人工智能自然语言处理诊断肾癌T分期的研究
2023-05-12江卫星孙丰龙毕新刚寿建忠马建辉
温 力 江卫星 孙丰龙 毕新刚 寿建忠 马建辉
人工智能是模拟人类智能的一种算法过程,随着科技的进步和发展,人工智能在医学中的研究正蓬勃发展[1, 2]。自然语言处理(natural language processing, NLP)作为人工智能的一个分支领域,是将语言转换为计算表达的形式,可作为工具用于处理肿瘤诊疗信息,特别是在提取临床电子病历(electronic medical records, EMR)文本数据中发挥了重要作用[3]。基于NLP构建自由文本挖掘算法去进一步挖掘肿瘤临床信息是十分有前景的新方法,比如提取肿瘤的分期、分级等数据[4]。在临床工作中,恶性肿瘤的分期是预后评估和制定治疗计划的重要程序之一,美国癌症联合委员会(American Joint Committee on Cancer,AJCC)制定的TNM分期是最常用的癌症分期系统。肾癌作为泌尿系统常见的恶性肿瘤,其分期依据主要包括原发肿瘤直径、肾周脂肪、肾盂、静脉瘤栓、区域淋巴结侵犯以及远处转移。这些临床资料大部分能从病理报告中获得,而病理报告是传达肿瘤分期的黄金标准,可以以自由文本形式存储,有研究者基于NLP建立了肺癌英文的T分期算法[5]。本研究利用NLP作为工具对笔者医院收治的肾癌患者临床电子病历数据进行人工智能自然语言处理分析,提出一种可自动诊断肾癌T分期的算法,以进一步协助病理医生进行病理诊断。
资料与方法
1.临床资料收集:收集2018年1月~2020年1月因肾癌于国家癌症中心、国家肿瘤临床医学研究中心、中国医学科学院/北京协和医学院肿瘤医院行手术治疗的200例肾癌患者作为训练组,并选取2015年1月~2017年12月性别、年龄以及病理分期匹配的200例因肾癌行手术患者作为测试组。病理结果均以自由文本报告的形式存储在临床诊疗信息系统中,每份报告由几个结构部分组成,包括肿瘤切除部位、性质、分级、肿瘤直径、侵犯范围等。所有患者均有完整的病理诊断和病理分期。

3.概念框架:研究框架设计如图1所示,将数字化肾癌病理报告作为输入,针对肾癌T分期组成的各个要素,病理医生使用训练组为各分期要素创建一组同义词及其词缀,即表1中的关键词,同时将分期要素定义为识别域及其值,如“肾周脂肪”为识别域,则“累及”和“未累及”为值。开发基于规则模板匹配和基于条件随机场的两种信息抽取算法。通过图2所示流程依据抽取的信息获得肾癌病理T分期的预测结果,并且在测试组数据上计算预测准确性,作为分期预测模型性能的整体评估。

图1 基于NLP的中文病理报告处理框架及在病理T分期预测中的应用

表1 肾癌病理报告中识别域对应的关键词和值提取规则
