基于BiLSTM-EPEA模型的实体关系分类
2023-05-14蒋丽媛吴亚东张巍瀚王书航
蒋丽媛 吴亚东 张巍瀚 王书航
摘 要: 提出一种基于实体注意力相加机制的关系抽取模型BiLSTM-EPEA。即通过BiLSTM(双向的长短期记忆网络)对Glove表示的文本向量进行特征提取,通过EPEA模块分别计算每个字相对于第一个实体和第二个实体的注意力值,并将两个有权重的语句序列逐位相加,最后利用Softmax函数划分实体关系类别。通过实验证明,BiLSTM-EPEA相比于BiLSTM-ATT模型和RBERT模型,F1值分别提升了0.42%、1.47%,验证了模型的有效性。
关键词: 关系类别划分; BiLSTM-EPEA; 实体注意力相加机制; 长短期记忆网络
中图分类号:TP391.1 文献标识码:A 文章编号:1006-8228(2023)05-46-05
Entity relationship classification based on BiLSTM-EPEA model
Jiang Liyuan, Wu Yadong, Zhang Weihan, Wang Shuhang
(Sichuan University of Science & Engineering, Yibin, Sichuan 644002, China)
Abstract: In this paper, a relationship extraction model BiLSTM-EPEA based on entity attention summation mechanism is proposed. The text vector represented by Glove is extracted by BiLSTM, the attention value of each word relative to the first entity and the second entity is calculated separately by EPEA module, the two obtained sequences of weighted utterances are summed bit by bit, and finally the Softmax function is used to classify the entity relationship categories. It is demonstrated experimentally that the F1 value of BiLSTM-EPEA is improved by 0.42% and 1.47% compared with the BiLSTM-ATT model and RBERT model, respectively. The effectiveness of the model is verified.
Key words: relational category delineation; BiLSTM-EPEA; entity attention summation mechanism; LSTM
0 引言
關系抽取是知识图谱构建过程中一个重要环节,旨在从包含两个实体的文本中,提取出两个实体间存在的关系。通过构成的三元组(实体1,实体2,关系)对文本进行结构化的表达。根据训练方式的不同,关系抽取可分为两类:①远程监督关系抽取;②全监督关系抽取。远程监督的方法,通过对外部知识库对实体对之间的关系进行实体对齐,其强假设造成了数据标注错误的问题。在减少人力标注的同时,也使得数据中的噪声较大。全监督关系抽取,实体已经被标注,关系抽取任务被视为一种多分类任务。重点在于如何提取文本中的特征以帮助关系类别的划分。早期的关系分类是直接训练语句,从文本中提取特征进行关系的分类。其文本多通过Skip-gram[1]和词袋模型等[2-3]进行表示,只利用了固定窗口内的语料,而没有充分利用所有的语料,并且忽视文本中的一些字对实体之间关系的表达有着重要作用。
为了能够充分的利用到全局的字的信息并对表达实体关系的词进行强调,本文构建了BiLSTM-EPEA模型。本文的主要贡献在于:一是构建了BiLSTM-EPEA模型,并将该模型应用与实体关系类别划分中,有效的提高了模型的运行效率和效果;二是提出了实体注意力相加机制EPEA(Attention mechanism of entity1 plus entity2),通过计算每个字分别相对于实体1和实体2的注意力值,并将两个注意力值相加,对实体1和实体2之间表达关系的字进行强调;三是在公开数据集SemEval 2010 Task8上进行实验,并对模型进行了消融实验,证明了模型的有效性。
1 相关工作
有监督的关系抽取的效果提升主要有两种方式。一是使用深度学习网络对文本向量进行特征提取并加入特征;二是使用注意力机制对文本中的重要信息进行强调。
1.1 对文本向量进行特征提取并加入特征
2014年,Zeng[4]等人提出一个最大池化卷积神经网络来提供句子级表示并自动提取句子级特征。Zhou[5]等人用BiLSTM来提取上下文的特征。随着BERT[6]模型的提出,Wu[7]等人采用BERT模型对句子进行编码,通过插入不同特殊的字符,将句子分成三部分,并对三部分的信息进行编码。
