基于视觉加强注意力模型的植物病虫害检测
2023-05-25范习健薄维昊王俊玲
杨 堃,范习健,薄维昊,刘 婕,王俊玲
(南京林业大学信息科学技术学院,江苏 南京 210037)
植物病虫害是影响植物存活率和生长的主要因素[1],传统的仪器检测和人工识别检测效果已经无法满足当今社会的生产需求[2],如何准确、快速地检测病虫害并采取有效措施成为植物病虫害防治的重中之重[3-4]。机器学习结合传统图像特征提取的病虫害检测技术,因其较好的检测性能得到了较为广泛的应用[5-7]。此类方法往往先提取病虫害图像的形状特征、颜色特征、纹理特征等全局特征,再利用机器学习方法进行训练,进而获得病虫害检测模型。然而,提取图像特征需要大量计算,并且需要专业知识才能获得稳定的性能,导致泛化性能不足,难以应对病虫害种类繁多、环境因素复杂的检测场景。以卷积神经网络(convolutional neural network, CNN)为代表的深度学习技术[8-10]在图像识别和目标检测等计算机视觉任务中得到了应用。农林业科研工作者也将深度学习技术应用于植物与树木的病虫害识别和检测研究[11-12],相关研究表明,基于深度学习和计算机视觉技术的检测模型可以更加快速和准确地发现病虫害,从而满足人们对病虫害测报实时性和准确性的需求[13]。有研究者利用深度神经网络如YOLOv 3、YOLOv 5及注意力机制引入的SSD目标检测框架进行烟草等植物的病虫害检测[14-16],但也存在缺乏对植物病害场景的针对性分析而无法取得最优性能、提出的模型泛化能力相对较弱、具有局限性容易产生漏检现象等缺陷。
笔者针对植物病虫害检测常见的特殊性和困难性,提出了一种基于视觉加强注意力的植物病虫害目标检测模型——YOLOv 5-VE(vision enhancement)。首先运用数据增强技术,丰富部分含有小尺寸病虫害区域的类别样本数,提升对该类目标的学习能力,从而提升模型对小尺寸目标的检测性能,降低漏检和误检率;其次,利用注意力机制提高模型对不同尺度病虫害特征的提取能力,缓解野外环境存在复杂背景干扰问题;最后,引入一种改进的检测框损失函数,增强算法在目标遮挡或者重叠等情景下的鲁棒性,有效提升模型泛化性能。为了充分验证算法的有效性,本研究通过整合两个公开的野外病虫害数据集:病害数据集PlantDoc[17]和虫害数据集IP 102[18],构建了大规模、多类别的病虫害目标数据集,并与现有的目标检测算法进行对比验证,以期改善病虫害检测效果及其实时性,为实际农林业场景下大规模病虫害检测识别提供可行方案。
1 材料与方法
1.1 数据来源
采用涵盖13种植物和17类病害的PlantDoc数据集[17],并与IP 102数据集进行合并,提升场景复杂性的同时进一步丰富了虫害的种类。基于PlantDoc数据集和IP 102数据集的部分样本见图1。

图1 IP 102数据集部分数据样本(a—f)和PlantDoc数据集部分数据样本(g—l)Fig.1 IP 102 dataset(a-f) and partial data samples (g-l) of PlantDoc dataset
IP 102是虫害识别的大规模基准数据集,该数据集包含75 000多张图片,共102个类别。合并后的数据集包含已经用边界框标注了的19 000张图片,共计132类。数据集中包括大多数常见的病虫害,如玉米叶枯病、番茄七星斑病、马铃薯早疫病等植物病害,还有像豆科水疱甲虫、蝗虫总科、盲椿科等常见虫害,以及部分健康的植物类别图片(含非生物胁迫造成的叶片异色)。将合并后的数据集按照70%、20%、10%的比例分为训练集、验证集和测试集。数据集中的原始图像大多分辨率大小不等,为平衡模型检测效率与准确度,将模型输入维度固定,原始图像尺寸(像素维度)被统一调整为640×640。