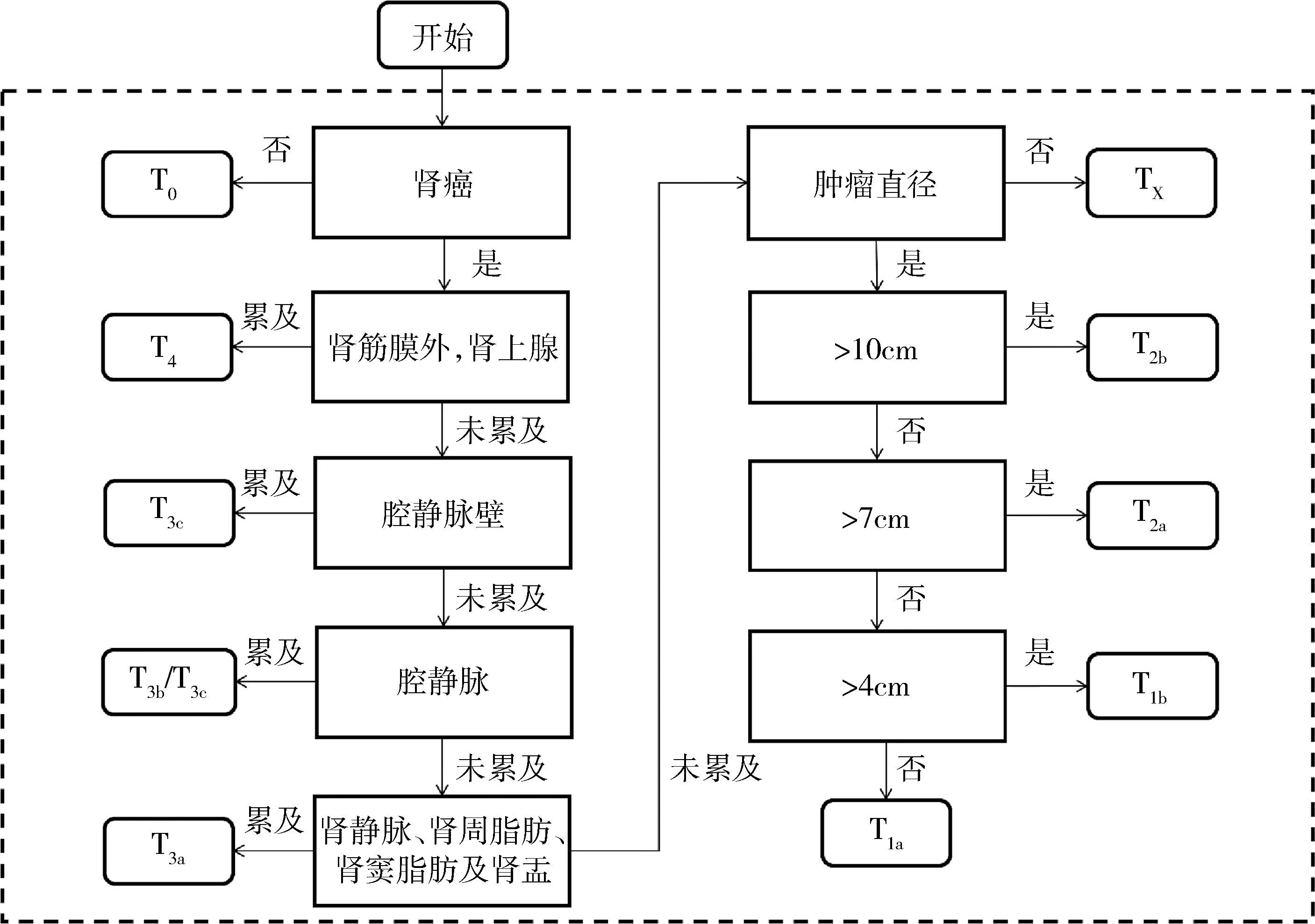
图2 基于识别域值提取的肾癌病理T分期预测流程图
4.基于规则模板匹配的方法:算法分为4个部分,包括预处理、文本分割、关键词识别和值提取。首先,在预处理中统一标点符号,将英文的逗号、分号、句号和括号转化为相应的中文符号。然后,根据中文书写习惯,以逗号、分号和句号作为分界符号,将预处理后的文本分割为一些小片段。接着,针对每个关键词,通过字符串匹配定位出与它相关的文本小片段。最后,对训练组数据中定位出来的文本小片段总结出规则模板,设计正则表达式进行规则匹配,提取每个识别域对应的值。信息抽取及T分期预测过程示例如图3所示。

图3 肾癌病理报告病理T分期关键信息抽取示例
具体建立规则模板的过程如下:针对提取出来的包含关键词的文本小片段,定位一些规律性的表达,例如,肿瘤直径的文字描述一般是关键词“肿瘤大小”,“最大径”或者“肿瘤”后面加上相应的数值表达式;肿瘤累及部位的文字描述一般为具体部位前面或者后面加上特定的描述词如“累及”、“侵犯”、“见癌”、“瘤栓”等;而关于肿瘤未累及部位的文字描述,则是在特定描述上再添加否定词如“未”。笔者研究使用python正则表达式设计以下提供进行匹配的规则模板:(R1)关键词+数值,例如:最大径2.5cm;(R2)特定描述+关键词,例如:侵犯肾上腺;(R3)关键词+特定描述,例如:肾静脉瘤栓。对肿瘤累及部位的描述中如出现否定词则排除,并在正则表达式中体现。
5.基于条件随机场的方法:对照着基于规则模板匹配的方法,用条件随机场替代文本分割部分和值提取中的语义识别部分。先是预处理统一标点符号,然后使用开源软件brat标注出病理报告中对于判断肾癌病理T分期有用的陈述信息:(1)大小陈述,如“肿瘤最大径6.5cm”。(2)累及陈述,如“肾门处可见血管侵犯,形成瘤栓”。(3)未累及陈述,如“未累及肾周脂肪、肾窦脂肪及肾盂”,详见图4。类似于命名实体识别,再使用“BMEO” 用于定义每个有用陈述信息的边界。其中“B”代表起始字符,“E”代表结束字符,“M”是中间字符,“O”代表其他无关字符。同时,在边界信息后面加上陈述类型,所以一个字符完整的标注形如“B-大小陈述”或者“O”。模型在预测的时候,将预测为同一类陈述的“B”,紧随其后的一系列“M”以及之后的“E”的字符进行连续组合即为所提取的陈述。

图4 条件随机场方法标注示例
在对训练组完成标注后,研究使用sklearn_crfsuite=0.3.6中的条件随机场进行训练得到模型,用模型对测试组中数据进行预测,提取出有用陈述。在条件随机场提取出有用陈述之后,依据陈述的类别信息,通过简单的数字提取和关键词搜索就可以得到肿瘤直径及累及部位信息,从而完成值提取过程。
