基于TPE_XGBoost的冠心病风险评估与致病因素研究
2023-05-29郎许锋周作建李红岩万泽宇朱金阳何佳怡郑永明胡孔法
黄 敏,郎许锋,周作建,李红岩,万泽宇,王 锐,程 俊,朱金阳,何佳怡,郑永明,胡孔法,3
(1.南京中医药大学 人工智能与信息技术学院,江苏 南京 210046;2.南京中医药大学附属连云港中医院,江苏 连云港 222000;3.江苏省中医药防治肿瘤协同创新中心,江苏 南京 210046)
0 引言
《中国心血管健康与疾病报告2021》指出,目前心血管疾病高居我国居民总死亡原因的榜首,且冠心病的死亡率和患病率仍在增加[1]。冠心病的病因构成十分复杂,通常是由多种危险因素引起的。因此,对冠心病患者进行风险评估,尽早干预,通过消除危险因素可预防或延迟冠心病的发生或死亡。另外,对健康人群进行风险评估,及时根据评估报告调整饮食、作息等习惯,也可以有效预防冠心病的发生。
近年来,机器学习被许多研究人员运用于心血管病、肾病、乳腺癌、代谢疾病等领域的风险预测中,其对临床疾病的诊断具有积极作用。齐俊锋等[2]采用随机梯度下降、logistic 回归等6种算法构建湖北省心血管疾病风险预测模型,其中LightGBM 模型最优,预测性能最好,前4 个危险因素依次为收缩压、脉压差、舒展压、年龄,但其对所有心血管疾病一起进行研究,存在一定局限;宋亚男等[3]利用解放军总医院糖尿病数据,对比随机森林、logistic 回归、XGBoost(Extreme Gradient Boosting)3 种算法,得出最优算法——XGBoost 算法,并构建2 型糖尿病患者并发视网膜病变预测模型,得到危险因素为合并肾病、糖化血红蛋白、血尿素水平;李慧等[4]基于公开数据集,采用SMOTE 算法平衡数据集,再使用lasso 算法进行特征选择,最后利用随机森林构建乳腺钼靶钙化灶的良恶性预测模型,具有一定可靠性,但精确率不高。
