面向编辑过程还原的勒索病毒删除文档重组方法
2023-05-12徐国天
徐 国 天
(中国刑事警察学院 公安信息技术与情报学院,沈阳 110854)
1 引 言
“僵木蠕”是僵尸程序、木马程序和蠕虫病毒的简称.2017年5月全球爆发的、肆虐互联网的勒索病毒“永恒之蓝”就是一种蠕虫病毒,被感染主机中的Office文档、数据库等重要文件被加密,原始文件被删除,受害者须支付300~600美金的比特币来解密“赎回”档案[1].在此次网络入侵事件中,我国的公安专网、交通管理系统受损最为严重,一些地方甚至因病毒袭击而暂停业务办理.可以说“勒索病毒”新型网络入侵已对互联网安全构成严重威胁.
勒索病毒主要采用RSA及AES算法对文档进行加密,在无秘钥情况下,很难进行数据解密[2].目前,通过数据恢复方法还原被勒索病毒删除文档是电子数据取证领域的研究热点[3].常规数据恢复方法主要包括基于文件系统元信息的数据恢复方法和基于文件首尾特征值的恢复技术[4].基于文件系统元信息的数据恢复方法是利用被删文件元数据项定位、提取残留数据,进而完成文件恢复.这种方法准确性高、速度快,可以提取出文件数据、文件名称和文件的删除时间,适合恢复分布式、离散存储的数据分片.但当文件系统元数据被覆盖时,即使磁盘内残留了大量数据分片,仍然无法完成数据恢复[5].基于文件首尾特征值的恢复技术是利用特定类型文件首部和尾部的唯一特征值,定位被删数据的起始和结束位置,进而完成数据恢复.这种方法可以在系统元数据被覆盖时,完成文件恢复.但是需要扫描磁盘全部空闲存储空间,速度较慢,且当被删数据以分片形式离散存储时,会出现定界错误,进而导致恢复失败[6].除上述方法之外,文献[7]提出一种基于统计的数据恢复方法,通过对各种类型文件数据块计算统计值(统计量有汉明值、香农熵、均值、卡方值等),根据统计值对数据块进行分类[7].这种方法可用于识别分片断点位置,但需要提前对不同类型文件数据块做统计学计算,统计量的选取直接影响文件恢复精度.文献[8]提出一种二分片文件恢复方法,采用一种对象配对校验技术不断测试确定分片断点位置,完成二分片文件恢复[8].当文件由两个以上分片组成时,不能应用这种方法,同时当二分片间隔较远时,断点位置计算时间也急剧增加.文献[9]提出一种基于语义的文件恢复技术,通过特征词匹配来连接数据分片[9].它要求分片边界位置存在特定语义连接词,如英文单词.文献[10]提出一种基于文件内部结构的恢复方法,当文件内部由若干个特定结构的数据块组成时(例如Oracle、SQL Server数据库文件),可以使用这种方法定位、恢复全部数据块[10].此方法可在被删文件首尾特征值被覆盖时,恢复被删数据,但是仅对特定类型文件有效.文献[11]提出一种基于函数映射的数据恢复方法,在文件每个字节数据的逻辑存储位置与磁盘物理存储位置之间建立映射,进而完成数据恢复[11].这种方法需要不断修正映射函数,中间生成的无效数据较多,当发生映射错误时需要人工干预.