6.肾癌T分期预测效能评估:在测试组上,基于不同的信息抽取值算法及流程图2可以得到病理T分期的预测值,通过与金标准比较,计算整体的准确率(precision)、召回率(recall)、F1-分数(F1-score)以及正确率(accuracy)[7]。其中正确率,即预测正确的数目与全部病例数目之比。对于准确率、召回率和F1-分数,设FP为假阳数目,TP为真阳数目,FN为假阴数目,TN为真阴数目,则
因为研究的问题为多分类问题,而且类别不平衡,所以针对每一个类别计算出对应的准确率(记为Precisioni)、召回率(记为Recalli)和F1-分数(记为F1-scorei)后,再根据各类样本比例配置权重得到加权平均值,作为总的准确率、召回率和F1-分数,即
结 果
1.肾癌手术患者的临床病理特征:本研究共400例患者,其中男性287例,女性113例;患者年龄25~80岁,中位年龄62岁;肿瘤直径为6.1±2.3cm。透明细胞癌356例,乳头状细胞癌22例,嫌色细胞癌13例,其他病理类型包括MIT家族转位性肾癌、集合管癌等共9例。根据TNM分期标准,pT1a期252例,pT1b期69例,pT2a期10例,pT2b期4例,pT3a期59例,pT3b期2例,pT4期4例 (表2)。
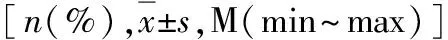
表2 400例患者一般临床资料
2.测试组结果分析:根据测试组200例患者效能评估结果,基于规则模板匹配方法准确率为99.0%,召回率为99.0%,F1-分数为99.0%,正确率为99.0%;而基于条件随机场方法,准确率为97.1%,召回率为95.5%,F1-分数为96.3%,正确率为95.5%(表3)。前者正确率高于后者(99.0% vs 95.5%,χ2=4.581,P=0.032)。

表3 肾癌病理报告T分期预测结果(%)
讨 论
笔者之前总结了国内外人工智能诊断肾细胞癌的现状,关于人工智能在肾细胞癌中的研究和应用目前尚处于起步阶段,主要集中在影像学,而病理研究较少报道[8]。本研究对肾癌病理报告利用人工智能自然语言处理方法进行识别和分析,提出可自动诊断肾癌T分期的算法,从而降低病理医生负荷,提高临床工作效率。
近年来,越来越多的研究证实人工智能在医学研究中展现出了巨大的优势,特别是在大数据的趋势下,人工智能作为一种自动化的工具,在多个方面直接或者间接地减轻医疗工作的负担[9~11]。通过医学图片的人工智能深度学习可协助诊断,如Campanella等[12]开发了多层面的人工智能决策支持系统,对共15187例癌症患者包括44732张病理切片进行了测试,诊断准确性的曲线下面积达0.98,预计能减少70%病理医生的工作量。