基于PNN模型和RF模型的沥青路面使用性能预测研究
2023-05-13赵国武刘涛金磊董磊杨纪举
赵国武、刘涛、金磊、董磊、杨纪举
(1.临沂市公路事业发展中心,山东临沂 276007;2.山东通维信息工程有限公司,山东济南 250000;3.临沂市公路事业发展中心郯城县中心,山东临沂 276037)
0 引言
近些年,随着车辆保有量持续增长,路面行车荷载也随之急速增长,随之带来了沥青路面使用寿命减少、使用性能下降的后果。及时科学预测并评价沥青路面使用性能状态,是实现制定养护策略、保障沥青路面使用和服务性能的关键[1]。目前,针对路面使用性能的评价多依赖于相关规范,未能充分挖掘路面性能使用指数和其他指数之间的关系。现有的研究多通过多项式回归的方法获取路面性能使用指数的表征方式[2]。除此以外,相关权重系数仅通过道路等级确定,而非根据道路实际使用情况确定,如此将导致所得到的路面性能指数预测公式与实际数据贴合不紧密,鲁棒性与泛化性能不强,无法较好地应用于实际当中[3]。因此寻求一种贴合于道路实际使用情况的性能评价方法极为重要[4]。
为了解决上述问题,诸多学者做出了很多努力。张凯星等[5]以广东省的道路数据为研究对象,通过采用BP 神经网络,将路面结构强度纳入路面使用性能考量因素中,最终结果证明,通过此种方法可以在一定程度上对路面使用性能进行评价。张丽娟等[6]同样以广东省沥青路面相关数据为研究对象,基于ARIMA 和支持向量机(SVM)算法构建沥青路面PCI 的预测模型,试验结果表明,此两种方法可以较好地对沥青路面使用性能进行预测。孙鹏等[7]则是通过采用灰色预测模型,实现对沥青路面使用性能指数PQI 的预测。相似的是,商博明等[8]以市政道路路面为研究对象,通过灰色马尔可夫模型实现了对路面使用性能较为准确的预测。总的来说,现在大多数沥青路面使用性能预测多基于数学统计模型(层析分析法、灰色预测、粒子群算法等)以及机器学习模型(SVM、BPNN等),但是大多数研究仅是研究一种算法在路面使用性能预测上的表现如何,缺乏对多种算法对同一路面数据的横向对比研究。
综上所述,本文以临沂市沥青路面数据为研究对象,基于概率神经网络(Probabilistic Neural Network,PNN)和随机森林(Random Forest,RF)构建沥青路面使用性能评价指数预测模型,并以整体预测准确率和子类别预测准确率为评价指标进行对比分析,以得到预测准确率较高的模型来解决沥青路面使用性能指数PQI 的预测问题。
