不定长数据中识别模糊文本的数据加载方法
2023-05-29苗小爱
苗小爱
(青岛酒店管理职业技术学院,山东 青岛 266100)
0 引言
随着CRNN[1]的诞生,文本识别相关应用越来越多,当前很多研究者在CRNN 模型基础上,针对损失函数[14]、学习率下降方法[15]、数据加载方法[16],以及骨干网络[17]选择、优化[18]方法选择等做了很多调整,模型效果不断变好。但是在处理特定场景下的数据集时,由于无法使用固定宽、高的图像数据进行训练,训练数据量有限且图片中需要识别的文本过于模糊,背景也复杂多样(见图1),因此常常无法通过改变骨干网络、损失函数和优化方法以有效提高CRNN 识别准确率。
复杂背景下模糊文本图片实例如图1 所示,图1(a)和图1(b)有3 个字,图1(c)有4 个字(在现实数据集中数据文字数量从1 到15 不等),而且“收货方”文本被印章覆盖,“合同号”文本缺少笔画,“存货名称”则十分模糊,数据集中图片的宽高比从1~12(经处理后)不等。因此,为得到更好的训练效果和模型,需修改数据集加载部分。
图2 是在背景填充后作灰度化处理后进行放缩的效果,可以看出,使用近似背景填充几乎分辨不出填充部分。图3 是进行补0 的填充放缩操作,可以发现,填充部分像素值与文本相近,与背景相差较大。图4 是直接放缩效果,可以看出,放缩后的图片文本变形,不利于训练计算。由此可知,图2(本文提出的数据加载方法)模型计算最好。

Fig.1 Example of blurred text picture under complex background图1 复杂背景下模糊文本图片实例

Fig.2 Scaled rendering of grayscale after approximate background filling图2 近似背景填充后灰度化放缩效果

Fig.3 Scaled rendering of grayscale after filling with 0图3 补0填充后灰度化放缩效果

Fig.4 Directly zoom the rendering after grayscale图4 灰度化后直接放缩效果
基于CRNN 的模型经常使用两种常见的数据加载方法:①直接对图片进行指定比例的放缩,依靠骨干网络强大的拟合能力映射到指定文本,但是由于同一文本在不同维度下放缩后的图像发生形变,模型最终效果相对较差;②将图片进行减均值的标准化操作后填充0,使图片在相同的放缩比例下进行操作,这样训练时模型会将填充部分作为负样本,但是填充的数据十分突兀,对负样本的像素值十分接近需要时的文本,导致部分负样本向正样本倾斜。这种填充方式在文本文数据大小相差不是很大时效果很好,但数据相差较大时就会产生较差的效果。在本文数据中,由于短文本过多,且一些合同中协议部分文本较长,需训练一个可以识别长文本又能很好处理短文本的模型。因此,本文在数据加载过程中进行修改如下:
修改加载数据的放缩比例,平衡正负样本。对短样本使用近似背景填充后放缩到指定宽高比例,对接近指定宽高比(设置超参数进行指定)的样本进行放缩时不进行背景填充。在进行推理时,直接进行识别便可以得到很好的效果。最后,通过实验对比发现,本文设计的数据加载方法相比常用的数据加载方法有更高的识别准确率和更快的训练收敛速度。
本文主要贡献有两个:①通过构建近似背景填充的方式进行数据加载,提高模型识别准确率并提高训练收敛速度;②设定不填充比例加强文本图像的多样性(还原真实场景下的文本形状变化)以辅助模型识别准确率提升。
1 国内外研究现状
目前,国内文本识别领域中效果最好、速度最快的是百度的PPOCR[2]项目,通过阅读PPOCRv2 的源码发现它在数据加载时默认使用将图片进行标准化后填充0 的数据加载方式。目前,文本识别方法主要分为两种类型。一种是语义上下文无关方法,其中以CRNN 最为典型,它是结合CNN 和RNN 的网络主体,用CTC[3]解码器计算损失构建的文本识别模型。Xie 等[4]提出汇聚交叉熵(aggregation crosentropy,ACE)损失,优化了每个字符在时间维度上的统计频率,提高了识别效率。另一种是上下文感知方法,主要有效果突出的SRN[13]模型,该模型利用并行Transformer[5]和CNN 结合的方式作为主体,使用FPN[6]进一步提取特征,在兼顾检测速度的同时获得很好的识别效果。ASTER[7]同样针对Attention 模型进行优化,并提高了模型识别效果。上述模型在进行研究和建模过程中均会广泛使用到标准化后填充0 的数据加载方式或者直接放缩的数据加载方式。在处理模糊文本时,直接使用现有的模型和产品效果均不佳,因此本文提出针对模糊文本、复杂背景的近似背景填充数据加载方法。
OCR 识别主要包括文本检测和文本识别。在检测出文本行或文本区域后截取文本区域数据,识别文本特征,进而识别出文本内容。目前流行的检测模型有DBNet[8]、PAN[9]、craft[10]等,检测出的文本一般有倾斜或者弯曲等多种形态。针对本文场景,主要检测单据文本,并识别文本行数据,但由于低像素值的问题导致文本识别难度变大。因此,本文设计一种更好的数据加载方式,在均衡正负样本的同时,能够突出有效的文本数据,从而极大减小文本检测难度,提高文本检测准确率。
2 算法设计
2.1 正负样本均衡
在构建近似背景填充时,首先计算在不同宽高比时正、负样本的比例。因现实场景中存在长文本,模型的输出大小不能太小,故选取了宽高比为4~12 比例范围。本文数据集中数据的正负样本占比如表1所示。

