论新一代法律智能系统的融合性道路
2023-05-17魏斌
魏 斌
(浙江大学 光华法学院, 浙江杭州 310008)
引言
新一代法律智能系统在演化过程中形成了“机器学习+法律大数据”的法律人工智能道路与“逻辑推理+法律专家知识”的法律逻辑道路。大数据驱动的法律人工智能使用深度学习算法挖掘法律文本大数据,推动了法律文本分析(又称法律文本挖掘)研究,辅助类案检索、判决预测、法律文书自动生成等任务。生成式人工智能ChatGPT就是利用深度学习算法构建预训练大模型,从大数据中学习人类的知识并自动化生成文本,同样在法律文书写作等任务中有良好的表现。法律逻辑道路在兰德尔(C.Langdell)时期受到公理化思想的影响,启发法学理论从法律概念、法律原则、法律规则三个维度来构建法律系统。在弗雷格(G.Frege)之后,受到现代逻辑的影响,法律逻辑学刻画了权利与义务、可废止性、模糊性等属性。基于规则或案例的法律专家系统实现了法律推理的自动化,论辩的人工智能研究又推动法律逻辑学研究法律论证的分析和评估理论。
法律智能系统的两种道路应用于不同领域的法律任务,计算结果的表现力各有差异,在算法过程的透明性和可解释性等方面也各有优劣。法律逻辑学的优点是推理过程透明、可解释,但缺陷是知识获取瓶颈和推理结果表现力弱。大数据驱动的法律人工智能有着良好的预测和泛化能力,优点是学习结果突出并且能避免知识获取瓶颈。然而,人工智能面临着可解释性差、伦理对齐困难、认知推理能力弱等瓶颈问题。(1)参见廖备水:《论新一代人工智能与逻辑学的交叉研究》,载《中国社会科学》2022年第3期。法律逻辑学体现的是符号主义范式,而大数据驱动的法律人工智能体现的是联结主义范式。
符号主义与联结主义范式结合起来是发展人工智能的必经之路。(2)参见张钹、朱军、苏航:《迈向第三代人工智能》,载《中国科学:信息科学》2020年第9期。大数据驱动的法律人工智能作出决定时遵循什么样的逻辑?特别是和法律逻辑相比,究竟有无不同?这是要我们相信并接受法律智能系统的决定之前必须厘清的问题。(3)参见刘东亮:《新一代法律智能系统的逻辑推理和论证说理》,载《中国法学》2022年第3期。大数据驱动的法律智能系统与法律逻辑学的融合,体现的是法律人“知识+数据”的新思维模式,是综合运用法律人的演绎式和归纳式思维的融合范式。新一代法律智能系统既要追求大数据驱动的算法效率,也要以法律逻辑来弥补人工智能算法的不可解释性等缺陷。
一、大数据驱动的法律人工智能及其应用难题
(一)大数据驱动的法律人工智能
大数据驱动的法律人工智能的当前热点是深度学习与自然语言处理技术的融合,法律智能系统在机器学习算法不断升级迭代的过程中不断得到优化,法律任务的结果表现力愈加良好。生成式人工智能ChatGPT就采用了最新的神经网络模型Transformer,它嵌入了自注意力机制(self-attention)和自监督学习的方法,通过模型生成的输出文本与目标文本进行比较,使用反向传播算法更新模型的参数,使得模型更好地逼近目标输出,从而优化模型的预测准确率。法律大数据分析的基础任务是法律信息抽取,它研究的是关于法律文本中要素的抽取,这包括法律概念的抽取,法律文本中案例要素的抽取,合同要素的抽取等。(4)参见Peter Jackson, Khalid Al-Kofahi, Alex Tyrrell, et al., "Information Extraction from Case Law and Retrieval of Prior Cases", Artificial Intelligence, Vol.150, No.(1-2)(2003), pp.239-290.法律文本分类主要是基于不同类型的分类器实现对法律文本的分类,通常使用恰当的方法描述数据的特征,选择的算法分类器通常包括朴素贝叶斯、支持向量机、逻辑回归和神经网络算法等,多标签学习成为流行的方法。(5)参见Enrico Francesconi, Andrea Passerini, "Automatic Classification of Provisions in Legislative Texts", Artificial Intelligence and Law, Vol.15, No.1(2007), pp.1-17.法律文本摘要主要针对法律文本中的关键信息的抽取,较早是通过文本语法表示的语义网络来识别法律文本类型、相关性和重要组成部分。目前的自动摘要多采用监督学习的方法处理结构化的法律文本数据,通过常见的机器学习算法实现法律摘要的抽取。(6)参见Ben Hachey, Claire Grover, "Extractive Summarisation of Legal Texts", Artificial Intelligence and Law, Vol.14, No.4(2006), pp.305-345.
法律预测是文本信息抽取和分类的一种特殊应用。判决预测从包含先例数据的裁判文书等法律文本当中抽取文本信息,然后再应用这些信息去预测新案例的结果,从而达到“举一反三”的效果。(7)参见魏斌:《智慧司法的法理反思与应对》,载《政治与法律》2021年第8期。构建特征工程需要按照相似案件的标准对关键要素进行标注,继而通过对相关事实文本的分类来预测当下法律问题的结果。(8)参见Kevin Ashley, Stefanie Brüninghaus, "Automatically Classifying Case Texts and Predicting Outcomes", Artificial Intelligence and Law, Vol.17, No.2(2009), pp.125-165.法律知识图谱是在法律信息抽取基础上构建的,已成熟应用于法律信息检索,通过搜索引擎理解实体及实体之间的联系,进而搜索可关联的信息。构建法律知识图谱除了需要抽取实体,还需要抽取实体关系,常见的实体之间关系包括因果关系、隶属关系、位置关系、社会关系等,不同的评测方法可能得到不同类型的实体关系。实体关系抽取的方法包括:有监督实体关系抽取方法,这种方法需要通过人为标注数据的方式为机器学习训练模型,然后再对关系的类型进行分类。半监督的学习方法只需要人工少量标注实体关系实例,再基于弱监督关系分类算法来抽取实体关系。无监督学习方法不需要依赖实体关系的标注,实体关系的抽取和聚类算法等都无需人工干预。ChatGPT就采用了人类反馈的强化学习(RLHF)的方法来对输出的结果进行调整,它将收集到的人类反馈的数据通过监督学习的打分模型来获取人类的偏好,然后再使用这个模型通过强化学习来训练生成模型。(9)参见Nisan Stiennon, Long Ouyang, Jeffrey Wu et al., Learning to Summarize from Human Feedback, in Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell (editors), Advances in Neural Information Processing Systems 33, 2020, pp.3008-3021.
