基于预训练模型融合深层特征词向量的中文文本分类
2023-05-30汤英杰刘媛华
汤英杰 刘媛华


摘要:为解决传统模型表示出的词向量存在序列、上下文、语法、语义以及深层次的信息表示不明的情况,提出一种基于预训练模型( Roberta)融合深层特征詞向量的深度神经网络模型,处理中文文本分类的问题。通过Roberta模型生成含有上下文语义、语法信息的句子向量和含有句子结构特征的词向量,使用DPCNN模型和改进门控模型(RGRU)对词向量进行特征提取和融合,得到含有深层结构和局部信息的特征词向量,将句子向量与特征词向量融合在一起得到新向量。最后,新向量经过softmax激活层后,输出结果。在实验结果中,以F1值、准确率、召回率为评价标准,在THUCNews长文本中,这些指标分别达到了98.41%,98.44%,98.41%。同时,该模型在短文本分类中也取得了很好的成绩。
关键词:预训练模型;Roberta模型;DPCNN模型;特征词向量;中文文本分类
中图分类号:TP 391.1
文献标志码:A
随着移动互联网技术的飞速发展,以及社交平台、购物平台的不断涌现,人们畅游在网络世界中,在享受高度便利和快捷生活的同时,海量信息也随之充斥网络,让人们难辨真伪和善恶。对网络信息进行正确的文本分类,可以有效降低互联网舆论中负面的影响,如:造谣、诋毁、恶意中伤等事件。同时,正确的文本分类,可以建立起智能信息推荐系统,根据用户的个人兴趣来定位并推荐相关的新闻资料、商品信息等;也可以建立垃圾信息过滤系统,减少生活中琐碎、烦心事件,极大地简便公众的生活。
文本分类的方法包括使用传统的机器学习方法和深度神经网络构建模型的方法。使用机器学习进行文本分类时经常会提取TF-IDF(term frequency-inverse document frequency)或者词袋结构,然后对模型进行训练,如支持向量机[1]、逻辑回归、XGBoost[2]等。利用传统机器学习方法进行文本分类的基本流程是获取数据、数据预处理、特征提取、模型训练、预测。TF-IDF和词袋模型都需要手动去构建词典,统计词汇,进而计算出相关顺序(使用欧式距离或夹角余弦相似度)。这两种方法都存在较大的缺陷,如计算繁琐、可解释性差、语义不明等。
软件、硬件技术的快速发展,使得文本分类问题开始从传统的机器学习转移到深度学习,词向量Word2vec[3]的发展,推动了深度学习模型在自然语言处理中的应用。深度学习模型包括卷积神经网络(convolution neural network,CNN)、循环神经网络(recurrent neural networks,RNN)、图神经网络(graph convolution network,GCN)等方法。
针对当前使用神经网络处理文本分类的问题,本文提出了预训练Roberta[4]模型,对输人数据的随机掩码和双向动态的向量表示方法进行训练,加强了向量表示的灵活性,实现了数据增强。利用DPCNN( deep pyramid convolutional neuralnetworks for text categorization)和改进门控网络提取深层词向量的特征,强化了有效信息,降低了无效信息和梯度消失的影响。运用注意力机制的方法融合句向量与深层词向量,增强了文本向量的语义丰富性,捕捉重要词与句之间的潜在语义关系,有效丰富了特征向量中的结构、语义和语法信息。
1 相关工作
目前的文本分类深度学方法主要包括两种,分别为基于卷积神经网络、循环神经网络和图神经网络进行改进的神经网络,以及基于预训练的神经网络。
1.1 基于CNN、RNN和GNN进行改进的神经
网络
文本分类模型使用较多的是TextCNN( textconvolutional neural network),该模型由Kim等[5]提出,第一次将卷积神经网络用于自然语言处理的任务中。TextCNN通过一维卷积来获取句子中n- gram的特征表示,对文本抽取浅层特征的能力很强。在长文本领域,TextCNN主要靠filter窗口抽取特征,但信息抽取能力较差,且对语序不敏感。文献[6]通过采用多个滤波器构建多通道的TextCNN网络结构,从多方面提取数据的特征,捕捉到了更多隐藏的文本信息。文献[7]提出图卷积神经网络对文本内容进行编码,文献[8]使用了异构图注意网络进一步提升了模型的编码能力。