1.2 YOLOv 5-VE模型
本研究提出的YOLOv 5-VE模型,框架如图2所示。首先对原始图像进行Mosaic 9数据增强[19],将增强后的数据作为模型的输入,提升模型训练的泛化能力;在YOLOv 5目标检测模型主框架中的金字塔特征输出层嵌入视觉注意力增强机制(CBAM),针对不同尺度病虫害特征的表征能力,增强模型降低因复杂背景带来的干扰,有效提升病虫害目标的检测效果;使用DIoU损失函数进行模型训练学习,降低模型对不同程度重叠和遮挡的敏感性,加强目标框的回归,加快损失收敛。
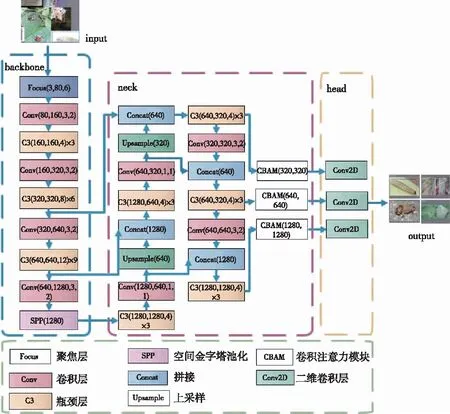
图2 YOLOv 5-VE模型结构Fig.2 YOLOv 5-VE model structure
1.2.1 数据增强
借助数据增强技术,对数据样本进行平移、翻转、裁剪、缩放、颜色转换等多种方式图像变换。上述基本的数据增强技术,在增加训练样本数量的同时,也丰富了样本的多样性,能够有效提高模型的泛化能力。此外,针对植物病虫害检测场景存在不明显以及小尺寸的病虫害区域,受Mosaic数据增强的启发,使用Mosaic 9数据增强技术,将9张图片随机裁剪、随机缩放、随机合并以增加数据中小目标数量,提高模型对小目标的检测能力,降低漏检率。经过Mosaic 9数据增强方法处理的图像见图3,其中的识别框识别了包括小目标在内的大部分检测目标,并且每个识别框都标记了各自目标的种类用于识别分类。在数据增强的过程中还随机添加一些噪声,提高模型对复杂目标的识别能力,增强模型泛化能力。经过基本混合和Mosaic增强后的数据将被送入主网络进行训练。

图3 Mosaic 9数据增强部分示意Fig.3 Schematic diagram of Mosaic 9 data enhancement part
1.2.2 视觉注意力增强的YOLOv 5模型
YOLOv 5模型可以分成3个部分,即主干提取模块Backbone、特征金字塔提取网络FPN和YOLO Head。Backbone是YOLOv 5的主干网络,用于提取特征,使用的是CSPDarknet架构。CSPDarknet对输入模型的图片首先使用Focus网络结构进行特征提取,并通过瓶颈层和卷积层产生3个特征层,同时引入SPP模块,使用不同池化核大小的最大池化操作对最后1个特征层进行特征提取,扩大网络的感受野。Focus网络结构相当于特殊的下采样结构,可有效减少参数量,增加局部感受野。FPN是YOLOv 5的加强特征提取网络,在主干部分获得的3个特征层会在这一部分进行特征融合,将不同尺度的特征信息结合。FPN模块会从已获得的特征层中继续获取特征信息。在YOLOv 5中还使用了PANet结构,该结构会同时通过上采样和下采样进行特征融合,加强网络识别不同尺度目标的能力。YOLO Head是YOLOv 5的分类器和回归器,用于处理经过CSPDarknet和FPN模块后的3个加强特征层,判断其与真实类别间的相似性,检测出目标种类。因此,整个YOLOv 5模型通过特征提取、特征加强、特征判断过程完成目标检测。对YOLOv 5的病虫害实验表明,原模型在进行病害检测时会出现误检、漏检等情况,对原有的YOLOv 5模型进行改进,将一种视觉注意力机制CBAM嵌入特征提取模块[20]。其目的是让模型更专注于找到输入样本中与病虫害相关的有用信息,同时提升模型捕捉不同尺寸病虫害特征的能力,有效降低模型的漏检率和误检率。CBAM模块分为空间注意力和通道注意力两个部分(图4)。