通过病历文本的自然语言处理可协助肿瘤分期,如Nguyen等[5]使用基于规则的符号分类从718例肺癌的自由文本病理报告中实现对肺癌自动分期,准确性可达到80%左右。在泌尿肿瘤方面,Schroeck等[13]报道了从600份膀胱癌病理报告中提取信息的基于规则方法的准确性在68%~98%。Odisho等[14]开发了一种对前列腺癌病理报告和临床指标的识别算法,准确性为94.8%~100%。而缺乏肾癌的自然语言文本处理的相关研究报道。
本研究利用自然语言方法对肾癌的病理报告进行了提取分析,首先收集2018年1月~2020年1月200例肾癌病理报告作为训练组,既往2015年1月~2017年12月年龄、性别、病理分期匹配的200例肾癌病理报告作为测试组,然后分别使用基于规则模板匹配和基于条件随机场两种方法预测肾癌的T分期,结果显示,两者在测试组的正确率分别为99.0% 和95.5%(P=0.032)。在测试组的方法性能评估中,对于规则匹配方法的准确度为99.0%,召回率为99.0%,F1-分数为99.0%;对于条件随机场方法的准确度97.1%,召回率为95.5%,F1-分数为96.3%。从以上结果的准确性来看,两种不同的自然语言处理方法均是可行的,使用规则匹配的方法可能略好。但笔者发现规则匹配的方法虽然实现了关键信息的提取,如作为处理更大的数据集或更换癌种后,可能需要设计更复杂的规则模板,而基于条件的随机场法可自主学习标注陈述的关键信息,可能在大数据上具有较好的适应性优势。
笔者对在本研究中预测错误的病理报告也进行了分析,错误的识别主要源自病理报告内容不完整,在按照规则流程进行分期时,因缺乏识别域和值导致识别错误,如病理报告中未描述肿瘤直径,则识别为Tx。因此,笔者认为完整的病理报告是提高准确程度的必要因素,这样也有利于规范病理医生的报告书写,根据病理报告识别内容可形成病理报告书写统一规范,适合在基层推广,提高基层医疗水平。另外,根据本研究结果可开发相应的软件系统,协助病理医生进行分期,大大减少病理医生的工作量。
本研究存在一定的局限性:(1)研究来自单中心的病例,病理报告书写规范比较统一,仍需与其他机构合作进行完善识别工作。(2)本研究入组病例数量有限,准确度可能有偏差,需进一步收集大样本量的病理资料去验证。(3)本研究仅为单个癌种的识别算法,对其他癌种并不适用,笔者将在下一步利用本体语言去扩大适用范围。
综上所述,使用自然语言处理通过病理报告诊断肾癌病理T分期是可行的方法,基于规则匹配的算法具有较高准确度。但这些研究结果有待下一步多中心、大样本量的数据去证实。国内外尚无肾癌病理报告人工智能识别自动诊断T分期的报道,本研究可作为未来研究的初步参考。