文献[9]提出了循环神经网络的文本分类模型,但RNN结构是一个串行结构,对长距离单词之间的语义学习能力差,同时可能伴随有梯度消失和梯度爆炸的问题。随后,LSTM( long shorttermmemory, LSTM)和GRU(gate recurrentunit, GRU)模型被应用在自然语言处理任务中,LSTM由输入门、输出门和遗忘门控制每个时间点的输入、输出和遗忘的概率,有效缓解了梯度消失和爆炸问题。文献[10]中,提出了ONLSTM( ordered neuronslong-short memory)结构,在LSTM结构中引入层级结构,可以提取出文本的层级信息。GRU通过将输入门和遗忘门组合在一起,命名为更新门,减少了门的数量,在保证记忆的同时,提升了网络的训练效率。文献[II]用BiGRU模型进行文本情感分类任务,提出了使用BiGRU模型对文本进行情感分析。
1.2预训练神经网络
2018年,谷歌团队提出了transformer模型[12],并采用了self-attention机制[13]。相比于循环神经网络模型,transformer模型是并行结构,其运算速度得到了大大的提高。Transformer模型由encoder模块和decoder模块两部分组成,decoder模块与encoder类似,只是在encoder中self-attention的query,key,value都对应了源端序列,decoder中self-attention的query,key,value都对应了目标端序列。注意力机制开始被应用于图像处理上,Bahdanau等[14]首次将其应用在了NLP(自然语言处理)任务中,NLP领域也迎来了巨大的飞跃。文献[15]针对文本分类任务提出了基于词性的自注意力机制网络模型,使用自注意力机制学习出特征向量表示,并融合词性信息完成分类任务。
在Transformer模型和注意力机制的基础上,Devlin等[16]提出了预训练Bert模型(bidirectionalencoder representation from transformers),开启了预训练神经网络的时代。Bert的新语言表示模型代表了Transformer的双向编码器,从而生成了文本的双向动态句子向量。孙红等[17]基于Bert+GRU的网络结构对新闻文本进行分类,运用Bert得到特征词向量,利用GRU网络作为主题网络提取上下文的文本特征。文献[18]提出了一种基于Bert的构建双通道网络模型的文本分类任务,提升了混合语言文本分类模型的性能。
尽管上述研究证明了对文本进行特征提取和融合之后,可以为分类器提供足够的信息,提高了文本分类问题的准确率。但是,如何对句与词之间的结构、语义和语法等信息进行提取,未作出明确的说明和研究,这也是本文所关注的重点。简而言之,在提取文本信息时,既要提取出文本主要信息,同时也需要注重词与句之间内容关系的提取。
在此基础上,本文利用Roberta模型的强大功能,训练出含有上下文语义、语法信息的句子向量和含有句子结构特征的词向量。并分别利用DPCNN网络和改进门控网络(RGRU),对词向量进行特征提取,使用注意力机制将两部分输出的词向量进行融合,得到深层特征词向量。其中,DPCNN的主要作用是负责强化局部上下文的关系,RGRU负责词与词之间的时序关系,注意力机制对局部上下文关系和时序关系进行通盘考虑,使用注意力机制也能够更好地将特征中的重点表现出来。最后,将词向量与句向量相融合来提升模型的性能。
2 模型设计
2.1 模型结构
本文提出的模型应用于中文文本分类任务,模型结构图1主要由3个部分组成:a.Roberta模型对输入的中文文本进行预训练,得到含有上下文语义、语法信息的句子向量和词向量;b.将词向量分别输入至DPCNN特征提取层和改进门控神经网络中,然后使用注意力机制将两部分的特征词向量相融合,得到含有深层结构和局部信息的特征词向量;c.将句子向量与词向量进行融合,得到最终的文本向量表示,最后经过softmax激活层后,输出结果。
2.2 预训练模型Roberta
Bert预训练模型具有以下3方面优势:参数规模大、通用能力强、综合性能好。预训练模型中包含着丰富的文本信息知识,因此,近些年的文本分类任务中通常会使用Bert行文本特征提取。但是,Bert的预训练阶段并没有使用全词覆盖的方式,mask(掩码)字符不利于文本信息的提取,且使用NSP任务也会损害Bert的特征提取能力。为避免这些问题,本文使用了Roberta模型。同时,由于Roberta相较于Bert使用了更大规模的数据集,使得模型消耗的资源增加,训练时间增长。