从技术实现的机理来看,大数据驱动的法律人工智能采用多种数据分析技术使大数据转变为可供法律人决策的知识,即实现由大数据到知识的转变。首先,法律人工智能构建多模态信息感知的技术,针对文本、语音、图像和视频的数据建立规则模型,使得机器能根据一定的规则来获取多模态的感知大数据,由此得到多模态感知数据库。其次,法律人工智能构建司法知识的认知模型,这类模型对案件要素、人员画像、法律知识、证据知识等构建规则模型和机器学习模型,规则模型依赖于人来制定识别的规则,而机器学习模型是依赖多样化的机器学习算法来自动化识别知识的类型,由此构建司法画像知识库、司法知识图谱与要素知识库。最后,法律人工智能在司法知识认知模型的基础上构建司法决策辅助模型,这类模型根据前述得到的知识来进行决策,分别构建基于逻辑的决策模式和基于机器学习的决策模型。根据这类决策模型所作出的决策就形成了司法决策知识库。法律人工智能的技术机理图表示如图1。
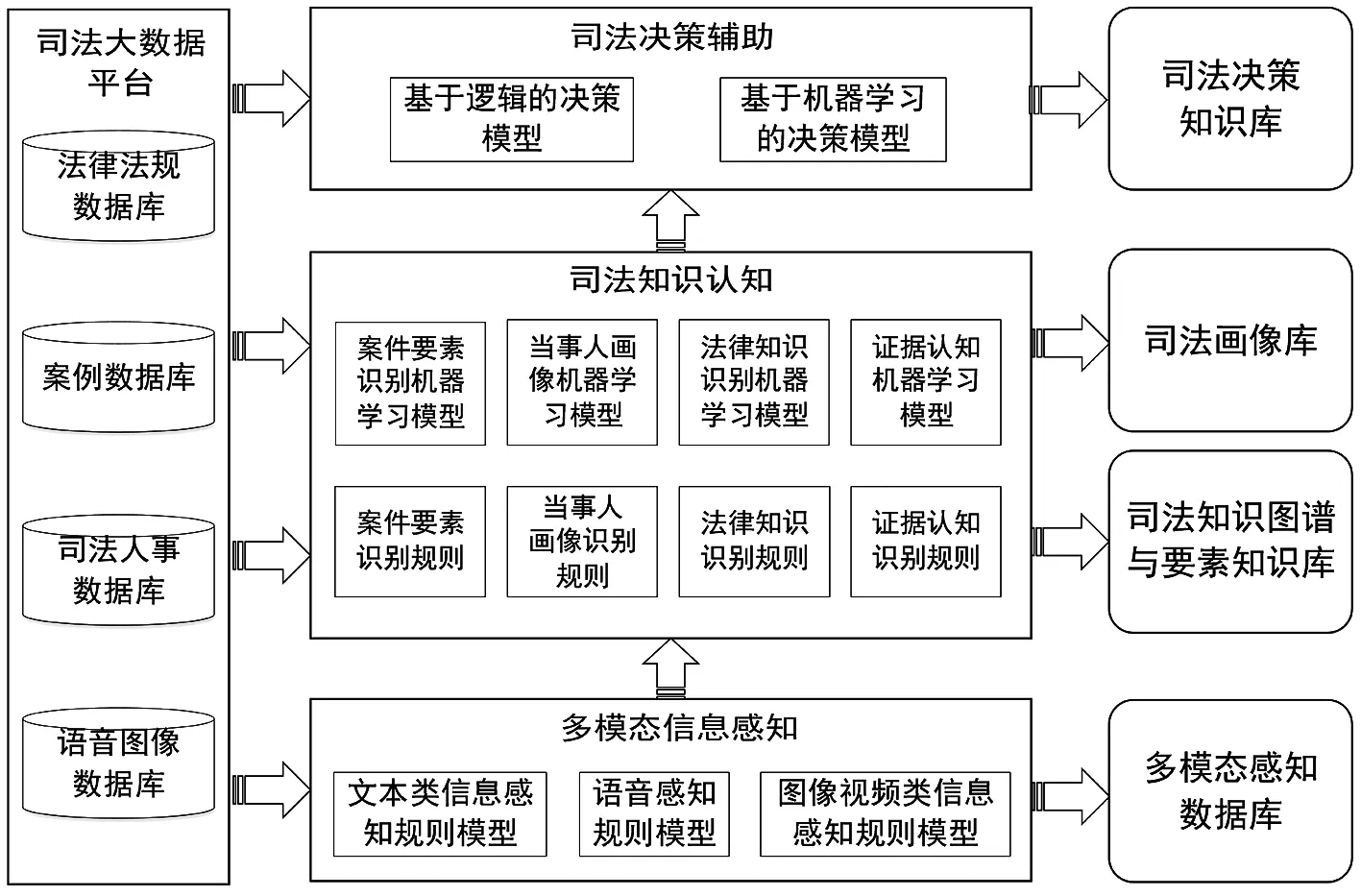
图1 法律人工智能机理图
大数据驱动的法律人工智能推动了法律智能系统由感知智能走向认知智能,由此产生了诸多直接服务于法律实践的应用,尤其以面向“智慧法院”场景的应用最具有代表性。大数据驱动的法律人工智能应用主要包括:(1)法律检索服务。采用自然语言处理技术,以案由、争议焦点、本院查明等指标为检索要素,判定待决案件与检索结果的相似性,由此判定是否属于类案。(2)法律咨询服务。结合计算语言学和语音识别等技术实现精准咨询的法律机器人,向律师和当事人提供法律咨询服务。(3)法律大数据管理。自动检测或提取文档中的条款和关键数据,实现自动文档分类、电子卷宗自动化编目,方便查询和管理关键事项信息和法律资源。(4)法律文本审查和生成。自动获取裁判文书、法律法规和合同文本数据中的关键信息,辅助法律文档审查,实现法律文本自动化生成与校对。(5)法律分析和判决预测。采用自然语言处理技术分析先例大数据,对法官的决策进行司法画像,预测当前案件的判决结果。(6)量刑辅助。通过对审查报告、起诉意见书、公诉书、裁判文书的文本数据分析,根据犯罪事实、量刑情节等案件要素,自动检索并推荐相似案例的量刑结果。
(二)法律人工智能系统的应用难题
人工智能以深度学习的突破性进展最具代表性,大数据驱动的法律人工智能也面临深度学习算法瓶颈与推理模式的缺陷。
第一,深度学习对大数据的容量和质量有很高的要求。一方面,数据的容量必须要足够大,否则深度学习无法发挥作用,达不到训练的目标,容易出现欠拟合和过拟合的问题,甚至比其他机器学习的算法表现力更弱,因而,数据量要达到从量变到质变的效果。另一方面,深度学习需要高质量的数据,数据的质量直接决定了模型训练的效果,垃圾数据输入必然会造成垃圾结果输出。低质量的数据通常存在这些问题:(1)数据来源不明确,可靠性不高;(2)数据信息残缺和不完整;(3)数据不符合目标需求,针对性和准确性弱;(4)数据之间存在不一致或矛盾;(5)数据的可实用性低,特征工程构建困难;(6)重复性数据大量存在;(7)数据不满足独立同分布,难以满足精确标注的要求。在司法领域,数据质量问题十分突出,司法数据往往是半结构化的,它遵循一定的司法文书的写作要求和结构,但又不能完全达到被计算机所理解的结构化要求,司法大数据的质量往往达不到模型训练的要求,因而,难以成功用于数据量少的案件分析。
第二,人工智能的算法仍然存在缺陷。深度学习的基本原理是采用反向传播的神经网络,隐层之间的信号传递方式是上一层往下一层传递,如果在输出层无法达到期望输出,那么变为反向传播,误差就会返回调整权重,直至误差变得最小。(10)参见Yann LeCun, Yoshua Bengio, Geoffrey Hinton, "Deep learning", Nature, Vol.521(2015), p.436.换言之,神经网络的技术竞争力就是反向传播的机制,这种机制是一种循环试错的方法,它通过调整参数,缩小与既定目标之间的误差,这种试错直到习得所要的目标之后才终止。反向传播发现误差并往回传递的方式所采用的是梯度下降的方法,梯度下降是找寻多元函数的方向导数,下降率最快的向量方向就是梯度下降的方向。然而,深度学习算法本身容易造成过拟合的问题,过拟合是指学习能力过于强大,将训练样本自身的特点当作所有潜在样本都会具有的一般性质,也就是把训练样本所包含的不太一般的特性都学到了,这样就会导致模型的泛化能力下降。(11)参见周志华:《机器学习》,清华大学出版社2016年版,第23页。过拟合显示是对模型训练过度的表现,这导致本不该被学习的特征被习得,尽管过拟合能够满足当前的数据集,但是却无法准确预测后续数据的结果。虽然已经有通过正则化和增加数据集等方法来解决这个问题,但是过拟合问题仍然无法完全得到解决。(12)参见魏斌:《司法人工智能融入司法改革的难题与路径》,载《现代法学》2021年第3期。
第三,人工智能最为人所诟病的是算法的不可解释性。深度学习算法尽管能够发现大数据中的规律,但这种规律只是统计意义上的显著性,当数据当中频繁出现两个因果关系的概念,那么预测模型习得这两个概念存在统计意义上的关系,但是机器并不理解这两个概念之间是否存在逻辑上的因果关系。人工智能学界对算法的可解释性的界定存有争议,但是逻辑合理性一定是核心的特有属性。路易斯(D.Lewis)就指出:“解释一个事件就是提供一些关于它的因果历史的信息。在解释的行为中,拥有关于某些事件的因果历史的一些信息——解释性信息。”(13)David Lewis, Causal Explanation, In Philosophical Papers Vol.II, Oxford University Press, 1986, p.217.可解释性最基本的特征就是因果属性,主要采用了相干性理论与反事实条件理论(counterfactuals)。(14)参见Tim Miller, "Explanation in Artificial Intelligence: Insights from the Social Sciences", Artificial Intelligence, Vol.267, 2017, p.4.从因果属性来看,可解释性被理解为一种逻辑合理性,法律逻辑学擅长解释由前提(知识)到结论的过程,精准分析法律论证的结构,评估法律论证的好坏。新一代人工智能推崇的深度学习算法缺乏逻辑上的可解释性,尽管深度学习算法也可能表达数据之间的内在关系和结构,如卷积神经网络处理图像的空间结构和自然语言的时序结构等,但仍然无法解释数据之间的因果联系等逻辑关联。