1 PNN 模型和RF 模型预测原理
1.1 PNN 模型基本原理
概率神经网络(PNN)模型是一种较为有效的预测神经网络模型,属于前馈神经网络,是径向基网络的一种变体。从本质上说,此种网络是一种自监督网络,需要特定的标签进行学习识别。相较于多层感知机,PNN 运行速度更快、准确度更高,更为重要的是对于异常值的敏感性更低。总体而言,PNN 由四部分组成,即输入层(Input),模式层(Pattern Layer),求和层(Summation Layer)以及输出层(Output)。PNN的结构如图1所示。输入层用于将所需要学习认知的数据传入网络,模式层则用于计算所输入数据的特征向量与其各自模式的匹配程度,即相似度。值得一提的是,模式层的神经元个数是和输入的数据样本个数保持一致的。
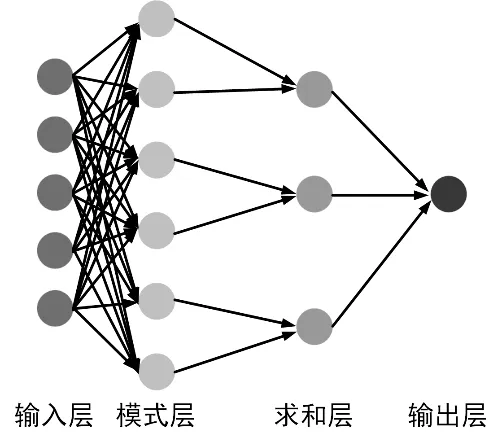
图1 PNN 的结构图
从上述描述及图1 可知,输入层和模式层之间通过某个高斯函数相连接,通过计算模式层和输入层中各个神经元之间的匹配程度并进行累加求和平均数学运算,最后可以预测出输入数据的所属类别。则PNN 的数学计算表达式可用式(1)进行表示
式(1)中:yg表示网络的输出值;lg表示g 类的数量;表示g 类的第i 个神经元的第j 个数据。
1.2 RF 模型基本原理
随机森林(RF)算法,属于集成学习中的Bagging(也称为Bootstrap Aggregation)的方法。RF 是基于决策树而形成的一种有监督学习算法。决策树通过树形结构,利用层层推理的方式学习输入数据的关键特征,进而实现对关键类别的分类学习。从本质上来讲,决策树是一种基于if-then-else 规则的有监督学习算法。随机森林算法就是基于众多无关联的决策树,实现对数据的分类学习。具体来讲,随机森林即是通过组合多种分类器,以投票的方式结合多个分类器的预测结果,进而提升整体算法的预测鲁棒性。总体来说,RF 的数据处理预测主要可以分为三个部分,其运行流程如图2所示。
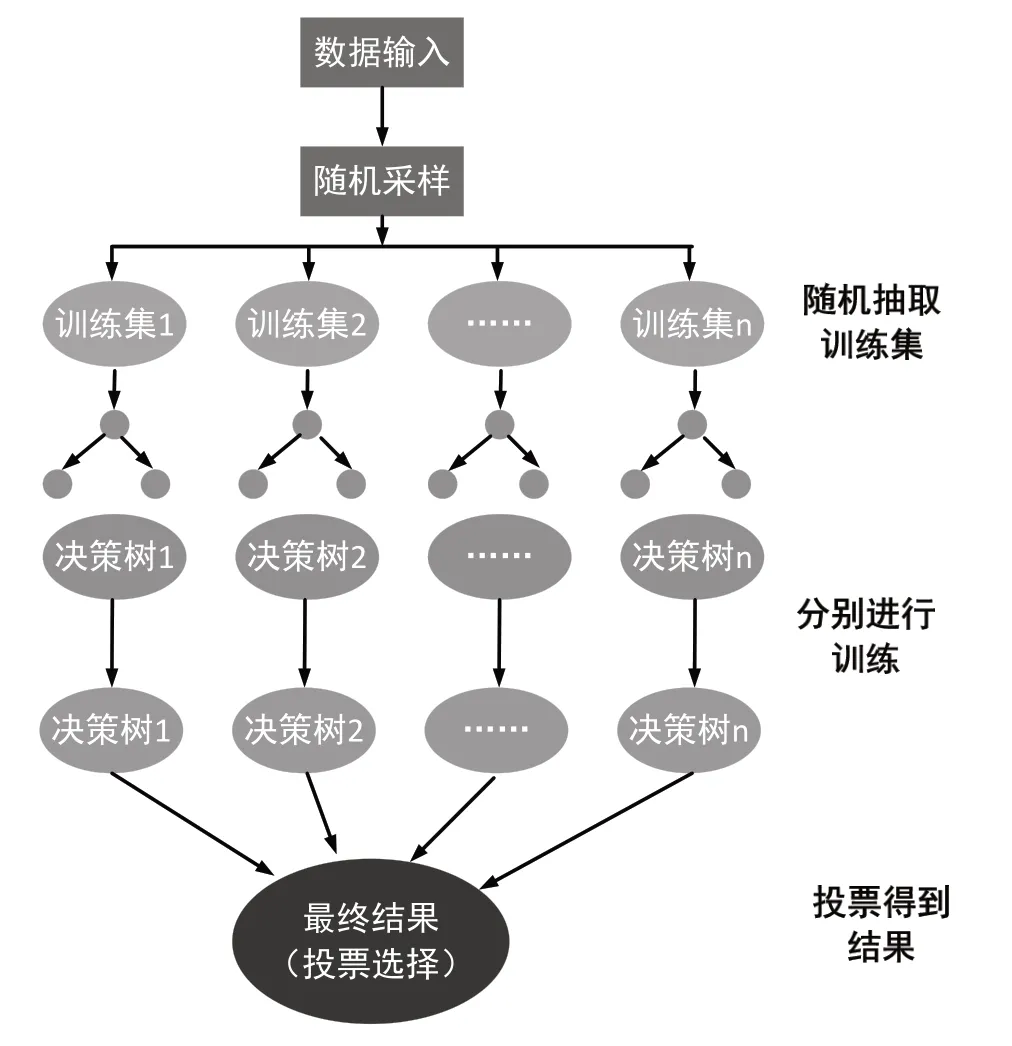
图2 RF 运算示意图