Roberta模型结构不仅继承了Bert的双向编码器表示,而且将输入的句子表示为字向量、句向量、位置向量三者之和,经过多层双向Transformer编码器(见图2)得到文本的向量化表示。图中:Add表示残差连接;Norm表示层标准化;FeedForward表示前向传播;Nx表示Ⅳ个堆叠的相同x。
多头注意力机制:假设输入句子为X,X=[X1 X2 -xn],n表示样本句子中字的个数,对字使用one-hot编码表示,其维度为k,则X所对应的字嵌入矩阵为Y= [y1y2 - Ynl,xi所对应的向量表示为Yi。通过训练模型可得出Q(Query)、K(Key)、V (Value)矩阵,dk表示K中列向量的维度大小,从而计算得到注意力值为
Bert模型中掩码mask是静态的,即Bert在准备训练数据时,只会对每个样本进行一次随机的mask(在后续训练中,每个epoch(训练数据)是相同的),后续的每个训练步都采用同样的mask。Roberta模型相比于Bert,建立在Bert的語言掩蔽策略的基础上,将静态mask修改为动态mask,对数据进行预处理时会对原始数据拷贝10份,每一份都随机选择15%的Tokens(字符)进行mask,图3为Roberta掩码方式。
同时,Roberta取消了Bert的NSP(next sentenceprediction)任务,采用了更大规模的数据集进行训练,更好地表现出了词的语义和语法信息,文本向量表示更加完善。Roberta也修改了Bert中的关键超参数,使用更大的batch方式和学习率进行训练,增长了训练序列,使得Roberta表示能够比Bert更好地推广到下游任务中。
2.3 DPCNN特征提取层
DPCNN[19]模型相比于TextCNN模型是更为有效广泛的深层卷积模型,如图4所示。图中:σ(.)为逐分量非线性激活函数;权重W和偏差6(每层唯一)为所要训练的参数。
DPCNN的底层为Region embedding层,该层由多个不同大小的卷积核组成,经卷积操作后生成embedding,作为模型的嵌入层。本文使用两层等长卷积层来捕获长距离模式,提高对词位embedding表示的丰富度。
下采样的操作采用固定数量的滤波器,通过最大池化的方法,将原词向量的长度减少一半,计算复杂度也相对减少,但其中包含的文本内容却得到了加长。然后进行两层等长卷积,这两部分组合成block模块,重复block模块的操作,直至满足任务。随着模型深度的变化,词向量中的深层结构信息和全局语义信息会不断得到加强。
为了解决卷积过程中的梯度消失和爆炸问题,模型在block模块进行前与region embedding使用pre-actlvation策略进行残差连接,或者直接连接到最后的输出层,有效缓解了梯度问题。模型随着序列长度的加深呈现出深层次的金字塔结构。
2.4 改进门控网络
改进门控模型结构见图5,对于t时刻而言,输人为qt,隐藏层输人为nt-l,隐藏层输出为nt,计算过程如式(4)~(7)所示。
传统的门控神经网络中重置门和更新门都是使用的σ(σ=1/1+e-g)激活函数,σ函数存在以下两个缺点:a.容易出现梯度消失的现象,当激活函数接近饱和区时,变化太缓慢,导数接近0,从而无法完成深层网络的训练;b.σ的输出不是0均值,这会导致后层的神经元的输入是非0均值的信号,会对梯度产生影响,导致收敛变慢。本文的φ(φ= eg - e-g/eg+ e-g)激活函数具有以下3个优点:a.解决了上述σ函数输出不是0均值的问题;b.φ函数的导数取值范围在0~1之间,优于σ函数的0~0.25,一定程度上缓解了梯度消失的问题;c.φ函数在原点附近与y=x函数形式相近,当输入的激活值较低时,可以直接进行矩阵运算,训练相对容易。
3 实验
3.1 实验环境
CPU 6x Xeon E5-2678 v3,内存62 G,显存ll G,NVIDIA GeForce RTX 2080 Ti,操作系统为Windowsl0 64位,python版本为3.8,深度学习框架为PyTorch。
3.2 实验数据集
