采油工程领域的数据清洗方法研究
2023-05-30吴运驰马庆宋波张永峰
吴运驰 马庆 宋波 张永峰

关键词: 大数据分析;油田数据;数据清洗;数据质量;贝叶斯反演
中图分类号:G642 文献标识码:A
文章编号:1009-3044(2023)03-0086-03
1 引言
随着数据存储设备飞速进步,以及分布式计算技术突破性的进展,原本只出现学术领域中的大数据、深度学习和人工智能等技术出现在大众日常生活的各个角落。大庆油田在信息化领域深耕多年,善于利用新技术、新方法提高油田管理水平。将大数据技术与油田数据相结合,指导生产,降本增效,可以进一步促进大庆油田向智能化、智慧化油田方向转型。大数据技术的核心是数据,数据质量直接决定了大数据分析的效果。
2 油田数据情况
大庆油田在信息化建设上已经布局多年,基础设施建设较为完善,建立了涵盖所有数据的统建系统,实现每日的生产数据实时上传,存储的数据量极大,但这海量的油田数据,却不能直接用于大数据分析,因为当前数据存在以下问题:
1) 低价值数据。随着石油不断产出,地下油层环境会不断变化,多年前的油水井产油产液数据、地质数据对于现在的产油产液量分析参考价值较低。
2) 数据存储位置分散。在油田公司推行统建系统之前,部分二级单位已经进行了信息化建设,建立了自己的数据库系统和软件系统,并已投入日常使用。在推行统建系统后,存在二级单位继续使用原有数据库的情况,许多数据分别存储在二级单位自建的数据库和统建系统中,数据获取难度较大。
3) 存在缺失值、异常值。随着大庆油田信息化进程的不断推进,统建系统中数据的完整性、及时性和准确性有了极大提升。但油田信息化早期录入的数据,由于当时操作环境的限制,存在部分数据缺失、数值异常等问题。
要从这些海量、复杂的数据中提取出有价值的數据,提高大数据分析的准确性,关键在于高质量的数据清洗。
3 常规数据清洗方法
针对这些数据量大、格式不一、包含重复值和缺失值的数据,常规的数据清洗方法通常包括:
1) 定期更新。通过连接目标数据库,设置定时任务,不断获取最新数据,为之后的数据清洗、分析、预测提供良好的数据支持。
2) 统一格式。将日期、数值、全半角、大小写等显示格式进行统一化处理,将原有列名修改为对应的中文名,去除数据中的空格。
3) 清理无效数据。由重复录入导致的重复数据,明显超出有意义的范围的数据,经过对比验证后,直接去除。
4) 缺失值填充。通过同类数据的均值、中位数或众数进行填充,关联性弱的缺失数据也可假定为0,或从数据来源的相关材料中提取补充。
通过常规数据清洗方法处理的油田数据,在使用大数据方法分析预测后,预测结果缺少明显的规律,效果较差。通过对处理后的数据进行比对后发现,由于油田统建系统中包含的业务类型复杂,并包含大量空数据,常规的数据清洗方法无法进行有效处理,导致最终结果不佳。
4 采油工程领域的数据清洗方法