除了通过BiLSTM、CNN和RNN对文本特征进行提取,许多学者还通过加入外部特征的方式来提高效率。如XU等人[8]加入了实体之间的最短路径信息。但其忽略掉了最短路径是一种特殊的结构,每两个相邻的词都由依赖关系分隔,每个单词设置上位词的方式,不能学习到充足的依赖关系特征。Cai等人[9]则通过BiLSTM+CNN的结构,从前后两个方向沿着最短路径学习每个两个相邻单词的局部特征。但其未考虑到文本中的一些字对实体之间关系的表达有着重要作用。
1.2 注意力机制的使用
除了加入特征,一些学者通过加入不同的注意力机制来提高分类效率。Wang等人[10]和Zhu等人[11]都采用了注意力机制去关注句子的关键部分。但其都没有充分利用到实体的信息。
Ji等人[12]提出了句子级别的注意力机制用于选取有用的远程抽取实例并从Freebase和维基百科上抽取了实体描述信息,构成(实体,实体描述)对。Jat等人[13]通过将每个词的词嵌入和每句话的第一个实体嵌入和第二个实体嵌入分别拼接,通过线性计算得到每个词与实体的相关程度得分,实现实体注意力机制。但其是基于远程监督关系抽取实现的。赵丹丹等人[14]加入了自注意力机制[15]用以计算句子中的每个字对于关系分类的重要程度。但其忽略了字对于实体关系类别划分的作用。潘理虎等人[16]通过用TransE对实体进行向量表示用以突出实体的信息。但TransE不适用于解决一对多的关系抽取问题。Lee等人[17]通过对实体的潜在类型进行预测,对实体信息进行利用,实现模型的端到端训练。
2 方法
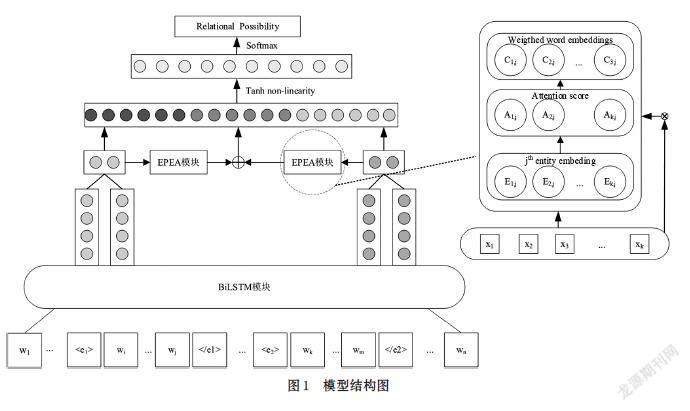
本节主要介绍如何使用BiLSTM对Glove表示的字向量进行特征提取和实体注意相加机制的实现。BiLSTM-EPEA模型如图1所示,模型输入层、嵌入层、实体注意力相加机制层(EPEA)和输出层组成。
输入层:给定一个句子[S=[w1,…,wi,…,wj,…,wk,]
[…,wm,…,wn]],其中[n]为句子的最大长度。[wi…,wj]为实体1所在的位置,[wk,…,wm]为实体2所在的位置。[w1,…,wn]为每个字经过Glove训练后得到的字嵌入,每个字嵌入的维度为100维。
特征提取层:使用双向的LSTM来提取每个字在其上下文的语义表达向量。得到输出序列为[x1,…,xi…,xj,…xk,…,xm…,xn]。
其具体步骤如下:
⑴ 计算遗忘门的值,,选择要遗忘的信息[ft]。其中[xt]当前时刻的输入词,[ht-1]为上一时刻的隐藏层状态。
[ft=σwf?ht-1,xt+bf] ⑴
⑵ 计算记忆门的值,选择要记忆的信息。
[it=σwiht-1,xt+bi] ⑵
[Ct=tanh (wcht-1,xi+bc)] ⑶
⑶ 计算当前的细胞状态。
[Ct=ft?Ct-1+it?Ct] ⑷
⑷ 计算当前时刻隐藏层状态和输出门。
[ot=σ(wo[ht-1,xt]+bo] ⑸
[ht=ot?tanh (Ct)] ⑹
然后得到两个隐藏层状态序列,将两者进行结合,最终得到BiLSTM模块的输出序列[h1,h2,h3...,hn-1,hn]。通过BiLSTM模块的输出,得到每个字的特征序列、头实体的特征序列及尾实体的特征序列。
实体注意力相加机制层:EPEA层用于分别计算每个字相对于第一个实体的注意力值和第二个实体的注意力值。其具体实现过程如下:
假设[si;i∈1…N](N为batch数)和实体对[epm,m∈1,2],一个句子有j个字[xij,j∈1…M],[xij]是每个字的嵌入表示,每个字相对于实体1和实体2的注意力计算值表示如下:
[ui,j,qk=xij×Ak×Ek] ⑺
其中,[xij]为BiLSTM模型输出的每个字的特征表示,[Ak]和[rk]是学习到的参数,[Ak]确定每个字和实体嵌入向量[Ek]的相关性。然后对[ui,j,qk]归一化,得到注意力值。即每个字相对于实体1和实体2的注意力分数值[ae1ij]、[ae2ij],然后,注意力分数值和BiLSTM模型输出的特征表示向量相乘,得到有权重的语句序列。
[ae1ij=expuijl=1Mexpuij] ⑻
[xe1mbij=aij×wij] ⑼
[xembij=xe1mbij+xe2mbij] ⑽
[xemb=[xembi,…,xembj,…,xembn]] ⑾
全連接层:将EPEA模块输出的带有权重的序列[xemb]、实体1的嵌入表示[eemb1]和实体2的嵌入表示[eemb2]进行拼接,即全连接层的输入为[I=eemb1,eemb2,xemb],使用激活函数对[I]进行激活后,输入全连接层。
[h'=w1eemb1,eemb2,xemb)+b1] ⑿
其中,[w∈RL×3d],L为关系类别数,[b1]为偏置向量。
通过[Softmax]函数得到每一个句子相对于19类关系的概率值。取出其中的最大概率即为所分类的关系类别。
[p=softmaxh'] ⒀
3 实验
3.1 数据集及其评价标准
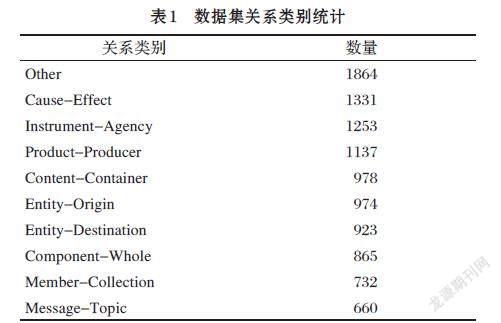
实验的数据集为SemEval-Task8。其中共有19种关系。其关系类别和数量如表1所示。
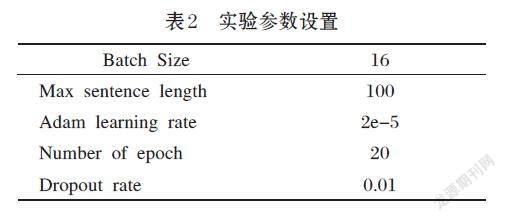
本文实验的效果评价指标为召回率F1值。数据集的数据总共有10717条,采用8:2的比例对实验集和测试集进行划分。实验中的参数设置如表2所示。
3.2 实验结果分析