勒索病毒(如永恒之蓝、Locky等)感染用户主机后,会将被感染主机中的Office文档、数据库、图片等重要文件加密,将原始文件删除,向受害者索要“赎金”来解密“赎回”档案.为防止用户还原被删数据,勒索病毒通常将加密之后的密文数据写回文件在磁盘内的原始存储位置,覆盖原始文档内容,致使现有数据恢复方法难以有效还原被删文件.基础实验表明,办公文档在“增、删、改”编辑过程中,文件数据在磁盘内的存储位置会发生迁移,且最近几步编辑操作对应的文件数据基本完整存储在磁盘内,勒索病毒只对当前文件数据(即最后一次编辑痕迹)进行加密和覆盖删除处理,而对其它遗留在磁盘内的编辑过程痕迹不进行处理,进而可以通过还原编辑过程痕迹来恢复原始文档.由于办公文档编辑痕迹在磁盘内极易出现分片存储情况,目前现有数据恢复方法无法有效识别、恢复分片存储的办公文档.针对上述问题,本文提出一种基于编辑过程还原的勒索病毒删除文档分片识别及恢复方法.该方法通过扫描全部磁盘空闲存储空间,根据ZIP数据块首部标志位和修改时间字段识别全部办公文档编辑过程痕迹数据分片,再利用文档尾部目录项将数据分片重组为完整的Office文档,采用CRC32校验技术修复边界数据块识别错误.实验结果表明,在主机感染勒索病毒情况下,该方法可准确识别、恢复2007以上版本Office电子文档编辑痕迹数据分片,重组原始办公文档内容.
2 勒索病毒删除文档存储状态分析
文件系统元数据(如NTFS系统的$MFT元数据,EXT4系统的inode元数据)记录了磁盘内全部文件信息,包括文件数据在磁盘内的存储位置,文件最近一次访问及修改时间,文件大小和文件名称等重要信息.磁盘内每个文件对应一条元记录,文件系统通过元记录可以快速访问文件数据,当文件内容发生变化或存储位置发生改变时,元记录项自动更新.Office办公文档编辑是指对文件内容进行增、删、改操作,每次保存动作对应一组编辑行为.实验结果表明,即使编辑行为只造成一个字节内容改变,也会触发文件数据在磁盘内发生存储位置迁移.如图1(a)所示,编辑行为发生后文档数据在磁盘内被移动到新的位置,原始位置的文件内容仍然存留在磁盘内,只是对应存储空间被标识为空闲状态,其它文件可以重新使用这块存储区域.文件的元记录项也发生迁移,原始记录项被分配给其它文件重新使用,文件系统产生一个新的元记录项指向磁盘内当前文件数据区域.
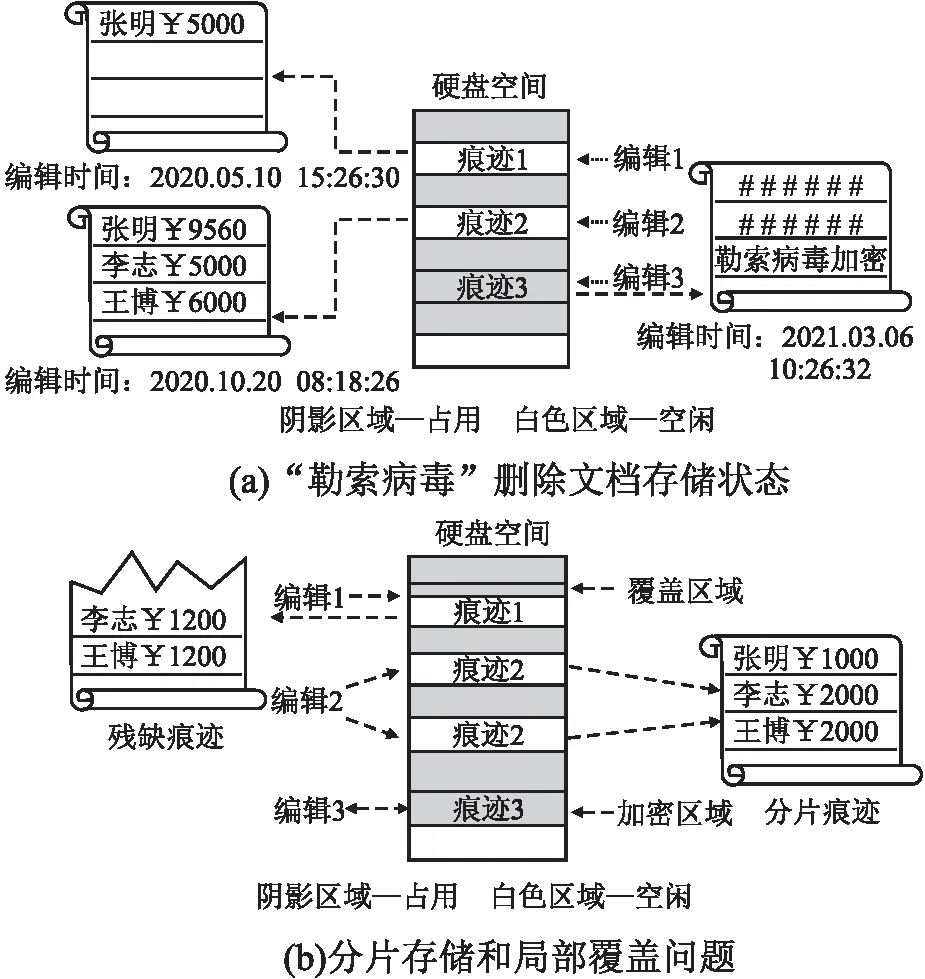
图1 磁盘内遗留的办公文档编辑过程痕迹Fig.1 Traces of document editing process left in disk