Table 1 Proportion of positive samples表1 正样本占比
正负样本占比是正样本(文本所在部分)占据图像的比例,负样本(无文本部分)占据图像的比例。由表1 可知,在宽高比为9 时,数据集的正、负比例分布最为均匀,近似为1∶1,因此固定放缩的宽高比例为9。此外,为证明正负样本均衡能使识别模型取得更好的效果,在下文进行实验对比(结果见图6)。
2.2 不填充比例设置
不填充比例设置是指当某些图像原始的宽高比在指定宽高比(本文为9)附近时,将图片直接放缩到指定的宽高比不会影响图中文字的质量,使图像中文本明显变形,避免相同文本特征大小不同而出现偏差的问题。因此,这部分数据可以直接进行放缩以丰富正样本空间,进而加强特征提取。
通过观察不同指定宽高比下,图片放缩不会影响文本质量,选取合适的不填充比例。经过实验表明,当指定宽高比为9 时,原始宽高比为7、8、11、12 的图片放缩到9 之后都不会产生肉眼可见的变形,经计算得出,选择向下不填充比例为7.8,向上不填充比例为11。
为证明设置不填充比例效果,本文在直接放缩对比实验的基础上,添加向下不填充比例为7、7.2、7.5、8 的对比实验以证明本文指定的不填充比例效果。根据数据的独特性,在指定宽高比减一到指定宽高比减二之间进行选择,若数据指定宽高比较大,则可适当扩大不填充比例设置范围。
2.3 近似背景填充
采用近似背景填充是为避免使用一个突兀的背景填充图像。虽然用一个全0 或全255 的像素值进行背景填充能达到构建负样本的目的,但会产生两个问题:①样本本身会存在少量负样本,若使用统一为0/255 进行填充则会在计算时忽略真实负样本的特征;②由于文本本身背景与负样本是近似或相同,若全为0/255 填充背景则会导致文本背景分离效果差。
针对上述问题,本文构建一个近似背景填充的方法,步骤如下:①将原图像按照指定高度,原始宽高比放缩;②获取当前图片中前16 个像素(从左上角开始)组成的正方形区域中像素值最大的像素(所需检测的文本颜色较深,像素值较小,因而取最大值为背景填充);③计算放缩后图片的宽度与指定宽度的差,当原始图片宽度小于指定宽度时则进行背景填充,将步骤②获取到的像素填充到指定宽度。算法设计如下:
算法1 近似背景填充

