融入注意力机制的轻量化可回收垃圾检测方法
2023-05-13郭洲黄诗浩谢文明吕晖张旋旋陈哲
郭洲,黄诗浩,谢文明,吕晖,张旋旋,陈哲
融入注意力机制的轻量化可回收垃圾检测方法
郭洲1,2,黄诗浩1,2,谢文明2,吕晖1,2,张旋旋1,2,陈哲1,2
(1.福建省汽车电子与电驱动技术重点实验室,福州 350118; 2.福建工程学院 电子与电气物理学院,福州 350118)
针对目前智能垃圾分类设备使用的垃圾检测方法存在检测速度慢且模型权重文件较大等问题,提出一种基于YOLOv4的轻量化方法,以实现可回收垃圾的检测。采用MobileNetV2轻量级网络为YOLOv4的主干网络,用深度可分离卷积来优化颈部和头部网络,以减少参数量和计算量,提高检测速度;在颈部网络中融入CBAM注意力模块,提高模型对目标特征信息的敏感度;使用K−means算法重新聚类,得到适合自建可回收数据集中检测目标的先验框。实验结果表明,改进后模型的参数量减少为原始YOLOv4模型的17.0%,检测的平均精度达到96.78%,模型权重文件的大小为46.6 MB,约为YOLOv4模型权重文件的19.1%,检测速度为20.46帧/s,提高了约25.4%,检测精度和检测速度均满足实时检测要求。改进的YOLOv4模型能够在检测可回收垃圾时保证较高的检测精度,同时具有较好的实时性。
可回收垃圾检测;MobileNetV2;YOLOv4;注意力机制;深度学习
随着经济的快速发展,人们的生活水平进一步提高,伴随而来的垃圾产出数量也在逐年增加,垃圾对环境、人们的健康造成的影响也日益凸显,垃圾处理面临着巨大的挑战。垃圾分类是减少垃圾处理量的一种有效方式。由于目前垃圾的种类繁多,很难实现准确分类。随着人工智能的快速发展及计算机算力的不断提升,垃圾分类研究已经受到国内外学者的广泛关注,尤其是对能高效分拣垃圾的智能垃圾分拣设备的研究。比如,美国光学分类设备生产公司设计的Max−AI智能分类机器人,通过扫描物体形状来实现分类,其准确率较高;日本的FANUC分拣机器人,利用视觉分析系统对物品进行跟踪和分类;中国的Picking AI垃圾分类机器人,利用人工智能算法、机器人控制等技术实现垃圾分拣。上述分拣机器人的分拣功能较单一、占用面积较大、价格昂贵,因此无法大规模应用。随着深度学习技术的快速发展,基于深度学习模型解决的问题也越来越多。由此,可以将深度学习技术应用于智能垃圾分拣设备,以解决当前垃圾分类困难和人工分拣效率低等问题。
近年来,基于深度学习技术的目标检测算法发展迅速[1]。目标检测算法主要分为两阶段算法和一阶段算法。两阶段算法首先采用传统的选择性搜索(Selective Search)及后来更新的区域生成网络(Region Proposal Network,RPN)生成候选区域,然后对候选区域特征进行提取和分类,得到最终的检测结果,其特点是精度较高,缺点是检测速度较慢,以Fast R−CNN(Fast Region-Convolutional Neural Network)[2]、Faster R−CNN[3]等算法为代表。一阶段算法直接在整张图片中生成若干候选框,即可同时得到目标的位置和类别信息。虽然一阶段算法的准确率相对于两阶段算法较低,但其检测速度更快。