第四,大数据推理与人类推理有显著差异。以ChatGPT为代表的智能系统采用深度学习算法,其推理能力是通过学习大规模数据而实现的。尽管ChatGPT等智能系统能够求解部分逻辑问题,但是因为大数据推理与人类推理存在显著的区别,因而它在复杂推理和计算方面与人类仍然有较大差距。首先,两种推理的知识来源不同,ChatGPT推理所依据的知识是通过大规模数据学习所得到的,而人类推理是通过经验、事实和规则等作为前提来推得结论的。其次,两种推理的方式不同,ChatGPT的推理方式主要是统计学推断,是通过大数据学习和概率逻辑来进行推理,而人类的推理方式是通过逻辑推理规则来进行推理。最后,两种推理的推断范围不同,ChatGPT受到大数据规模的限制,学习到的知识不会超过大数据产生的知识范围,因而它只能学习知识而不能创造知识,而人类推理的特点在于可以通过归纳和假设等手段发现新的知识。
正是由于法律人工智能系统存在以上问题,使得其仍然难以处理疑难案件,技术上的不可为也印证了对同案同判理论的质疑,正如有观点认为同案同判只是与法律相关的道德要求,它本身并不是一项无法摆脱的法律义务。(15)参见陈景辉:《同案同判:法律义务还是道德要求》,载《中国法学》2013年第3期。疑难案件的成因十分复杂,它既有语言的不确定性、法律方法的有限性、法律的开放性等法律成因,又有社会成因和历史成因。(16)参见孙海波:《疑难案件与司法推理》,北京大学出版社2020年版,第125-134页。复杂的成因导致疑难案件难以适用人工智能处理简易案件的工作机理,案件的要素通常包括事实要素、法律法规要素和判决结果要素,人工智能针对案件要素来构建简易案件的预测模型,但疑难案件的要素是复杂且不清晰的,人工智能在算法标记和预测模型训练等方面存在难以逾越的困难。对于法官都难以判定的疑难案件,人工智能几乎不可能通过数据学习的方法来准确作出判决。
二、法律逻辑学的发展及其挑战
(一)传统与现代法律逻辑学概观
法律逻辑学研究法律推理和法律论证,面向法律概念体系构建、案件事实发现与证立以及法律法规适用等,涵盖了演绎推理、类比推理、归纳推理、溯因推理等推理类型。在西方法律思想史上分析/新分析法学派受到分析哲学与逻辑学的影响,奥斯丁(J.Austin)、凯尔森(H.Kelsen)等法哲学家都强调逻辑分析的重要性。(17)参见陈锐:《论分析哲学与分析法学之间的内在关联》,载《比较法研究》2010年第2期。法律形式主义流派极大地影响了法律逻辑的形式化研究,它认为法律推理应该仅仅根据客观事实、明确的规则以及逻辑去决定一切为法律所要求的具体行为。(18)参见[美]史蒂文·伯顿:《法律和法律推理导论》,张志铭、解兴权译,中国政法大学出版社1998年版,第3页。传统法律逻辑学的符号化方法采用命题逻辑和谓词逻辑,也时常被表达为司法三段论的形式。演绎逻辑不容许结论超出前提的断定范围,就意味着法律后果不允许超出法律规则的溯及范围,那么法律规则必须毫无例外地适用于所有个案。(19)参见魏斌:《法律逻辑的再思考——基于“论证逻辑”的研究视角》,载《湖北社会科学》2016年第3期。在英美法系国家,类比推理广泛应用于案例推理,类比推理是根据两个或两类对象的某些性质相同,从而推理得到它们的其他性质也相同的推理。类比推理是一种或然性和扩展性的推理,结论所断定的范围大于前提中所断定的范围。法律逻辑学还研究法律规范的结构理论与法律论证的模式理论。(20)参见雷磊:《法律逻辑研究什么?》,载《清华法学》2017第4期。阿列克西(R.Alexy)的法律论证理论区分了三种模式:涵摄适用于规则推理,其形式为演绎;权衡适用于原则推理,其形式为重力公式;类比则适用于案件之间的比较。(21)参见雷磊:《类比法律论证》,中国政法大学出版社2011年版,第63页。克鲁格(U.Klug)在《法律逻辑》(Juristische Logik)中除了提到演绎推理和归纳推理之外,还指出了形式逻辑中的类演算和关系演算以及它们在法律推理中运用的可能。(22)参见[德]乌尔里希·克卢格:《法律逻辑》,雷磊译,法律出版社2016年版,第88-100页。
法律逻辑学在早期被认为是以演绎逻辑为代表的传统形式逻辑应用于司法裁判领域的理论和方法,后来采用非单调逻辑等现代逻辑建模的路径,形成了基于规则和基于案例两类典型的可计算模型,为认定案件事实和适用法律法规提供了逻辑引擎。法律逻辑学的研究议题非常广泛,主要体现在三个领域:(1)基于法律的推理(reasoning with the law)研究包括支持法律起草的逻辑、道义逻辑的应用、法律关系表达、法律概念和定义建模、法律规章的时效和修订、例外与层级研究(hierarchies)等;(2)关于法律的推理(reasoning about the law)研究包括法律规则(statutory rule)的推理、法律解释研究、法律论证图式研究等;(3)关于事实的推理包括法律证明的模型、证明责任和假定研究、法律程序模型等。(23)参见Henry Prakken, Giovanni Sartor, "Law and Logic: A Review from an Argumentation Perspective", Artificial Intelligence, Vol.227(2015), pp. 214-245.法律逻辑服务于特殊的法律目的,即正确地进行法律推理。(24)参见雷磊:《法律规则的逻辑结构》,载《法学研究》2013年第1期。这种“正确性”也并不局限于演绎有效性标准,而是诞生了包含可接受性、相关性、充分性等模态要素的新评价标准。
