基于改进YOLOv5s的道路场景多任务感知算法
2023-05-29宫保国陶兆胜赵瑞李庆萍伍毅吴浩
宫保国,陶兆胜,赵瑞,李庆萍,伍毅,吴浩
基于改进YOLOv5s的道路场景多任务感知算法
宫保国,陶兆胜,赵瑞,李庆萍,伍毅,吴浩
(安徽工业大学 机械工程学院,安徽 马鞍山 243032)
针对单一任务模型不能同时满足自动驾驶多样化感知任务的问题,提出了一种基于改进YOLOv5s的快速端到端道路多任务感知方法。首先,在YOLOv5s网络输出端设计两个语义分割解码器,能够同时完成交通目标检测、车道线和可行驶区域检测任务。其次,引入RepVGG block改进YOLOv5s算法中的C3结构,借助结构重参数化策略提升模型速度和精度。为了提升网络对于小目标的检测能力,引入位置注意力机制对编码器的特征融合网络进行改进;最后基于大型公开道路场景数据集BDD100K进行实验验证该算法在同类型算法的优越性。实验结果表明,算法车辆平均检测精度为78.3%,车道线交并比为27.2%,可行驶区域平均交并比为92.3%,检测速度为8.03FPS,与同类型算法YOLOP、HybridNets对比,该算法综合性能最佳。
无人驾驶;目标检测;多任务网络
自动驾驶环境感知作为影响后续决策系统和控制系统的关键技术,将周边物体、行驶路径、驾驶状态等作为感知对象,为车辆平稳运行提供丰富、准确的数据支撑[1-3]。目前,研究人员主要通过单任务模型解决环境感知问题,例如将单阶段目标检测模型YOLO用于车辆检测[4],语义分割用于可行驶区域检测的EdgeNet[5],将结合逐片卷积的语义分割模型SCNN[6]用在车道线检测。然而,上述模型忽视了不同任务之间存在的关联性,可行驶区域中包含其他检测任务所需要的车道线和交通车辆位置信息,因此,不同感知任务模型会造成特征的重复提取。同时,车载平台受到制造成本和便携性限制,计算性能较弱,多个单任务模型同时运行会对车载计算平台的运算能力造成挑战。为了充分利用不同任务之间的关联性,提高子任务准确性,同时降低模型的内存占用,提高计算效率,研究满足车载平台精度和实时性需求的多任务环境感知模型具有重要意义。
