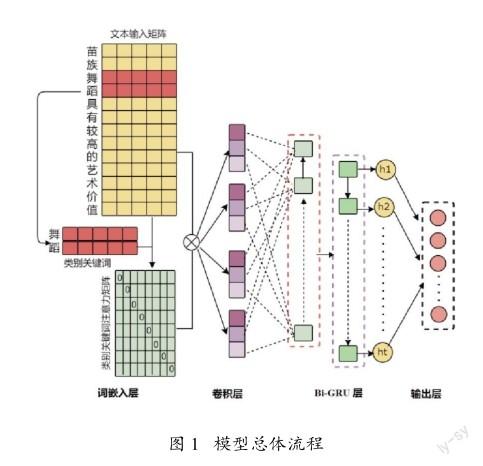
3.2输入特征层
模型的输入层由词向量矩阵和类别关键词注意力矩阵拼接构成。
(1)词向量矩阵
本文使用谷歌开发的开源工具Word2vec进行单词向量训练,Word2vec词向量工具输入为文本文档,输出为基于这个文本文档的语料库训练得到的词向量模型。Word2vec[13]对词向量的训练有2种方式:一种是CBOW模型,即通过上下文来预测中心词;另一种是skip-Gram模型,即通过中心词来预测上下文。CBOW对小型数据比较适合,而skip-Gram模型在大型的训练语料中表现更好。因此,为了计算字向量,本文使用了CBOW。其中,单词特征窗口大小为8,最小词频为1和词向量维度为128。
(2)类别关键词注意力矩阵
通过对初步构建的论文摘要数据集进行TF值计算发现,艺术类论文分类中,每个类别都有一些属于自己的高频词汇,具体如表1所示。本文从每个类别中选择代表性的关键词构成关键词类别词典。



4实验与分析
4.1数据集
艺术类科研论文与其他意识形态论文的区别在于它的审美价值,这是它的最主要、最基本的特征。艺术类论文通过阐述艺术创作来表现和传达论文的研究内容和审美思想,欣赏者通过艺术欣赏来获得美感,并满足自己的审美需要。因此,本文根据艺术类科研论文特点,以艺术类院校专业设置来划分论文类别。本文从中国知网上抽取经典的、较为符合新疆艺术学院各类专业设置要求的音乐类、舞蹈类、美术类、设计类、书法类、传媒类、戏剧影视类、文化艺术类论文各1 000篇。然后将这些数据集通过基于弱监督的数据增强方法来扩充,扩充之后的数据以9∶1的比例分为训练集和测试集。
4.2实验环境与参数设置
硬件配置:GPU为RTX-2080Ti,CPU为i7-9700,操作系统为Windows 10,编程语言为Python3.6。论文分类模型的超参数设置如下:词向量维度为128,输入文本最大长度为200,Bi-GRU隐含层的维度256,批处理数据大小为128,迭代参数为20,神经元失活率为0.4,学习率为0.001。
4.3实验结果与分析
为了验证本文提出的论文分类模型的有效性,选择了SVM,KNN等传统的机器学习算法和CNN,GRU,Bi-GRU等深度学习模型作为基线系统进行论文分类实验,实验结果如表2所示。在本文的实验中,用精准率(P)、召回率(R)和F1-值(F1-score)作为评价指标。
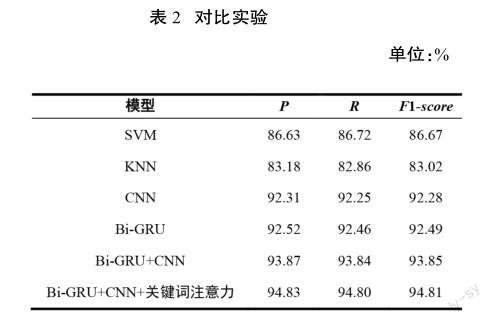
由表2可以看出,在艺术类论文分类实验中,传统的机器学习算法———SVM,KNN算法的实验结果明显低于深度学习模型。但是这类机器学习算法的核心思想是假设输入文本中出现的单词互相独立来计算条件概率,因此训练时间较短。SVM相比于KNN小样本数据的适应性较好。
深度学习算法———CNN和BiGRU与传统机器学习算法SVM相比获得较好的结果,这是由于建模的模型加强了上下文信息的依赖关系。
CNN+BiGRU是2种神经网络模型的拼接模型,该模型可以获得比单一模型更好的实验效果。
本文提出的基于类别关键词注意力机制的深度学习模型,使用论文摘要和论文类别关键词的词向量信息作为模型的输入,以有效克服论文摘要短而造成的特征信息较少的缺点,以此降低论文容易被错判的问题。
4.4消融实验
为了探讨本文所提模型的性能,设计了进一步的对比实验。
(1)迭代次数对实验结果的影响
为了验证迭代次数选择是否合理,本文选择不同的迭代次数,查看模型的收敛速度,收敛速率如图2所示。
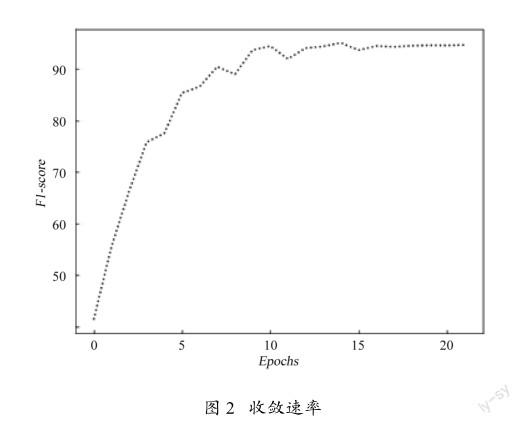
由图2可以看出,迭代次数为15~20时,模型收敛速度达到一个比较平稳的状态。
(2)卷积核大小对实验结果的影响
为了验证卷积核大小(filter-size)选择是否合理,本文选择不同的卷积核数进行实验,结果如表3所示。