对于常规数据清洗方法在油田数据的处理过程中遇到的难点,通过对数据范围,数据格式及缺失数据的深入研究,设计出一套针对性的处理方案,解决采油工程领域的数据清洗问题,并在压裂措施数据的处理上进行应用。
4.1 确定数据范围
大庆油田的统建系统中,包含了油田相关的所有数据类型,上千张数据表,部分数据项之间没有任何业务关联,不同数据表中的相同名称的数据项还会起到干扰作用,需要结合待分析业务的业务方式,选择与之相对应的数据表。
在压裂措施效果数据的选择上,通过与实际压裂业务相结合,选取了地质参数、井史数据、层位信息、生产数据、增产措施参数等20余张数据表,114项数据字段。
4.2 数据表合并
压裂措施效果通常以单井数据前后变化进行分析,所有相关数据需要通过井号串联在一起,而地层数据、井数据、生产数据的维度不同,需要增加和减少维度实现井号与相关数据项的一一对应。
1) 压裂数据处理
使用“井号/压裂日期/施工井段顶深/施工井段底深”产生联合索引并分组聚合,对数值型数据求和处理;
联合索引增加压裂类型、压裂液名称、支撑剂名称、压裂液类型、厂名信息,重新分组聚合,对string类型数据进行合并处理;将处理后的数值型数据和字符型数据进行合并操作。
2) 地层数据选取与处理
通过井号将层位数据和射孔数据合并,计算合并结果中“| 砂岩顶深”-“井段顶深”|,差值绝对值结果小于等于0.2,采用层位表对应数据,差值大于0.2,则使用射孔表中的对应数据。
3) 压裂与地层数据合成处理
将之前处理好的压裂数据与地层数据通过井号进行合并;
用“井号”“/ 施工井段顶深”“/ 施工井段底深”生成新数据字段“index”;
将“index”和“有效厚度”两列数据按照“index”进行分组加和操作,合成新的有效厚度;
将渗透率、孔隙度、含油饱和度与有效厚度的乘积,分别与“index”进行分组加和,得到的结果与新生成的有效厚度相除,合成新的渗透率、孔隙度与含油饱和度;
将上述步骤生成的新表与压裂数据通过“index”进行合并,去除存在空值的行数据即完成压裂地层数据合并。
4) 压裂地层数据与井史数据合并
通过压裂地层表中的井号对井史生产数据进行筛选;根据压裂地层表中的“压裂日期”信息,对已经按照井号筛选出来的井史数据进行再次筛选,计算出7天、180天、360天的各种产量数据;将计算出的产量数据与压裂地层表合并,得到最终的压裂数据总表。
4.3 相关性分析
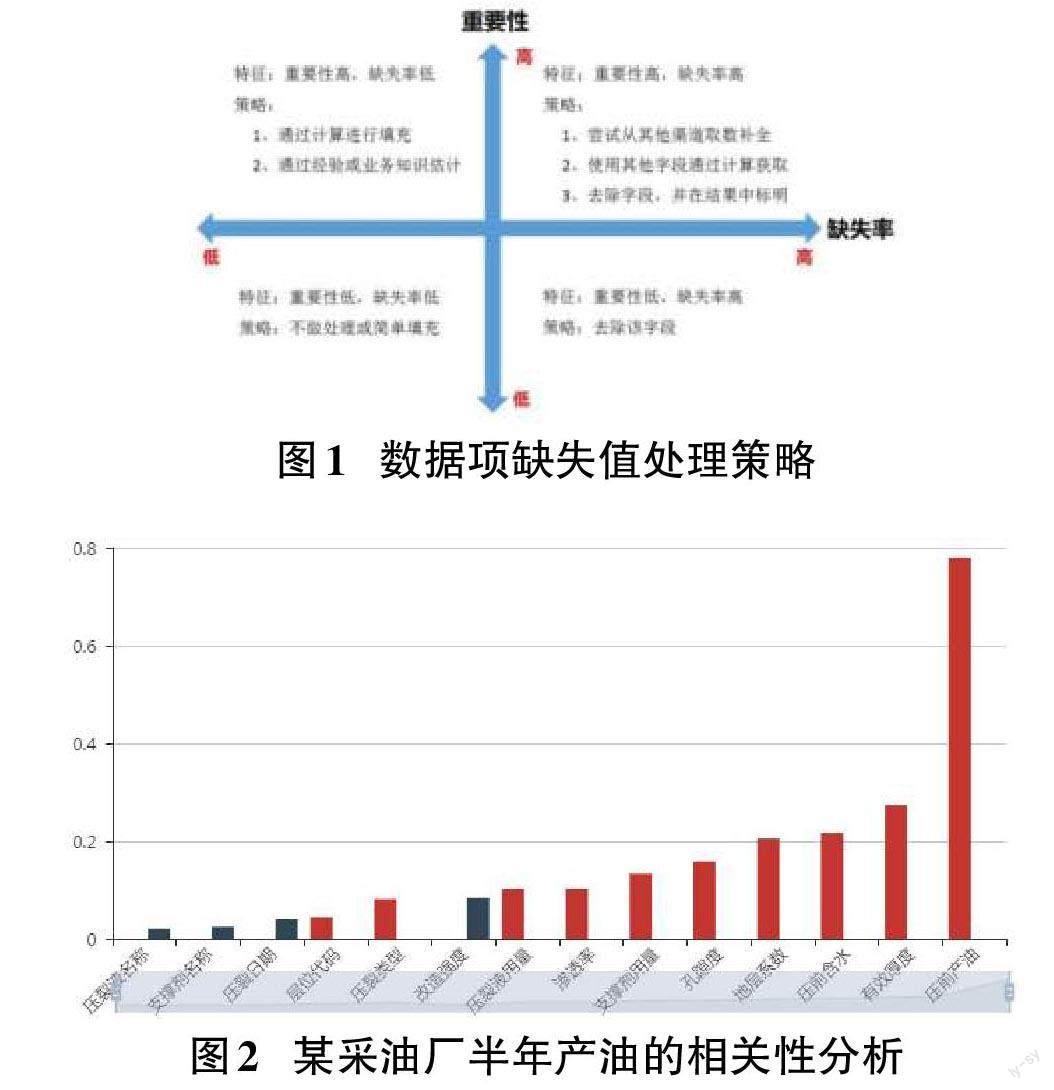
由于数据表中存在大量缺失数据,对缺失数据的处理方法尤为重要,与业务关联性高的数据要重点处理,关联性不强的数据根据后续分析结果再决定是否补全。
判断数据项的重要性,必须明确待分析的对象,及分析结果的评价标准。压裂效果是否良好,注重的是压后产量情况,通过皮尔逊系数和协方差进行相关性分析,将压后产量数据作为目标值,将其他数据与产量数据的相关性进行排序,通过排序结果划分字段的重要程度。