目前,通常将一阶段算法用于实时检测的场景,以SSD(Single Shot Multibox Detector)[4]、YOLO(You Only Look Once)[5-8]系列,以及RetinaNet[9]等算法为代表。其中,RetinaNet提出的 Focal Loss解决了一阶段算法正负样本不均衡的问题,提高了一阶段算法的检测精度。当前,深度学习目标检测方法在垃圾目标检测方面开展了一系列研究。赵珊等[10]提出了一种基于IFPN+MobilenetV2−SSD模型的垃圾实时分类检测方法,使用MobileNetV2作为SSD的主干网络,加入带有空洞卷积的空间金字塔池化模块,提高了模型的检测精度和检测速度。马雯等[11]提出了改进的Faster R−CNN垃圾目标检测模型,实验结果表明,与传统Faster R−CNN算法相比,其平均精确度提高了8.26%,综合识别率达到81.77%。许伟等[12]提出了一种基于YOLOv3算法的轻量级垃圾目标检测算法,能有效地对垃圾目标进行检测。李庆等[13]基于YOLOv4提出了嵌入注意力机制的目标检测算法Attn−YOLOv4,经实验验证,比原始YOLOv4算法的平均精度(Mean Average Precision,mAP)提高了0.16%,实现了对运动垃圾的快速稳定跟踪,在20 mm误差范围内达到0.945的精确度。Kumar等[14]建立了一个垃圾数据集,共包含数量为6317张的垃圾图像,在YoLov4模型中训练,平均精度达到94.99%。
上述方法虽然在一定程度上有效地提高了垃圾分类检测的精度和速度,但很多检测方法的参数过多,导致内存占用较大,其检测精度和速度存在较大的改进空间;存在不注意特定场景和标准数据集场景之间差异的问题,不能达到与通用数据集相同的结果;存在因垃圾目标样本中的小目标样本导致的正、负样本不平衡,从而出现垃圾分类检测精度低的问题。针对以上问题,文中提出了一种基于YOLOv4改进的轻量化可回收垃圾检测方法,通过优化网络模型结构和减少模型参数来提升检测精度和检测速度,使网络模型在满足检测精度的同时保证了检测速度。
1 相关网络模型及原理介绍
1.1 YOLOv4网络模型
YOLOv4是一种端到端的目标检测模型,在YOLOv3的基础上进行改进,并经过不断的模型优化,模型的检测精度和速度达到了不错的水平。YOLOv4整体结构大致分为3个部分。
1)主干特征提取网络。YOLOv4采用CSPDarknet53作为主干(Backbone),包含由29个卷积层堆叠而成的5组(Cross Stage Partial Network,CSPNet)模块[15]。CSPNet结构可以增强卷积网络的学习能力,减少模型的计算量。通过对主干网络进行特征提取,得到了3个有效特征图,尺度分别为13×13、26×26、52×52。不同尺度的特征图包含不同维度的目标语义信息。
2)颈部特征融合网络。包含空间金字塔池化(Space Pyramid Pool,SPP)模块[16]和路径聚合网络(Path Aggregation Network,PANet)[17]2个部分,SPP网络对Backbone输出的13×13特征图进行了1×1、5×5、9×9、13×13等4种尺度的最大池化(Maxpooling)操作,有效提高了网络的感受野。PANet相较于特征金字塔网络(Feature Pyramid Network,FPN),增加了一条自下而上的增强路径,加强了对浅层信息的提取,提高了模型的检测精度。
