深度学习在基于叶片的油茶品种识别中的研究
2023-05-25尹显明张日清莫登奎彭邵锋
尹显明, 棘 玉,张日清*, 莫登奎, 彭邵锋, 韦 维
(1. 中南林业科技大学林学院,湖南 长沙 410004; 2. 湖南省林业科学院,湖南 长沙 410004; 3. 广西壮族自治区林业科学研究院,广西 南宁 530002)
油茶(Camelliaspp.)是山茶科(Theaceae)山茶属(Camellia)油用物种的总称[1]。作为世界四大木本油料树种之一,主要分布于我国南方的湖南、广西、浙江、云南、贵州等省域,其中湖南、江西、广西是主要产区。其综合利用价值较高,在保健、医疗、生物农药、生物饲料、杀菌消毒以及化学工业等方面应用广泛[2]。
近年来,多省份、多学者开展了油茶优良品种的选育研究,至今为止,已有375个良种通过国家或省级审(认)定。国家林业与草原局(原国家林业局)2016年发布《全国油茶主推品种目录》中,列出适宜各省份种植的120个油茶品种,其中主要有“长林系列”“三华系列”“赣无系列”“赣州油系列”“湘林系列”“岑软系列”6大品系。然而我国的油茶生产也随之产生一些问题。王金凤等[1]总结我国油茶产业发展存在的问题,包括良种选育过程不规范导致出现部分“良种不良”和“良种不用”的现象;油茶品种分辨不清、繁育难度不同导致出圃配置不合理现象;造林时品种配置不当、相应品种培育方法不适宜等导致的林地产量低的现象。因此,实现油茶林植株品种的快速分类具有重要的意义。
随着人工智能技术的快速发展,深度学习理论广泛应用于农林业[3-6],其中分类识别研究主要集中于物种种类、种子、果实、叶片病害以及田间害虫方面。不同于早期主要采用基于统计模型的机器学习方法进行研究[7],近年来涌现了AlexNet[8]、ZFNet[9]、VGGNet[10]、ResNet[11]、GoogLeNet[12]等卷积神经网络,可自动提取图片特征进行识别并分类,效果显著,且检测模型能移植到移动设备运行,众多优点使卷积神经网络愈加受到研究人员的青睐。卷积神经网络在叶片分类方面也有一定研究,如韩斌等[13]通过提取多特征使用AlexNet网络对数据库叶片进行识别研究,取得90%以上的平均准确率。原忠虎等[14]基于改进VGGNet网络对外来入侵植物的叶片进行识别,平均准确率达99%。品种分类方面,王建霞等[15]通过VGGNet、Inception-V3网络对10种不同品种的宠物猫进行分类研究,取得较好效果。石洪康等[16]使用MobileNet[17]网络对4龄、5龄的家蚕幼虫进行分类研究,平均准确率达96%。杨静亚等[18]对107种花朵品种使用基于BP算法的卷积神经网络进行分类,取得83%平均准确率。游嘉伟等[19]基于叶片利用目标注意力转换网络对120个大豆品种进行识别研究,取得71.90%平均准确率。
综上所述,卷积神经网络已广泛应用于农林业,基于神经网络对物种品种进行分类已有一定研究,然而基于叶片的品种分类方法研究较少。为减少油茶造林时品种配置不当,或在已造油茶林中不同品种油茶混种导致的培育方法不适问题,现行的油茶品种选育方法大多是基于不同油茶种间或种内杂交获得后代进行选育,不同品种的油茶存在一定的性状差异,油茶叶片的叶形、叶脉及颜色等均存在不同大小的差异。本研究使用深度学习方法对油茶品种进行分类研究,为通过油茶叶片识别油茶品种提供理论依据。
1 材料与方法
1.1 数据获取与预处理