随着非经典逻辑的发展,法律逻辑学进入了现代逻辑的研究范畴。法律逻辑学的现代形态是建立在现代逻辑的基础之上,诸多现代逻辑分支的特性与法律推理或法律论证的特性相符合,满足了法律的模糊性、多义性等法律的价值开放性。(25)参见[瑞]亚历山大·佩策尼克:《论法律与理性》,陈曦译,中国政法大学出版社2015年版,第19页。现代法律逻辑学的研究对象可以归纳为以下几种情况:(1)非单调逻辑(包括缺省逻辑、可废止逻辑、回答集编程)刻画法律推理和法律论证的可废止性。(26)参见[荷]亨利·帕肯:《建模法律论证的逻辑工具》,熊明辉译,中国政法大学出版社2015年版。(2)道义逻辑通常用来表达包含权利和义务关系的法律规范命题、法律规范命题的结构和特征、法律规范推理的对当方阵等。(27)参见[德]乌尔弗里德·诺伊曼:《法律论证学》,张青波译,法律出版社2014年版,第39页。(3)模糊逻辑和DS证据理论研究了法律命题的模糊属性和法律推理的不确定性,如基于模糊逻辑的“不精确涵摄理论”。(28)参见[波]耶日·施特尔马赫、巴尔托什·布罗泽克:《法律推理方法》,陈伟功译,中国政法大学出版社2015年版,第34-42页。(4)概率逻辑和贝叶斯网络等探究证据和事实之间的因果关系,推动了法律推理从模糊的定性研究向精确化定量研究转化。(29)参见[荷]弗洛里斯·贝克斯:《论证、故事和刑事证据——一种形式混合理论》,杜文静、兰磊、周兀译,中国政法大学出版社2020年版。
传统法律逻辑与现代法律逻辑的形态和应用领域归纳如表格1。
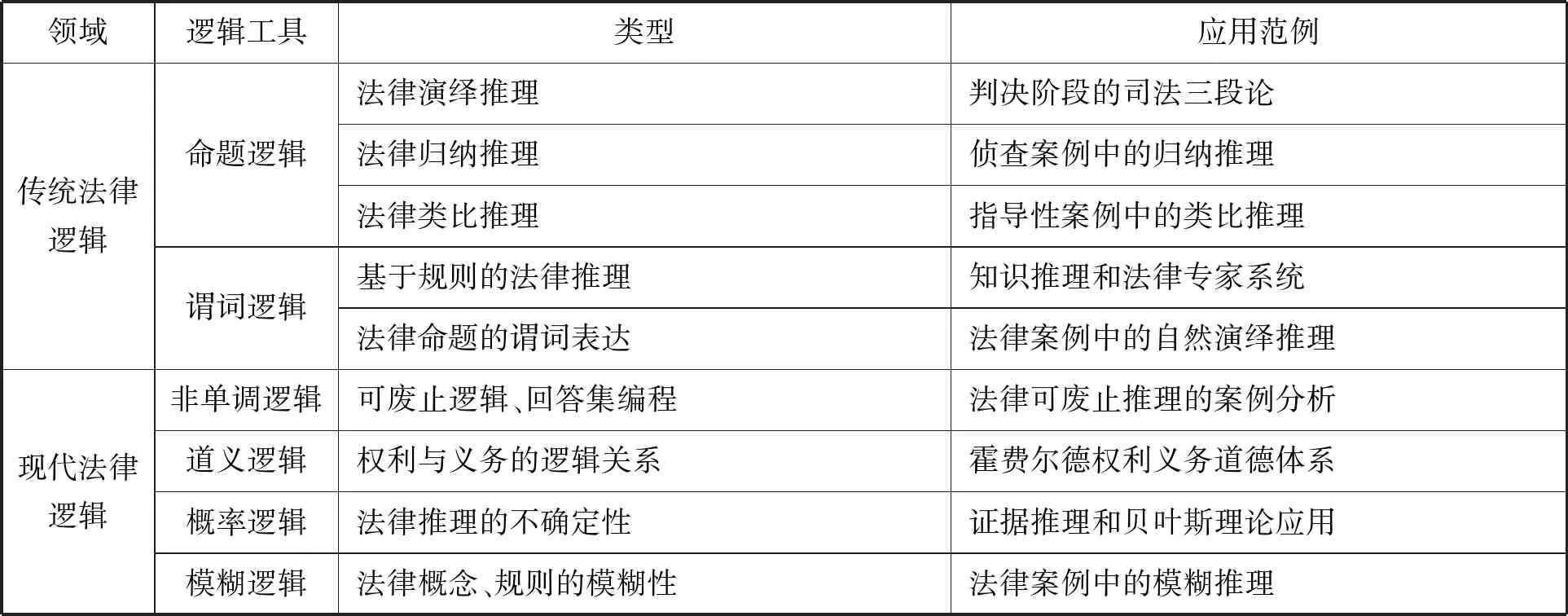
表1 传统与现代法律逻辑
法律逻辑研究还试图提供一种既能用以评估法律推理的有效性,又能指导智能主体从事法律推理活动的形式逻辑系统。(30)参见陈坤:《逻辑在法律推理中没有作用吗?——对一些常见质疑的澄清与回应》,载《比较法研究》2020第2期。法律专家系统(IKBS)的应用使得法律专家知识与知识推理的逻辑相互融合,推动法律知识的自动化应用。法律专家系统多数开发用于支持判决,具有透明性、启发性和灵活性等特点。(31)参见 Richard E. Susskind, "Expert Systems in Law: A Jurisprudential Approach to Artificial Intelligence and Legal reasoning", Modern Law Review, Vol.49, No.2(1986), pp.168-194.法律知识库包含有多样化的知识来源,包括立法、判例、法律文本、专家知识和元知识等。这类系统支持法律推理、法律论证和法律对话呈现的应用,支持基于知识图谱和事理图谱推理的应用,支持案件事实认定的应用,支持法律法规适用和解释的应用等。(32)参见Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017.法律专家系统将法律知识清晰地表示为可描述的形式,使之适用于基于规则的法律推理。知识主体进行推理都必须依赖知识表达,推理进程的好坏也取决于知识表达的优劣。基于案例的推理已经由类比或归纳逻辑转向大数据挖掘的路径,融合知识引导的规则推理和数据驱动的案例推理是当前法律逻辑学的新趋势。
(二)法律逻辑学的新发展——以可计算论辩模型为工具
上世纪90年代末,形式论辩理论在人工智能领域快速兴起,法律逻辑学借助可计算论辩模型研究法律论证理论演化为一个重要研究方向,使得法律逻辑学研究迎来了新的发展契机。图尔敏(S.Toulmin)指出法学(jurisprudence)的主要任务是刻画法律过程的本质:提出、争论和决定法律主张的程序。(33)参见Stephen E. Toulmin, The Uses of Argument, Cambridge University Press, 2003, p.7.从法律程序的视角看,法律推理不再是静态式的推理,而往往体现出动态性的特征,这使得法律推理具备可废止性,法律推理的研究也逐步被包含在法律论证的研究当中。法律论证的可计算模型是利用形式化工具抽象法律论证,得到分析和评价法律论证的模型。由于法律论证被认为是一种合法性、合理性、正当性的证明,而不是一种“真/假”的判断,法律论证的评估标准也从演绎有效性标准走向可接受性等多样化的评估标准。(34)参见焦宝乾:《法律论证:思维与方法》,北京大学出版社2010年版,第67页。早期有波普(W.Popp)和施林克(B.Schlink)研发了用于民事案件事实推理的JUDITH系统,(35)参见Walter G.Popp, Bernhard Schlink, "JUDITH: A Computer Program to Advise Lawyers in Reasoning a Case", Jurimetrics Journal, Vol.15, No.4(1975), pp.303-314.该系统就采用了论辩和对话式的程序,律师可以向系统提问并由系统给出对策建议。帕肯(H.Prakken)研究了法律论证的可废止建模,后来在此基础上发展了一种表达论证结构的结构化论辩框架,并且将其应用于分析Popov诉Hayashi案。(36)参见Henry Prakken, "An Abstract Framework for Argumentation with Structured Arguments", Argument and Computation, Vol.1, No.2(2010), pp.93-124.