本实验采用网上公开的清华THUCNews文本分类数据集中的短、长文本数据集,用于预测模型的性能。选取THUCNews数据集中的10个类别进行测试,短文本的类别包括:体育、娱乐、房产、教育、时政、游戏、社会、科技、股票、金融;长文本的类别包括:体育、娱乐、家居、房产、教育、时尚、时政、游戏、科学、金融。实验数据集信息如表1所示。
3.3参数设置
文献[20]在使用Bert作文本分类时给出了fine-tune建议。多相关任务的前提下,选擇多任务学习进行Bert frne-tune,目标任务的实现需要考虑文本的预处理、图层选择和学习率。
进行学习率衰减,β= 0.95时模型效果最佳。Roberta模型只需要一个较小的学习率,同时使用warm-up策略,有助于缓解mini-batch的提前过拟合现象,保持分布的平稳,同时也有助于保证模型深层的稳定性。以Adam算法为基础,采用手动阶梯式衰减、lambda自定义衰减、三段式衰减和余弦式调整的4种方法(见图6),调整学习率。
宋明等[21]在Bert作文本分类时,运用FocalLoss[22]作为损失函数,提高了模型对困难文本分类的准确率,本文采取Focal Loss作为损失函数。
本文中Roberta模型的学习率为1.0×10-5,但是在DPCNN的结构中需要一个较大的学习率,取0.001。THUCNews长文本中句子长度取150,batch size取32;THUCNews短文本中句子长度取38,batch size为128。DPCNN结构中,等长卷积kernel size为3。
3.4评价标准
将准确率(accuracy)、精确率(precision)、召回率( recall)和Fl值作为实验的评价标准,相关的混淆矩阵结构如表2所示。式中,H表示混淆矩阵各值。
3.5 实验结果
为验证本文所提模型的合理性和有效性,采用了8种模型在两个数据集上进行测试,最后的结果也表现出本文所提出的模型效果优于其他7种模型。
a.FastText[23]。Facebook在2016年发布了这种简单快速实现文本分类的方法。FastText会自己训练词向量,同时采用层次化softmax和n-gram让模型学习到局部单词顺序的部分信息。
b.TextCNN。采用多通道CNN结构,经过嵌入层后词向量维度为300,经过卷积核尺寸分别为2,3,4,通道数为256的卷积层后,将输出的3个词向量拼接在一起,经过全连接层和softmax激活函数后输出结果。
c.LSTM。LSTM的结构为2层全连接层,隐藏层中神经元的个数为128,方向为双向;LSTM输出的词向量经过全连接层和softmax激活函数后输出结果。
d.DPCNN。深层金字塔卷积结构,采用图4中的结构设置。
e.Bert+DPCNN。采用谷歌提供的Bert模型作为预训练模型,下游任务连接DPCNN网络结构,参数设置与Roberta+DPCNN网络结构一样。
f.Roberta+LSTM。将Roberta模型中encoder层的输出作为LSTM模型的输入,得到输出,将此输出与Roberta模型中最后一层的输出拼接在一起,经过全连接层和softmax激活函数后输出最后的结果。
g.Roberta+TextCNN。将Roberta模型中encoder层的输出作为TextCNN模型的输入,得到输出,将此输出与Roberta模型中最后一层的输出拼接在一起,经过全连接层和softmax激活函数后输出最后的结果。
所有模型的实验结果对比见表3和表4,其中本文所提出的模型为基于余弦式调整学习率的方法。
THUCNews短文本分类中,无迁移学习的模型中FastText模型的效果最优。而在迁移学习的模型中,本文所采用的模型结合余弦式调整学习率的方法,所得出的结果在所有模型中最优,Fl值可以达到96.98%,比FastText模型高出了2.gg%,比使用Roberta+TextCNN高出了1.02%。在THUCNews长文本分类中,本文模型相比于无迁移学习的DPCNN模型,准确率高出了5.23%,比Roberta+LSTM模型高出了1.56%。在其他3项评价标准上,效果也明显优于其他模型。
THUCNews短文本分类中,无迁移学习的模型中效果最好的是FastText。这是因为FastText将短文本中的所有词向量进行平均,句子中的序列、语义和结构信息保存都较为完整。
在无迁移学习的模型结构中,长文本分类使用FastText模型,效果不如卷积神经网络和循环神经网络。其原因是n-gram结构所能获取的上下文语义信息不如神经网络模型结构完整。