目前,利用机器学习进行冠心病风险预测被广泛应用,虽具备较好性能,但可解释性较差,对疾病的防治意义有限。此外,由于真实临床数据量小,一般来说,机器学习算法优于深度学习算法[5]。因此,本文选用经典机器学习中的XGBoost 方法进行建模来预测冠心病,同时利用SHAP 算法分析不同特征对冠心病的重要程度,提升模型的可解释性。与上述研究相比,本文使用了真实数据集,具有较高可靠性,且仅研究了心血管疾病的一个分类,具有针对性,同时具有较强的可解释性。
1 模型构建方法
基 于TPE_XGBoost(Tree-structured Parzen Estimator_Extreme Gradient Boosting)的冠心病风险评估及基于SHAP 的特征解释模型构建流程如图1 所示,其构建过程包括数据预处理、基于TPE_XGBoost 的风险评估模型构建与优化、基于SHAP 的特征解释模型构建。
首先,由于原始体检数据中部分生化指标缺失严重,因此首先通过特征选择、缺失值处理、数据标准化对体检数据进行预处理;然后,利用该数据建立XGBoost 预测模型,因XGBoost 模型的超参数众多,故针对此模型进行基于TPE 的贝叶斯优化,以自动优化其超参数,从而提升TPE_XGBoost 冠心病风险评估模型的性能;最后,通过SHAP 解释模型对特征进行分析,获得不同特征对模型预测的贡献度,提高模型的可解释性。
1.1 XGBoost模型
XGBoost 是一种能够实现分类与回归的Boosting 集成学习算法[6],由多个弱学习器迭代学习实现强学习器。XGBoost 目标函数包括损失函数和正则项两部分,本质是对梯度提升决策树的改进[7-8]。XGBoost 对损失函数使用二阶泰勒展开,可以有效控制模型过拟合,提高预测精度[9-11]。正则项可以提升单颗树的泛化能力。
1.2 贝叶斯优化
贝叶斯优化(Bayesian Optimization,BO)是一种基于概率分布的全局优化算法[12],用于解决最优化问题[13],以求得XGBoost的超参数最优解,如式(1)所示。
其中,x表示d维决策向量,X表示决策空间,f表示目标函数。在本文中,x为XGBoost 预测算法的超参数组合,f(x)为准确率高低的测度。贝叶斯优化主要包含两个核心部分:概率代理模型和采集函数[14-15]。本文的概率代理模型为树形概率密度估计[16]。