3)头部预测网络。对特征融合网络输出的3个不同大小特征图的信息进行解码,分别检测小、中、大3个目标,在原图上输出检测目标的位置和类别。
1.2 MobileNetV2网络结构
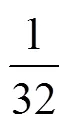
深度可分离卷积将卷积分为2个过程:深度卷积,采用3×3的卷积核进行DWConv操作;逐点卷积,采用1×1的卷积核进行普通卷积操作。深度可分离卷积操作在参数量和计算量上比标准卷积操作更少,标准卷积和深度可分离卷积两者的卷积过程如图1—2所示。

图1 标准卷积
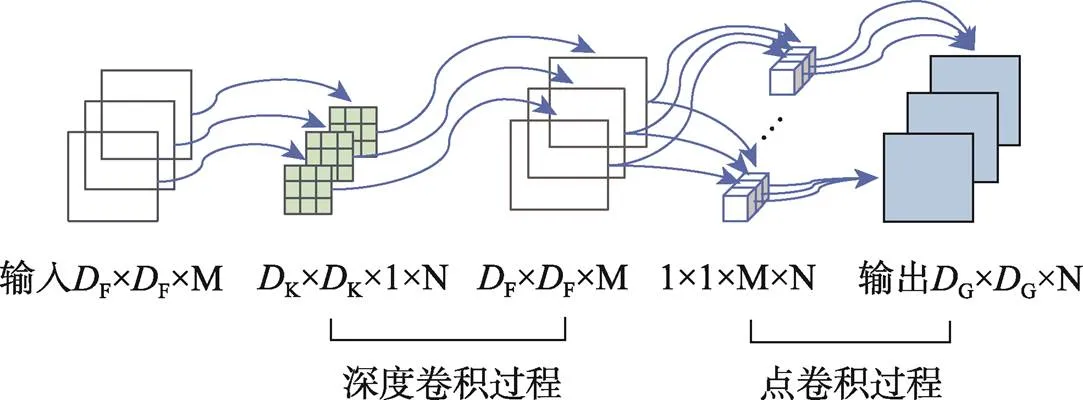
图2 深度可分离卷积
对于输入为F×F×的特征图,F为输入特征图的高度或宽度,为通道数。对特征图进行卷积操作,卷积核大小为K×K,卷积核的数量为,通道数为1,输出特征图的大小为G×G×,G为输出特征图的高度或宽度,为通道数。
对特征图进行标准卷积的过程中的计算量1和参数量1如式(1)—(2)所示。

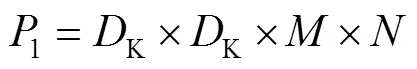
在对特征图进行深度可分离卷积过程中的计算量2和参数量2如式(3)—(4)所示。
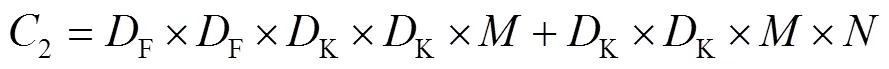
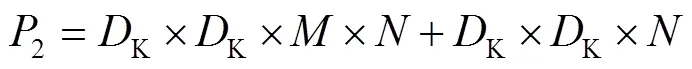
深度可分离卷积与标准卷积计算量之比的计算如式(5)所示。
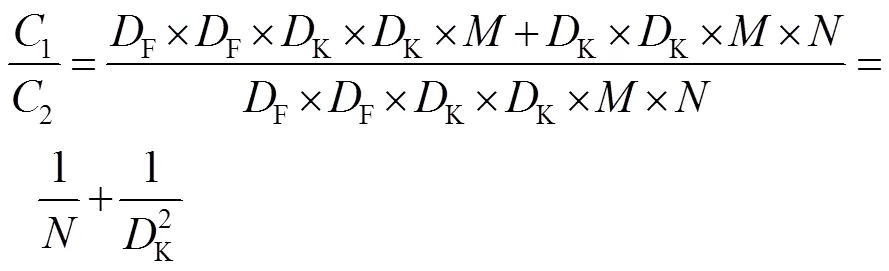
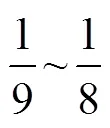
MobileNetV2是在MobileNetV1的基础上引入具有线性瓶颈的倒残差结构[18]。残差模块先对特征图进行压缩,然后再扩张,而倒残差结构与之相反,先对特征图进行扩张,然后再压缩。MobileNetV2有2种倒残差模块,如图3所示。当stride=1时,特征图首先通过一个1×1的卷积来提升通道维度,且激活函数使用ReLU6,然后通过一个3×3的深度卷积进行特征提取,且激活函数使用ReLU6,最后通过一个1×1的卷积来降低通道维度,并采用线性激活函数。为了避免特征信息的损失,采用Linear线性激活函数,接着将输出结果与输入进行shortcut拼接。当stride=2时,与stride=1时的原理差不多,唯一不同的是无shortcut拼接。因为输出和输入的特征图尺度不一样,所以无法进行shortcut拼接。
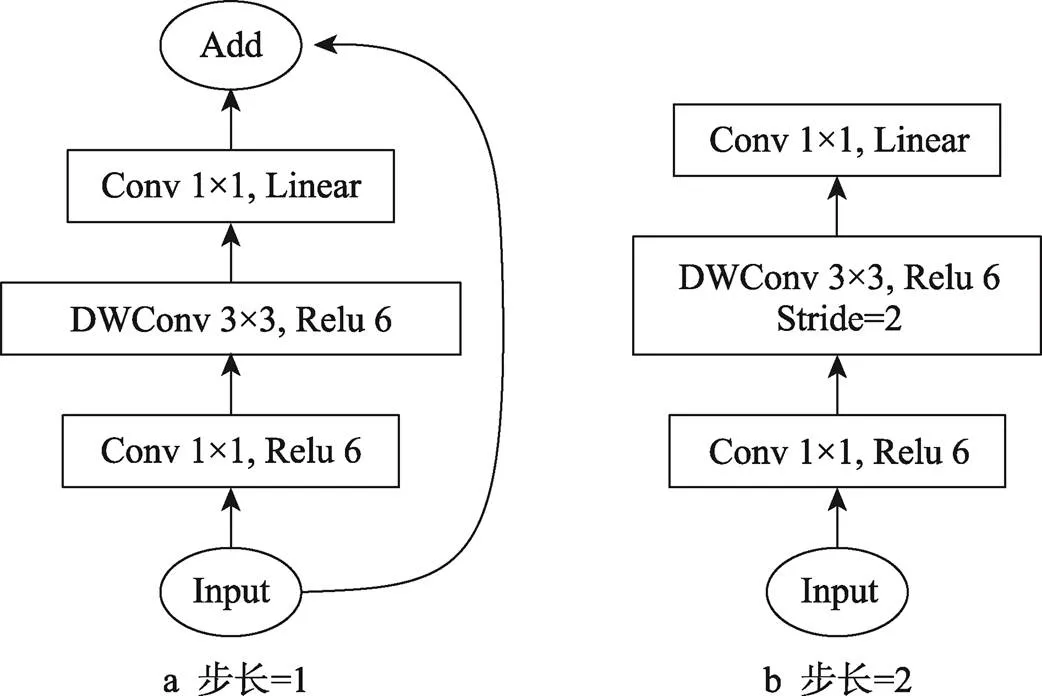
图3 具有线性瓶颈的倒残差模块
CSPDarknet 53与MobileNetV2各层计算量和参数量的对比如表1所示。2种网络结构均使用了2种大小为3×3和1×1的卷积核。在不考虑激活函数层、BN层和全连接层的影响下,设置输入图片的尺寸为416×416×3,各层的计算量和参数量如表1—2所示。
表1 CSPDarknet 53各层的计算量与参数量
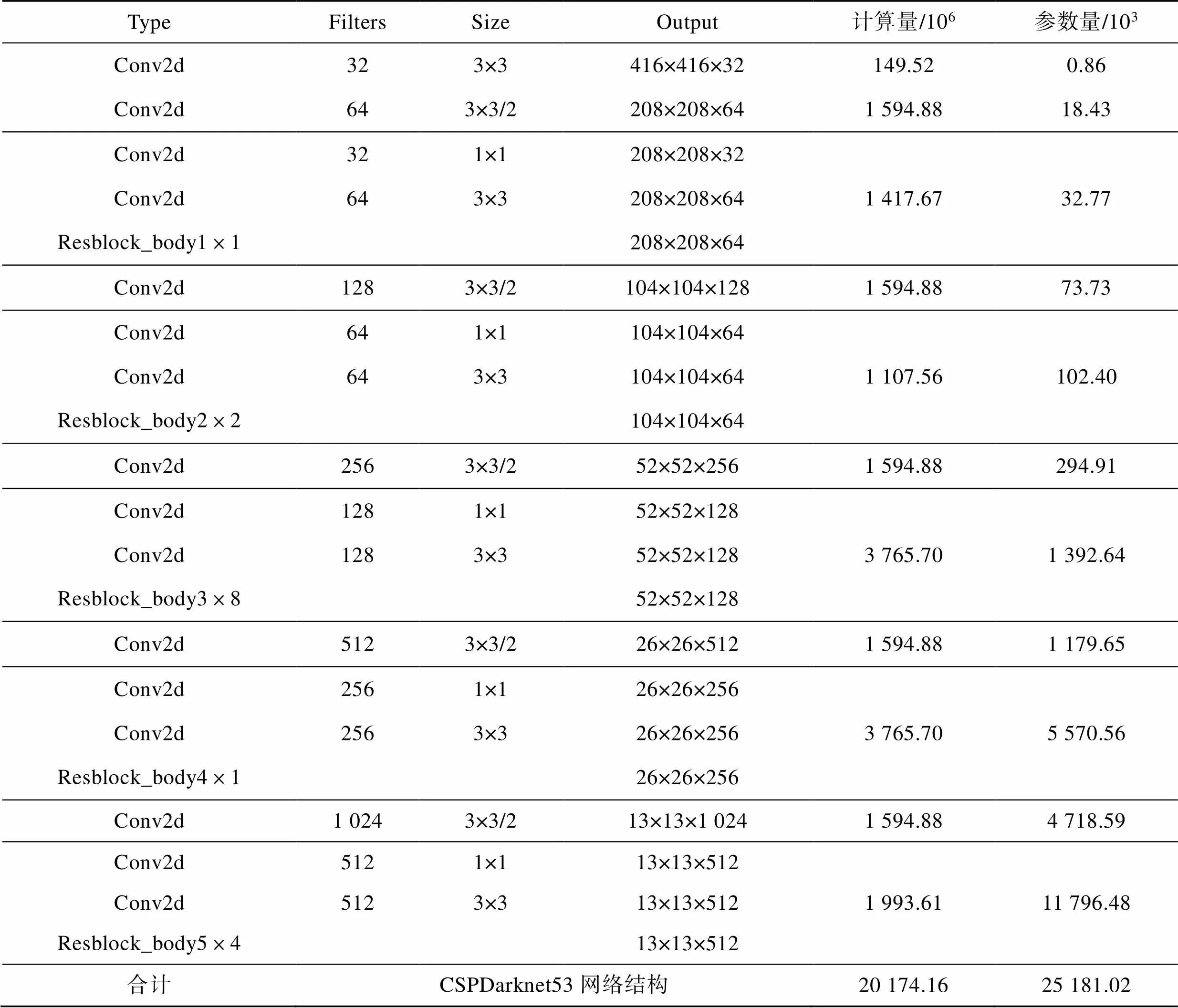
Tab.1 Computational and parametric quantities for each layer of CSPDarknet 53
