FMCW雷达基于光学字符识别的连续动作识别研究
2023-05-25蒋留兵吴岷洋
蒋留兵,吴岷洋,车 俐
(1.桂林电子科技大学信息与通信学院,广西桂林 541004;2.桂林电子科技大学计算机与信息安全学院,广西桂林 541004)
0 引 言
根据第七次全国人口普查显示,2020年我国60 岁及以上人口有2.6 亿人,占总人口的18.70%,中国已经逐步进入深度老龄化社会[1-2]。老人活动不便,很容易跌倒并且无法依靠自身能力站起来,这给医疗保健行业带来巨大的压力,需要该行业在老人发生跌倒等重大事件时能够及时做出响应[3]。
目前对于人体动作主要采用基于摄像头[4-5]和基于穿戴设备两种方法[6-7]。前者采用图像处理的技术而后者则采集人体运动数据。很显然,基于摄像头的动作识别方法存在侵犯个人隐私,容易受到外界干扰的问题;基于穿戴设备的动作识别方法存在设备容易损坏,穿戴不适等问题。基于雷达的人体动作检测则能很好地解决上述两种方法存在的问题。该方法是一种通过雷达向目标发射电磁波,接收目标回波信号判断人体动作的主动探测方式。
基于雷达的动作识别方法主要基于深度学习,对雷达信号进行预处理,然后输入到深度学习网络中进行训练和识别。文献[7]使用UWB 雷达采集代表运动特性随时间变化的时变距离多普勒图像(TRDI),采用自动编码器(CAE)提取特征,输入到长短记忆网络(LSTM)中进行识别达到了96.80%的准确率。文献[8]使用双向长短记忆网络(Bi-LSTM),将可穿戴传感器和雷达数据直接的软特征融合,在连续活动和跌倒事件方面的准确度提高到大约96%。文献[9]利用超宽带雷达提取动作特征生成图像,然后将图像输入到卷积网络中进行识别,达到了99.2%的准确率。文献[10]提出基于主成分分析法(PCA)和离散余弦变换(DCT)相结合的人体动作特征提取方法,并利用改进网格搜索算法优化的支持向量机在小样本数据下对人体动作进行识别,最终得到超过96%的识别精度。基于深度学习的雷达动作识别方法主要通过将采集的信号进行预处理,生成相应的特征图,然后将这些特征图输入到深度学习网络中进行训练和识别,这就导致了识别速度相比直接对原始信号处理慢一些[11-12]。文献[11]提出一种新的端到端网络,直接对收集的FMCW 雷达原始数据进行处理,对5 种动作超过90%的识别准确率。文献[12]提出了一维卷积神经网络(1D-CNNs)和长短记忆网络(LSTM)组成的深度学习模型直接对原始信号进行处理,在对7种动作达到超过95%的识别精度的同时,训练参数少很多,因此识别速度也快很多。目前大部分基于深度学习的雷达动作识别算法只能对单个动作进行识别,通过简单的信号处理,将原始信号处理成相应的特征图像,然后输入到基于分类的深度学习网络中进行识别。这种情况导致了当一组数据中包含多个动作信息的时候算法也只能将其识别为单个动作。