其中,r表示指定宽高比,selectFromTop16 表示从前16个像素的正方形区域中获取填充像素值,max 表示获取最大的像素值,resize 表示对图片进行放缩,filling 表示对图片使用指定像素值进行填充。将在下文实验证明,本文设计的近似背景填充收敛速度更快、识别准确率更高。
2.4 模型构建
设计好数据加载方法后,构建识别模型进行效果验证。本文实验选用CRNN 模型,识别准确率和训练收敛速度都在CRNN 模型上通过对比分析得到。本文没有使用较为复杂的ResNet18[19]或更复杂的ResNet31、ResNet50 等骨干网络,使用CRNN 原文中建议的VGG16[11]。VGG16网络结构层数较少、复杂度较低、训练较快,便于实验对比。模型设计步骤如下:
(1)构建配置文件。配置所使用的骨干网络层,指定模型使用的宽和高,指定数据加载方式,配置学习率以及学习率的调整方法,指定优化函数对损失函数进行优化,最后配置超参数。
(2)数据处理与加载。数据处理与加载是模型计算之前的必要步骤,由于收集到的数据不规范且不利于模型计算,因此需要进行一定的图像处理后再将其加载到内存中进行计算。首先将数据进行指定比例的放缩,这里采用本文提出的近似背景填充方法;然后对图像进行减均值和除以255 的操作,将图形标准化到一定范围内,便于网络计算;最后根据文本图像特点进行灰度化处理,将处理后的数据加载到计算机内存中。
(3)模型设计。构建好配置文件并做好数据处理与加载之后,对模型进行设计,用设计出的模型对数据进行计算,训练出能够进行文本识别的模型参数,CRNN 模型的主要架构包括VGG16 和BiLSTM[20]。VGG16 是一个16 层的CNN 网络模型,能够提取深度图像特征映射,对图像中的文本进行有效的向量表示,然后根据文本的语言特征使用循环神经网络中的BiLSTM 进行下一步计算。本文构建了一个两层的BiLSTM,根据文本的时序特征预测每一个文本字符。
(4)CTCLoss 损失。由于本文使用的数据是一个不定长的图像文本数据集,因此需要在计算过程中对文本进行自动对齐,以防止识别出的文本出现多一个字符或少一个字符的情况,CTC 算法采用动态规划方法对文本图像进行有效的对齐操作。计算出的CTCLoss 就是文本识别的损失,得到损失函数后使用Adam 算法进行梯度下降以优化权重矩阵[12]。
在训练过程中根据超参数中的批次大小加载数据,执行上述步骤(1)—步骤(4),在指定的epochs 内进行一次又一次的网络训练,并在训练中保存最优结果,算法设计如下:
算法2模型构建算法

Model_Weight 是最终计算的模型参数,也称为文本识别模型,ABF 表示算法1,即近似背景填充算法,means表示图象均值,dataLoader 表示数据加载器,images.next()表示获取下一个批次的图像数据。
3 实验比较
将本文的近似背景填充方法与填充0 的方法以及不填充只放缩的方法进行比较,评价标准是校验准确率和训练收敛速度。在数据集上保证相同的实验设置,通过实验证明了本文所设计方法的有效性。
3.1 数据集
本文使用的数据集有两种:①自行收集的单据数据,由于数据未经过其他形式的清洗,因而存在清晰模糊数据并存、背景复杂多样、像素值跨度大等问题,使得收集的样本数据十分复杂;②百度收集并处理的360k 数据集,数据样式多,但数据样式规整。本文针对中文数据进行建模,主要收集中文文本数据集。
本文收集拍照的单据、pdf 合同图像数据,pdf 样式的合同易于计算分析,文字为黑色、背景为白色,特征明显,易于区分。主要分析单据数据,按照背景划分为3 种:①如图1(c)所示模糊的灰色背景;②如图1(a)所示蓝色的存单;③如图1(b)所示带有红印覆盖的单据。此外,如图1(a)约100 份单据中几乎每张单据都会存在文本部分缺失的情况,如图1(b)约100 多张单据中部分文本会被红盖住影响识别。剩余100 余张数据中都是文字模糊与背景像素接近的情况,在这类数据中也存在部分文本清晰的图像数据。由于已经训练好文本检测模型,因此使用设计好的文本检测模型截取数据集。在收集好数据集之后,将数据按照80%的训练集和20%的测试集进行划分。最后训练集有文本图片2 176 张,测试集有480 张,在百度360k 的预训练模型上进行微调。