注:3×3/2表示步长为2的卷积,其余步长均为1。
表2 MobileNetV2各层的计算量与参数量
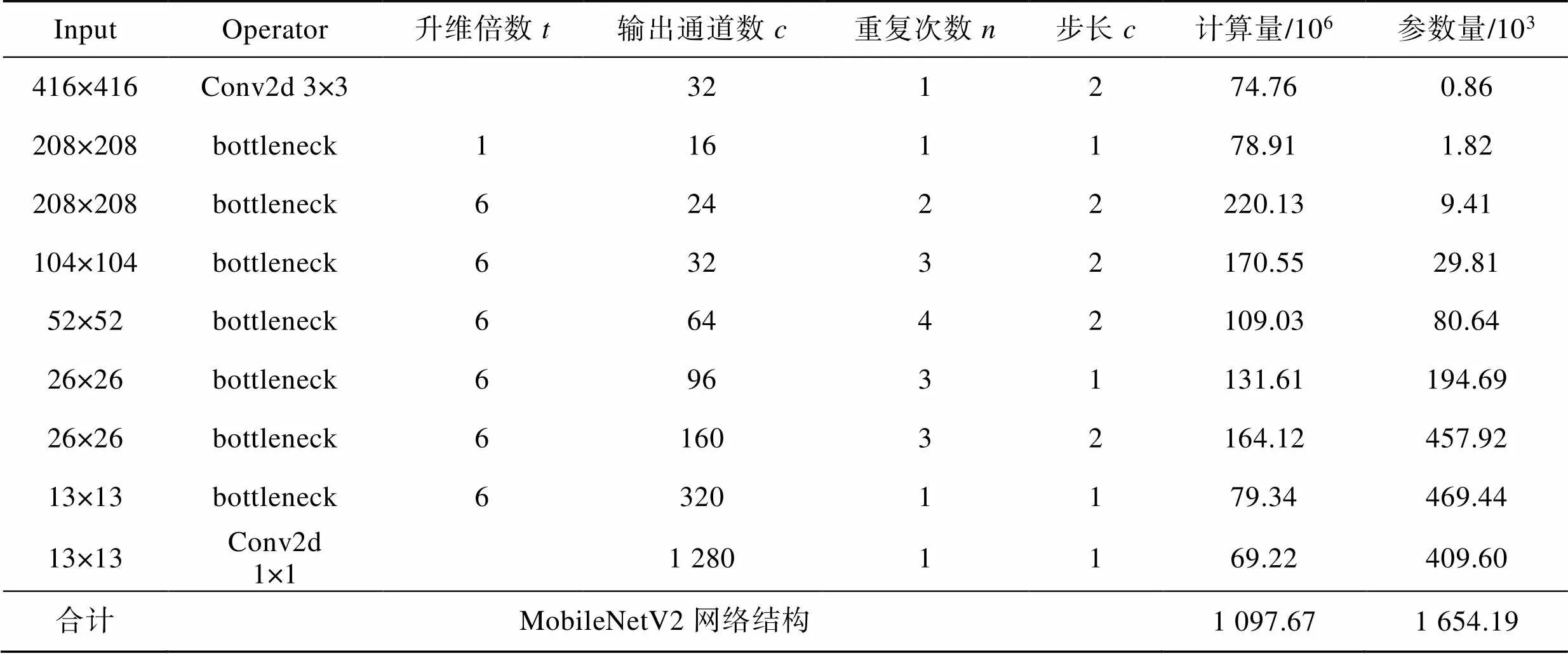
Tab.2 Computational and parametric quantities for each layer of MobileNetV2
2 YOLOv4模型轻量化
2.1 主干网络优化
原始的YOLOv4模型存在参数过多、计算量大等缺点,因此为了减少参数量、提高检测速度,使减少参数量与提高检测速度这两者之间达到最优平衡,文中采用参数量少的轻量级网络MobileNetV2来作为模型Backbone。由MobileNetV2替换CSPDarknet53重新构建的主干网络结构如图4所示,经过主干网络特征提取后,获得了3个有效特征层,分别为52×52×32、26×26×96、13×13×320,这3个有效特征层将作为颈部网络的输入。
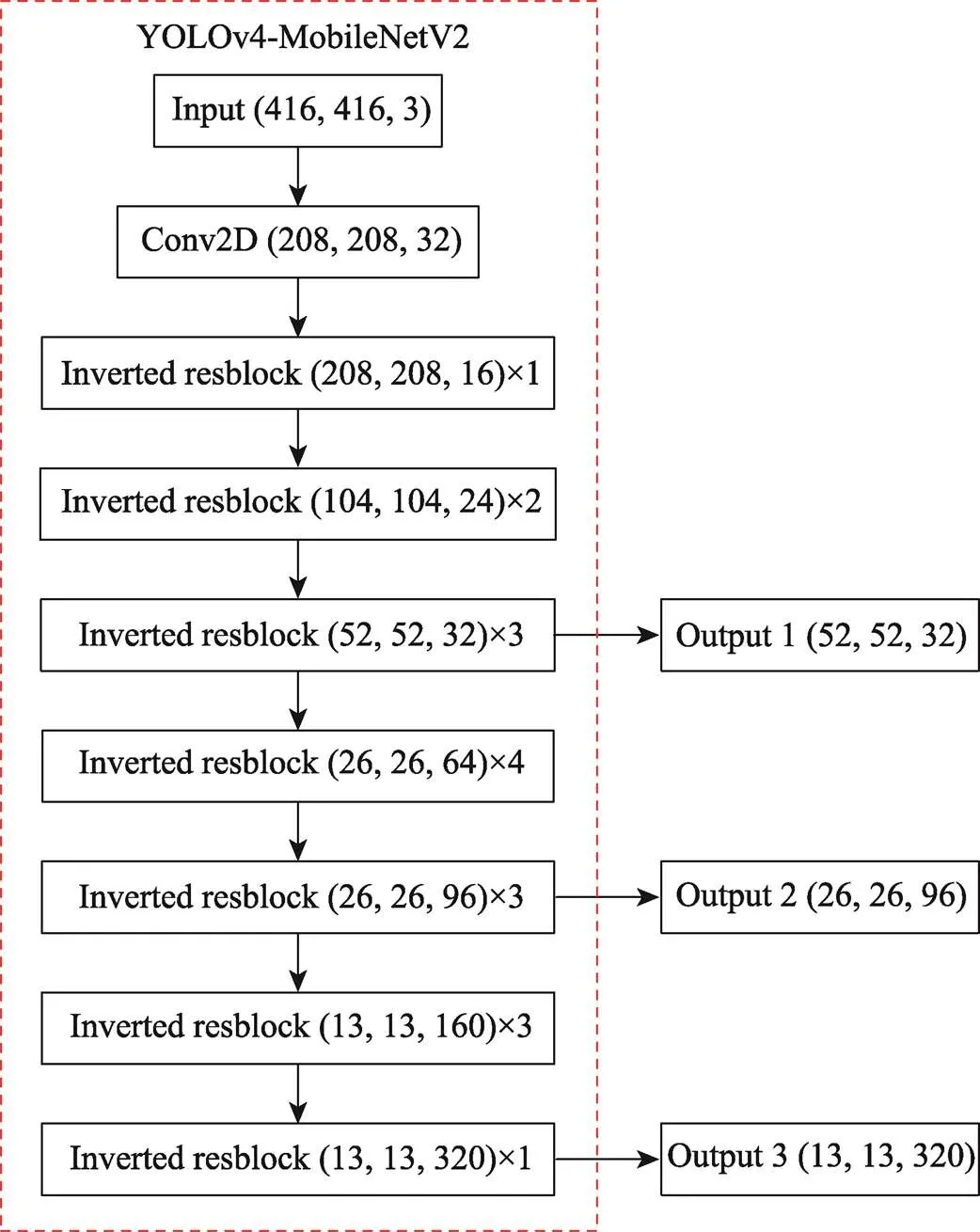
图4 重新构建的主干网络结构
2.2 颈部网络和头部网络优化
为了进一步减少模型的参数,对颈部和头部网络进行了优化。因为在颈部和头部网络中存在许多三次和五次卷积块,并且在三次和五次卷积块中存在大量步长为1的3×3卷积,同时在颈部网络中的二倍下采样(DownSampling)模块中也存在步长为2的3×3卷积,这都将造成大量的卷积运算,影响模型的推理速度,所以将三次和五次卷积块及二倍下采样模块中的3×3卷积修改为3×3的深度可分离卷积。同时,为了使网络模型更加关注待检测目标的高层语义特征,文中受到CBAM的启发,采用通道注意力模块来增大感兴趣区域特征通道的权重,并且通过空间注意力模块来关注感兴趣区域的空间位置,增大有意义特征区域的权重,减少无效区域的权重[19]。CBAM模型如图5所示。通道注意力模块的主要实现过程:首先对输入的特征图进行全局空间最大池化和平均池化,得到2个维度为1×1×的特征图,然后将它们输入1个2层的共享神经网络(Multilayer Perceptron,MLP),得到2个特征向量,再将它们求和,通过激活函数得到通道注意力权重参数c(),最后将权重系数c()与原特征图相乘,得到新的特征图1,见式(6)—(7)。
c()=(MLP(AvgPool())+MLP(MaxPool())) (6)
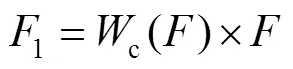
式中:(·)为sigmoid()函数;MLP(·)为多层感知机网络模型函数;AvgPool为平均池化;MaxPool为最大池化。
空间注意力模块的主要实现过程:将特征图1作为本模块的输入特征图,首先进行全局空间最大池化和平均池化,得到2个××1的特征图,然后将这2个特征图进行堆叠拼接,之后经过卷积核为7×7的卷积操作,再经过激活函数后得到空间注意力权重参数s(1),最后将权重参数s(1)与特征图1相乘,得到最终的特征图2,见式(8)—(9)。融入具有双重注意力机制的颈部网络,如图5所示。
s(1)=(7×7(AvgPool(1);MaxPool(1))) (8)
2=s(1)×(9)
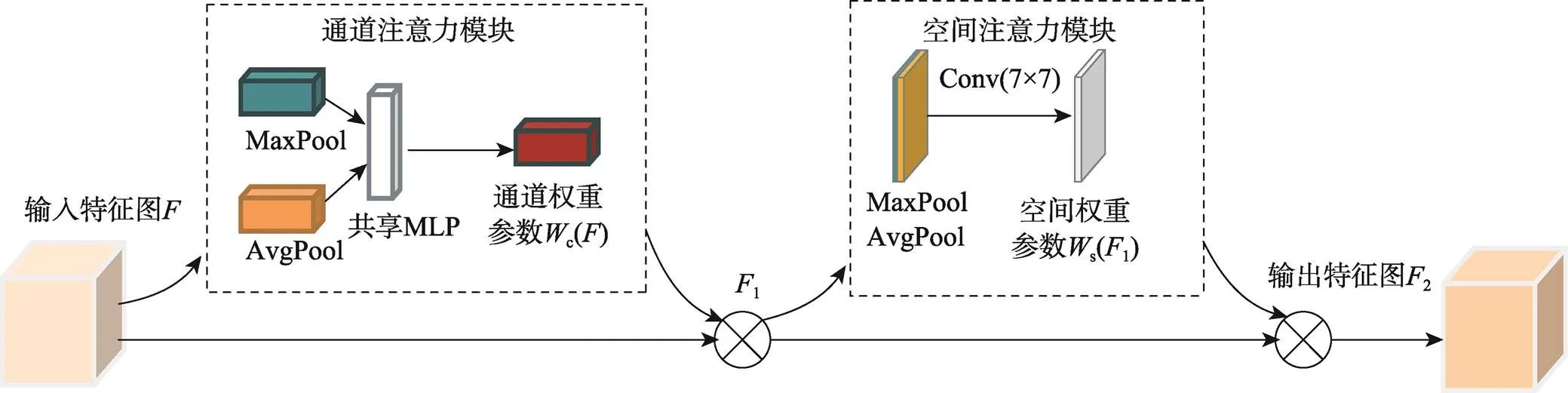
图5 CBAM结构