在RF 算法计算过程中,获得一个可靠的预测结果的关键是选取典型的关键特征。其中,基尼系数是特征选择的关键,基尼系数计算方法如式(2)所示。
式(2)中:p表示概率值;K表示某一类别。
2 PNN 模型和RF 模型预测PQI 值对比
2.1 PNN 模型和RF 模型预测PQI 值
本文以临沂市2021年沥青路面使用性能检测数据为研究对象,进行两种预测模型基于行驶质量指数(RQI)、路面状况指数(PCI)、路面车辙深度指数(RDI)、磨耗指数(PWI)以及跳车指数(PBI)5 种路面特征指数对路面使用性能指数(PQI)的预测准确率进行对比研究。现对上述指数进行介绍。行驶质量指数RQI:该指数主要用来反映路面的凭证情况,一般而言,路面的平整度会受到荷载、道路结构、路面材料、外界环境等多种因素影响,之间的影响关系较为复杂。通过一些车载传感器设备可以获取路面平整度信息。路面状况指数PCI:用来反映道路在服役过程中的损坏情况。总体上来说,道路损坏可以分为两种,即外部损坏和内部损坏。该指数主要用来反映路面外部损坏程度。其量化方式主要通过车载摄像机拍摄路面情况,对图中路面损坏情况进行分类统计并量化。车辙深度指数RDI:用来衡量路面在车辆反复荷载下的沉陷深度,是衡量路面舒适程度的重要指标。磨耗指数PWI:该指标主要用于反映路面的整体粗糙程度,可以对沥青路面的表观构造微观特征进行描述。该指标反映了路面的摩擦阻力、降噪能力等特性。跳车指数PBI:该指标从某种程度上反映了路面在服役过程中纵断面的变化情况。
本文基于上述路面评价指标,通过实际数据构建路面性能综合评价指标的表达式。选取了临沂市2021年的数据进行处理并构建。初始得到的数据共有2140 条,通过删除缺损、异常的数据,最终可用的数据共有1220 条。基于PQI 数值大小(0~100)将其分为4 个类别,即优、良、中、次,分别记为4、3、2、1。通过统计可以得出,各个类别下的数据各有847、314、56、3 个样本。由于PQI 类别为1 的样本数据过少,在使用模型进行分析预测的过程中,此类别无法充分学习其特征并得到准确可靠的预测结果,故本文将PQI类别为1 和2 的样本数据合并,统一定为2。
通过基于本文1.1 和1.2 小节所述的PNN 和RF模型基本原理,基于Scikit-Learn 第三方库,用Python 编程语言实现上述计算过程,最后所得的两种预测模型结果如表1所示。