本文针对手机拍照上传的模糊图像(尤其像素较低的手机),因此数据场景有限,但是为证明模型在标准数据集上的有效性,本文还使用了百度整理的360k 中文数据集进行实验分析。其训练数据集有80%,测试数据集有20%,都是从各种书本上截取的文本数据,经过百度技术人员的处理,所有图片数据宽高分别为280 和32,每个图片10个文本。
3.2 实验设置
本文的识别模型为CRNN,骨干网络是VGG16[11],训练轮次为5 000 次,批次大小为32,初始学习率为0.000 1,优化方法为Adam[12](其中betas 为(0.9,0.999)),学习率下降方法为按步下降[21],每500 轮下降为上一轮的80%。为保证实验对比的公平性,在所有实验中采用相同的设置。
3.3 实验结果与比较
首先构建基于VGG16 骨干网络和BiLSTM 的CRNN 模型并进行训练,在训练过程中分别使用3 种数据集加载方法计算模型识别准确率和训练收敛速度,并进行比较。实验设置如下:①CRNN 模型使用数据标准化填充0 的数据加载方式;②CRNN 模型[1]使用不填充的直接放缩数据加载方式;③PPOCR 模型[2]使用数据标准化填充0 的数据加载方式;④CRNN 模型使用近似背景填充的数据集加载方式。
本文每训练500轮记录一次实验准确率以进行准确率和收敛速度比较。实验结果如图5所示。
在本文数据集上,如图5(a)所示,使用背景填充的数据加载方式不论是训练准确度还是收敛速度都快于使用0填充的数据加载方式以及不进行填充的数据放缩加载方式。图5 中训练轮数乘以10 是真实训练轮数,准确率是百分比。从图5(a)中可知,基于背景填充的方法在5 000 轮之前就已达到收敛,其准确率为85.89%,基于填充0 的数据加载方法的CRNN 模型在第8 000 轮之前收敛准确率为84.22%,基于不填充直接放缩的CRNN 模型在10 000 轮之前收敛准确率为83.15%。实验结果表明,均衡正负样本后的数据加载方式不仅能够更好地表现数据特征、有更高的准确率,还能加快模型收敛速度。在百度360k 数据集上,如图5(b)所示,所有设置与图5(a)相同,表明使用本文数据加载方式准确率高达99.37%,取得与PPOCR 极为相近的效果。但是,仍然比其他数据加载方式训练模型效果高,这表明在标准数据集上,面对大量清晰的文本图片,本文模型仍然具有鲁棒性。
3.4 不同正负样本比例效果比较
本文设计的数据加载方式主要面向中文、模糊文本、复杂背景情况下的不定长文本数据识别,以下实验结果是在收集的单据、合同数据集上进行比较分析得到。
在证明近似背景填的数据加载方法均衡正负样本后能够提高模型识别准确率后,正负样本比例即填充背景后数据宽高比的选择极为重要。本文选择的是9(正负样本比例为1∶1),为证明宽高比为9 时模型效果最佳,本文分别选择宽高比为7、8、10、11、12 时的近似背景填充方法进行比较。这里仍进行5 000 次实验,每500 次记录一次准确率。
如图6 所示,宽高比为9 时,正负样本比例1∶1,此时最为均衡,实验效果最好,模型收敛速度也最快。宽高比为8和10 时识别准确率分别达83.69%和83.57%,效果与宽高比为9 时最相近,宽高比再变大或者变小时准确率效果相对较差。实验证明,正负样本最为均衡时(宽高比为9)模型识别准确率最高。因此,固定宽高比大小设置为9,正负样本均衡为1∶1时在实验和理论上效果最好。
3.5 不填充比例效果比较