法律论证理论也受到古希腊“论辩术”的影响,“论辩术”为分析和建模“可废止性”提供了一种恰当的理论工具,并且形成了逻辑和法学理论领域所使用的“论辩术模型”。(37)参见[荷] 雅普·哈赫:《法律逻辑学》,谢耘译,中国政法大学出版社2015年版,第260-261页。戈登(T.Gordon)与沃尔顿(D.Walton)就受到古希腊哲学家卡尔尼德斯(Carneades)的启发,发展了一种能够刻画不同类型的证明标准和证明责任的卡尔尼德斯模型。(38)参见Thomas F. Gordon, Henry Prakken, Douglas Walton, "The Carneades Model of Argument and Burden of Proof", Artificial Intelligence, Vol.171(2007), pp.875-896.卡鹏(B.Capon)受到新修辞学代表人物佩雷尔曼(C.Perelman)的启发,发展了一种基于价值的论辩模型,将听众加入了论辩模型并且增加了听众对论证的赋值因素。(39)参见Trevor J. M. Bench-Capon, "Persuasion in Practical Argument using Value-based Argumentation Frameworks", Journal of Logic and Computation, Vol.13, No.3(2003), pp. 429-448.最新的研究动态是贝叶斯网络和统计推断在法律论证中的应用,维赫雅(B.Verheij)等还在综合论证、叙事理论和概率论的基础上提出了证据推理的可计算模型。(40)参见Bart Verheij, Floris Bex, Sjoerd Timmer, et al., "Arguments, Scenarios and Probabilities: Connections Between Three Normative Frameworks for Evidential Reasoning", Law, Probability &Risk, Vol.15, No.1(2016), pp.35-70.近些年,论证图式(argument scheme)也成为法律逻辑研究的新方向,(41)参见魏斌:《法律论证人工智能研究的非形式逻辑转向》,载《法商研究》2022年第5期。非形式逻辑学家与人工智能专家合作研究了多达一百余种论证图式,并且开发了Araucaria软件在教学中使用论证图式。(42)参见Fabrizio Macagno, Glenn Rowe, Chris Reed, et al., "Araucaria as a Tool for Diagramming Arguments in Teaching and Studying Philosophy", Teaching Philosophy, Vol.29, No.2(2006), pp.111-124.在新一代人工智能的推动下,法律论证的研究开始呈现出与法律文本解析相融合的趋势,例如,IBM在认知计算机沃森(Watson)基础上研发的法律机器人ROSS就是一个可以理解自然语言提问的智能法律助手,(43)参见Noam Slonim, Yonatan Bilu, Carlos Alzate, et al., "An Autonomous Debating System", Nature, Vol.591(2021), pp.379-385.它将法律推理、法律论证、法律对话的模型与法律文本解析技术相融合,能够以自然语言问答的方式与律师进行专业交流。ChatGPT同样是一种对话式人工智能,用户可以通过问答的方式来获得知识,它甚至在一些对话情境中能够通过“图灵测试”。
(三)法律逻辑学面临的挑战
在传统法律逻辑学看来,道义逻辑、非单调逻辑等存在约根森困境、各种责任的考量、反对把非单调系统标记为“逻辑”等问题。(44)参见[波]耶日·施特尔马赫、巴尔托什·布罗泽克:《法律推理方法》,陈伟功译,中国政法大学出版社2015年版,第79页。但是在大数据时代,法律逻辑学研究面临最紧迫的挑战是知识获取的瓶颈。法律推理不能脱离法律专家知识,它是在形式逻辑的基础上增加了法律知识的特有属性。在法律推理中,连接前提与结论的可废止推论规则往往是需要通过经验概括(generalization)来得到的。证据法学将概括分为两类:第一类是可靠性概括,它包括:依据科学意见(专家意见)的概括、基于常识经验的概括、人们普遍拥有但是并未证明或不可证明的信念、人们强烈相信的偏见、不被强烈持有但仍然有效的信念。(45)参见Terence Anderson, David Schum, William Twining, Analysis of Evidence, 2nd edition, Cambridge University Press, 2005, p.102.第二类是来源性概括,它指的是基于后天知识的综合性(synthetic)或直觉性概括,即得出这些概括的来源暂时不能明确。比如,在某些情况下,一个被看到正逃离犯罪现场的人,可能是罪犯。知识同样会遭受质疑,西奇威克(A.Sidgwick)认为:“既然我们从事实到事实的推论取决于我们关于事实和事实之间联系的一般规则的信念,取决于我们关于自然界失误发生方式的概括,那么,对推论的批判本身就演变为对概括的批判。”(46)Terence Anderson, David Schum, William Twining, Analysis of Evidence, 2nd edition, Cambridge University Press, 2005, p.262.这意味着对于概括的质疑同样也依赖于法律专家的知识。