本文从两个角度对模型进行分析。一是用Glove表示训练字向量和BERT预训练模型训练的字向量对于关系类别的划分的影响;二是实体注意机制是否有效。本文的对比模型主要有:
RBRET[7]:通过BERT提取文本特征,通过加入特殊字符,用于标注实体的位置。其最终用于分类的输入为[contact(CLSemb,eemb1,eemb2)]。一是句首[CLS]的表示,二是实体1的向量表示,三是实体2的向量表示。
BiGRU-EA[13]:通过BiGRU提取文本特征,通过实体注意力关注文本中的与关系有关的词。其输入为[aijhfij,hbij]。其中[aij]为注意力值的大小。
BiLSTM-EA[13]:通过BiLSTM提取文本特征,通过实体注意力关注文本中的与关系有关的词。其输入为[aijhfij,hbij]。
BERT-GRU-ATT[14]:通过BERT得到每个字的向量表示,将向量表示通过BiGRU层提取特征。将BiGRU层的输出通过注意力层得到关系类别的划分。其输入为[aijxij]。
从表3可知,BiLSTM-EPEA取得了较好的效果,相比于RBERT模型,F1值提升了1.47%,其原因在于BiLSTM中加入了文本的特征向量表示,并且对关系划分有重要关系的词增加了权重。相比于BiLSTM-Attention模型提升了0.42%,其原因在于BiLSTM-EPEA加入了实体的特征表示。相比于BiGRU-Attention提升了1.52%,其原因在于BiLSTM性能优于BiGRU。本文将EA层加入了RBERT模型中,发现其分类效果不如BiLSTM- EPEA。其原因在于,RBERT中有大量的线性层,使得模型结构复杂,分类效果下降。RBERT-EPEA模型的效果优于BERT-EPEA模型的原因在于,RBERT-EPEA模型中加入了实体1和实体2嵌入。
3.3 消融实验
实验主要从两个方面展开,一是实体1和实体2的注意力对于关系分类的影响。二是BiLSTM-EPEA中的输入是否应该拼接实体的信息,即输入为[contactxemb,eemb1,eemb2]对关系分类效果的影响。
由于每句话都有两个实体,因此计算每个字相对于实体对的注意力值,会产生两个权重序列。本文对这两个权重序列进行了评估。EA1表示计算每个词对实体1的注意力的得分,从而得到的权重序列。同理可得实体2的注意力权重序列EA2。EA1+EA2则表示将两个权重加在一起所得的权重序列。
由图2(a)可知,通过计算每个字对于实体2的注意力值所取得的分类效果相比于计算每个字对于头实体的注意力值的分类效果。其原因在于关系的方向性。通过统计测试集的数据发现,由实体1指向实体2的关系共有1318条,由实体2指向实体1的关系共937条。其他的是Other关系类别。通过实体注意力相加机制可以发现实体2对于关系类别的影响大于实体1对于关系类别的影响。
由图2(b)可知,通过对两个实体的注意力值进行逐位相加的关系分类效果更好一些。其原因在于,同一个句子对于关系类别有重要作用的字通过逐位相加之后会得到更高的注意力值,从而提高了关系分类的效果。通过导出每个词的注意力值,本文通过注意力值的大小来决定每个字的颜色深浅,直观的表示每个字对关系的影响。由图可知句子为“The
本文通过实现发现,RBERT-EPEA模型和BERT-EPEA模型带来的效果不同,对是否加入实体1和实体2的嵌入进行了实验。通过实验可知,加入了头实体和尾实体的嵌入的效果更好。
4 结束语
本文通过使用Glove训练字向量,将训练好的字向量放入BiLSTM模型中进行特征提取,通过EPEA模块计算每个字相对于头实体和尾实体的注意力值,得到两个权重序列,将两个权重序列逐位相加,得到特征向量表示。然后将特征向量、实体1和实体2的嵌入表示三者进行拼接,通过线性层输出关系类别的概率,从而进行关系类别的划分。通过实验表明,加入实体注意力相加机制和实体对的嵌入有助于关系类别的划分。由于中文的语句表达和英文的语句表达有区别,下一步还应考虑BiLSTM-EPEA模型在中文数据集上的效果。
参考文献(References):
[1] Mikolov T, Sutskever I, Chen K, et al. Distributed
representations of words and phrases and their compositionality[J]. Advances in neural information processing systems,2013,26
[2] Mikolov T, Chen K, Corrado G, et al. Efficient estimation
of word representations in vector space[J]. arXiv preprint arXiv:1301.3781,2013
[3] Pennington J, Socher R, Manning C D. Glove: Global
vectors for word representation[C]//Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP),2014:1532-1543
[4] Zeng D, Liu K, Lai S, et al. Relation classification via