Fig.5 CRNN accuracy comparison图5 CRNN准确度对比

Fig.6 Approximate background filling effect under different aspect ratios图6 不同宽高比下近似背景填充效果
设置不填充比例的原因有两个:①尽量保证初始的正样本数量,减少因为近似填充带来的数据误差;②由于较小比例差距的放缩不会使文字发生明显形变,并且这种放缩属于现实中存在的正常文本样式,也会使数据集包含更多的文字样本。但是不同程度的不填充比例,会得到不同程度的放缩样本,因此针对不同的数据集可能会有不同的效果,对于不同的宽高比、不同的不填充比例也会有影响。因此,本文针对复杂背景下的不定长模糊文本数据进行实验,针对不同的不填充比例进行比较,实验结果如图7所示。
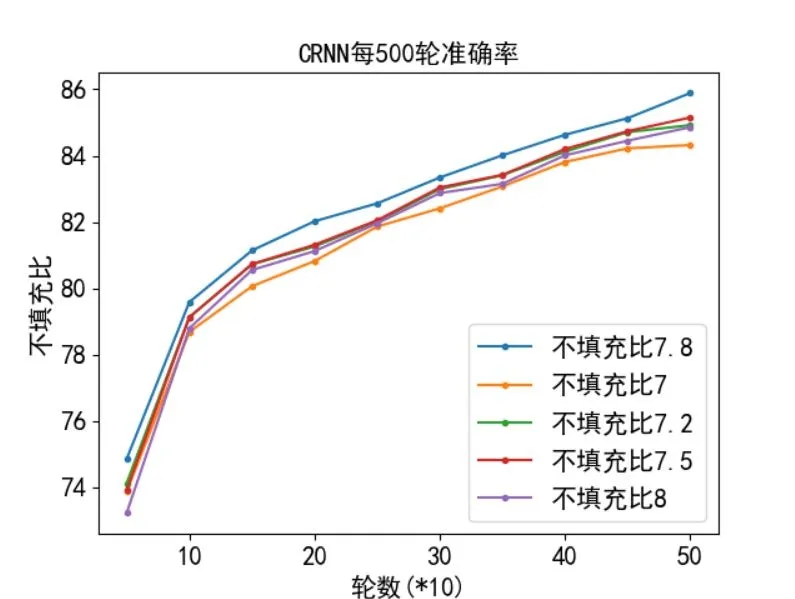
Fig.7 Comparison of the realization effects of different unfilled ratios图7 不同不填充比例的实现效果比较
由于本文设定的宽高比为9,以上下比例范围2 作为不填充比例,这里以不填充比例为7、7.2、7.5、8 的实验进行比较。同样地,训练5 000 轮,每500 轮记录一次结果。如图7 所示,在填充比例为7.8 时最快达到最高识别准确率,在放缩比为7 时则效果最差,因为不填充比例离固定宽高比越大,则识别准确度越低。在7.2 和7.5 时效果最为接近,再继续训练得到的结果与不填充比7.8 的实验结果极为相近。当不填充比为8 时由于引入的原始数据量减少导致最后结果变差,因此本文针对收集的数据选取不填充比例在(7,8)之间,选定为7.8。
3.6 有效性分析
(1)近似背景填充有效性分析。本文设计的数据加载方式旨在解决模糊文本的识别问题,因为文本相对模糊甚至于部分文本与背景像素值相近,若直接进行黑边和白边的填充会导致网络计算时特征计算不准确,造成识别时出现误识别和多识别的问题。本文采用的近似背景填充方法是根据对数据的大量观察、分析提出的设计思路,根据观察发现文本图像4 个角附近的背景信息最为明显,因此在取到宽和高各为4 个像素点的左上边缘区域时,像素中值最大的一个像素点必定是真实背景中存在的像素点。将该像素点作为背景填充,在训练和推理时对图片进行放缩后进入网络模型计算,以此保证网络分析每个像素点时不会因为填充0/255 等与文本像素值十分相近而与背景像素值相差较远的问题导致误识别和多识别问题的发生。
(2)正负样本比例设定有效性分析。本文从经验和实际情况出发,将正负样本比例设定为近似1∶1。首先从经验出发,从表1 可以观察到,在设定不同宽高比时正负样本比例不同,图3 利用实验证明,在设定宽高比为9,正负样本比例近似1∶1 的情况下模型效果最好。从理论出发,研究者们早期进行图像分类时也会保证不同类图像的数量,从早期的猫狗数据集开始,假设以狗为正样本,猫为负样本,则两种图像数据的比例为1∶1,再到ImageNet 等多类数据集,都是保持各类图像数量相等。当出现正负样本不均衡时,科学家们也会采用数据增强、采样或较少数据的方式进行样本均衡。因此,本文样本均衡设计也符合数据集收集和和处理的理论依据。
3.7 模型实际使用效果分析
本文是在真实应用的模型构建中提出的数据加载方法,因此以真实场景下的单据合同识别作为依据。由于是手机拍照,因而数据仍然存在模糊问题,目前已经在测试环境下进行测试。为验证3 种数据加载方式的计算效果,在测试环境下用SpringBoot 后端进行字段识别准确率统计,根据识别的字段和纠错的字段计算出每张图片的识别准确率然后取均值,获得一段时间内的计算准确率。
本文在测试环境下使用100张未参与训练的新单据和合同数据进行测试,经过系统取数发现,使用直接放缩的数据加载方式获得平均为86.78%的实际准确率,使用0 填充的数据加载方式获得平均为88.89%的实际准确率,使用本文设计的近似背景填充的数据加载方式获得平均为94.44%的实际准确率。
4 结语
通过实验比较发现,在使用CRNN 识别复杂背景、模糊文本的不定长数据集时,可使用近似背景填充的方法提高识别准确率并加快训练收敛速度。相较于对图像数据标准化后填充0 或者直接放缩这两种方式,本文取背景像素点进行近似背景填充的方法效果要好。结合不填充比例的辅助计算,目前本文模型在自己收集的数据集上效果比其他数据加载方式要好,甚至优于PPOCR 的效果,在百度360k 标准数据集上,也取得不逊于PPOCR 的效果。在面临一些复杂的不定长数据集训练时,可以使用这种背景填充的数据加载方式以均衡正负样本,从而提高识别准确率并加快训练收敛速度。
目前,本文使用的数据加载方式只是在语义上下文无关方法的CRNN 模型上进行实验,之后将用于一些语义上下文相关关方法(如SRN)进行实验。此外,针对OCR 系统优化,将通过为模糊文本构建高分辨率图像的方式优化数据集,并开展模糊文本的进一步特征提取工作。