针对上述问题,该文提出一种基于文本识别技术(OCR)的连续动作雷达微多普勒特征识别方法。首先对采集的雷达数据采用RDM(Range-Doppler Map)向速度维投影的方法逐帧获取微多普勒时频图,然后将处理得到的时频图输入一个特别定制的,由卷积神经网络、inception_resnet、最大池化层和Bi-LSTM的网络组成,使用联结主义时间分类(CTC)作为损失函数进行训练的网络。实验结果表明该方法对步行、跑步、蹲下、站起、跳跃这5 种动作的识别准确率分别高达96.16%,95.34%,88.49%,89.37%,96.72%。对一个时间窗口内多个动作的识别也取得了不错的效果,时间上的识别准确率整体令人满意。
1 FMCW雷达信号处理
1.1 FMCW 雷达信号模型
FMCW 雷达由一个波形发生器、一个带有2个发射器和4个接收器的天线阵列、一个信号解调器和一个模数转换器(ADC)组成。波形发生器通过发射Chirp 信号,然后利用低频滤波器(LPF)得到中频信号。假设FMCW 雷达发射调频连续波信号,其发射信号模型[13]可以表示为
式中,AT表示发射功率,fc表示Chirp的起始频率,B表示Chirp 的带宽,Tc表示Chirp 的持续时间,φ(t)表示相位噪音。
目标反射回来的是一个有延迟的信号,可以表示为
式中,td=2R(t)/c表示信号在与距离雷达R(t)距离处的目标之间的往返时间,α表示回波损耗系数。将发射信号xT(t)和接收信号xR(t)混频以后再结合I/Q信号分析,其差拍信号可以表示为
式中AR为接收信号的功率,fb表示为
相位φb(t)则表示为
通常情况下,探测近距离目标的时候,残留的相位噪声Δφ(t)可以忽略不计。并且,πBt2d/Tc的数值也非常小,可以被忽略掉。因此,最终的可以用雷达采样数据矩阵表述差拍信号为
式中,n表示快时间采样轴上对应的标号,m表示慢时间采样轴上对应的标号,Tf表示快时间采样轴上的ADC 采样时间间隔,Ts表示慢时间采样轴上的采样时间间隔。
1.2 微多普勒时频图
传统的短时傅里叶变换(STFT)采用定长窗函数进行时频分析,对于连续的Chirp 信号能够取得不错的效果,不过对于没有连续Chirp 而是连续帧(帧内Chirp 连续,帧间的Chirp 不连续)的信号来说一旦参数调整不好就会出现严重的功率泄露的情况。为了解决这个问题,使用文献[14]所提出的RDM投影法获取微多普勒时频图。对单帧的快时间维数据加上汉宁窗,然后进行RangeFFT 获得距离信息,然后再对单帧的慢时间维数据加上汉宁窗,进行DopplerFFT 获得目标的速度信息,最后将零频率分量搬移至频率中间,得到最终的RDM(Range-Doppler-Map)。该RDM能够很好地描述在该帧下人体所有散射点的距离和速度。假设RD(i,j,t)表示t帧下位于RDM 中第ith距离门、jth速度门下的信号功率值。
每帧RDM通过对距离门的投影可以得到目标与雷达的距离变化,如图1(a)所示,计算公式为
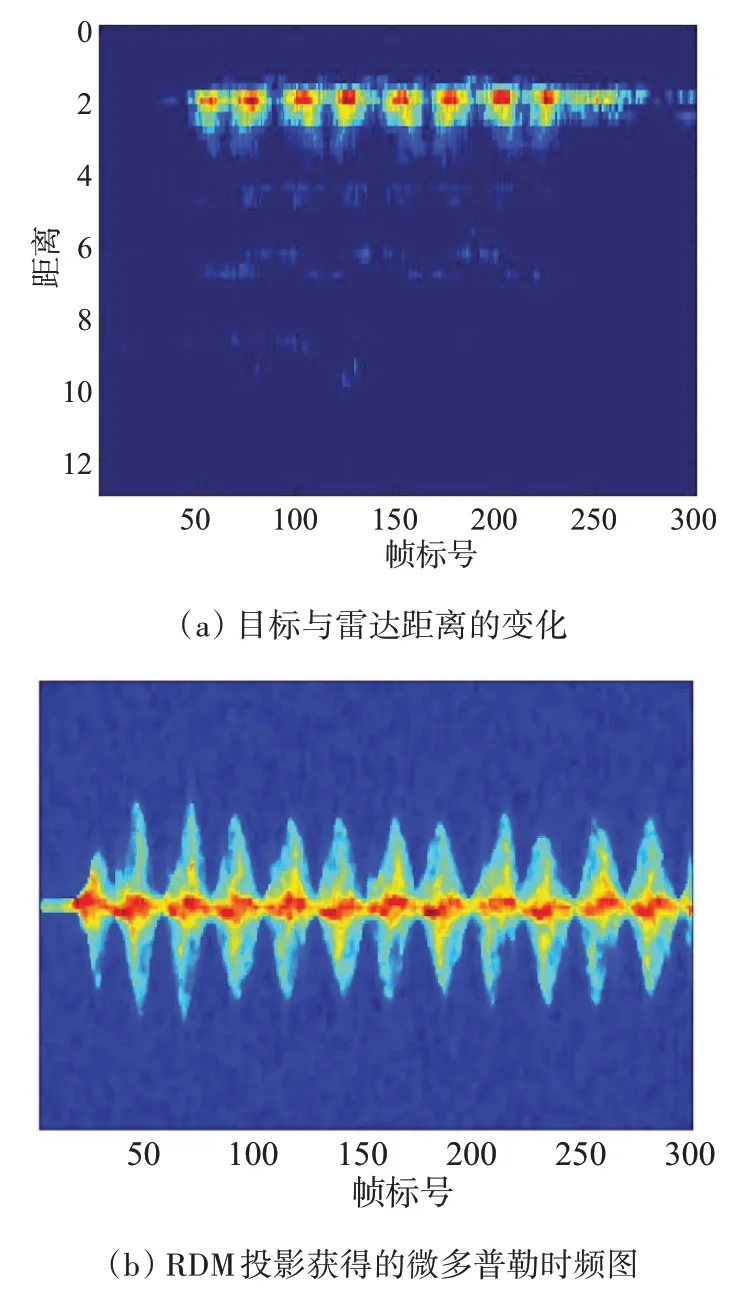
图1 距离门与RDM投影