1.3 SHAP解释模型
SHAP(Shapley Additive Explanations)是 由Lundberg等[17]提出的用于解释黑箱模型的一种解释框架,广泛应用于解释医疗和社会现象[18]。SHAP 基于博弈论和局部解释,通过计算每个特征的Shapley value,以此衡量每个特征对预测结果的贡献度[19]。如式(2)所示,其中g表示解释模型,M表示特征数目,z表示该特征是否存在,φ为每个特征的Shapley value。当φi>0,说明该特征对模型结果有正向作用,反之,说明该特征对模型结果有负面影响。
2 模型构建及对比实验
2.1 实验环境
本文使用人工智能实验室服务器进行训练与测试,具体配置如表1所示。

Table 1 Specific configuration of experimental environment表1 实验环境具体配置
2.2 评价指标
为了评估本文构建模型的优劣,采用5 项常用的机器学习分类指标,分别为:准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 值(F1-score)及AUC 值(Area Under Curve,AUC)。准确率、精确率、召回率和F1 值可通过混淆矩阵进行表示,如表2所示。

Table 2 Confusion matrix表2 混淆矩阵
这些评价指标的相关公式如式(3)-(8)所示。
2.3 数据及其特征工程
2.3.1 数据来源及纳入规则
本文的数据集来自南京中医药大学附属连云港中医院的体检数据,该数据集包含2017-2021 年体检人群的基本信息、体检项目、体检报告、体检问卷等信息,包括58 602例健康人群和674 例冠心病患者。数据共包含216 个特征和1个标签,是否患冠心病是一个二分类问题,为处理缺失特征、选择高相关性特征、提高模型泛化能力,本文采用特征选择、缺失值处理和数据标准化方法进行预处理。
健康人群虽某次体检未有异常,但是存在既往病史,例如患甲亢、糖尿病在服药等情况。既往病史的复杂背景或其接受过的治疗可能影响研究结果的准确性,故删除有既往病史的人群,总共有16例。