模型的特征图可视化结果如图6所示,可知融入CBAM注意力机制后可以更好地覆盖目标区域,增加目标区域的显著度,因此模型能够更好地学习目标区域的特征。为了保证模型的检测精度和速度,最终在颈部网络融入了3个CBAM模块。

图6 特征图可视化结果
经修改后模型的参数量得到大幅度减少,与原始YOLOv4模型参数量的对比见表3。
表3 模型参数的对比

Tab.4 Comparison of model parameters
由表3可知,改进后YOLOv4模型的参数量为10 973 415,参数量仅为原始YOLOv4模型的约17.0%,参数量的减少使得模型更加轻量化,从而加快了模型的推理速度。改进后的模型整体结构如图7所示。
2.3 先验框重新聚类
原始YOLOv4模型中的先验框尺寸采用K−means算法[20]在PASCAL VOC数据集聚类时得到,PASCAL VOC数据集中包含20类目标,而自建的可回收垃圾数据集只有5类目标,与PASCAL VOC数据集中所包含的目标种类和数量都存在较大差异,锚框尺寸不一定适合可回收垃圾的检测。为了得到更加匹配的先验框[21],采用K−means算法对自建的可回收垃圾中5种类型标注框的宽高维度进行重新聚类。K−means算法的步骤:首先随机选取个初始的聚类中心;其次,计算其他目标与聚类中心的距离,根据距离度量形成新的个簇,并重新调整聚类中心;最后,通过循环迭代调整,使群中各个目标向各聚类中心聚集,使群之间的距离变大。K−means算法通常以欧氏距离为距离度量,文中将用标注框和聚类中心框的面积重叠度作为距离度量,距离度量计算见式(10)—(11)。
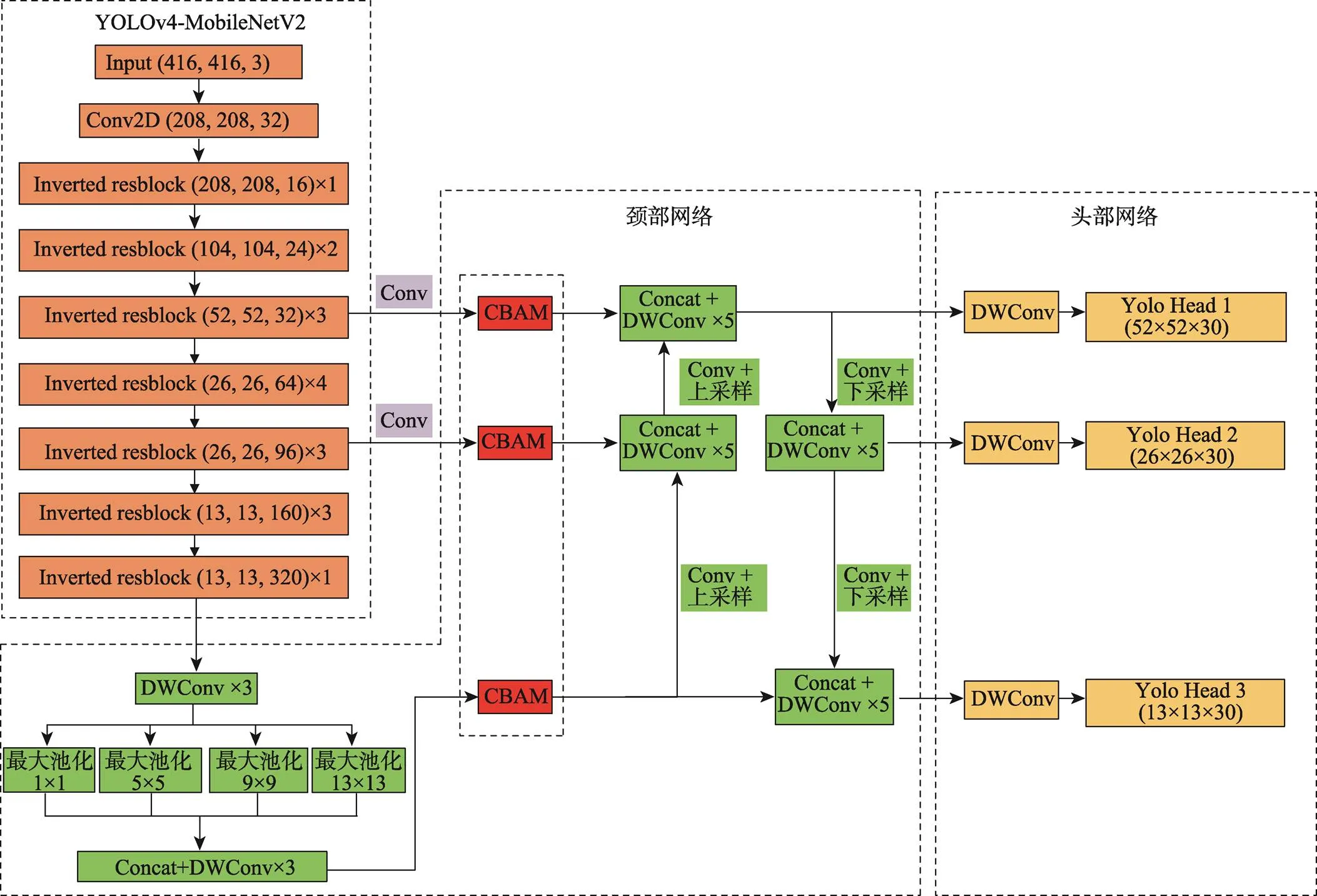
图7 改进后的模型整体结构
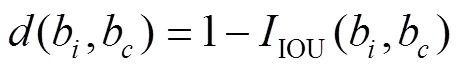
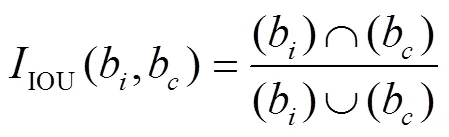
检验K−means聚类生成的先验框的准确性常常使用平均交并比(AvgIOU)进行评估,一般来说AvgIOU值越大,说明聚类算法生成的先验框越准确。对已经标注好的可回收数据集进行聚类分析,得到与AvgIOU之间的关系,如图8所示。
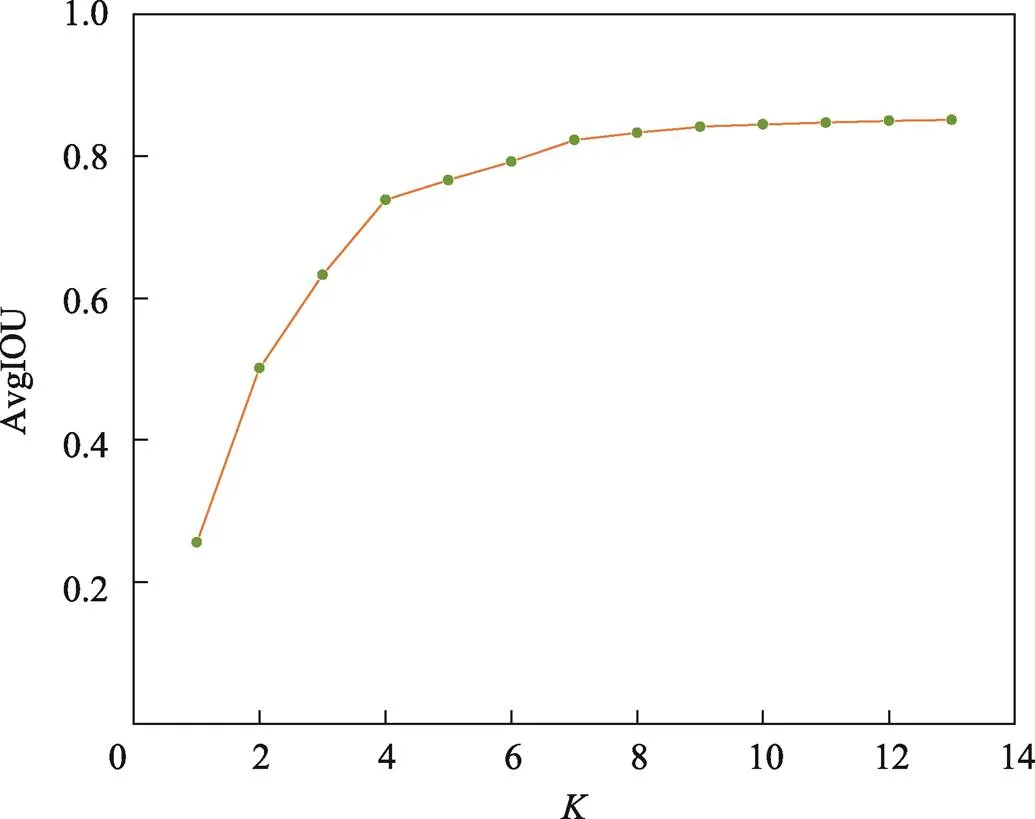
图8 K−means聚类结果
由图8可知,=9为AvgIOU曲线上的一个拐点;在>9时曲线变化的幅度非常小。由此,在考虑计算速度和检测精度的情况下选取先验框的数量为9,经聚类选择的9个先验框分别为(146,132)、(177,378)、(182,233)、(259,297)、(305,387)、(368,227)、(383,299)、(394,359)、(400,401)。
3 实验结果与分析
3.1 实验数据集及评价指标
文中实验使用的数据集来自自建的可回收垃圾数据集,该数据集共有5类标签,分别为废纸类(cardboard)、玻璃类(glass)、塑料类(plastic)、金属类(metal)、纺织类(textile)。这里分别使用水平翻转、亮度调整、添加噪声、随机裁剪和随机旋转等5种数据扩充方法对可回收垃圾数据集进行样本扩充,扩充后的图片总数量为5 048张。采用标注工具LabelImg软件对可回收垃圾目标进行标注,各类可回收垃圾图片样本数量如表4所示,数据集样例见图9。训练集、测试集和验证集的划分比例为8∶1∶1。