在多任务环境感知方法研究中,TEICHMANN等[7]提出了同时完成道路场景分类、车辆检测、可行驶区域检测的多任务模型MultiNet,验证了检测任务和分割任务之间存在特定关联性。但是由于分类任务的存在,MultiNet需要进行模型预训练,提高了时间成本。孙宇菲[8]提出了一种结合MultiNet和改进SCNN的多任务学习模型同时检测车道线和可行驶区域,但是该算法忽略了道路场景中最重要的目标检测任务。QIAN等[9]提出了DLT-Net同时进行车辆检测、车道线和可行驶区域分割,通过构建上下文张量将3个分支任务中的特征图进行级联,显著提高了检测精度,但是实验结果表明该模型在车道线不连续时检测效果不佳。WU等[10]提出了一种能够在嵌入式平台实时运行的多任务模型YOLOP,通过3个分支任务解码器共享一个特征编码器,以降低计算量,在检测精度和实时性上都要优于DLT-Net,但是YOLOP中每个编码器都是独立设计,多个任务之间没有共享信息。
为了解决以上问题,本文基于YOLOv5s提出了一种快速准确完成交通车辆检测、车道线检测、可行驶区域分割的多任务环境感知算法。实验结果表明,本文算法能够有效提高模型检测准确度和实时性能。
1 算法理论介绍
1.1 YOLOv5s算法原理

图1 YOLOv5s模型结构

图2 C3模块基本结构

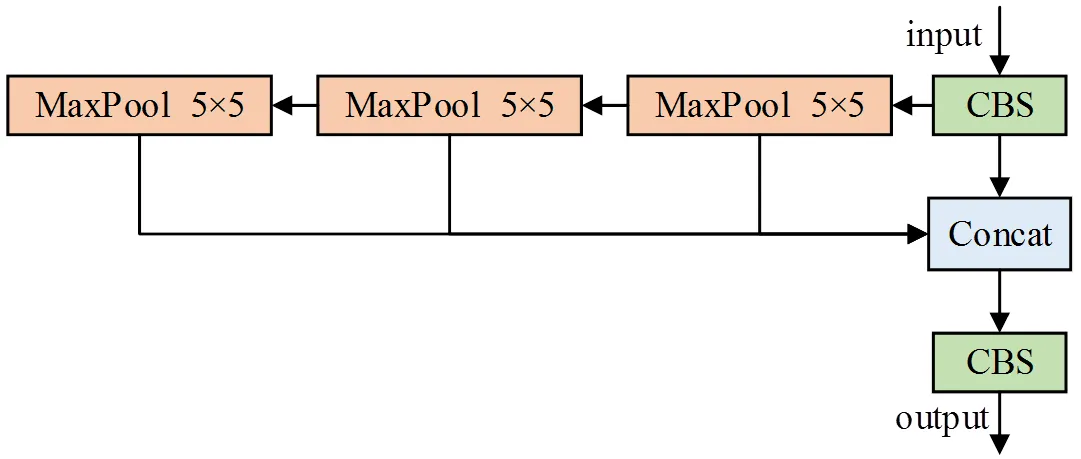
图3 SPPF模块基本结构
1.2 REPVGG算法原理
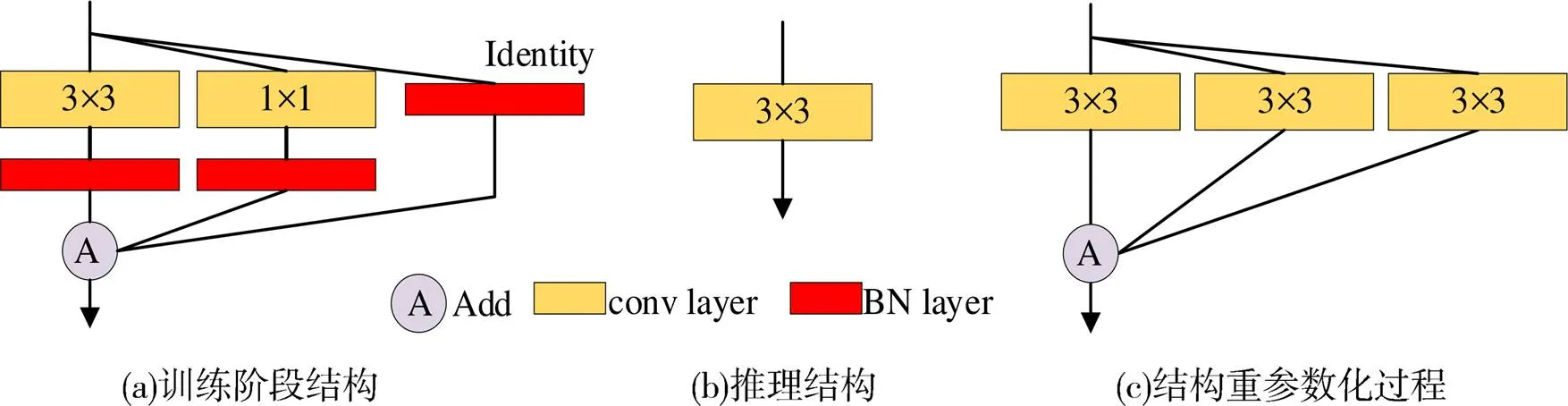
图4 RepVGG Block结构重参数化过程
1.3 位置注意力机制原理
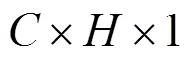
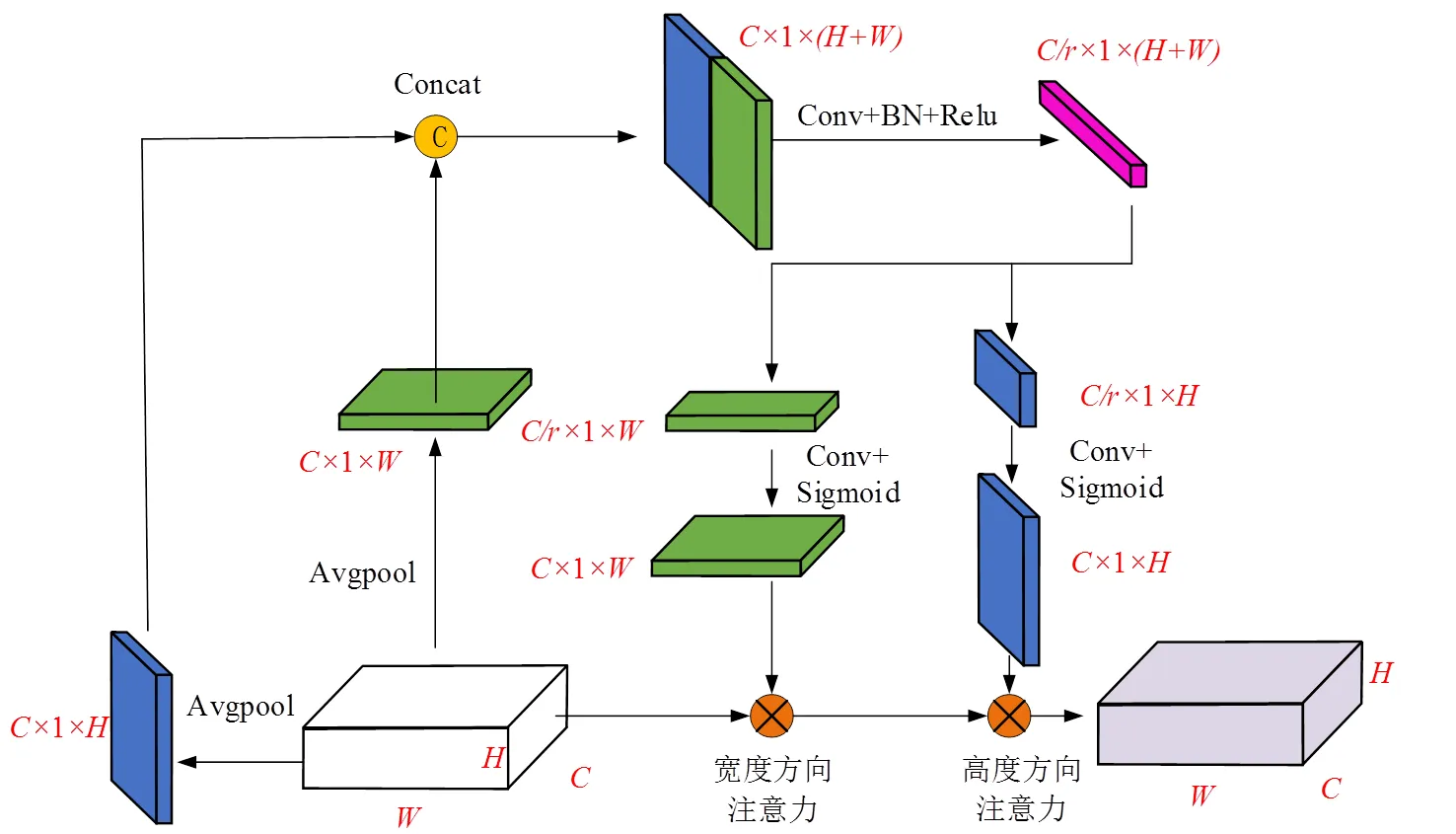
图5 位置注意力机制结构
2 道路场景多任务感知模型
本文研究模型整体网络结构如图6所示,网络结构由编码器和解码器组成,其中编码器由主干网络和特征融合网络组成,解码器由可行驶区域解码器、车道线解码器和车辆检测解码器构成,编码器用于提取不同任务所需的图像特征,并对特征进行聚合,从而使得模型学习到多尺度的特征信息。解码器则按照不同任务的特性设计了相对应的语义分割结构或目标检测结构,以便网络同时检测3种对象。

图6 本文多任务网络模型
2.1 主干网络改进