convolutional deep neural network[C]//Proceedings of COLING 2014, the 25th international conference on computational linguistics: technical papers,2014:2335-2344
[5] Zhou P, Shi W, Tian J, et al. Attention-based bidirectional
long short-term memory networks for relation classification[C]//Proceedings of the 54th annual meeting of the association for computational linguistics (volume 2: Short papers),2016:207-212
[6] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of
deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805,2018
[7] Wu S, He Y. Enriching pre-trained language model with
entity information for relation classification[C]//Proceedings of the 28th ACM international conference on information and knowledge management,2019:2361-2364
[8] Xu Y, Mou L, Li G, et al. Classifying relations via long short
term memory networks along shortest dependency paths[C]//Proceedings of the 2015 conference on empirical methods in natural language processing,2015:1785-1794
[9] Cai R, Zhang X, Wang H. Bidirectional recurrent
convolutional neural network for relation classification[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),2016:756-765
[10] Wang L, Cao Z, De Melo G, et al. Relation classification
via multi-level attention cnns[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),2016:1298-1307
[11] Zhu J, Qiao J, Dai X, et al. Relation classification via
target-concentrated attention cnns[C]//International Conference on Neural Information Processing. Springer,Cham,2017:137-146
[12] Ji G, Liu K, He S, et al. Distant supervision for relation
extraction with sentence-level attention and entity descriptions[C]//Proceedings of the AAAI conference on artificial intelligence,2017,31(1)
[13] Jat S, Khandelwal S, Talukdar P. Improving distantly
supervised relation extraction using word and entity based attention[J]. arXiv preprint arXiv:1804.06987,2018
[14] 趙丹丹,黄德根,孟佳娜,等.基于BERT-GRU-ATT模型的中文实体关系分类[J].计算机科学,2022,49(6):319-325
[15] Vaswani A, Shazeer N, Parmar N, et al. Attention is all
you need[J].Advances in neural information processing systems,2017,30
[16] 潘理虎,陈亭亭,闫慧敏,等.基于滑动窗口注意力网络的关系分类模型[J].计算机技术与发展,2022,32(6):21-27,33
[17] Lee J, Seo S, Choi Y S. Semantic relation classification
via bidirectional lstm networks with entity-aware attention using latent entity typing[J]. Symmetry,2019,11(6):785