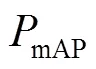
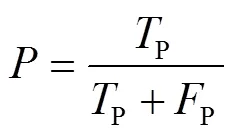
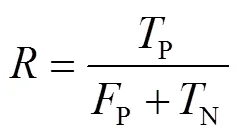
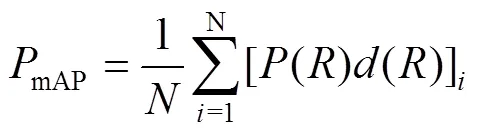
平均准确率均值为多个类别的平均准确率(Average Precision,AP)求和后再取平均值。AP表示以召回率为横轴,以精确率为纵轴,所绘制的−曲线的面积。FPS表示在模型检测速度时每秒钟能够处理的图片数量。
3.2 模型训练
在训练过程中涉及的具体软硬件环境:操作系统为Windows 10中文版,CPU型号为Intel Core i5−10200H2.40 GHz,GPU型号为Nvidia GeForce GTX1650Ti,内存为16 GB,显存为4 GB,深度学习框架选用Pytorch1.7,加速库为Cuda11.2、Cudnn11.2。
表4 各类别样本数量

Tab.4 Number of each sample category

图9 收集的可回收垃圾数据集样例
在训练过程中,将输入图片尺寸设置为416×416。在模型训练时,将momentum(动量系数)设为0.9,初始learning_rate(学习率)设为0.001,总训练代数为100个epoch。训练时分为2个阶段,先进行60个epoch冻结训练,再进行40个epoch解冻训练。冻结阶段具体为冻结主干网络,因为该阶段网络占用的显存较少,此时设置batch_size为8。解冻阶段具体为不冻结主干网络,采用Adam优化学习率,将学习率降至0.000 1。该阶段网络的参数变多,占用的内存较大,此时设置batch_size为4,置信度为0.5。
3.3 实验结果分析
为了验证MobileNetV2、K−means算法和CBAM模块对模型检测性能的影响,使用相同的训练数据集和测试数据集,相同的迭代次数和学习速率,对优化的模块进行消融实验,实验结果见表5—6。
由表5可知,实验1是将YOLOv4的主干网络替换成MobileNetV2,虽然mAP值只有85.56%,但其检测速度最快,达到了22.23帧/s;实验2和实验3是在原始YOLOv4的基础上分别使用K−means算法优化先验框和在颈部网络融入3个CBAM模块,可知这2种方法都有助于提高模型的mAP值,但会使模型的检测速度降低,尤其是加入CBAM模块后其检测速度下降得最为明显,原因是融入CBAM模块后,模型的计算量相对增加;实验4结合了3种改进方法,该模型的mAP值达到了96.78%,相较于实验1提高了约13.1%,检测速度为20.46帧/s,相较于实验2、3提高幅度较大。由表6可知,结合了3种改进方法的模型的AP值都达到95%以上,说明K−means聚类算法重新聚类先验框,提高了模型的检测精度,CBAM的注意力机制有效地抑制了干扰信息,提高了模型对目标特征信息的敏感度。
为了验证文中改进模型在可回收垃圾检测中的性能,选取了目前一些主流目标检测模型(Faster-RCNN、YOLOv4、SSD、YOLOv5s)与文中的改进YOLOv4模型在相同的数据集上进行训练,性能的对比结果见表7。