为了满足多任务环境感知模型在边缘设备等移动硬件的实时性和准确性需求,本文引入RVB结构对图2所示的C3模块的残差单元进行替换,得到RepC3模块,其结构如图7所示。与原来的C3模块结构相比,在训练阶段,RepC3模块增加梯度回传支路;在模型推理阶段中,将3分支卷积层转换为单分支结构,更好的提升设备的内存利用率,从而提升模型的推理速度。
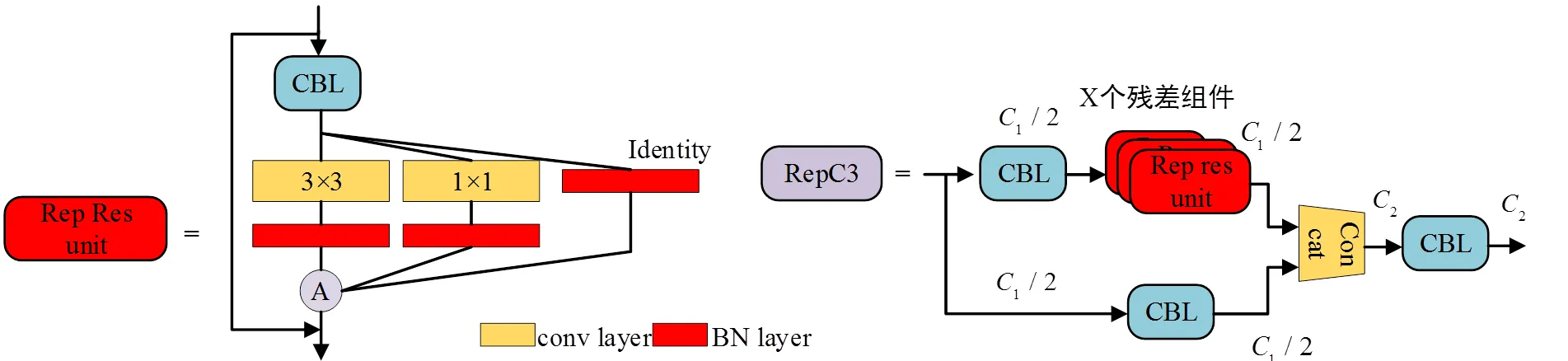
图7 RepC3模块结构
2.2 特征融合网络改进
YOLOv5s的Neck结构构建特征金字塔网络(Feature Pyramid Network, FPN)[19]和特征聚合网络(Feature Aggregation Network, PAN)[20]对提取的多尺度特征进行融合和再分配,提高网络对不同尺度目标检测结果的可靠性,FPN和PAN结构如图8(a)所示。PAN结构运用Concat将不同尺度特征图在通道维度上进行拼接,造成输出特征图通道数量增加。此外由于道路场景的物体之间存在相对位移,会导致目标的姿态发生改变,不利于小目标的检测。为了提高多任务网络算法在车载计算平台上的推理效率和关注重要小尺度目标的能力,本文结合RepC3、位置注意力机制模块构建一种更加有效的特征融合结构,其结构如图8(b)所示。

图8 特征融合网络结构
2.3 语义分割任务解码器结构设计
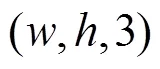
由于车道线为细长状且线条纹理不同于道路表面的长条状指示标志,在道路场景中占比远远小于可行驶区域。因此在可行驶区域分割解码器的基础上引入SPPF模块增强其特征提取能力,应用多个小尺寸卷积核替换SPP模块中的单个大尺寸卷积核,既融合不同尺度的感受野,又提高了运行速度。网络层结构如图10所示,与可行驶区域解码器结构相比,除了在调整通道维度后,增加了一个SPPF模块,其余结构基本相同。
3 损失函数选择
因本文模型需要同时完成交通车辆检测、车道线检测、可行驶区域分割,所以使用一种由3个任务各自对应的加权损失函数训练模型,如式(1)所示。
目标检测分支损失函数由分类损失、置信度损失、目标框回归损失3部分构成:

车道线检测分支损失函数由交叉熵损失和Dice[23]损失函数组成,交叉熵通过逐个对比每一个像素得到损失值。由于车道线像素数量远远少于背景像素,此时仅仅使用交叉熵损失函数,会导致损失函数趋向于背景像素,因此本文通过Dice损失函数抑制样本类别不平衡问题,其公式为