用户主机感染勒索病毒后,勒索病毒通过扫描文件系统元数据,快速定位全部重要文档存储位置,将文档依次读入内存加密,再将密文写回磁盘原始存储位置,覆盖原始文件内容.除了最后一次编辑痕迹外,办公文档其他编辑痕迹在元文件中并未记录,即勒索病毒只会加密、删除办公文档最后一次编辑痕迹,而不会对之前遗留在磁盘内的编辑痕迹进行加密、删除处理.因此,可以通过提取办公文档遗留的编辑过程痕迹来恢复原始文档内容.
办公文档编辑过程中会在磁盘内遗留多处痕迹数据,这些编辑过程痕迹对应的存储空间被文件系统标识为空闲状态,可以分配给其它文件重新使用.文件系统在分配存储空间时,为防止出现磁盘碎片,会优先使用空闲空间的首部或尾部数据块,这导致部分编辑痕迹数据首部或尾部可能被局部覆盖,造成文档首尾特征值消失.此时,即使编辑痕迹仍有大量数据残留,但因首部特征值被局部覆盖,现有数据恢复方法无法有效识别、恢复文档内容.如图1(b)所示,编辑1遗留的痕迹数据首部被覆盖,首部特征值消失,即使这组痕迹内仍有大量数据残留,现有数据恢复方法也无法利用首部特征值识别、恢复这组文件数据.
文件在编辑过程中,存储在磁盘内的文件数据极易出现分片存储情况,即文件内容被分为多段存储在磁盘不同区域内[12],如图1(b)所示编辑2产生的痕迹数据被分为两个分片存储在磁盘内.现有方法可以根据文件首尾特征值恢复连续存储的文件内容,但当文件以分片方式,离散分布于磁盘内时,无法有效识别、恢复文档数据.
3 Office电子文档分片重组问题
Office电子文档在编辑过程中,存储在磁盘上的文件数据极易出现分片情况,即文件内容被分为多段,分别存放在几块非连续存储区域内.图2(a)所示Office文档容量为0X447E个簇块,文档被划分为6个分片存储在磁盘内,分片大小依次为0X6、0X1FEB、0X0A23、0X1164、0X08FD和0X9个簇块.图2(a)给出了每个分片的容量和存储位置,以第3个分片为例,其在磁盘存储空间的起始簇号为0X0A2D,分片容量为0X0A23个簇块,6个分片在磁盘存储空间内的存放次序为3、4、5、1、2、6.

图2 Office文档分片重组问题Fig.2 Office document fragmentation and reorganization

(1)
为了计算正确的分片次序,需要标识出原始文件中相邻的分片对.本文使用权重值C(i,j)表示分片Aj和Ai相邻的可能性,权重值越大表示两个分片相邻的可能性越大,反之越小,权重最大值为1.有多种技术可以计算权重值,例如通过相邻分片边界数据块CRC32校验值计算,或者通过边界数据块熵值计算.一旦全部分片两两之间权重值都被计算出来,正确重组原始Office文档的最佳排序π也就计算出来了.根据最佳排序π计算出的n个节点累计权重值一定大于其它可能排序计算出的累计权重值[14].