在法律推理中,概括可以通过重写为条件句的方式来重构为推论规则。法律逻辑的推论规则是形式逻辑的推论规则加上法律领域中的特殊推论规则的结果。(47)参见熊明辉:《论法律逻辑中的推论规则》,载《中国社会科学》2008第4期。从法理学角度看,法律规范是条件式命令(conditional commands),法律规则就是条件式规则,法律规则可以用以下方式表达:“如果……那么……”。(48)参见舒国滢:《法律规范的逻辑结构:概念辨析与逻辑刻画》,载《浙江社会学》2022第2期。从法律逻辑学角度看,概括可以被重构为推论规则,概括起着连接前提和结论的作用,因而构造和攻击推论规则都是针对概括本身的。例如,对于经验概括“在多数情况下,凶手会逃离犯罪现场”,容易重构为一个推论规则“如果凶手在某地实施犯罪,那么他会逃离该地”。又如,根据通常的刑侦经验,有经验概括“有犯罪动机的人会被认为是犯罪嫌疑人的怀疑对象”,容易得到一个推论规则“如果某人有犯罪动机,那么假定他有犯罪嫌疑”。(49)参见梁庆寅、魏斌:《庭审对话的逻辑分析》,载《学术研究》2014年第12期。
无疑,法律逻辑学对于将概括重构为规则并依此推理有可行的方案,但仍然必须依赖于人来构造知识,这就意味着无论是何种法律逻辑系统,都依赖于法律专家知识并基于知识系统来推理。然而,法律逻辑系统无法自动化从法律文本中的案例中获取知识,也就无法自动化构造和预测法律推理或法律论证,这也是依赖于法律专家知识的法律专家系统难以推广的原因。正如卡多佐(B.N.Cardozo)所认为:“法律概念和公式是从先例到先例成长起来的。”(50)[美]本杰明·卡多佐:《司法过程的性质》,苏力译,商务印书馆2019年版,第25页。司法过程就是从先例中获取法律概念、法律原则、甚至是法律规则的知识的过程。按照形式主义的说法,正是“形式化的法律系统”这一理念指导着现存的法律系统理性地发展。(51)参见[以]约瑟夫·霍尔维茨:《法律与逻辑——法律论证的批判性说明》,陈锐译,中国政法大学出版社2015年版,第228页。法律知识接收的瓶颈在法律专家系统中的应用还会表现出自适应能力和自学习能力弱、实时性差等缺陷。(52)参见华宇元典法律人工智能研究院:《让法律人读懂人工智能》,法律出版社2019年版,第48页。大数据时代,大数据分析具备自动化摘要、分类和预测的功能,一定程度上实现了从法律大数据中获取法律知识的目的。法律逻辑学研究需要克服法律知识瓶颈获取的缺陷,借鉴新一代人工智能的数据驱动方法是一个可能的融合路径。
三、新一代法律智能系统的融合原理
新一代法律智能系统的融合体现在大数据驱动的法律人工智能与法律逻辑学的融合。两种路径各有优缺点,在融合上可以借鉴对方的优点来弥补自己的不足。法律逻辑学突出法律人的“演绎式”思维,而大数据驱动的法律人工智能突出法律人的“归纳式”思维,法律人进行决策往往需要综合这两种思维。因而,两种路径的融合本质上是源于两者的相互需要,法律逻辑学有助于解决大数据驱动的法律人工智能的不可解释性和“黑箱算法”等问题,而法律人工智能系统弥补了法律逻辑学的知识表达缺陷,提升了推理和计算结果的表现力。
法律逻辑学与大数据驱动的法律人工智能相融合主要表现在法律推理与法律大数据挖掘的融合。法律推理的前提主要是由证据所构成,还包括常识性事实、自然规律及定理、法律规定的推定事实、程序事实等。法律推理所包含的经验概括需要表达为机器可读的规则,例如,犯罪通常都有犯罪动机,它需要表示为“如果某人犯罪,那么通常他有动机”的推论规则形式才能够被机器所理解。比较而言,法律文本分析依赖于法律大数据,它具备半结构化的特征,法律文本大数据经过人工或半自动标记,再利用机器学习算法来训练模型,进而达到预测的目的。当前,深度学习被认为是效果最佳的算法,模型复杂性和不可解释性与隐层的数量正相关,隐层间信号传播的机制是一种循环试错的方法,即通过调整参数来缩小与既定目标之间的误差,直到习得所要的目标之后才终止,这使得算法的可解释性存在极大的不确定性。法律文本分析的预测效果与文本数据的数量和质量、算法的优劣、模型的复杂度等因素相关。
法律推理与法律文本大数据分析的作用机理不同。法律推理不只是“三段论”式的演绎推理,它还包含了诉诸例外的可废止推理,表现对法律概念、法律原则和规则、先例的可废止性,例如,哈特(H.L.Hart)提出的“车辆禁止进入公园”命题在法律意义上被理解为“凡是机动车都被允许进入公园”,(53)Herbert L. Hart, "Positivism and the Separation of Law and Morals", Harvard Law Review, Vol.71, No.1(1958), p.607.但是当救护车这样的机动车出现时,机动车不能进入公园的结论又被否定,即反映了概念的可废止性。因而,法律推理可废止性在于对法律概念的本体论诠释,对法律规则背后立法意图的理解。比较而言,法律文本分析就缺乏了对法律文本自身的理解,以深度学习算法为例,其本质上是将本文中要素表示为高维度向量,在经过非线性表达之后形成相关的信息表征。然而,这些信息表征不像符号有明确的内涵,例如,案件的案由分类经过深度学习的表征,并不能明确哪些神经元包含了何种案由,这些信息都是一种无序混合的编码形式来存在的。基于法律文本分析的法律预测无法理解当前案件与先例之间的法律关系,尽管深度学习擅长发现概念之间的关联,但是却无法理解概念之间真正的逻辑关系或法律关系。
尽管法律推理与法律文本分析有显著差异,但是两者的最终目标都是为辅助司法裁决,只是实现的方式不同。法律推理对应于制定法推理,而法律文本分析则对应于判例法中的裁判结果预测。从技术原理上来看,法律推理是根据前提,通过逻辑推理来得到结论,而法律文本分析技术是将当前案件数据与语料库中的数据特征进行要素式对比,再利用机器学习模型来预测案件的结果。两者都是由已知的知识或数据作为输入,得到判决结果的过程。我国以制定法驱动的规则推理为主,同时指导性案例制度也确立了案例推理作为辅助的推理模式。法律推理与法律文本分析技术的融合为最大限度地发挥两种推理模型的效力提供了可能。