可行驶区域检测由于目标像素数量较多,检测难度较低,因此仅使用交叉熵作为损失函数:
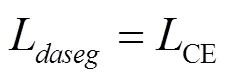
4 实验结果及分析
4.1 实验数据集
本文采用加州大学伯克利分校发布的自动驾驶公开数据集BDD100K[24]作为实验数据集。BDD100K包含了不同天气和时间段下的复杂道路场景图像,并对道路车辆、车道线、可行驶区域进行了标注,能够有效验证算法性能。BDD100K包含10万张图片,其中7万张为训练集,1万张为验证集,2万张为测试集,由于测试集标签并未公开,因此本文在验证集上评估算法性能。
4.2 实验参数设置与评估指标
本文所做的验证实验均基于Pytorch1.10框架,CUDA版本为11.3,计算平台使用的CPU为Intel Core i7-11700K,GPU为NVIDIA RTX 3070,Python版本为3.7。

本文实验采用召回率(Recall)、锚框交并比阈值设置为0.5时的类别平均精度均值(mean Average Precision,mAP)评估算法车辆检测性能、交并比(Intersection over Union,IOU)评估算法车道线分割性能,平均交并比(mean Intersection over Union,mIOU)评估算法可行驶区域分割性能,每秒检测帧数(Frames Per Seconds,FPS)、参数量、十亿次浮点运算次数(Giga Floating Point Operations,GFLOPs)评估模型的轻量化性能和复杂度。
召回率和类别平均精度均值的计算公式如式(7)和式(9)所示:

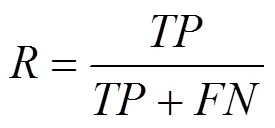
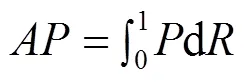
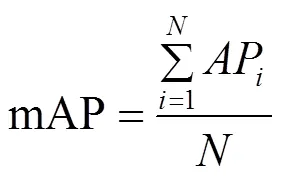
交并比和平均交并比计算公式如下:
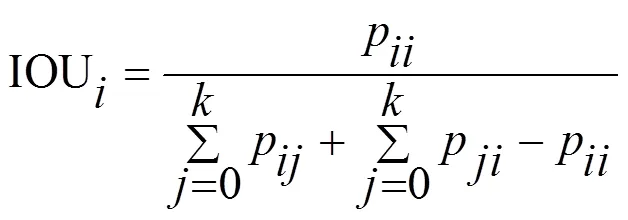
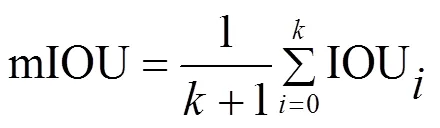