如果用全部候选权重值C来构成n个节点的完全图邻接矩阵,则公式(1)中求最佳排序π,使得T值最大的问题也可以抽象为图问题.其中节点i代表数据分片i,边的权重C(i,j)代表分片j与分片i相邻的可能性.正确的排列次序π是图中的一条路径,该路径遍历所有节点,并且该路径的累计权重值大于其它路径的累计权重值.寻找这条最佳路径问题相当于在一张完全图中找出一条累计权重值最大的哈密顿路径问题,问题的最佳解决方案是比较难于获得的.前面只考虑了单个Office文档的恢复问题,但实际环境中,计算机存储空间内通常有多个Office文档需要恢复,每个文档又由若干个数据分片组成.分片数量众多,且不清楚哪些分片属于特定的Office文档,这些因素使得Office数据分片恢复问题复杂性进一步提高[14].
当分析由n个数据分片组成的k个Office文档恢复问题时,可以将这些分片看成由n个节点组成的一张完全图,相邻节点之间的权重值代表两个分片在同一个Office文档中位置相邻的可能性.假设Pi是第i个Office文档的重组路径,那么全部k个Office文档的最佳重组路径集合{P1,P2…Pk}是n个节点构成的完全图中k条顶点不相交路径,如图2(b)示例.因此,查找k个最佳排序问题等价于在完全图中寻找K条顶点不相交路径问题,这些路径的累计权重值最大,这是一个NP完全问题[14].
在实际环境中,解决k个Office文档数据分片恢复问题难度相对小些.这是因为Office文档有固定组成结构,在文档尾部存在一个目录区,根据目录区数据可以确定Office文档总大小,同时根据目录项可以在磁盘空闲空间内找出全部Office数据分片,还可确定分片的排列次序.如果目录区数据遭到覆盖,可以根据数据分片边界位置数据块CRC32校验值重组分片.
4 Office文档数据分片识别、重组方法
图3说明了Office文档数据分片识别、重组方法的基本原理.图3(a)显示了一个Office文档的基本存储结构,由3部分组成,即数据块区、目录区和目录结束记录[15].数据块采用ZIP存储结构,图3(a)所示文档包括4个数据块(即obj1-obj4).目录区由多个目录项构成,每个目录项保存了一个数据块在整个Office文档中的起始偏移地址,同时记录了数据块名称、块数据CRC32校验值(注意这个校验值是未压缩块数据的CRC32校验值[16])、块数据压缩前和压缩后大小,上述4种信息也存储在对应数据块首部.

图3 Office文档数据分片识别、重组原理图Fig.3 Data segmentation recognition and reorganization
算法1的主要功能是从磁盘空闲空间内识别出全部Office数据分片,再查找出全部目录项数据块,根据目录项将分片重组为完整的Office文档,同时对分片边界受损数据块进行修复.算法流程如下:
算法1.
输入参数:磁盘空闲空间地址信息.
输出参数:无.
Step1.在磁盘空闲存储空间内,搜索识别Office数据分片,具体步骤见算法2.
Step2.查找包含Office文档目录结束记录的数据分片,令这类分片数量为m(即待恢复的Office文档数量为m),设置num=1.
Step3.根据第num个Office文档目录项识别第num个文件全部数据块,具体步骤参见算法3.
Step4.第num个Office文档重组,具体步骤见算法4.
Step5.第num个Office文档中受损数据块修复,具体步骤见算法5.
Step6.设置num=num+1,如果num<=m,则执行Step 3,否则,算法结束.