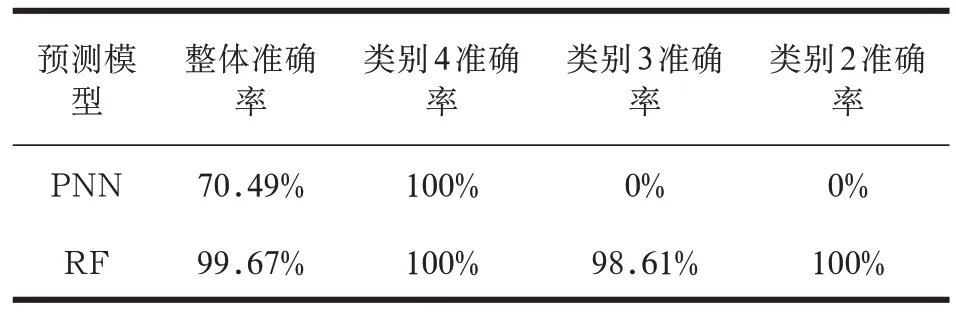
表1 RNN 和RF 模型对PQI 的预测准确率比较(2021年数据)
从表1 结果可以得出,RF 模型在整体预测准确率上远高于PNN 模型,其准确率高达99.67%。除此以外,两种模型针对类别4 样本,即PQI 指数为优秀的类别样本,预测准确率均达到了100%。而对于类别3 和类别2 的样本数据(即PQI 指数为良和中)来说,PNN无法正确预测该两种类别的样本数据,反观RF 模型可以较为准确地进行预测,其准确率分别为98.61%和100%。
造成这种现象的原因可能是,在测试集中的类别2 和类别3 样本数据过少,无法满足PNN 模型对这两种类别样本数据的特征学习,进而不能进行较为准确的预测。另外,从这个结果还可以得到,RF 模型在小样本数据上的敏感性要远低于PNN 模型。
2.2 模型对比及实际应用
为了进一步对比验证PNN 模型和RF 模型在PQI指数验证上的预测鲁棒性和模型泛化性能,本文随机选取了临沂市2019年共计200 组PQI 指数相关数据。使用上述基于2021年训练测试得到的相关模型,在此200 组数据上进行预测。各类别及整体准确率如表2所示。
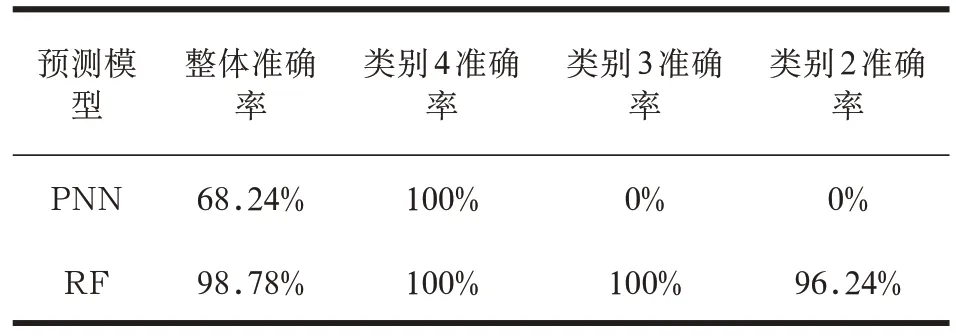
表2 RNN 和RF 模型对PQI 的预测准确率比较(2019年数据)
从表2 中不难看出,RF 模型在整体准确率上依旧优于PNN 模型。两种模型在类别4 样本上均表现出较高的准确率,而在类别3 和类别2 样本数据上,两种模型表现依旧相同。从上述结果可以得出,PNN 模型和RF 模型在本测试集上具有较好的鲁棒性和泛化性能。
3 结论
本文以临沂市沥青路面使用性能相关数据为研究对象,通过PNN 模型和RF 模型分别进行了沥青路面使用性能指数(PQI)预测对比研究,从中得出以下结论:第一,RF 模型相较PNN 模型具有较强的预测能力,整体预测准确率及单个类别预测准确率均较高;第二,RF 模型和PNN 模型均具有较好的鲁棒性和泛化性能,对数据的敏感性较小;第三,PNN 模型相较RF 模型而言具有较强的样本数量敏感性,易因样本数据量多少影响其预测准确率。在之后的研究中,将收集更多数据,使所建立的预测模型可以充分学习获取PQI 指数特征信息。