模型迭代训练100个epoch过程中的算法平均精度均值、损失函数变化曲线如图11(a),(b)所示。可以看出,前50个epoch内,训练损失下降较快,50个epoch后逐渐收敛,第80个epoch后训练过程总损失趋于稳定。最终选取在验证集上评价指标最高的作为最终权重。
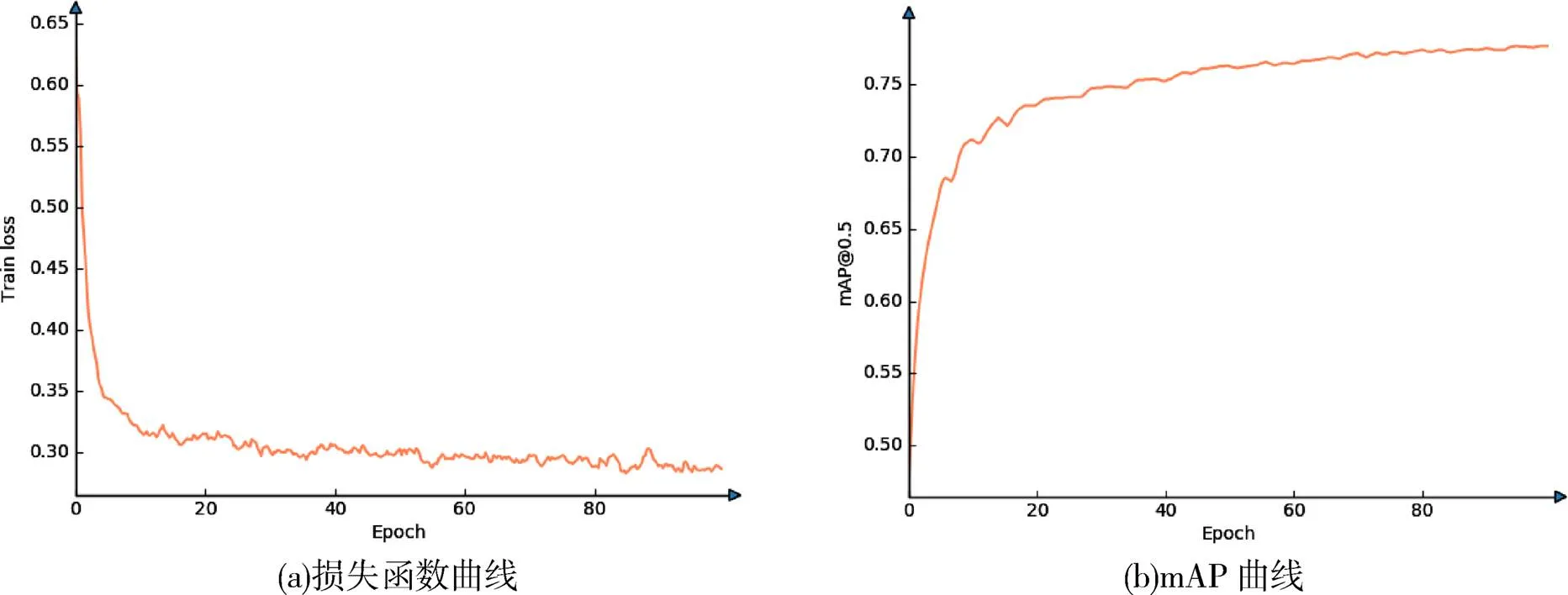
图11 训练过程可视化
在推理过程中,模型加载已训练的权重,并将输入图像前向传播。模型输出结果后,经过非极大值抑制滤除重复锚框后,将其绘制在原图上,得到图12所示的可视化结果。由图12可知,本文模型的车辆检测解码器能够较为准确识别前方车辆位置,并且置信度分数较高。车道线和可行驶区域解码器能够准确识别道路两旁的车道线以及可行驶区域。同时,本文模型在光照较弱的黑夜场景下仍能保持较好的检测效果。

图12 模型推理可视化结果
4.3 对比实验结果
为了验证本文提出算法在同类型的多任务环境感知算法的优越性,本文与现有的道路场景多任务算法YOLOP、HybridNets[25]进行了对比实验,定量评价实验指标已在4.2节详细说明,定量实验结果如表1所示。
从表1中不同多任务算法感知模型的对比结果可知,与YOLOP算法比较:在车辆检测任务中,本文算法召回率比YOLOP高了0.6个百分点,平均检测精度高了1.8个百分点;在车道线检测任务中,本文算法交并比IOU比YOLOP算法高了1个百分点;在可行驶区域检测任务中,本文算法平均交并比mIOU比YOLOP高了0.8个百分点;在模型整体复杂度和实时性方面,本文算法的浮点计算量和参数量都要低于YOLOP算法,反映在本文算法FPS指标比YOLOP算法快了1.72帧。由上述分析可知,对比YOLOP算法,本文算法无论是在检测精度还是检测速度都占有优势。与HybridNets算法比较,在车辆检测任务中,本文算法召回率比HybridNets低了3个百分点,平均检测精度高了1个百分点;在车道线检测任务中,本文算法交并比比HybridNets低了4.4个百分点;在可行驶区域检测任务中,本文算法平均交并比HybridNets高了1.8个百分点;在模型整体复杂度和实时性方面,本文算法的参数量远远小于HybridNets算法,FPS指标比HybridNets算法快了2.64帧。