2.3.2 特征选择
为了方便大众随时随地都可得知自己将来是否会患有冠心病,选取不用去医院即可测得的数据,分别为收缩压、舒张压、体重指数、低密度胆固醇、高密度胆固醇、总胆固醇、空腹血糖、甘油三酯和尿酸,同时纳入人口统计学变量:性别和年龄。
2.3.3 缺失值处理
分别将未患冠心病和患冠心病的数据进行缺失值的可视化,如图2、图3 所示。白色线条越多,说明数据缺失越多。从图2、图3 可以得知,除性别和年龄外,其他特征都有缺失。其中,患冠心病的人群特征缺失较少,缺失最多的是体重指数,达到8.2%,未患冠心病的人群特征缺失较为严重。由于部分病人的重要特征缺失,采用算法自动进行填充可能对分析结果造成较大影响,因此本文直接将生理指标缺失严重的样本删除。

Fig.2 Feature absence of individuals without coronary heart disease图2 未患冠心病人群特征缺失情况

Fig.3 Feature absence of individuals with coronary heart disease图3 患冠心病人群特征缺失情况
2.3.4 数据标准化
根据医院体检系统里给定的参考范围对数据进行划分,划分标准如表3 所示。其中,a为参考范围中的最小值,b为参考范围中的最大值,x为特征值。
2.4 与其他机器学习模型对比
为了更好地验证本文模型的优越性,将本文模型与9个机器学习模型进行对比,各模型均使用默认参数,并使用准确率、精确率、召回率、F1 值、AUC 值5 个指标对模型进行评估。将预处理后的数据集划分为训练集和测试集,比例为7∶3。
各个模型实验结果如表4 所示。由实验结果可知,本文所用模型的评价指标均优于9 个对比模型,准确率、精确率、召回率、F1值、AUC值分别为0.974 5、0.970 6、0.990 0、0.980 2、0.968 7,所以XGBoost模型是最优模型。

Table 3 Data standardization表3 数据标准化
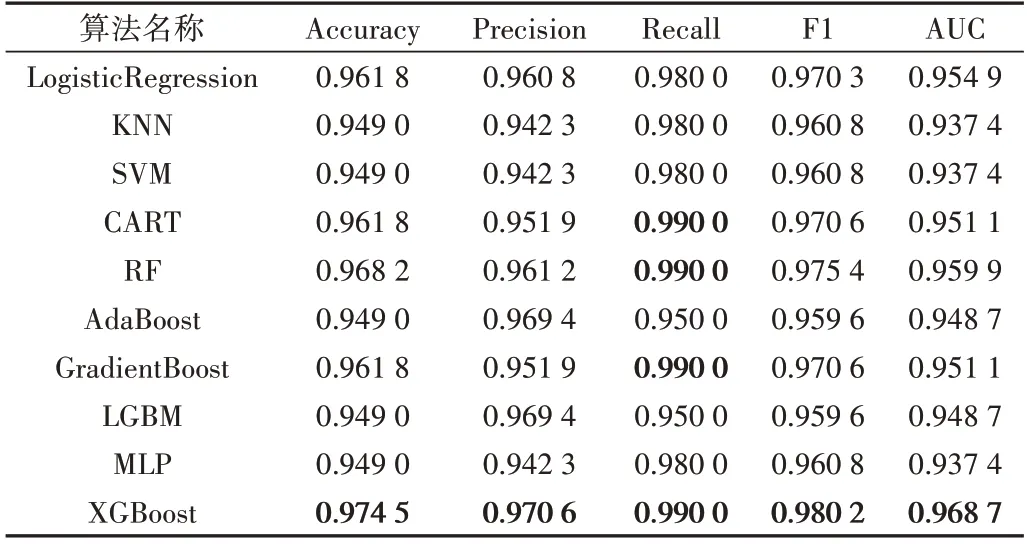