4.4 缺失值处理
结合相关性分析结果与缺失值处理策略,制定了三种缺失值填充方法:均值填充、业务资料填充、贝叶斯反演填充。
4.4.1 均值填充
孔隙度、渗透率、含油饱和度、有效厚度等地层数据,在相同区块,相同层位数据基本一致。使用区块、层位数据进行筛选,将相同区块、层位的缺失数据以已有数据的均值进行填充。
4.4.2 业务资料填充
压裂措施数据中压裂液名称、压裂液用量、压裂类型等缺失数据,可以通过压裂井的设计、施工总结等文档材料进行填充。
4.4.3 贝叶斯反演填充
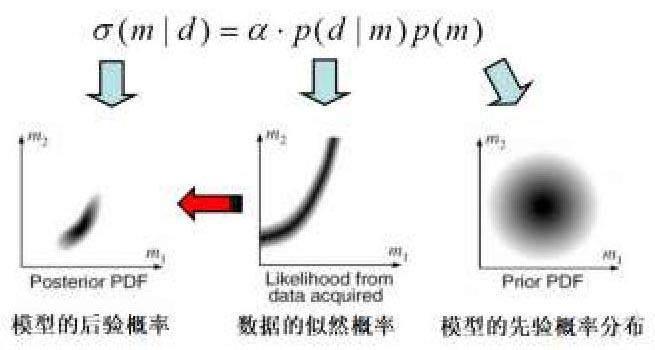
反演是指由結果出发去确定参数,解决参数无法直接获取的难题,一个优秀的反演模型,可以通过产量数据推算出地层数据及措施数据。贝叶斯反演的优势:
1) 充分利用先验知识,可以用多维概率密度函数的形式(例如高斯分布)来描述模型参数的先验知识。
2) 在先验信息的背景上,根据观测数据,缩小模型参数的分布范围,获得反演问题的解的后验概率密度分布。
3) 后验概率分布揭示了模型参数值的最可能分布。
贝叶斯定理:
P(m):模型参数的先验概率分布;
P(d):地质条件的先验概率分布,可视作常数;
P(d | m):给定模型参数条件下的似然概率;
σ(m | d):组合先验信息和似然概率得到的模型参数后验概率;
反演结果是否在合理的范围内,通过模型的均值、方差和后验概率分布来评价和预测反演结果,彻底脱离对人工判定的依赖。
贝叶斯反演方法的主要流程如下:
1) 根据地质参数、措施参数和生产数据的相关性,确定出反演模型的先验概率分布;
2) 将参数的先验概率分布作为约束条件,建立初始模型;
3) 使用模型进行正演模拟,并计算模拟结果与观测数据的能量值及似然函数;
4) 如果模型结果符合要求,则保存模型,然后修改模型参数建立新模型;
重复步骤3、4得到更多的模型样本。
对所有反演出的模型样本进行统计计算,得到模型的均值、方差和后验概率分布;
最终得到的均值模型与原始模型的相关性高,在数据有噪声的情况下仍能给出准确的结果。
通过上述针对采油工程领域数据的清理方法,将原本位置散乱、缺失值多、格式各异的油田数据整理为种类多、相关性强、数据量大的优质数据,对压裂措施效果进行分析预测时,较未处理的数据,分析结果准确性有显著提升。
5 结论
高质量的数据清洗是利用大数据技术辅助决策者做出正确策略的重要前提。目前国内外现有的数据清洗方法往往是应对常见数据的通用方法,在对海量多源异构的油田数据的处理上,效果不佳。结合采油工程领域的专业知识,通过数据范围选取、数据格式整理及缺失数据填充,形成了一套针对采油工程领域的数据清洗方法。
结果表明,本文方案对油田数据进行处理后,对比普通数据清洗方法,在大数据分析预测中具有明显优势。