通过距离门可以得到目标在运动中距离雷达的最小/最大径向距离,记录下对应的距离门标号为imin及imax。提取对应距离内的RDM,然后将RDM 向速度方向投影并且进行逐帧积累得到微多普勒时频图,如图1(b)所示,具体公式为
本质上,RDM 投影是一个窗口长度,步长都为一帧中慢时间的Chirp 数(实验中为128),重叠率为0 的短时傅里叶变化。微多普勒视频图的构建流程如图2所示。
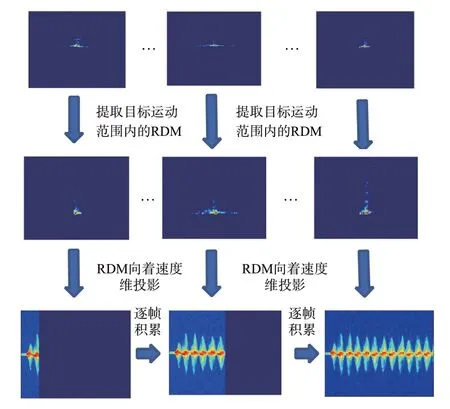
图2 微多普勒图构建流程
德州仪器AWR1843 因为存在帧的概念,即每帧存在若干个Chrip,然后每个Chrip间存在若干个采样点,这种情况导致了单个帧内的Chrip 时间是等长的,然而多个帧之间的Chrip 是不等长的,这种情况就会导致使用短时傅里叶变换出现严重的功率泄露的情况,生成的图像质量非常差,严重影响深度学习网络的识别精度。而RDM投影是通过对单个帧的累加得到,没有涉及到多个帧之间的操作,因此不存在功率泄露的情况,相比于短时傅里叶生成的图像,质量要高很多。
2 基于文本识别的连续动作识别
一组连续动作的微多普勒时频特征如图3所示,不同动作的微多普勒特征有很大的不同。受到文献[15]的启发,将不同动作的微多普勒特征进行编码,使用文本识别的思路进行识别。具体来说,是将包含多个动作特征的微多普勒时频图输入到一个由卷积神经网络,inception_resnet 网络作为主干网络对时频图进行压缩并提取特征得到一组帧序列,然后使用BLSTM 网络对每帧进行预测,最后使用CTC[16]将每帧的预测编码解码成标签序列。

图3 一组连续动作的微多普勒时频图
2.1 网络结构
本文提出的网络结构如图4所示。该网络要求图像输入的高度为256,宽度w不限,通道数为3,即输入图像的尺寸为256×w×3,核心思想是使用卷积神经网络、inception_resnet 提取特征,然后使用最大池化层对图像进行压缩,图像最后会被压缩成一个如图5所示,一共由w/16 个1×1×512 维度长方体特征组成的时间序列,然后将该序列输入到Bi-LSTM 网络中进行预测。网络的参数如表1所示。

图5 压缩以后的长方体序列

表1 基于文本识别的网络框架参数
2.2 Bi-LSTM
连续动作的微多普勒特征存在时序的特性,因此运动会被依次顺序纪录下来。传统的CNN 网络只能提取微多普勒特征,无法对时序序列进行动态预测。为了解决这个问题,引入Bi-LSTM 网络,提取CNN 网络输出的特征序列的时间特征,并且对每个时间序列进行预测。简单地说,Bi-LSTM分别结合了前向和后向LSTM 网络还处理两个方向的时间信息,除了使用过去的信息对现在进行预测以外还能使用将来的信息预测现在。LSTM 是一种特殊的RNN,加入了遗忘门,能够丢弃过去无用的信息,保留有效的信息,从而缓解梯度消失的问题,其计算模型如下:
式中σ为激活函数,i(t)为输入门,f(t)为遗忘门,o(t)为输出门。Bi-LSTM 由前向和后向LSTM 组成,其模型如下:
2.3 联结主义时间分类