图4 CBAM 总体结构图Fig.4 CBAM overall structure diagram
首先将经过处理的特征图F输入,接着进入通道注意力,分别经过全局最大池化(Fpool,max)和全局平均池化(Fpool, agv)得到C通道对应空间特征F和Fc,avg,再经过由多层感知机(层数为2)组成的全连接层(FCL,式中表示为FCL)后进行像素级的相加,最后由 sigmoid函数σ激活获得通道注意力权重。C通道注意力[CA(F)]计算过程为:
CA(F)=σ[FCL(Fpool,max+Fpool,avg)]=σ{W1[W0(Fc,avg)]+W1[W0(Fc,max)]}。
(1)
式中:W0和W1为全连接层多层感知机第1层和第2层的权重。最终,由输入特征图F和计算得到的通道注意力逐像素相乘生成通道注意力加强后的特征(F′)。
F′=CA(F)⊗F。
(2)
将特征图F′作为空间注意力模块的输入,首先进行基于通道的全局最大池化和全局平均池化操作,得到S空间对应的特征FS,max和FS,avg。这里的池化操作能够提高模型对小尺寸的目标病虫害区域表征能力。接着,生成的两个特征图通过拼接、卷积操作和sigmoid函数生成空间注意力[SA(F′)]图。
SA(F′)=σ[Conv(FS,max,FS,avg)]。
(3)
最后将空间注意力图SA(F′)与该输入特征图F′做逐像素相乘生成最终的视觉注意力加强特征(FSCA)图。
FSCA=SA(F′)⊗F′。
(4)
在本工作中,CBAM被嵌入在YOLOv 5模型的FPN金字塔特征输出部分,用以对提取的多尺度病虫害特征进行加强和优化。嵌入CBAM注意力增强模块的YOLOv 5网络结构见图3的Neck虚框部分。CBAM模块是一种轻量级的通用模块,在病虫害检测场景中,相较于其他注意力机制在精度和速度上具有较好的适用能力。
1.2.3 损失函数
YOLOv 5的损失函数由3部分组成,包括定位损失Lbox、分类损失Lcls和置信度损失Lconf。定位损失预测框与标定框之间的误差;分类损失计算锚框与对应的标定分类是否正确;置信度损失计算网络的置信度。YOLOv 5中的定位损失采用的是LGIoU,而分类损失和置信度损失采用的是BCEBlurWithLogitsLoss (带log值的二叉熵损失)。原模型中的LGIoU损失函数是先计算两个框的最小闭包区域面积,再计算出LIoU,之后计算闭包区域中不属于两个框的区域在闭包区域的占比,最后用LIoU减去这个占比得到LGIoU。但LGIoU存在缺陷,当实际框与预测框水平或竖直重合,或两个框为包含关系时,LGIoU将会退化为LIoU,其次它还存在收敛慢和回归不准确的问题。所以,YOLOv 5-VE用LDIoU替换了LGIoU,LDIoU比LGIoU更加符合目标框回归的机制,将目标与Anchor之间的距离、重叠率以及尺度等多重因素都考虑到,使得目标框回归变得更加稳定,解决了LIoU和LGIoU训练过程中出现的发散问题。LDIoU还可以直接最小化两个目标框的距离,因此比LGIoU收敛更快。对于包含两个框在水平方向和垂直方向上这种情况,LDIoU可以进行快速回归与精确计算,而LGIoU几乎退化为LIoU。LDIoU损失函数计算如图5所示。其中A代表的是预测框,B代表的是实际框,c是包围两个预测框和实际框最小矩形框对角线的长度,LDIoU代表的是实际框和预测框的交集比。