数据集的大小、图像的清晰程度决定神经网络模型的识别效果,为确保模型的可行性,在样本量有限的情况下,本研究在油茶(Camelliaoleifera)林中采集各品种一定数量的叶片,通过智能手机拍摄纯色背景中的油茶叶片,减少外界环境对模型学习的影响。为了减少人工选择的影响,本研究在长沙市路口镇油茶基地随机选择11个油茶品种进行识别研究。随机选择的油茶品种叶片在颜色深浅、大小、叶形等方面存在一定差异;考虑到油茶会在不同时期抽梢,当年抽梢的油茶叶片成熟度难以确定,因此选择位置靠近油茶主干的去年成熟叶片。采集时间2020年8月8日,图像采集设备为智能手机。采集方法为:将完整、无明显病虫害的油茶叶片自叶柄处折断并取下,按品种收集带回,由于不同品种油茶的完整、健康叶片数量存在差异,每个品种采集80~160片油茶叶片,将所有品种叶片带回后使用智能手机进行拍摄。拍摄方法为:使用白板作为背景,将智能手机以特定角度倾斜进行摄影,获得油茶叶片正、背面单色图像(图1),采集的图像包含叶片的颜色、形状、大小、锯齿、叶脉等多种特征信息,已有研究表明,智能手机采集的图像足以作为有效的品种识别材料[20-21]。对拍摄获得的图像进行可用性挑选、裁剪等处理,去除可用性差的图像,最终获得2 791张图像,各品种图像数量见表1。

图1 油茶叶片正、背面图像Fig.1 Front and back images of Camellia oleifera leaf
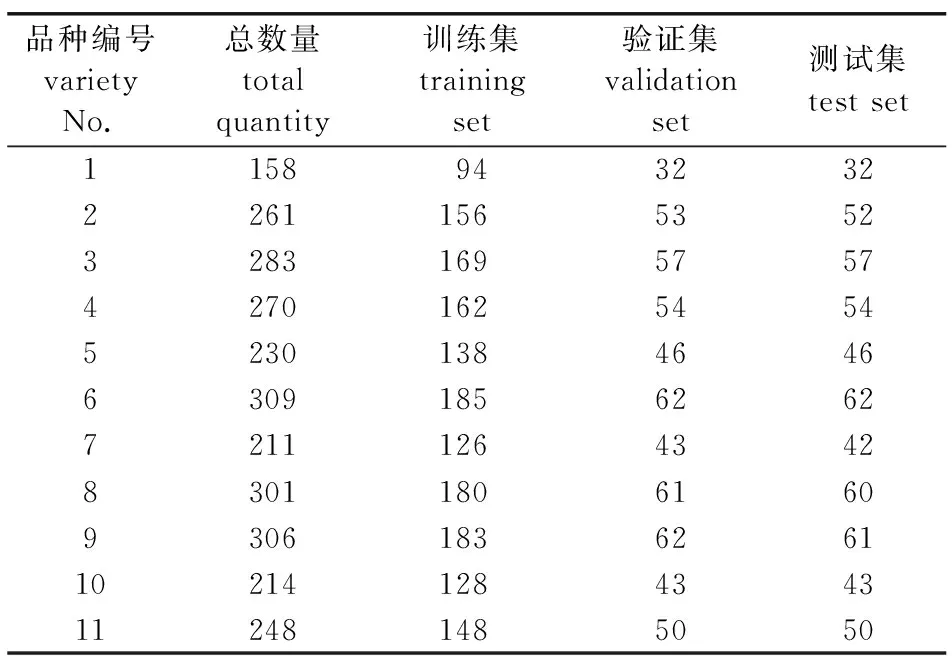
表1 油茶品种图像数据集
1.2 数据集准备
以预处理后的图像(图2)为基础,将图像缩放为299×299大小,按6∶2∶2比例将每一品种图像划分为训练集、验证集和测试集,数量分别为1 669、563和559张。将数据制作成3通道的TFRecords格式数据集,TFRecords是TensorFlow官方提供的一种存储数据格式[22-23],该格式的文件允许用户将任意的数据转换为TensorFlow支持的格式,方便TensorFlow网络对数据集文件进行读取、存储、移动等训练相关操作,从而快速进行训练,而且用文件进行存储更节省内存。制作TFRecords格式数据集的方法为:读取图片后,使用TensorFlow官方提供的函数将图片的数据转换为字符串,与宽、高及类别信息一起转化为二进制格式,存入TFRecords格式文件。

图2 各品种编号油茶叶片图像Fig.2 Images of various varieties of Camellia oleifera
1.3 研究方法
1.3.1 油茶叶片分类算法流程
本研究所提出的算法流程为:采集不同品种油茶叶片,使用手机拍摄获得叶片图像。对采集的叶片图像进行筛选、裁剪等预处理,按6∶2∶2比例划分数据集,使用GoogLeNet和ResNet对训练集、验证集进行训练,使用测试集检验训练模型可行性,调整数据集和模型参数直到模型准确率满足品种识别的要求。
1.3.2 深度学习算法框架
GoogLeNet[12]是Google在2014年提出的分类网络,其在不改变网络深度和宽度的情况下,通过减少网络参数达到提高模型性能的效果,其优点在于使用Inception模块、批归一化方法[24]和辅助分类器。Inception模块使用多尺寸卷积核提取特征并叠加的方法将不同尺度的特征进行融合,较小参数情况下获得较高模型拟合效果,原始的Inception模块见图3A,它通过多个不同大小的卷积核分别提取上层的特征,并将提取的特征叠加传入下层,相比传统的单一卷积核效果更好,但也会带来大量额外的参数。