法律推理与法律文本大数据分析的融合可以借鉴对方的优势,达到相互补充的目的。法律推理的特点在于能够解释前提推出结论的逻辑机理,即结论是如何由前提所推导得出的。法律推理能够支持法律知识的模块化存储和使用,也能够为结论提供清晰的解释,因而,法律推理的优点是推理过程透明并且可解释。在审判当中,法律推理的过程可以解构为“大前提+小前提⇒结论”的三段论模式,其中,作为大前提的法律法规适用又可以分解出固定请求、寻找基础规范、分解规范要件等任务,而作为小前提的案件事实认定则包含检索诉讼主张、整理诉讼争点、证明要件事实、认定要件事实等任务。(54)参见邹碧华:《要件审判九步法》,法律出版社2010年版,第35页。然而,正如前面所论述的,法律推理无法逃避知识获取瓶颈的问题,基于规则的法律推理依赖法律专家来获取法律知识,基于案例的推理不能创制案例知识之外的一般知识,因而受限于案例本身的知识范围。正是由于高度依赖专家来获取知识,法律推理缺乏自主学习和自主更新的能力。
法律文本分析可以从数据中获取规则,替代行业专家的知识构建,达到自主更新和自主学习知识的目标,从而弥补法律推理效率较低的问题,也一定程度上避开了知识获取瓶颈的难题。法律文本分析的优势在于使用机器学习的算法对法律文本大数据进行挖掘,但法律信息抽取、法律文本分类、法律文本摘要和法律预测都难以实现文本内要素之间的逻辑关联,仅体现统计频次的关联。法律文本分析通过统计学分析的方法来挖掘隐藏在文本数据中的规律和特征,并不能理解数据文本中的概念、命题、规则和原则等内容,因而不可避免地产生了不可解释性问题,这也使得法律大数据挖掘的应用饱受争议,如法国《司法改革法》就明确禁止对法官和书记官处成员的身份进行评价、分析、比较或预测。(55)参见王禄生:《司法大数据应用的法理冲突与价值平衡——从法国司法大数据禁令展开》,载《比较法研究》2020第2期。我国“智慧法院”建设在类案检索、司法判决预测、裁判文书自动生成等任务中普遍采用了法律文本分析的技术,由此也产生了不可解释性问题。
从法律推理的特征来看,恰可以弥补法律文本分析的不可解释性问题,法律推理反映了前提与结论之间的逻辑关联,通过符号来表达抽象的概念,并且赋予明确的内涵和外延。法律文本分析技术不可解释的问题在于机器学习算法的统计关联性难以解释输入和预测结果之间的关系,符号化方法的介入将统计关联转化为逻辑关联,从而增强因果关联的可解释性。布兰廷(L.K.Branting)就是主张大数据方法与逻辑方法相融合的积极推动者,他认为逻辑的方法擅长法律文本的逻辑表达和知识推理,能够建模法律论证和证成的规则属性,但缺乏效率而且法律文本的表达技术不成熟,而数据中心的方法擅长经验分析且能够实现预测等目的,但不能表达法律论证和证成的规则属性。法律任务的人工智能研究需要融合基于逻辑的方法和数据中心的方法,从而形成一种复合模型。(56)参见Karl Branting, "Data-centric and Logic-based Models for Automated Legal Problem Solving", Artificial Intelligence and Law, Vol.25, No.1(2017), pp.5-27.
四、新一代法律智能系统的融合路径
新一代法律智能系统的融合思路是发挥两者的优势来弥补对方的缺陷,表现在法律推理与法律文本大数据分析的优势互补。在符号主义与联结主义路径相融合的背景下,法律逻辑学为大数据驱动的法律人工智能的可解释性问题给予了理论阐释,融合路径上既可以将法律推理的逻辑属性嵌入到法律文本分析当中,构建“符号-神经网络”等新方法,也可以从先例文本中学习逻辑关系并预测新的逻辑属性,从而自动化地发现结论、前提及其关系,实现对结论可信度的自动化评估。由此,未来将从法律文本分析的符号化和法律论证挖掘的可解释性研究两个维度来展开融合性研究。
(一)法律大数据分析的符号化研究
法律大数据分析的符号化思想是在法律文本大数据分析中嵌入因果关系等符号化要素,即通过在法律大数据驱动的机器学习中嵌入逻辑推理,使得输入和输出之间呈现出因果等逻辑关联的特征,从而提升可解释性。在法律人工智能领域,学者们很早就关注到神经网络与符号推理之间的关系。菲利普斯(L.Philipps)就试图融合神经网络和模糊推理来刻画法律推理理论,(57)参见Lothar Philipps, Giovanni Sartor, "Introduction: From Legal Theories to Neural Networks and Fuzzy Reasoning", Artificial Intelligence and Law, Vol.7, No.(2-3) (1999), pp.115-128.神经网络和模糊逻辑之间有诸多相似之处,它们之间可以互相适应,神经网络可用于调整模糊逻辑,两种方法应用于法律推理的运行机理有高度的相似性,也可以联合构成一个混合系统。阿什利(K.Ashely)也尝试在案例推理和文本信息抽取两个方面建立起联系,设计了一种SMILE+IBP的算法程序来预测司法判决结果。这套技术的运作思路是通过从已经判决的案例当中抽取文本描述信息,然后再应用这些信息去预测新案例的结果。该程序首先选取一些决定法律结果的要素,接着对法律问题相关的事实文本描述进行分类,而后在这些分类之下,程序进一步评价和解释如何从此前已经分类的案例当中预测当下法律问题的结果。(58)参见Kevin D. Ashley, Stefanie Brüninghaus, "Automatically Classifying Case Texts and Predicting Outcomes", Artificial Intelligence and Law, Vol.17, No.2(2009), pp.125-165.