表5 消融实验检测效果

Tab.5 Detection results of ablation experiment
注:打钩表示采用了该方法。
表6 各模块对模型的AP值对比
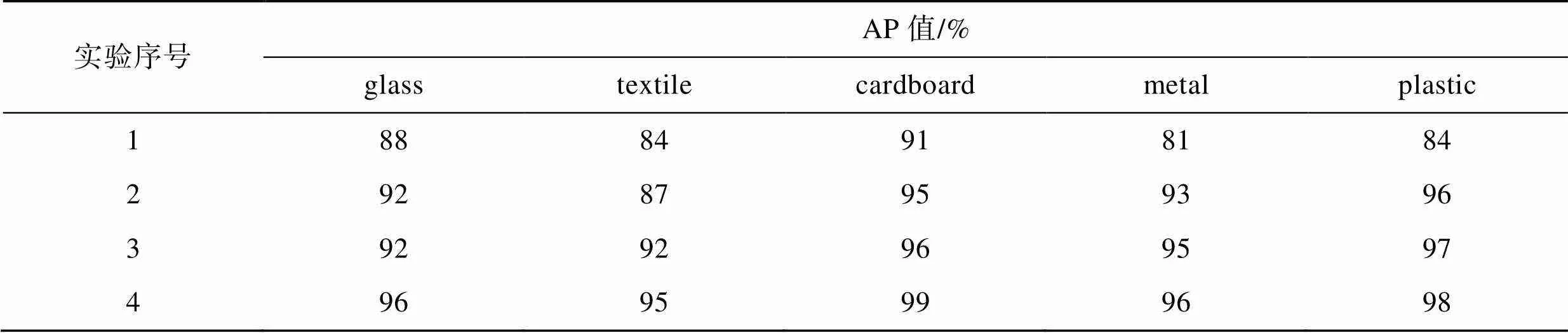
Tab.6 Comparison of AP values of each module to model
由表7可知,两阶段检测网络Faster−RCNN的检测精度相对较高,但其模型体积也相对较大,检测速度最低仅为5.54帧/s,难以满足可回收垃圾检测实时性的要求。虽然SSD模型的检测精度最低,但其模型文件大小和检测速度都优于Faster−RCNN模型。原始YOLOv4模型的mAP值为91.65%,权重文件的大小为244.48 MB,比其他模型大。虽然YOLOv5s在当前模型中的检测速度最高且模型文件最小,但是其检测精度却不高,比原始YOLOv4模型低1.6%。文中的改进模型与原始YOLOv4模型相比,其mAP值提高了5.6%,模型权重文件大小为46.6 MB,相较于YOLOv4大幅减少,仅为YOLOv4的19.1%,检测速度为20.46帧/s。相较于YOLOv4,提高了约25.4%,检测速度和精度均满足实时性需求。
文中的改进模型与其他检测模型之间的检测效果对比如图10所示。由对比检测结果可知,虽然各模型均能检测出可回收垃圾,但是在检测结果的置信度值和拟合度上,文中的改进模型优于其他模型。
表7 各模型的对比结果
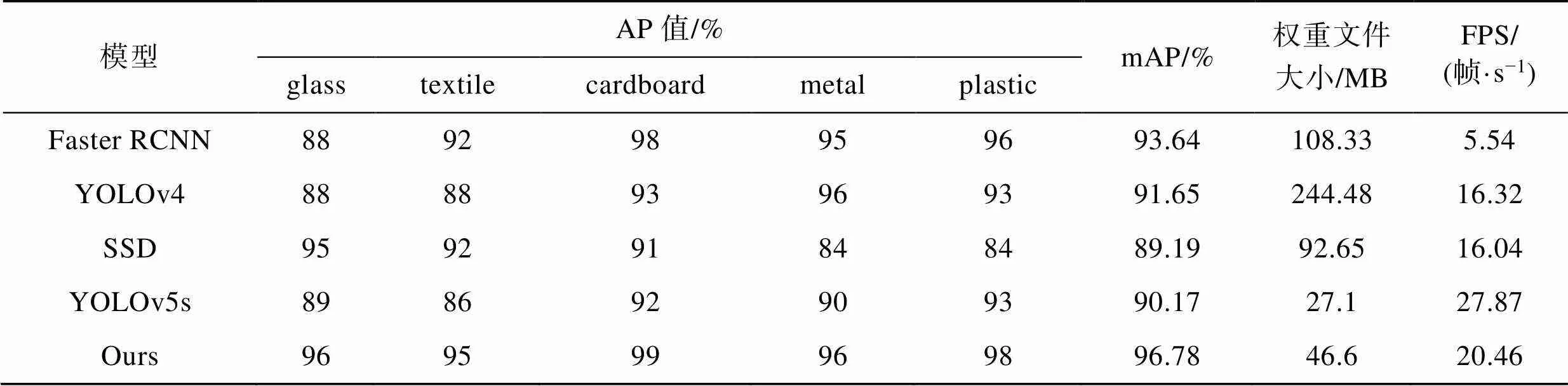
Tab.7 Comparison results of models

图10 文中的改进模型与其他模型检测效果的对比
4 结语
针对目前垃圾检测方法存在的检测速度慢且权重文件较大等问题,提出了一种改进的YOLOv4检测方法。为了减少模型的计算量和参数量,将YOLOv4的主干网络替换为MobileNetV2,并使用深度可分离卷积对网络进行优化;融入CBAM注意力机制,提高了模型对目标特征信息的敏感度,抑制了干扰信息,从而提升了模型的检测精度。为了得到适合数据集的先验框,采用K−means算法对自建可回收垃圾数据集进行重新聚类。实验结果表明,参数量和模型权重文件大小分别减小为原始YOLOv4模型的17.0%和19.1%,检测精度为96.78%,提高了5.6%,检测速度为20.46帧/s,提高了25.4%。未来应进一步对模型进行优化,在保证检测速度的同时提高模型的检测精度。
[1] 鞠默然, 罗海波, 王仲博, 等. 改进的YOLOV3算法及其在小目标检测中的应用[J]. 光学学报, 2019, 39(7): 253-260.
JU Mo-ran, LUO Hai-bo, WANG Zhong-bo, et al. Improved YOLOV3 Algorithm and Its Application in Small Target Detection[J]. Acta Optica Sinica, 2019, 39(7): 253-260.
[2] GIRSHICK R. Fast R-CNN[C]// IEEE International Conference on Computer Vision (ICCV), 2016: 1440-1448.