由上述分析可知,本文算法虽然在召回率和车道线检测任务中的指标稍逊于HybridNets算法,但是本文的实时性能优于HybridNets方法。综上所述,与同类型的多任务感知方法比较,本文基于YOLOv5s改进的模型有着最快检测速度的同时,保持着较好的检测精度,更能满足实际部署需求。为了更加直观展示不同算法的检测效果,分别选取3种不同道路场景进行比较,结果如图13所示,(a)~(c)为HybridNets检测效果,(d)~(f)为YOLOP检测效果,(g)~(i)是本文算法检测效果。

表1 多任务模型对比实验结果

图13 多任务算法对比结果
由检测效果(a),(d),(g)可知,HybridNets对可行驶区域的检测结果中出现明显的空洞,YOLOP算法对图像左下方像素进行了错误分类。由检测效果(b),(e),(h)可知,HybridNets对可行驶区域的检测结果中出现明显的空洞,YOLOP算法对图像左下方像素进行了错误分类。HybridNets模型和YOLOP方法得到的车道线检测结果在完整度上明显不如本文算法。检测效果(f)中,YOLOP模型错误地将路边的电动车误检为汽车。综上所述,与HybridNets方法、YOLOP方法比较,本文算法的车道线和可行驶区域连续性更好,缺失程度更低,在检测出小车辆目标的同时,不易发生误检。
5 结束语
针对单一任务模型处理自动驾驶环境感知任务实时性差、准确度低的问题,本文首先基于YOLOV5s进行改进,使其由单一任务模型转换为多任务模型,同时完成交通车辆检测、车道线和可行驶区域检测。其次借助参数重参数化策略,对C3模块进行改进,提升了模型的推理速度。最后,在特征融合网络中引入位置注意力模块,提升模型对于小目标的检测能力。在公开数据集BDD100K上的实验结果表明,本文算法能够准确、快速地完成交通车辆检测、车道线和可行驶区域检测。同时与近年来的同类型多任务检测算法比较,本文算法明显提高了3个分支任务的检测精度和推理速度,在计算能力欠缺的车载设备场景下,有着更强的实用价值。
[1] 王龙飞,严春满. 道路场景语义分割综述[J]. 激光与光电子学进展,2021, 58(12): 44-66.
[2] 于向军,槐元辉,姚宗伟,等. 工程车辆无人驾驶关键技术[J]. 吉林大学学报(工学版),2021, 51(04): 1153-1168.