法律文本分析符号化的主要目的还在于从法律文本数据中获取知识,法律知识图谱成为获取和组织法律知识的新方法。法律知识图谱构建将法律概念看作是图谱中的实体,将实体之间的关系看作是法律概念之间的逻辑关系。法律知识图谱将法律文本中的法律知识以一定的法律逻辑关系联结起来,从而形成法律概念、法律规则、案件事实和证据之间的逻辑关联。技术机理上,知识图谱采用图谱向量化表示方法将法律知识转换为计算机能够理解的知识表示,再使用不确定性推理技术来构建可解释和可回溯的推理模型。知识图谱需要建立高效且稳定的法律知识获取、表达和推理机制,探索从海量、多源、异构的大数据当中大规模、自动化地获取知识,实现大规模的法律知识图谱计算。大规模知识图谱构建采用深度学习等算法将知识图谱的语义信息输入到深度学习模型中,将离散化的知识表示为连续化的向量,最新的研究还尝试将法律知识图谱与图神经网络的结合,采用注意力机制等来构建知识图谱,使得实体之间的关系具备一定的可解释性。然而,传统知识图谱的实体关系仍然没有体现出推理的逻辑相关性。
为了提升知识图谱当中实体之间的逻辑关联性,知识图谱开始朝着事理图谱(EEG)的方向转变,事理图谱被看作是描述事件发展和演化规律的逻辑图谱,这种规律往往表现为事件之间的前后、因果、条件等逻辑关系。(59)参见Marco Rospocher, Marieke van Erp, Piek Vossen, et al., "Building Event-centric Knowledge Graphs from News", Journal of Web Semantics, Vol.37, No.3(2016), pp.132-151.在事理图谱的逻辑关系当中又以因果关系最为重要,事实间的因果关系是法律推理的特点,法律文本中普遍存在因果关系,诸如刑事案件的因果关系说理等都是裁判文书说理中的重要组成部分。法律事理图谱主要挖掘法律文本数据中的因果关系,由此说明输入和输出之间的可解释性。研究方法通过归纳不同案件类型的法律因果关系,将法律推理中的因果关系嵌入到深度学习的神经网络当中,结合深度学习和逻辑编程来实现溯因学习,推理模型需要从裁判文书等法律文本中提取事实因果关系,然后采用贝叶斯网络(BN)和反事实条件句逻辑来研究因果关系推理。以ChatGPT为代表的智能系统采用深度学习算法,数据输入和结果预测之间缺乏清晰的逻辑关联,探索将知识图谱与数据学习的方法相结合,使得机器既知道统计关联性,也理解因果关联性,是未来预训练大模型具备人类智能的一条路径。
(二)可解释的法律论证挖掘研究
大数据驱动的法律人工智能与法律逻辑学的融合路径还可以从法律文本数据中自动化地挖掘法律论证,法律论证本身包含了多样化的法律推理,因而法律论证挖掘能够自动化地获取法律文本大数据中的推理。由于法律信息抽取、法律文本分类、法律检索不能直接识别和给出支持论证或反对论证,因而法律论证挖掘需要识别法律论证的基本单元,并检测基本单元之间的逻辑关系。通常认为,论证的基本单元是由前提集、结论以及推论规则三个部分组成,这些基本单元的组合方式决定了前提与结论之间的逻辑关联,这往往表现为单一型、联合型、收敛型、序列型等论证类型。有机结合形式论辩与现有大数据和机器学习技术,有望在一定程度上突破现有技术瓶颈。(60)参见廖备水:《论新一代人工智能与逻辑学的交叉研究》,载《中国社会科学》2022年第3期。法律论证挖掘在识别法律论证基本单元的基础之上,通过机器学习算法分类器对不同结构的法律论证进行分类。
法律论证挖掘综合应用了法律信息抽取、法律文本分类和法律预测技术,技术使用的步骤如下:首先,法律文本分析需要对训练集中法律文本数据中的法律论证的基本单元进行标记,主要是论证的前提(论据)和结论(主张、论点),再标记出不同类型和结构的法律论证。其次,识别法律文本数据中的论辩性成分,主要识别论辩性的句子,由于论辩性句子可能包含论辩性成分和非论辩性成分,因而还需要识别论辩性句子的边界,明确论辩性句子在文本中的起始位置。再次,识别论证间的关系,主要是论点间的支持关系和攻击关系,方法上可以通过表达推理关系的指示词来识别,例如,如果某个命题A能够推导出命题B,那么A和B之间有支持关系。最后,采用SVM、朴素贝叶斯、逻辑回归、深度学习等算法来训练模型,从而预测前提、结论以及论点间的支持关系和攻击关系。随着BERT模型、LSTM循环神经网络、条件随机场(CRF)等模型的联合应用,法律论证挖掘的准确率和召回率等都有了较大幅度的提升。
法律论证挖掘被用于提升法律文本分析的可解释性,数据间的统计相关性被转化为法律论证中前提和结论的逻辑相关性。有学者在一种CN2算法的基础之上加入论证理论构建了新的ABCN2算法,研究思路是使用这种机器学习算法来对论证解释进行分类。新算法旨在提高学习过程的效率,同时提高机器习得规则的统计准确性和可理解性,使得领域专家能够理解和解释机器所学到的规则。(61)参见Martin Možina, Jure Žabkar, Trevor Bench-Capon, et al., "Argument Based Machine Learning Applied to Law", Artificial Intelligence and Law, Vol.13, No.1(2005), pp.53-73.默恩斯(M.Moens)等针对两种语料库研究了法律论证挖掘,Araucaria语料库是由Dundee大学开发用于支持论证构造的结构化数据库,而ECHR是由欧洲人权法庭的判决文书构成的数据库,研究使用朴素贝叶斯分类器、最大熵模型以及支持向量机三种算法实现了在Araucaria语料库74%的准确率以及ECHR语料库80%的准确率。(62)参见Raquel Mochales, Marie-Francine Moens, "Argumentation Mining", Artificial Intelligence and Law, Vol.19, No.1(2011), pp.1-22.2017年,阿什利在专著《人工智能与法律解析》中也探索了法律推理的可计算模型与法律分析技术的融合道路,提出了法律论证计算模型(CMLAs)与法律文本挖掘相融合的卢依马(LUIMA)系统,该系统从法律案例中提取有关法律规则及其在案件事实认定中法律论证的信息,通过对法律文本中的法律论证进行语义标注,将传统的法律信息检索转换为法律论证检索。(63)参见[美]凯文·阿什利:《人工智能与法律解析——数字时代法律实践的新工具》,邱昭继译,商务印书馆2020年版,第362-363页。
综上,新一代法律智能系统的可解释性体现在逻辑推理与神经网络等机器学习算法的融合当中。法律文本分析符号化的基本思路是对神经网络等技术的符号化,使用逻辑符号来表达神经元并构建神经网络中隐藏层之间的映射关系,进而将逻辑规则的结构化信息转化为神经网络的权重,由此神经网络结构被描述为“符号-神经结构”。法律论证挖掘在于教会机器理解和预测法律论证,通过检测法律文本数据中的论证基本单元以及单元之间的关系,提取不同的论证结构和论证图式,为法律推理的计算模型提供机器可处理的结构化数据。法律论证挖掘的前提和结论之间的逻辑关联提升了法律文本分析技术的可解释性。
结语
新一代法律智能系统的融合性道路是符号主义与联结主义法律人工智能的融合。两者的融合综合了法律人的演绎式思维和归纳式思维,在法律推理和法律大数据挖掘之间架起桥梁,提升了法律智能化应用的可解释性和计算表现力。也应当清醒地认识到,融合路径仍然远没有达到法官、检察官和律师的认知能力,现有的方案仍局限在理论和技术层面的互补性融合。法律实践(法律规范适用)的难题仍然需要逻辑学家建构出更为精致、实用的逻辑操作技术,使司法裁决真正受到法教义学和逻辑的双重检验。(64)参见舒国滢:《逻辑何以解法律论证之困? 》,载《中国政法大学学报》2018年第2期。大数据驱动的法律人工智能与法律逻辑学在融合过程中所遇到的问题对于法学理论构成了极大的挑战,法学研究需要发展出与之相匹配的理论,既能够从法理上给予两者融合充分的证成,也能够从法律方法论视角提供切实可行的融合思路和途径。未来的融合道路还需要善于向法律职业者学习,学会在“人机协同”交互机制中不断完善,突破由感知智能到认知智能的跨越,提升智能化系统的数据理解、知识表达、认知推理和解释能力,实现可解释和可信赖的法律智能化应用。