为了解决这个问题,Google在Inception结构中加入了1×1的卷积核,变成了如图3B的Inception V1模块,减少了网络的参数,例如,若上层输出为100×100×128,经过有256个通道的5×5卷积核后输出为100×100×256,参数量为819 200(128×5×5×256),而上层输出先经过一个32通道的1×1卷积核,再经过有256个通道的5×5卷积核后的输出仍为100×100×256,但参数量减少为204 800(128×1×1×32+32×5×5×256);批归一化是指将一批数据的输入值减去这批数据的均值再分别除以这批数据的标准差处理,能够减少训练过程中内部节点分布的变化,减少网络内部协变量移位,进而加速深度神经网络的训练;为防止网络传播过程的梯度丢失,GoogLeNet网络训练中增加辅助分类器,帮助传播梯度,同时提供额外正则化。

图3 Inception模块Fig.3 Inception module
ResNet网络由He等[11]提出,是一种基于多层卷积和恒等映射的网络结构。该网络中残差模块(bottleneck)的基础结构见图4,中间的weight层组成残差块,进行特征学习并传入下层网络,右侧的线条为Shortcut连接,直接将上层学习特征传入下层网络,达到残差模块学习残差的目的。这样一方面通过残差学习减少网络拟合难度,提升拟合精度;另一方面通过Shortcut连接,将上层学习特征直接传入下层网络,有效加速模型的学习速度,同时防止由于深度过深导致的模型效果减弱。

x为上层输入,F(x)为函数学习,F(x)+x为网络输出。x is the upper layer input, F(x) is functional learning, and F(x)+x is the network output.
2 模型训练
2.1 实验平台和参数设置
实验平台:操作系统为64位Windows 10操作系统,深度学习框架为TensorFlow,GPU为NVIDIA GeForce GTX 1660 SUPER,计算机语言为Python。
参数设置:迭代次数设置为36 000次,初始学习率设置为0.001,每批次迭代训练图像的数量为16,每迭代100次测试训练集准确率,每迭代200次测试验证集准确率,每迭代3 000次保存1次模型。
GoogLeNet-V3和ResNet-50两个模型的训练流程如图5所示,GoogLeNet-V3神经网络中叶片图像作为输入传递给模型,提取图像特征后传入连续的多个Inception模块进行特征学习,最后进行平均池化并输出分类结果;ResNet-50神经网络中叶片图像作为输入传递给模型,提取图像特征后传入连续的多个bottleneck模块特征学习,最后进行最大池化并输出分类结果。训练中模型会自动学习叶片图像的颜色、形状、大小、锯齿、叶脉等多层次特征信息。

图5 深度学习网络训练流程Fig.5 The training process of deep learning network
2.2 评价指标
深度学习分类中,常用的评价指标有:准确率(P)、召回率(R)以及识别准确率、召回率的调和平均值(F1)等。准确率(P)是被正确预测为某类样本的样本数与所有被预测为该类样本的样本数比值;召回率(R)是被预测为某类样本的样本数与该类样本实际数量的比值;F1值则是用来对准确率和召回率进行综合评价的指标。
P=TP/(TP+FP)×100%;
(1)
R=TP/(TP+FN)×100%;
(2)
F1=P×R×2/(P+R)。
(3)