Table 4 Comparison results with other machine learning models表4 与其他机器学习模型对比结果
2.5 基于TPE的贝叶斯优化
XGBoost 模型的超参数较多,因此参数设置是否合理会影响模型精度。仅使用默认参数进行测试,并不能得出最优结果,因此需要对XGBoost 进行超参数优化。常用的调参方法为网格搜索、随机搜索、贝叶斯优化等[20-21],本文使用基于TPE 的贝叶斯优化进行超参数优化,以准确率的十折交叉验证平均值作为目标函数,从而获得最佳参数。
XGBoost 共有3 类参数:一般参数、提升参数、学习参数。本文选择影响力较大的超参数进行优化,为了找到最优的超参数组合,首先设置合理的超参数空间,如表5所示。
通过不断迭代,得出12 个超参数的最优组合。寻找最优参数的结果如图4 所示。图中,圆点表示超参数不同取值对应的准确率,五角星表示模型达到最高准确率时该超参数的取值。准确率最高为0.993 7,此时n_estimators为77,learning_rate为0.38,colsample_bytree为0.47,colsample_bynode为0.1,max_depth为9,gamma为5.3,subsample为0.77,reg_lambda为0.08,min_child_weight为9.58,objective为binary:logistic,rate_drop为0.38,reg_alpha为0.18。
经贝叶斯优化后的模型TPE_XGBoost 在5 个评价指标上均有所提升,准确率、精确率、召回率、F1 值、AUC 值分别为0.993 7、0.992 9、0.998 1、0.995 5、0.998 3,比采用默认参数的XGBoost 性能提升约0.81%~2.97%,原因是寻找到的最优超参数组合与本文的数据集更加匹配,降低了复杂性,可防止产生过拟合,从而提升了模型性能。调参后的模型与其他算法比较如表6所示。
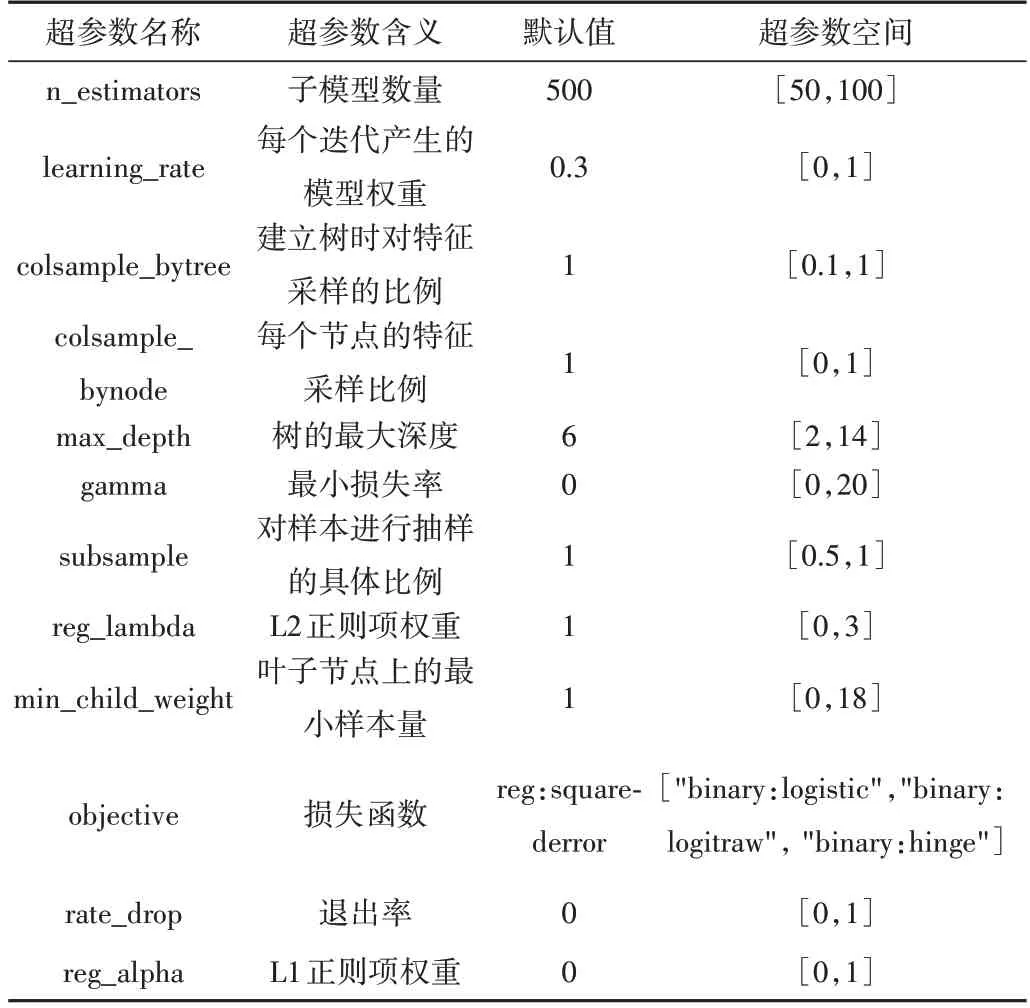