图5 LDIoU示意Fig.5 Illustration of LDIoU
YOLOv 5-VE改进后的损失函数为:
LYOLOv 5-VE=Lbox+Lcls+Lconf;
(5)
Lbox=1-LDIoU;
(6)
(7)
(8)
式中:a和b表示A和B的中心点,ρ(a,b)表示实际框与预测框中心点之间的欧氏距离。LDIoU函数作为损失函数能够应对模型在对小目标植物病虫害进行检测时出现漏检的情况。
1.3 模型训练
本研究训练用的系统是Ubuntu 18.04。CPU型号是Intel(R) Xeon(R) Gold 5 118 CPU @ 2.30 GHz,GPU型号为NVIDIA GeForce RTX 1 080Ti。训练所用的框架为Pytorch 1.10.2,并使用CUDA 11.6并行计算。实验的评价指标选取的是目标检测中常用的几个指标:查准率(Precision),查全率(Recall),测度F1分数(式中表示为F1),平均准确度(AP)。公式如下:
(9)
(10)
(11)

(12)
(13)
式中:TP代表的是真实的正样本数量;FP代表的是虚假的正样本数量;FN则代表虚假的负样本数量;AP是平均精度;而mAP是每种AP的平均值。本研究中选用LIoU阈值为0.5的mAP即mAP_0.5作为指标,Nc则代表总的分类数量。网络训练过程中,参数设置图像输入大小为640×640,批次大小设置为8,总迭代次数设置为100,初始学习率设置为0.01,动量设置为0.937,学习率的衰减方式使用cos函数,优化器为SGD。
2 结果与分析
2.1 对比实验
为了验证本研究提出的模型的有效性,选择YOLOv 3[21]、YOLOv 4[22]、YOLO X[23]以及原始YOLOv 5共4种网络模型在相同的配置环境下利用相同的数据集进行对比实验。选择上文介绍的评价指标从准确度和速度两方面得到对比实验结果。实验结果如表1所示,表1中精度表示的是预测正确的目标占总测试集的百分比,单张检测耗时表示的是检测1张图片所花费的时间,从表1中得出对于植物病虫害目标检测场景,一般的深度神经网络模型效果并不好,而本研究提出的YOLOv 5-VE模型效果更好,平均精度值比最差的YOLOv 4模型高约34%,比YOLOv 3也高出11.3%,比原YOLOv 5模型高8.25%。
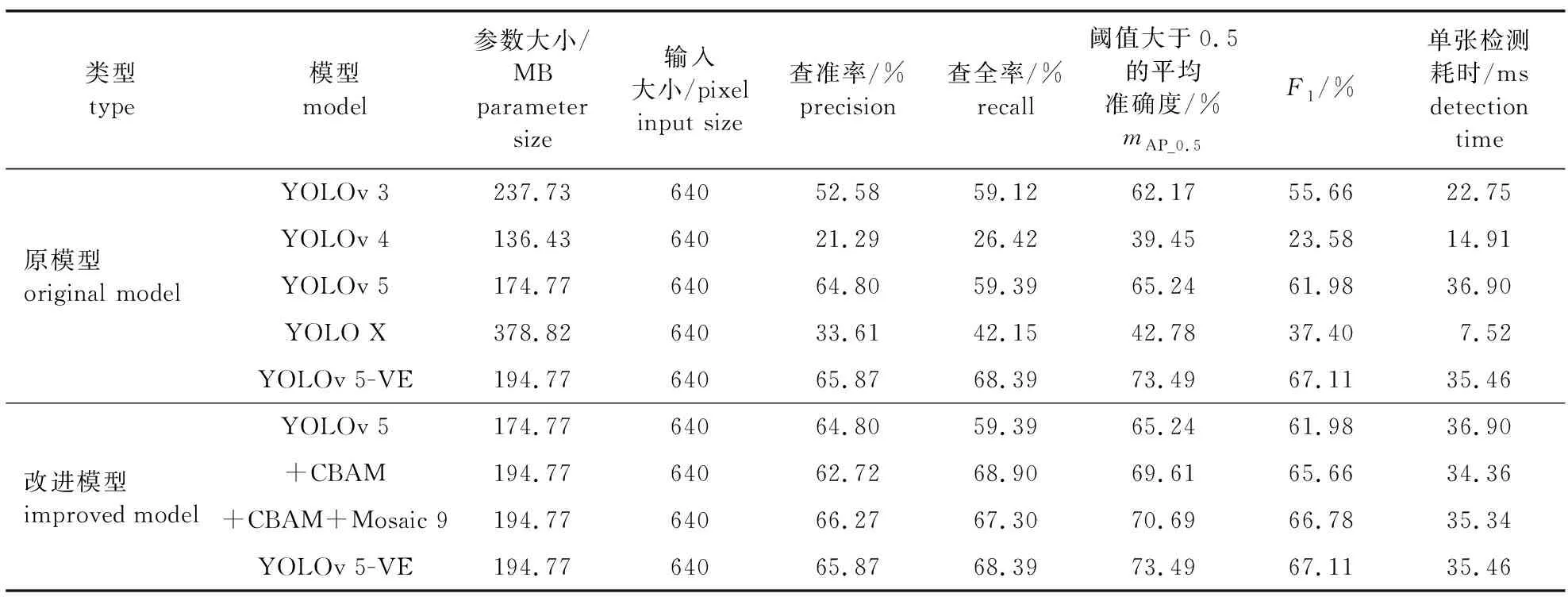
表1 不同网络模型检测能力及性能对比
YOLOv 5-VE模型在数据上的检测表现见图6,由图6可见模型可以准确检测到尺度不同、形状各异的各类病虫害区域。
2.2 消融实验结果
在消融实验中,对添加或改进模块的有效性进行验证分析,对比的模型有YOLOv 5原模型;添加注意力增强模块(CBAM)的YOLOv 5;添加注意力增强模块(CBAM)和数据增强Mosaic 9的YOLOv 5;添加注意力增强模块(CBAM),数据增强Mosaic 9和损失函数LDIoU的YOLOv 5即YOLOv 5-VE,对比实验结果如表1和图7所示。

第1行为真实标签,第2行为原YOLOv 5模型预测标签,第3行为YOLOv 5-VE模型预测标签。The first row images are ground truth, the second row images are using original YOLOv 5 and the third row images are using YOLOv 5-VE.