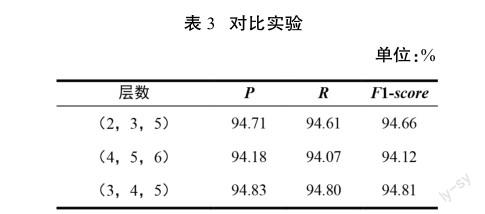
由表3可以看出,当卷积核大小为(3,4,5)时,模型达到了最佳效果;而当卷积核大小为(2,3,5)时,窗口较小,使得接收域的范围较小,接收域包含的文本信息较少,特征有限;当卷积核大小为(4,5,6)时,由于接受域的变化使全局特征明显,模型获得的文本语义信息中存在相当大的噪声,模型的复杂性增加。
5结束语
论文分类作为文献管理中的重要环节,帮助研究者从海量数据中找到自己所需要的研究资源。本文针对摘要文本语义稀疏,模型很难获取到足够的语义信息,导致准确率不高的问题,采用数据增强方法扩充和构建艺术类论文细分类数据集,极大地降低了人力资源的成本。此外,提出了一个基于类别关键词注意力机制的深度学习模型对艺术类论文进行分类。实验表明,提出的模型可以弥补摘要文本特征信息较少的缺点,有效提高艺术类论文分类的准确率。
参考文献
[1]薛峰,胡越,夏帅,等.基于论文标题和摘要的短文本分类研究[J].合肥工业大学学报(自然科学版), 2018, 41(10): 1343-1349.
[2]李彦轩.基于摘要的论文分类与推荐模型的研究与实现[D].北京:北京郵电大学,2019.
[3]王末,崔运鹏,陈丽,等.基于深度学习的学术论文语步结构分类方法研究[J].数据分析与知识发现, 2020,4(6):60-68.
[4]曾立梅.基于文本数据挖掘的硕士论文分类技术[J].重庆邮电大学学报(自然科学版),2010,22(5):669-672.
[5] GE S , YE Y , DU X , et al. Short Text Classification: A Survey[J]. Journal of Multimedia, 2014, 9(5):635-643.
[6]张学工.关于统计学习理论与支持向量机[J].自动化学报, 2000(1):36-46.
[7]董放,刘宇飞,周源.基于LDA-SVM论文摘要多分类新兴技术预测[J].情报杂志, 2017,36(7):40-45.
[8]康蔷,汪芳凯,邵恩泽. KNN算法在论文分类系统中的研究[J].中国科技投资, 2017 (3):284.
[9] DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of Deep Bidirectional Transformers for Language Understanding[J/OL].[2022-09-10].https://arxiv.org/abs/1810.04805.
[10]田文洪.一种基于注意力长短期记忆循环神经网络的论文质量测评方法:CN111522946A[P].2020.
[11]路永和,刘佳鑫,袁美璐,等.基于深度学习的科技论文引用关系分类模型[J].现代情报, 2021,41(3):29-37.
[12] STEVENS A K,SUN C J,LIU B G,et al.Augmentation and Heterogeneous Graph Neura1 Network for AAAI2021-COVID-19 Fake News Detection[J].International Journal of Machine Learning and Cybernetics, 2022(13):2033-2043.
[13] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient Estimation of Word Representations in Vector Space[J/OL].[2022-10-11]. https://arxiv.org/abs/1301.3781.