Table 5 Hyperparameter selection表5 超参数选择
3 基于 SHAP 的模型解释性分析
利用SHAP 模型对基于TPE_XGBoost 的冠心病预测模型的实验结果进行特征分析,图5 为SHAP 摘要图,该图纵轴代表特征重要性排序,横轴代表特征对模型的影响。由图5 可知,AGE(年龄)、体重指数、低密度胆固醇、舒张压、甘油三脂、高血压等特征对模型的影响较大。SHAP 得出最重要的特征为年龄,随着年龄的增大,患冠心病的风险也会增加;体重指数对患冠心病也有较大影响,体重指数越高,患冠心病的风险越大;舒张压越高,患冠心病风险越大;若患有高血压,则患冠心病的风险也较大;在相似的条件下,男性患冠心病的风险大于女性;尿酸越高,患冠心病的风险也越大。
利用SHAP 绘制前4 个重要特征的依赖图,如图6 所示。随着年龄、体重指数、舒张压的增加,SHAP 的值也增加,说明这些特征的值越大,患冠心病的风险则越大;SHAP 的值随着低密度胆固醇值的增大而减小,说明该特征在正常范围内对冠心病具有反向影响。
利用SHAP 对某个预测为患冠心病和未患冠心病的个体进行分析,分析结果分别如图7、图8 所示。红色指将模型分数变高的特征,蓝色指将模型分数变低的特征,箭头长度越长,代表该特征对模型结果的影响越大。由图7 可知,被预测为患冠心病的原因包括年龄较大、收缩压与舒张压较高、低密度胆固醇较低等。由图8 可知,被预测为未患冠心病的原因包括年龄较小、未患高血压、舒张压正常以及体重指数、甘油三脂较低等。
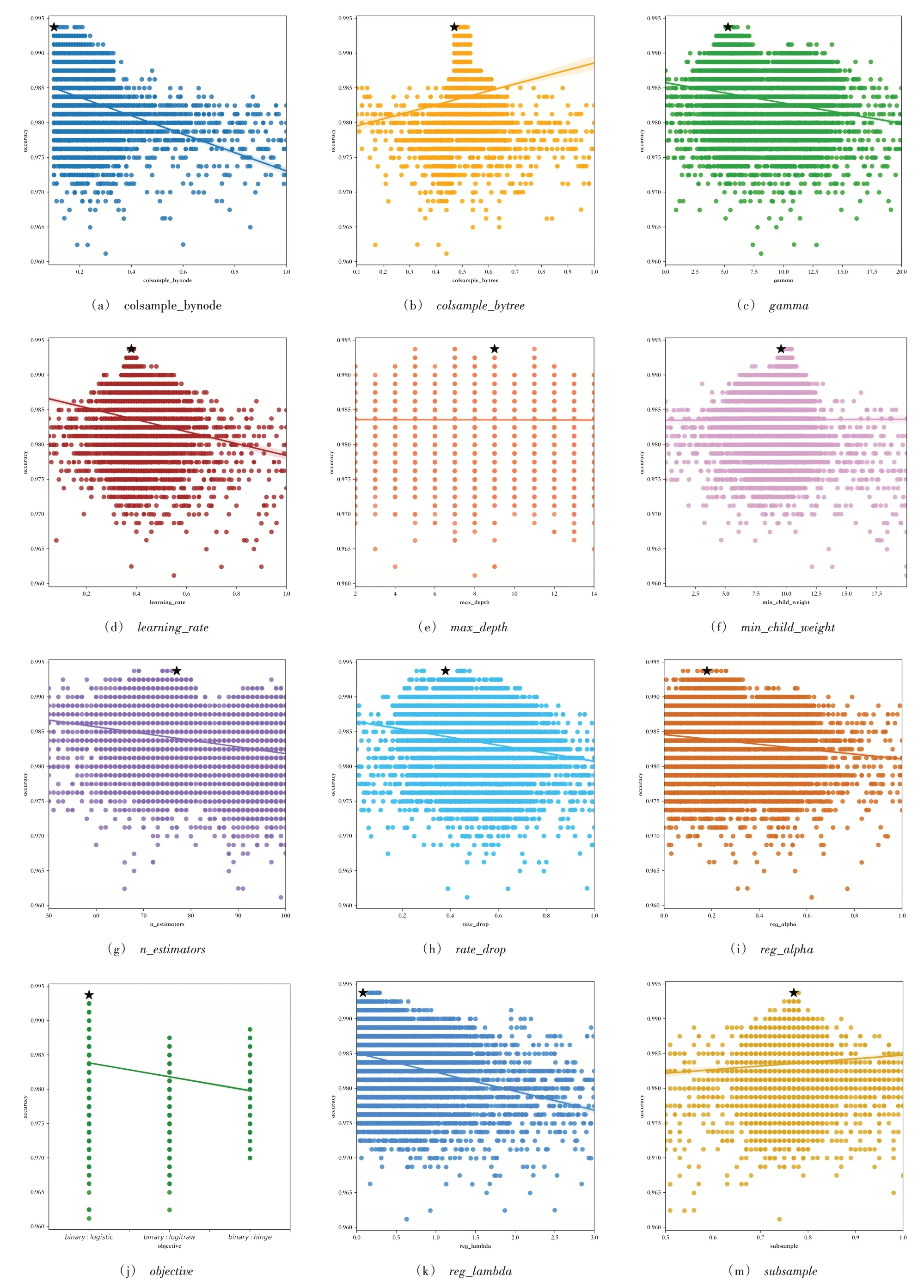
Fig.4 Finding the optimal parameter result图4 寻找最优参数结果
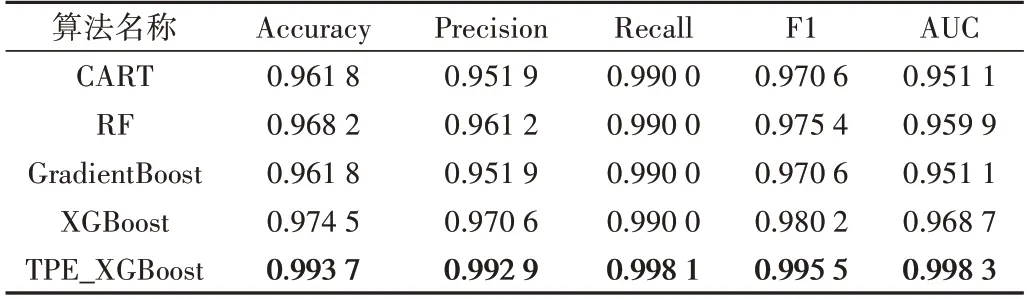
Table 6 Comparison of model after parameter tuning with other algorithms表6 调参后的模型与其他算法比较
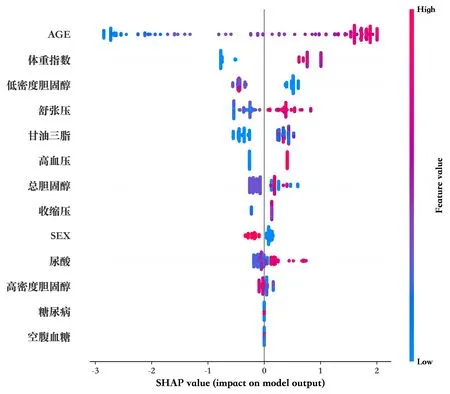