假设一段数据时长为9 s,有人可能在3~6 s的时间内执行了动作,也有人可能在4~9 s 内执行了动作,不同的人在不同的时间段内执行了不同时间的动作,因此需要精确标注数据是很困难的。为此,使用CTC 算法自动学习时间序列和标签间的对齐情况,从而避免了精确标注数据集,只需要数据标注顺序正确即可。
如果序列预测为y=(y1,y2,…,yN),对应的真实标签为I=(I1,I2,…,IW),这其中序列长度要大于等于标签长度(即N≥W)。考虑到不同的动作间存在过渡(一个动作执行完,过一段时间再执行下一个动作),过渡的这段时间内没有任何动作,因此需要定义一个blank 作为空白符加入到原始标签序列中构造一个新的标签序列,即L'=L∪{-},其中L'为新的标签序列,L为原始标签序列。很显然一个真实的标签对应的预测输出有很多,假设一个y预测输出序列为T=(t1,t2,t3,t4)的数据对应的真实标签序列为label=(l1,l2,l3),那么其对应的预测有p(π1)=(l1,-,l2,l3),p(π2)=(l1,l2,-,l3),p(π4)=(-,l1,l2,l3)等多种可能的路径。因此在真实标签为y的情况下,预测标签为I的概率为
式中π表示Bi-LSTM 的输出序列,p(π|y)表示路径的概率。由于各个时间序列间的预测概率是相互独立的,因此对于任意时刻输出序列π的概率计算如下:
式中πt∈L',是在时间t上路径π下预测的标签,是在时间t下标签为πt的概率。损失函数可以定义为Lctc=-lnp(I|y),通过对每个步长的每个标签求导进行梯度更新。
3 实验结果与分析
3.1 实验环境
实验中所用的毫米波雷达硬件平台由德州仪器研发的AWR1843BOOST 雷达传感器模块和DCA1000EVM 数据采集模块组成。设置该雷达的起始工作频率为77 GHz、带宽为4 GHz,单个Chirp下的采样点为256,单个帧下有128 个Chirp,单个帧的周期为30 ms。对单个动作和两个连续动作采集300 帧及9 s 的数据,对3 个连续动作采集400帧即12 s的数据。
实验中所用数据均在室内采集,雷达扫描扇面内除了单个测试者外没有其他目标。雷达置于距离地面0.8 m的支架上,测试者在雷达正前方2 m处原地执行指定动作。前后共有10名志愿者参与采集数据,他们的体重在41~80 kg,身高在1.60~1.80 m,年龄在22~25之间。实验中总共采集5种动作,分别是步行、跑步、蹲下、站起、跳跃,采集环境如图6所示,单个动作的微多普勒时频图如图7所示。总共采集1 600组数据,其中单个动作为800组,两个连续动作为500组,3个连续动作为300组。

图6 实验环境


图7 单个动作的微多普勒时频图