由图7可见,YOLOv 5-VE在逐步优化过程中检测精度方面表现优异。首先在模型的金字塔特征输出部分嵌入CBAM注意力模块,从表1中可以看出查准率、平均准确度和F1有明显提高;接着将使用Mosaic 9数据增强后,发现无论是查准率、查全率还是mAP_0.5值都有明显提高;最后将原来的loss函数改为LDIoU,即YOLOv 5-VE,检测效果进一步提升。改进后的模型查准率提高了1.07%(提高至65.87%),查全率提高了9%,平均准确度mAP_0.5值提高了8.25%。F1度量是分类检测问题的一个衡量指标,是准确率和查全率的一个调和平均数,综合二者的一个判断指标。F1的大小从0到1,值越大越好,在本研究中F1有着明显的上升,代表了改进后的模型识别效果更佳。此外,从检测速率来看,YOLOv 5-VE模型可以达到每秒35.46帧,实时性良好。为了更好展现YOLOv 5-VE模型的优越性,图8展示了YOLOv 5-VE和其他不同模型随迭代次数的查准率和查全率曲线。
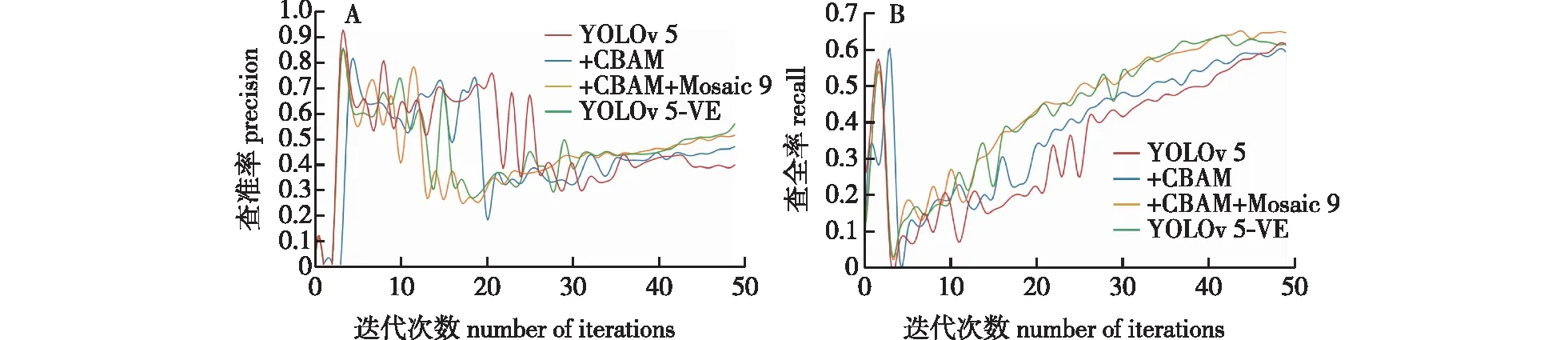
图8 不同模型的查准率(A)和查全率(B)对比Fig.8 Comparison of accuracy (A) and recall (B) of different models
查准率表示真实的正样本占总正样本的比例,所以值越大代表模型识别的精度越高;而查全率表示样本中的正例有多少被预测准确,值越大说明图像中有更多的物体被识别出来。从图8A中查准率曲线趋势可以看出YOLOv 5-VE模型与其他模型曲线在一开始都呈现出急速上升趋势,约迭代15次后出现下降趋势,迭代20次后开始缓慢上升,最终YOLOv 5-VE模型的表现优于其他模型。从图8B查全率的曲线看出几个模型在迭代3次前均呈快速上升趋势,在迭代3~7次之间又急速下降后基本呈上升趋势,最终YOLOv 5-VE模型的表现要优于原始的YOLOv 5。