Fig.5 SHAP summary graph图5 SHAP摘要图
SHAP 解释模型、XGBoost 模型的特征重要性排序如图9、图10 所示,可以看出,特征排名并不完全一样,但这两个模型都将年龄排在首位,故年龄是冠心病的重要风险因素,另外低密度胆固醇、舒张压、体重指数是影响患病的关键因素。
4 结语
当前冠心病的患病率逐年攀升,且年轻化趋势明显。为减少医疗诊断开支,提高冠心病诊断的准确率,辅助临床决策,将机器学习算法运用于冠心病风险评估中,对降低冠心病的患病概率有着重要意义。本文基于机器学习算法,使用医院的体检数据,首先对该数据进行预处理,构建的XGBoost 模型比其他9 种模型更优;然后经过TPE 对XGBoost 预测模型的优化,性能提升约0.81%~2.97%,准确率达到0.993 7;最后通过SHAP 模型对各个特征的重要性进行合理解释,得出年龄、体重指数、低密度胆固醇、舒张压等是影响冠心病患病的关键因素。
本文实验模型所采用的数据获取更加方便,节约了大众去医院检查的时间和费用,便于其自行分析和调整身体状态。此外,由于本文纳入的特征较少,可能会忽略部分重要特征。在下一步研究中,将纳入更全面的特征,如是否吸烟、饮食习惯、作息和运动规律等,进一步分析相关特 征对冠心病的影响,指导大众健康生活。
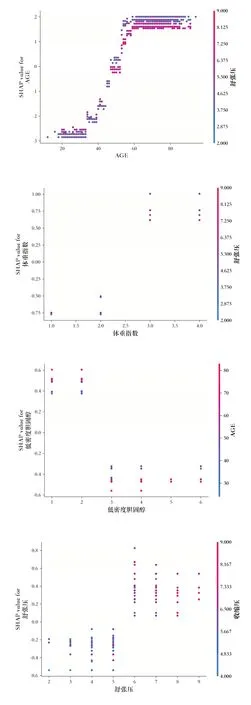
Fig.6 SHAP important features dependency diagram图6 SHAP重要特征依赖图

Fig.7 An analytical plot that predicts coronary heart disease图7 预测为患冠心病的分析图
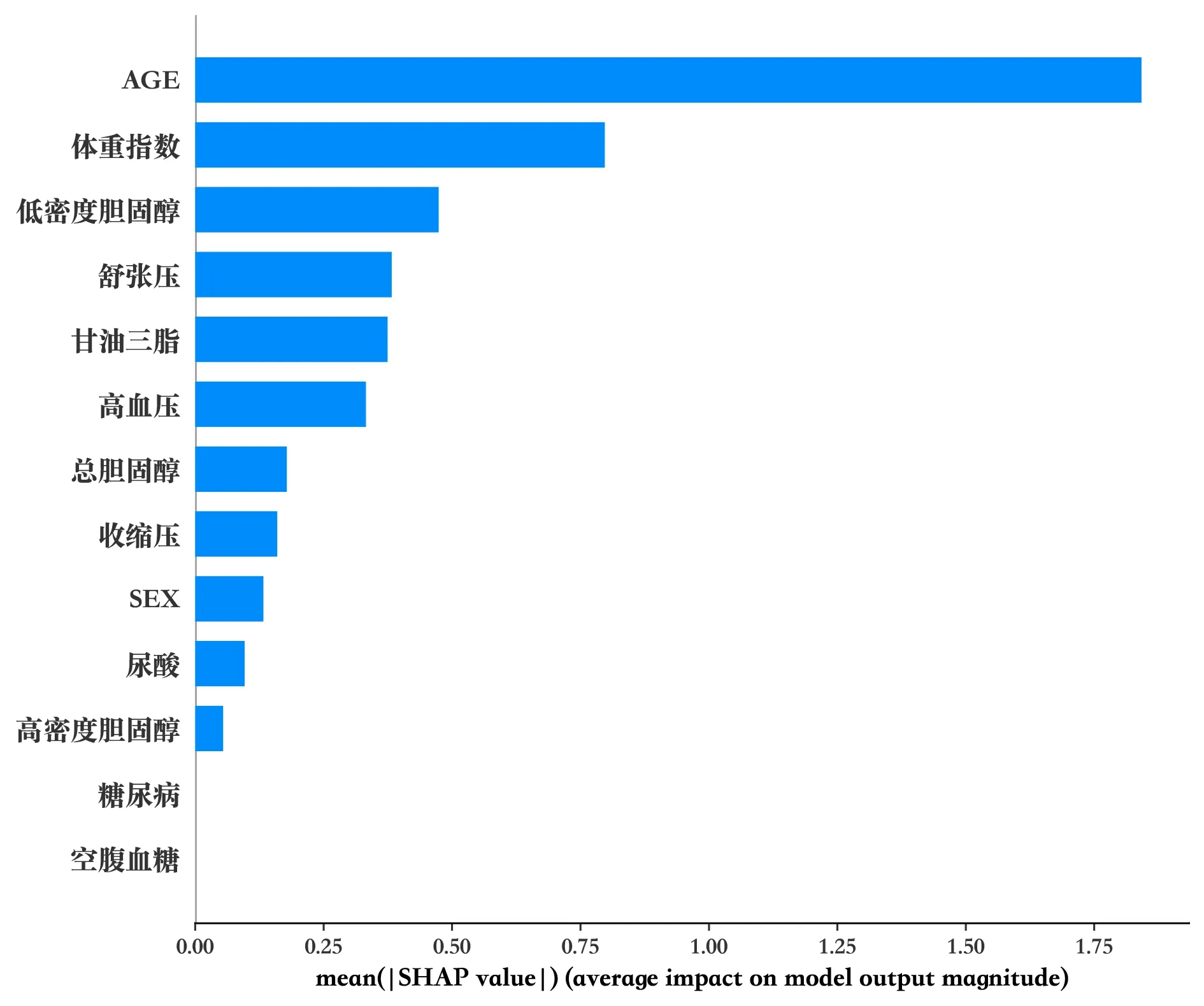
Fig.9 SHAP feature importance ranking图9 SHAP特征重要性排名

Fig.10 TPE_XGBoost model feature importance ranking图10 TPE_XGBoost模型特征重要性排名