深度学习网络基于TensorFlow2.0 中的keras框架,优化函数为Adam,使用默认学习率,设置批量大小为8。深度学习实验在一台配有GPU 为RTX2080Ti(8G显存),16G内存和酷睿i7的服务器上进行。训练测试数据的比例为8∶2。图像输入的高度为256,宽度不限,即图像输入的尺寸为256×w。实验中,9 s 的数据输入网络的宽度为576 像素(w=576,input=256×576×3),输出为1×36×512,即由36 个1×512 组成的特征序列,每个序列代表大约0.25 s 时长的数据;12 s 数据输入网络的宽度为768 像素(w=768,input=256×768×3),输出为1×48×512,即由48 个1×512组成的特征序列,每个序列代表大约0.25 s时长的数据。
3.2 单个动作的识别
该文所提出的方法既能够对多个连续的动作进行识别,也能够对单个动作进行识别。图8为5种动作的混淆矩阵。实验表明,该方法对5种动作识别的平均准确率高达93.22%,其中对步行、跑步和跳跃的识别准确率分别高达96.16%,95.34%,96.72%。由于蹲下和站起的为多普勒频率是相反的,同时在蹲下和站起的时候为了保持平衡手臂也会摆动,最终导致蹲下和站起的微多普勒特征比较相似,导致了在识别蹲下和站起这两个动作时的精度只有88.49%和89.37%。
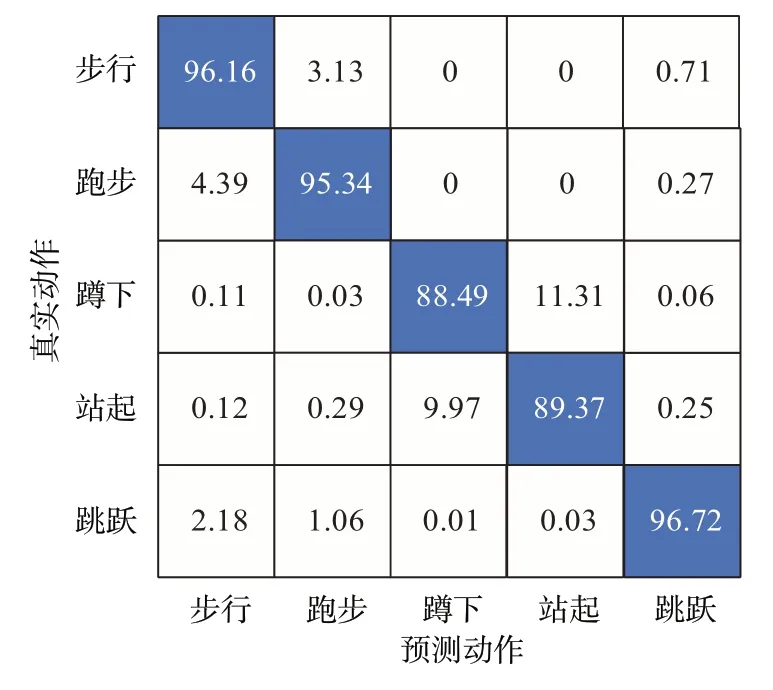
图8 5种动作的混淆矩阵
为了能够进一步验证该文所提出方法的可能性,将该方法与文献[7],文献[10]和文献[12]中提出的动作识别方法进行对比。文献[7]提出了一种时变距离-微多普勒图(TRDM)的方法,在目标执行动作区间中的数据进行距离和速度FFT 得到一组时序的RDM 图形成数据流,然后利用所提出的CAE+LSTM 网络提取数据流的时序特征和像素特征进行识别。文献[10]首先使用PCA 技术对原始数据降维,然后使用DCT 技术对降维以后的数据进行处理,最后使用一种改进型的SVM 网络对经过PCA 和DCT 处理以后的数据进行识别,取得了不错的效果。文献[12]将STFT 和深度学习相结合,直接对经过短时傅里叶变换以后的特征矩阵进行处理,使用1D_CNN 网络和LSTM 提取特征矩阵的信息,从而实现对单个动作的识别。对比效果如表2所示。

表2 本文方法同不同方法的对比
通过表2对比可以得知,本文所提方法同文献[7]、文献[10]和文献[12]所提方法相比,识别精度会稍微低一些。导致这种情况的原因是,CTC决定了不需要单个网络的输出序列的识别精度最高,但是需要整个序列组的输出精度最高,即h(x)=arg maxp(I|y),其中h(x)为输出序列,p(I|y)为真实标签为y的情况下预测标签为I的概率。
3.3 连续动作的识别
实验表明,本文所提方法对单个动作的识别达到了一个较高的准确率。为了进一步衡量本文方法的综合性能,除了测试对单个动作的识别准确率以外,还需要识别在时间上的准确率(假设一个24 s 的时间段,目标执行动作的区间分别为4~10 s,13~20 s,算法需要知道目标在具体哪几个时间段内执行了动作)。由于动作蹲下、站起、跳跃都是一瞬间完成的,因此仅仅对步行、跑步两个连续性动作进行测试。