使用预训练模型Roberta连接下游任务,模型的整体性能优于传统模型。这是因为预训练模型中的参数从海量数据中训练得来,相较于传统神经网络的自己从头开始训练,预训练模型的收敛速度更快,泛化效果更好。
学习率作为监督学习以及深度学习中重要的超参,决定着目标函数能否收敛到局部最小以及何时收敛到最小。合适的学习率能使目标函数在合适的时间内收敛到局部最小。表5为学习率衰减实验结果,从中可以发现,以Fl值为评价标准,Roberta模型使用余弦调整的方式分层调整其学习率,模型效果可以得到小幅度的提升。
从实验结果还可以看出,Roberta模型在放弃NSP任务后,得到的句向量和词向量的内容更为丰富。使用DPCNN和RGRU模型作为模型的深层特征提取层,能再次提取句子中的有效信息,模型的泛化能力得到了进一步增强。
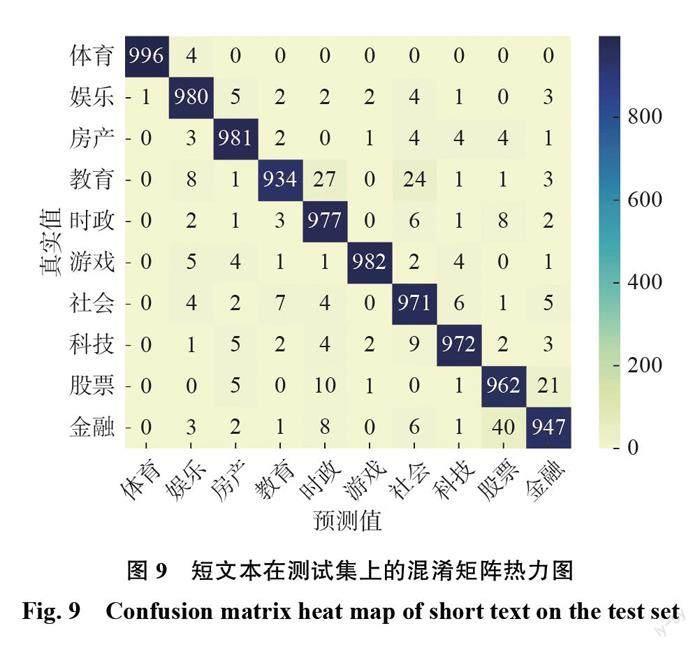
从图7和图8各个类别的F1值中可以看到,短文本分类模型中股票和金融类别的F1值较低,而长文本分类中只有金融这一个类别的F1值较高。从短文本中选取一部分相关性较高的数据(表6),结合图9,短文本分类里金融类被识别为股票类的有40个,股票类被识别为金融类的有21个,说明这两个分类在短文本分类模型里相互干扰较为严重。
针对THUCNews数据集出现的这种情况,在扩大数据集的同时,需要对数据进行进一步的预处理,同时也需要调整模型,使模型能更好地将不同的数据区分开来。如在序号为1的内容中,需要给予殴打、调查等动词更多权重,同时减少小学生、老师、区教委等名词的权重。
4 结束语
以预训练模型结构为基础,连接下游任务的模型结构,其性能优于无迁移学习的网络模型。本文使用了Roberta预训练模型连接下游任务的深层特征提取模型,同时针对Roberta模型、卷积神经网络和循环神经网络的特点,给予不同的学习率,分层调试其参数,最后得到的文本特征向量信息十分丰富。利用Roberta模型中掩码mask的策略,使得同一样本在每轮训练的时候,mask位置不同,提高了模型输入数据的随机性,得到更加符合语义环境的动态词向量,最终提升了模型的学习能力。
通过分析混淆矩阵,得出了当前模型中所存在的不足,下一步将会针对不同类别的数据权重进行研究,尝试将每个词的语义和类型融入到输入层中,进一步增强文本向量的表示信息。同时需要对模型的整体结构进行调整,找出能够提升模型效果的参数,使模型可以更加优秀地处理自然语言处理中的文本分类任务。
参考文献:
[1]CHEN P H, LIN C J, SCHLKOPF B. A tutorial on v support vector machines[J]. Applied Stochastic Models inBusinessandIndustry,2005,21(2):111–136.
[2]CHEN T Q, GUESTRIN C. XGBoost: a scalable treeboosting system[C]//Proceedings of the 22nd ACMSIGKDD International Conference on KnowledgeDiscovery and Data Mining. San Francisco: ACM, 2016:785–794.
[3]PENNINGTONJ,SOCHERR,MANNINGCD.GloVe:global vectors for word representation[C]//Proceedings ofthe 2014 Conference on Empirical Methods in NaturalLanguage Processing (EMNLP). Doha: Association forComputationalLinguistics,2014:1532–1543.
[4]JOSHI M, CHEN D Q, LIU Y H, et al. SpanBERT:improving pre-training by representing and predictingspans[J]. Transactions of the Association forComputationalLinguistics,2020,8:64–77.