式中:TP代表实际品种为目标品种,预测品种为目标品种的样本数;FP代表实际品种不为目标品种,预测品种为实际品种的样本数;FN代表实际品种为目标品种,预测品种不为目标品种的样本数。
对分类模型整体进行评估时,有两种常用的整体F1计算方法,分别是宏观F1(MacroF1)和微观F1(MicroF1)[25-26]。其中,MacroF1是各类样本F1值的平均值,即平均F1值,该F1值不受数据不平衡影响,但易受识别性高的品种影响;MicroF1则是所有样本的召回率与准确率求得的F1值,易受不平衡的数据影响,适合数据较平衡的数据集。
3 结果与分析
3.1 Loss及训练准确率曲线
在上述参数下网络训练的损失与精准度收敛曲线图如图6所示。由损失变化情况可看出,GoogLeNet-V3的初始损失约为3.3,变化趋势为前5 000次快速下降,5 000~10 000次缓速下降,10 000次后趋于稳定,稳定值约为0.75。ResNet-50的初始损失约为5.5,变化趋势为前20 000次稳定下降,20 000次后趋于稳定,稳定值约为3。这说明相比ResNet-50,GoogLeNet-V3的损失相对较低,损失下降速度快,且最终Loss较为稳定。
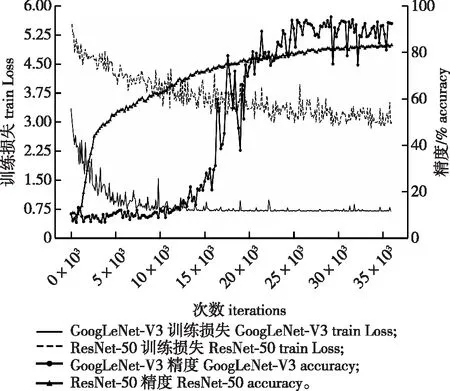
图6 训练Loss与测试精度变化曲线Fig.6 Training Loss and test accuracy change curve
由精度变化情况可看出,GoogLeNet-V3从10 000次开始,精度逐渐升高,从20 000次开始,精度逐渐稳定,总体精度变化浮动较大,精度增长较不稳定,最终精度在90%左右波动;ResNet-50从训练开始精度便逐渐提高,从20 000次开始精度趋于稳定,总体精度变化浮动小,精度增长较为稳定,最终精度在82.5%左右波动。这说明相比GoogLeNet-V3,ResNet-50收敛更快且更为稳定,但最终准确率GoogLeNet-V3比ResNet-50高,两者各有优劣。
3.2 识别准确率、召回率及F1值分析
本研究GoogLeNet-V3与ResNet-50模型的识别准确率、召回率以及F1值(识别准确率、召回率的调和平均值)的计算结果见图7。
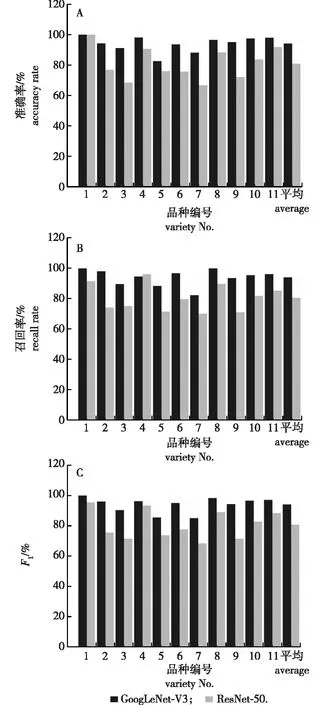
图7 GoogLeNet-V3与ResNet-50模型的识别准确率、召回率和F1值Fig.7 Recognition accuracy, recall rates and F1 values of GoogLeNet-V3 and ResNet-50 models
由图7可知,GoogLeNet-V3的识别准确率较高,各品种均超过80%,品种编号1的识别准确率达到100%,平均识别准确率为94.1%;ResNet-50的较高,各品种均达到60%,编号1的识别准确率达到100%,平均识别准确率为80.9%。相比之下,GoogLeNet-V3的各品种识别准确率均高于ResNet-50,各品种之间的识别准确率差距较小,识别准确率更为稳定。
GoogLeNet-V3的识别召回率较高,各品种均超过80%,品种编号1、8的识别召回率达到100%,平均识别召回率为94.0%;ResNet-50的识别召回率较高,各品种均超过60%,平均召回率达到80.4%。相比之下,除编号4外,GoogLeNet-V3的各品种识别召回率均高于ResNet-50,各品种之间的识别召回率差距较小,识别召回率更为稳定。