算法2的主要功能是寻找残留在磁盘内的全部Office数据分片.分片的识别方法是先找到全部数据块,如果这些数据块首尾相接,说明它们属于同一个分片,如果数据块出现不连续情况,表明发现了新的分片,分片计数值增加.算法流程如下:
算法2.
输入参数:全部磁盘空闲存储空间地址信息.
输出参数:全部Office数据分片地址信息.
Step1.磁盘内空闲存储空间数量为n块,令space=1,frag=1.
Step2.令ST=第space块空闲空间起始地址.
Step3.将修改时间和ZIP标志位作为搜索关键字,从地址ST开始查找Office数据块.如果查找成功,令BT1=数据块起始位置,BL1=数据块长度,设置分片起始位置CT[frag]=BT1,分片长度值CL[frag]=BL1,ST=BT1+BL1,执行Step 4;如未命中Office数据块,执行Step 6.ZIP标志位值为0X504B0102或0X504B0304或0X504B0506,数据块的修改时间字段值为0X00002100,即1980-01-01 00:00:00.
Step4.从起始地址ST开始,继续查找Office数据块,如成功命中,执行Step 5;否则,执行Step 6.
Step5.BT2=命中块起始地址,BL2=命中块长度值;如果BT2=BT1+BL1,即两个数据块首尾相接,则令CL[frag]=CL[frag]+BL2,ST=BT2+BL2,BL1=BL2,BT1=BT2,执行Step 4.如果BT2≠BT1+BL1,则令frag=frag+1,新识别分片起始位置为CT[frag]=BT2,分片初始长度值CL[frag]=BL2,设置ST=BT2+BL2,BT1=BT2,BL1=BL2,执行Step 4.
Step6.如果CT[frag]≠0,则令frag=frag+1.令space=space+1,如果space<=n,则跳转到Step 2,否则,算法结束.
以图3为例,分析算法2图3(b)所示Office文档被文件系统划分为3个分片存储在磁盘内,存放次序为分片2、分片3和分片1.Office数据块采用ZIP存储格式,与所有ZIP类型文件具有相同的首部标志位,标志位分别是0X504B0506、0X504B0304和0X504B0102.如果仅使用上述3种标志位作为搜索关键字,会产生大量误报情况.研究发现ZIP类型文件(如APK程序文件)的修改时间字段存储了数据块内容发生变化的实际时间,这个字段是一个动态变化的数值,时间计量单位精确到秒.2007以上版本Office文件也采用ZIP压缩存储结构,但Office文件的修改时间字段值为0X00002100(即1980-01-01 00:00:00),这个字段不会因为数据块内容改变而发生变化,这是Office文件与其它类型ZIP文件的一个明显区别.因此,将修改时间字段与标志位一起设置为搜索关键字可以有效避免误报,准确识别出磁盘空闲存储空间内的全部Office数据块[17].通过块首部标志位可以确定块起始地址[18],通过块首部长度字段可以确定块结束位置,如果两个数据块首尾相接,说明它们隶属于同一个数据分片,否则说明出现了新的分片,分片计数值加一.利用这种方法可以识别出磁盘空闲空间内的全部Office数据分片,图3(b)所示存储空间内Office数据分片识别结果如图3(c)所示.
算法3的主要功能是根据第num个Office文档的目录项搜索其全部数据块,确定每个数据块的起始和结束位置.如果某个数据块定位失败,则相应的块起始和结束地址设置为-1.算法流程如下:
算法3.
输入参数:全部Office数据分片地址信息和第num个Office文档目录区域数据.
输出参数:全部数据块的起始和结束地址.
Step1.设置item_m=第num个Office文件目录项数量,令block=1.
Step2.如果block>item_m,算法结束,否则执行Step 3.
Step3.在数据分片地址空间内,将修改时间、ZIP标志位、数据块对象名、压缩前后块数据大小和CRC32校验值作为搜索关键字,定位第block个目录项对应的第block个Office数据块.如定位成功,设置BST[block]=数据块起始地址,EST[block]=数据块结束地址,否则,设置BST[block]=-1,EST[block]=-1.之后,令block=block+1,执行Step 2.