[3] 彭育辉,江铭,马中原,等. 汽车自动驾驶关键技术研究进展[J]. 福州大学学报(自然科学版),2021, 49(05): 691-703.
[4] 王得成,陈向宁,赵峰,等. 基于卷积神经网络和RGB-D图像的车辆检测算法[J]. 激光与光电子学进展,2019, 56(18): 119-126.
[5] HAN H Y, CHEN Y C, HSIAO P Y, et al. Using channel-wise attention for deep CNN based real-time semantic segmentation with class-aware edge information[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 22(2): 1041-1051.
[6] PAN X, SHI J, LUO P, et al. Spatial as deep: Spatial cnn for traffic scene understanding[C]//Proceedings of the AAAI Conference on Artificial Intelligence, 2018.
[7] TEICHMANN M, WEBER M, ZOELLNER M, et al. Multinet: Real-time joint semantic reasoning for autonomous driving[C]//2018 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2018: 1013-1020.
[8] 孙宇菲. 基于多任务学习的车道线检测算法研究[D]. 西安:长安大学,2021: 20-28.
[9] QIAN Y, DOLAN J M, YANG M. DLT-Net: Joint detection of drivable areas, lane lines, and traffic objects[J]. IEEE Transactions on Intelligent Transportation Systems, 2019, 21(11): 4670-4679.