[5]KIM Y. Convolutional neural networks for sentenceclassification[C]//Proceedings of the 2014 Conference onEmpiricalMethodsinNaturalLanguageProcessing.Doha,Qatar: Association for Computational Linguistics, 2014:1746–1751.
[6]陳珂,梁斌,柯文德,等.基于多通道卷积神经网络的中文微博情感分析 [J]. 计算机研究与发展,2018,55(5):945–957.
[7]YAOL,MAOCS,LUOY.Graphconvolutionalnetworksfor text classification[C]//Proceedings of the 33rd AAAIConference on Artificial Intelligence. Honolulu: AAAI,2019:7370–7377.
[8]HULM,YANGTC,SHIC,etal.Heterogeneousgraphattention networks for semi-supervised short textclassification[C]//EMNLP-IJCNLP 2019: Proceedings ofthe 2019 Conference on Empirical Methods in NaturalLanguage Processing and the 9th International JointConference on Natural Language. Hong Kong, China:Association for Computational Linguistics, 2019:4821–4830.
[9] LIUPF,QIUXP,HUANGXJ.Recurrentneuralnetworkfor text classification with multi-task learning[C]//Proceedings of the Twenty-Fifth International JointConference on Artificial Intelligence. New York: AAAI,2016:2873–2879.
[10]SHENYK,TANS,SORDONIA,etal.Orderedneurons:integrating tree structures into recurrent neuralnetworks[C]//7th International Conference on LearningRepresentations.NewOrleans:OpenReview.net,2019.
[11]王偉,孙玉霞,齐庆杰,等.基于 BiGRU-attention 神经网络的文本情感分类模型 [J]. 计算机应用研究, 2019,36(12):3558–3564.
[12]VASWANIA,SHAZEERN,PARMARN,etal.Attentionis all you need[C]//Proceedings of the 31st InternationalConference on Neural Information Processing Systems.Long Beach, California, USA: Curran Associates Inc. ,2017:6000–6010.
[13]FENIGSTEIN A. Self-consciousness, self-attention, andsocial interaction[J]. Journal of Personality and SocialPsychology,1979,37(1):75–86.
[14]BAHDANAU D, CHO K, BENGIO Y. Neural machinetranslationbyJointlylearningtoalignandtranslate[C]//3rdInternationalConferenceonLearningRepresentations.SanDiego,2015.
[15]CHENG K F, YUE Y N, SONG Z W. Sentimentclassification based on part-of-speech and self-attentionmechanism[J].IEEEAccess,2020,8:16387–16396.
[16]DEVLIN J, CHANG M W, LEE K, et al. BERT: pre training of deep bidirectional transformers for languageunderstanding[C]//Proceedings of the 2019 Conference ofthe North American Chapter of the Association forComputational Linguistics: Human LanguageTechnologies, Volume 1 (Long and Short Papers).Minneapolis: Association for Computational Linguistics,2019:4171–4186.
[17]孙红,陈强越.融合 BERT 词嵌入和注意力机制的中文文本分类 [J]. 小型微型计算机系统,2022,43(1):22–26.
[18]张洋,胡燕.基于多通道深度学习网络的混合语言短文本情感分类方法 [J]. 计算机应用研究, 2021, 38(1):69–74.
[19]JOHNSON R, ZHANG T. Deep pyramid convolutionalneuralnetworksfortextcategorization[C]//Proceedingsofthe 55th Annual Meeting of the Association forComputational Linguistics. Vancouver, Canada:AssociationforComputationalLinguistics,2017:562–570.
[20]SUNC,QIUXP,XUYG,etal.Howtofine-tuneBERTfortextclassification[C]//18thChinaNationalConferenceonChineseComputationalLinguistics.Kunming:Springer,2019:194–206.
[21]宋明,刘彦隆.Bert在微博短文本情感分类中的应用与优化[J].小型微型计算机系统,2021, 42(4): 714-718.
[22] LIN T Y,GOYAL P,GIRSHICK R,et al.Focal loss fordense object detection[J]. IEEE Transactions on PatternAnalysis and Machine Intelligence, 2020, 42(2):3 18-3 27.
[23] JOULIN A,GRAVE E,BOJANOWSKI P,et al.Bag oftricks for efficient text classification[C]//Proceedings of the15th Conference of the European Chapter of theAssociation for Computational Linguistics: Volume 2,Short Papers. Valencia: Association for ComputationalLinguistics, 2017: 427-43 1.
(编辑: 丁红艺)