[3] REN Shao-qing, HE Kai-ming, GIRSHICK R, et al. Faster R-CNN: Towards Real-time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[4] LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: Single Shot Multibox Detector[C]// European Conference on Computer Vision, 2016: 21-37.
[5] REDMON J, DIVVALA S, GIRSHICK R, et al. You Only Look Once: Unified, Real-Time Object Detection[EB/OL]. (2015-06-08)[2022-03-15]. https://arxiv.org/abs/1506.02640
[6] REDMON J, FARHADI A. YOLO9000: Better, Faster, Stronger[C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017: 6517-6525.
[7] REDMON J, FARHADI A. Yolov3: An Incremental Improvement[EB/OL]. (2018-04-08)[2021-01-15]. https:// arxiv.org/1804.02767.
[8] BOCHKOVSKIY A, WANG Chien-yao, LIAO H Y M. YOLOv4: Optimal Speed and Accuracy of Object Detection[EB/OL]. (2020-04-23)[20220-03-15]. https://arxiv.org/ abs/2004.10934
[9] LIN Tsung-yi, GOYAL P, GIRSHICK R, et al. Focal Loss for Dense Object Detection[C]// IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017: 2999-3007.
[10] 赵珊, 刘子路, 郑爱玲, 等. 基于MobileNetV2和IFPN改进的SSD垃圾实时分类检测方法[J]. 计算机应用, 2022, 42(S1): 106-111.
ZHAO Shan, LIU Zi-lu, ZHENG Ai-ling, et al. Real-time Classification and Detection Method of Garbage Based on SSD Improved with MobileNetV2 and IFPN[J]. Journal of Computer Applications, 2022, 42(S1): 106-111.
[11] 马雯, 于炯, 王潇, 等. 基于改进Faster R−CNN的垃圾检测与分类方法[J]. 计算机工程, 2021, 47(8): 294-300.
MA Wen, YU Jiong, WANG Xiao, et al. Garbage Detection and Classification Method Based on Improved Faster R-CNN[J]. Computer Engineering, 2021, 47(8): 294-300.
[12] 许伟, 熊卫华, 姚杰, 等. 基于改进YOLOv3算法在垃圾检测上的应用[J]. 光电子·激光, 2020, 31(9): 928-938.
XU Wei, XIONG Wei-hua, YAO Jie, et al. Application of Garbage Detection Based on Improved YOLOv3 Algorithm[J]. Journal of Optoelectronics·Laser, 2020, 31(9): 928-938.
[13] 李庆, 龚远强, 张玮, 等. 用于智能垃圾分拣的注意力YOLOv4算法[J]. 计算机工程与应用, 2022, 58(11): 260-268.
LI Qing, GONG Yuan-qiang, ZHANG Wei, et al. Attention YOLOv4 Algorithm for Intelligent Waste Sorting[J]. Computer Engineering and Applications, 2022, 58(11): 260-268.
[14] KUMAR S, YADAV D, GUPTA H, et al. A Novel YOLOv3 Algorithm-based Deep Learning Approach for Waste Segregation: Towards Smart Waste Management[J]. Electronics, 2020, 10(1): 14.
[15] WANG Chien-yao, LIAO H Y M, WU Yueh-hua, et al. CSPNet: A New Backbone that can Enhance Learning Capability of CNN[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020: 1571-1580.
[16] HE Kai-ming, ZHANG Xiang-yu, REN Shao-qing, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
[17] LIU Shu, QI Lu, QIN Hai-fang, et al. Path Aggregation Network for Instance Segmentation[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 8759-8768.
[18] SANDLER M, HOWARD A, ZHU Meng-Long, et al. Mobilenetv2: Inverted Residuals and Linear Bottlenecks[EB/OL]. (2018-12-16)[2022-03-15]. https://arxiv.org/abs/1801.04381.
[19] 张宸嘉, 朱磊, 俞璐. 卷积神经网络中的注意力机制综述[J]. 计算机工程与应用, 2021, 57(20): 64-72.
ZHANG Chen-jia ZHU Lei, YU Lu. Review of Attention Mechanism in Convolutional Neural Networks[J].Computer Engineering and Applications,2021, 57(20): 64-72.
[20] SINAGA K P, YANG Min-shen. Unsupervised K-means Clustering Algorithm[J]. IEEE Access, 2020(8): 80716- 80727.
[21] 王子鹏, 张荣芬, 刘宇红, 等. 面向边缘计算设备的改进型YOLOv3垃圾分类检测模型[J]. 激光与光电子学进展, 2022, 59(4): 291-300.
WANG Zi-peng, ZHANG Rong-fen, LIU Yu-hong, et al. Improved YOLOv3 Garbage Classification and Detection Model for Edge Computing Devices[J]. Laser & Optoelectronics Progress, 2022, 59(4): 291-300.
[22] 董豪, 李少波, 杨静, 等. 基于YOLOv4算法的药用空心胶囊表面缺陷检测方法[J]. 包装工程, 2022, 43(7): 254-261.
DONG Hao, LI Shao-bo, YANG Jing, et al. Surface Defect Detection Method for Pharmaceutical Hollow Capsules Based on YOLOv4 Algorithm[J]. Packaging Engineering, 2022, 43(7): 254-261.
Lightweight Recyclable Garbage Detection Method Incorporating Attention Mechanism
GUO Zhou1,2, HUANG Shi-hao1,2, XIE Wen-ming2, LYU Hui1,2, ZHANG Xuan-xuan1,2, CHEN Zhe1,2
(1. Fujian Key Laboratory of Automotive Electronics and Electric Drive, Fuzhou 350118, China; 2. School of Electronic, Electrical Engineering and Physics, Fujian University of Technology, Fuzhou 350118, China)
The work aims to propose a lightweight method based on YOLOv4 to detect recyclable garbage, so as to address the problems of slow detection speed and large model weight files in the current garbage detection methods used by smart garbage sorting devices. The MobileNetV2 lightweight network was used as the backbone network of YOLOv4 and the depth-separable convolution was used to optimize the neck and head networks to reduce the parameters and computation to accelerate detection. The CBAM attention module was incorporated into the neck network to improve the sensitivity of the model to the target feature information. The K-means algorithm was used to re-cluster to get suitable self-built recyclable data with a priori frame for focused detection of targets. The experimental results showed that: the parameters were reduced to 17.0% of the original YOLOv4 model. The detected mAP reached 96.78%. The model weight file size was 46.6 MB, which was about 19.1% of the YOLOv4 model weight file. The detection speed was 20.46 frames/s, which was improved by 25.4%. Both the detection accuracy and the detection speed met the real-time detection requirements. The improved YOLOv4 model can guarantee high detection accuracy and good real-time performance in detection of recyclable garbage.
recyclable garbage detection; MobileNetV2; YOLOv4; attention mechanism; deep learning
TB487;TP391
A
1001-3563(2023)09-0243-11
10.19554/j.cnki.1001-3563.2023.09.030
2022−05−13
国家自然科学基金(61604041);教育部产学研协同育人项目(201901021014);福建省教育厅基金项目(JT180352)
郭洲(1996—),男,硕士生,主攻机器视觉、图像处理。
黄诗浩(1985—),男,博士,副教授,主要研究方向为光电信息材料与器件、机器视觉等。
责任编辑:彭颋