实验中使用长达24 s的数据,总共分4个场景,分别是只执行单个动作(步行,跑步)和执行两个动作(先步行后跑步,先跑步后步行)。单个动作的示例时间表如图9所示,目标第一个执行动作的窗口时间为5~10 s,第二个执行动作的窗口时间为15~24 s。网络输出的是一个序列,一个序列代表着一个时间段,也就是说如果一个24 s数据的微多普勒时频图的宽度为1 536个像素,那么经过主干网络的压缩以后输出一个长度为96的时间序列,也就是说一个序列代表0.25 s的时间,在这个窗口时间内认为动作是没有变化的。因此在最终预测的时候也不完全是连续的时间预测,一旦一个序列预测错误就意味着这0.25 s的预测都错误,该方法的本质上是将连续的时间分割成时间很短的时间序列,然后对这一段时间序列进行特征提取并且认为这段时间序列内只有一个动作。
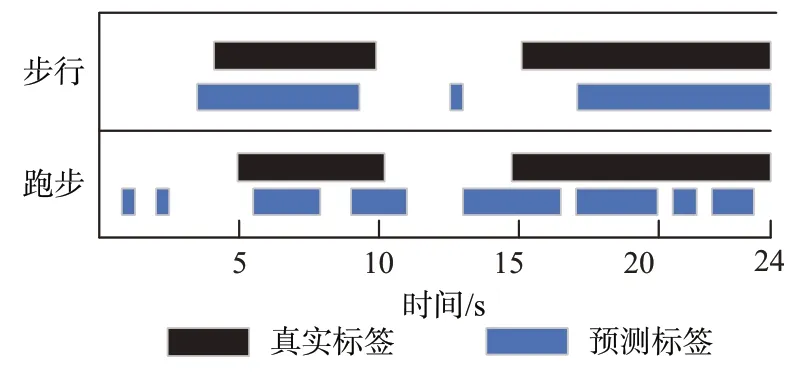
图9 单个动作的示例时间表
执行两个动作的示例时间表如图10所示,目标执行第一个动作的窗口时间为4~10 s,总共6 s,执行第二个动作的窗口时间为15~21 s,同样也是6 s。很显然,该算法在时间上有不错的识别准确率。对一段时间内的两个动作进行识别时,虽然出现时间上没有完全对齐,在没有动作的时间预测执行动作的错误,但是整体上的预测还是正确的,并且没有出现预测顺序错误的情况。出现真实标签和预测标签在时间上没有完全对齐的一个可能性是实验误差,在实验的时候是目标需要在发出信号以后等待到指定的时间区间再执行动作,因此会出现时间上的误差,在执行完一个动作之后目标没有完全立正不动,导致还存在一些微多普勒调制,因此出现误判的情况。

图10 两个动作的示例时间表
4 结束语
本文提出一种FMCW 雷达基于文本识别技术的连续动作识别方法。该方法将不同动作的微多普勒时频图的特征抽象成不同的字符,使用文本识别的思路进行识别。首先对原始数据进行预处理,使用RDM 投影的方法获取微多普勒时频图,从而避免了雷达帧与帧之间的Chirp 不连续导致STFT 变换调参麻烦和功率泄露的问题。然后,将处理得到的微多普勒时频图输入到有卷积神经网络、inception_resnet 和最大池化层组成的主干网络对图像进行提取特征和压缩,将原始输入尺寸为256×w×3 压缩成一个由w/16 个1×1×512 维度长方体特征组成的时间序列,然后输入到两层Bi-LSTM 网络对每个序列进行预测。由于一个目标在固定长度的时间窗口内执行动作的起始时间和结束时间是不同的,数据无法被精确标注,因此最后使用CTC 作为损失函数,对参数进行求导。实验表明,该方法对步行、跑步、蹲下、站起、跳跃这5 种动作的识别准确率分别高达96.16%,95.34%,88.49%,89.37%,96.72%。对一个时间窗口内多个动作的识别也取得了不错的效果,时间上的识别准确率整体令人满意。由于连续的动作存在前后的合法性,比如蹲下以后的动作只能是站起,不能是其他动作,因此下一阶段打算对该方法进行改进用以判断连续动作是否合法。