GoogLeNet-V3的模型识别准确率、召回率的调和平均值(F1)较高,各品种均超过80%,品种编号1的F1值达到100%,平均F1值为94.0%;ResNet-50的识别召回率较高,各品种均超过60%,平均F1值达到80.7%。相比之下,GoogLeNet-V3的各品种F1值均高于ResNet-50,各品种之间的F1值差距较小,模型效果更为稳定。
3.3 宏观F1与微观F1分析
两个模型的宏观(Macro)F1和微观(Micro)F1值较为接近(图8),说明各品种数据较为平衡,且模型准确率、召回率可信度较高。其中,GoogLeNet-V3的MacroF1达到94.0%,MicroF1达到96.9%;而ResNet-50的MacroF1达到80.7%,MicroF1达到89.0%。说明两个模型均有一定的识别效果,且GoogLeNet-V3模型较ResNet-50效果好,更符合油茶品种叶片分类的需要。

图8 GoogLeNet-V3与ResNet-50的宏观F1与微观F1Fig.8 Macro F1 and Micro F1 of GoogLeNet-V3 and ResNet-50
4 讨 论
油茶品种表型差异小,难以依靠肉眼进行区分。传统识别方法多依靠专家的知识和经验,难以对所有的油茶树进行品种识别。深度学习方法相比依靠专家的人工识别,具有快速、准确、客观等特点,对规范市场秩序、减少人工负担等有重要的意义。因此,本研究采用GoogLeNet-V3和ResNet-50等深度学习框架对油茶叶片进行品种识别研究,通过使用单色背景采集油茶叶片图像,实现对油茶叶片图像品种的快速和准确识别。
4.1 叶片特征识别的影响因素
已有研究表明,光照、环境、遮挡等情况都会对使用叶片图像进行识别造成影响[27]。本研究采用采集叶片后使用白色背景的方法进行图像采集,不涉及遮挡问题,未对油茶叶片进行分割处理,并且利用裁剪图像减少单侧光照带来的影响,后续将更新图像采集设备,使用全方位光照来消除单侧光照的影响。另一方面,在自然光照下进行图像采集,识别更为快速有效,考虑到背景的影响,在进行识别前对油茶叶片进行分割是必要的,因此在自然光照下的油茶叶片图像分割及识别将成为下一步的研究方向。
本研究中使用不同智能手机对油茶叶片进行数据采集,采集的油茶叶片图像分辨率大小、距离远近均存在一定差异,这些差异可能对识别结果产生一定的影响,已有研究[16]同时使用不同设备采集同一品种图像来增加多样性,但并未指出具体影响,因此后续将研究不同智能手机采集图像带来的影响。
4.2 叶片品种识别的精度分析
现有研究进行叶片特征识别时使用的模型多样,本研究使用应用广泛的两种经典模型分别进行油茶叶片识别,验证深度学习应用于油茶品种识别的可行性。对本研究模型分类结果进行对比发现,ResNet-50识别准确率偏低的为3、7号两个品种,GoogLeNet-V3网络对3、7号的识别准确率同样偏低,通过对比图像发现,3、4号及5、7号叶片相似度高,模型分类时易进行错分,因此后续将尝试采用特征提取性能更强的模型以提高模型效果。
5 结 论
1)GoogLeNet-V3的MacroF1值和MicroF1分别达到94.0%和96.9%,ResNet-50的MacroF1值和MicroF1分别达到80.7%和89.0%,均能满足油茶叶片识别的要求。
2)GoogLeNet-V3和ResNet-50识别的准确率分别为94.1%和80.9%,召回率分别为94.0%和80.4%。GoogLeNet-V3的识别效果更好,其对1、8号两个品种的识别召回率均达到100%。综合来看,本次对油茶品种的识别研究有一定指导意义,为油茶品种鉴别提供新思路。