[10] WU D, LIAO M W, ZHANG W T, et al. YOLOP: You only look once for panoptic driving erception[J]. Machine Intelligence Research, 2022, 19(6): 550-562.
[11] REDMON J, FARHADI A. Yolov3: An incremental improvement[J]. arXiv preprint arXiv:1804.02767, 2018.
[12] WANG C Y, LIAO H Y M, WU Y H, et al. CSPNet: A new backbone that can enhance learning capability of CNN[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020: 390-391.
[13] XU H, LI B, ZHONG F. Light-YOLOv5: A lightweight algorithm for improved YOLOv5 in complex fire scenarios[J]. Applied Sciences, 2022, 12(23): 12312.
[14] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[C]. 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 740–755.
[15] HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015, 37(9): 1904-1916.
[16] DING X, ZHANG X, MA N, et al. Repvgg: Making vgg-style convnets great again[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 13733-13742.
[17] HOU Q, ZHOU D, FENG J. Coordinate attention for efficient mobile network design [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 13713-13722.
[18] LIN M, CHEN Q, YAN S C. Network in network[J]. arXiv preprint arXiv:1312.4400, 2013. https://arxiv.org/abs/1312.4400.
[19] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 2117-2125.
[20] LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 8759-8768.
[21] TAN M, LE Q. Efficientnet: Rethinking model scaling for convolutional neural networks[C]//International Conference on Machine Learning. PMLR, 2019: 6105-6114.
[22] ZHANG Y F, REN W, ZHANG Z, et al. Focal and efficient IOU loss for accurate bounding box regression[J]. Neurocomputing, 2022, 506: 146-157.
[23] MILLETARI F, NAVAB N, AHMADI S A. V-net: Fully convolutional neural networks for volumetric medical image segmentation[C]//2016 Fourth International Conference on 3D Vision (3DV). IEEE, 2016: 565-571.
[24] YU F, CHEN H, WANG X, et al. Bdd100k: A diverse driving dataset for heterogeneous multitask learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 2636-2645.
[25] VU D, NGO B, PHAN H. HybridNets: End-to-end perception network[J]. arXiv preprint arXiv:2203.09035, 2022. https://arxiv.org/abs/2203.09035.
A road multi-task perception algorithm based on improved YOLOv5s
GONG Bao-guo,TAO Zhao-sheng,ZHAO Rui,LI Qing-ping,WU Yi,WU Hao
(College of Mechnical Engineering, Anhui University of Technology, Anhui Maanshan 243032, China)
Aiming at the problem that a single task model can not satisfy the diverse perception tasks of autonomous driving at the same time, a fast end-to-end road multi-task perception method based on improved YOLOv5s is proposed. First, two semantic segmentation decoders are designed at the output of the YOLOv5s network, which can simultaneously complete the tasks of traffic object detection, lane line and drivable area detection. Secondly, the RepVGG block is introduced to improve the C3 structure in the YOLOv5s algorithm, and the speed and accuracy of the model are improved with the help of the structural re-parameterization strategy. Then, in order to improve the detection ability of the network for small targets, the position attention mechanism is introduced to improve the feature fusion network of the encoder. Finally, based on the large-scale public road scene dataset BDD100K, experiments are carried out to verify the superiority of the proposed algorithm in the same type of algorithm. The experimental results show that the average vehicle detection accuracy of the algorithm in this paper is 78.3%, the lane line intersection ratio is 27.2%, the average drivable area intersection ratio is 92.3%, and the detection speed is 8.03FPS. Compared with the same type of algorithms YOLOP and HybridNets, this paper the algorithm has the best overall performance.
autonomous driving;object detection;multi-task networks
TP391
A
1007-984X(2023)03-0019-11
2022-11-03
安徽省自然科学基金面上项目(2108085ME166);安徽高校自然科学研究项目重点项目(KJ2021A0408)
宫保国(1998-),男,安徽阜阳人,硕士,主要从事机器视觉研究,GBG3119@163.com。