不同模型在实验数据集所得到的mAP趋势见图9,其中的0.5和0.95是阈值设置,mAP值表示对所有分类的目标进行平均计算的平均准确率值,从图9中得出mAP值总体均呈现上升趋势,随着模块的改进,模型的mAP值也在一直提高,mAP_0.5从原模型的65.24%提升到73.49%,而mAP_0.5∶0.95值也从开始的48.04%提高到了52.29%。
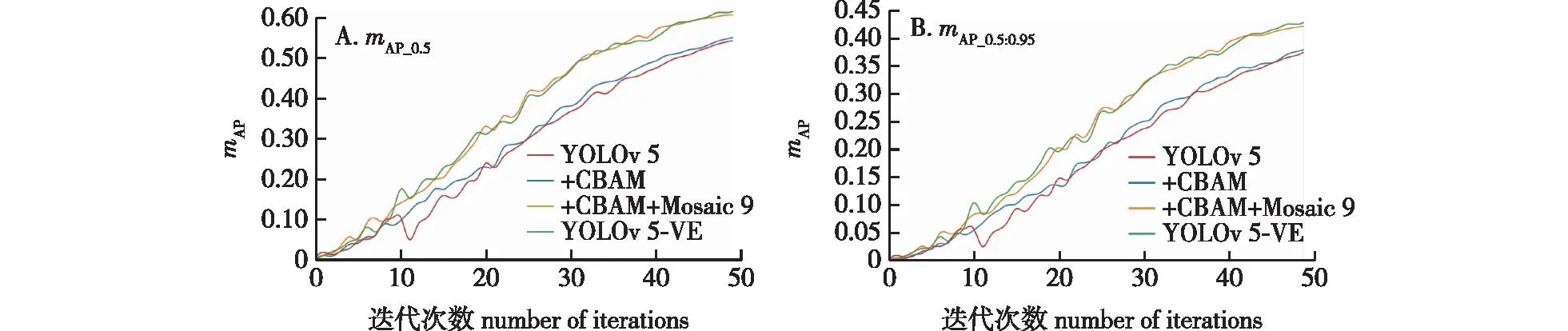
图9 不同模型的mAP_0.5值与mAP_0.5∶0.95值比较Fig.9 Comparison of different models using the metrics of mAP_0.5 value and mAP_0.5∶0.95 value
3 结 论
本研究使用两种数据集即虫害和病害,由于数据的局限性只是在生物层面上进行研究,但作为影响植株健康生长的主要因素,其对模型具有明显的促进作用。针对植物病虫害场景的特点,对原始YOLOv 5模型进行针对性改进构建的YOLOv 5-VE模型,在自制评测数据集上获得的检测效果提升幅度显著,展现了本模型应对大规模、背景复杂、种类繁多的病虫害检测场景的优秀性能。经过实验证明,面对不同目标大小的数据,改进后的YOLOv 5模型都能优秀应对,在上述对比实验和消融实验中,YOLOv 5-VE模型无论在识别目标的分类上还是对于检测目标的准确率上均表现优异,展现了模型的有效性和泛化能力。
针对植物病害和虫害的检测任务,提出了基于视觉加强注意力改进的植物病虫害检测模型YOLOv 5-VE,首先利用Mosaic增强技术丰富样本数量,提升样本多样性,降低训练过拟合风险,再利用CBAM数据视觉注意力机制对原始YOLOv 5的多尺度特征进行加强,提升了模型对病虫害目标特征提取的能力,降低背景干扰,最后用DIoU损失函数替代了原模型的损失函数,降低了损失函数的回归损失,提高了模型的检测精度。整体模型具有良好的鲁棒性和泛化性能,可广泛应用于背景复杂、种类繁多的各类病虫害检测场景。