算法4的主要功能是重组Office文档.首先新建一个Office文档,其大小与待恢复文档相同.之后按照目录项中存储的块偏移地址,将第num个Office文档全部数据块从磁盘空闲存储空间内读出,依次写入新建文档的相应偏移地址,完成文档重组.算法流程如下:
算法4.
输入参数:第num个Office文档目录区数据,第num个Office文档全部数据块起始与结束地址,以及全部Office数据分片地址信息.
输出参数:第num个重组Office文档.
Step1.令block=1,filesize=目录区大小+目录区域偏移地址+目录结束记录大小.创建一个大小为filesize的目标文件,将第num个Office文件目录区域数据存储到新建立文件末尾.
Step2.第num个Office文件的目录项个数为m,如果block<=m,则执行Step 3,否则,算法结束.
Step3.令OP[block]=第block个数据块在Office文件中的逻辑偏移地址,BST[block]=第block个数据块物理起始地址,EST[block]=第block个数据块物理结束地址.如果BST[block]>0 andEST[block]>0,则从逻辑偏移地址OP[block]开始,将第block个数据块写入新建文件.设置block=block+1,执行Step 2.
在Office文档数据分片重组算法4中,通过目录结束记录可以计算出Office文档总大小[19],公式如下:Office文档总大小=目录区大小+目录区域偏移地址+目录结束记录大小,目录区在Office文档的偏移地址恰好等于数据块区容量[20],因此三者之和等于Office文档总大小[21].算法的处理思路是创建一个新文档,容量与待恢复文档大小相同,再将恢复出的目录项和数据块依次写入新建文档的特定偏移位置,进而完成文档重组[22].根据目录项中存储的OBJ_name、CompressedSize、UnCompressedSize和CRC32等特征值定位相应数据块,再按照目录项中记录的偏移地址,将数据块写入新文档相应的偏移位置.图3(d)为重组之后的Office文档,可见位于分片边界位置的obj2和obj4数据块识别错误,部分不属于该文档的数据内容被写入新文件.如果此时打开新建文档,通常会提示出错信息,部分严重错误(如document.xml受损)会造成文档内容无法正常显示,因此需要对分片边界数据块识别错误进行修正.
5 分片边界数据块识别错误修复方法
下面以图3(c)中obj4数据块的修复为例分析受损数据块的修复原理,修复过程如图4所示,这里指定簇块大小为4096字节.图4中SP1′为分片2内最后一个数据块首部起始地址,down(SP1′)为分片2内最后一个数据块首部向下到达的第一个簇块边界位置,SP1为分片3内第一个数据块起始位置,up(SP1 )为分片3内第一个数据块首部向上到达的首个簇块边界位置.利用obj4块首部数据计算出块长度值为FLEN,如长度值满足FLEN=down(SP1′)-SP1′+n× 4096+SP1-up(SP1) ,则两个分片可以尝试配对修复.图4中EPn代表第n次正确识别簇块,EPn′代表第n次错误识别簇块.

图4 分片边界数据块修复Fig.4 Repair of fragmented boundary data block
在图4所示例子中,FLEN=down(SP1′) -SP1′+2 × 4096+SP1 -up(SP1),长度值满足配对条件,可以尝试进行修复.目前已知数据块第1个分段obj4-1的起始地址是SP1′,第2个分段obj4-2的结束地址是SP1,只要能计算出第1个分段的结束位置(即分片2的结束位置)和第2个分段的起始位置(即分片3的起始位置),即可重组两个分段.需要注意的是,由于磁盘空间以簇块为分配单位,因此,分片起始或结束位置一定位于簇块边界.
算法的基本思路是通过不断调整数据块两个分段的大小,来探测正确的分片位置,直至动态组建的数据块CRC32校验值与块首部存储的CRC32值相同.首先将第1个分段大小预设为可能达到的最大值,即down(SP1′)-SP1′+n×4096,第2个分段大小设置为可能达到的最小值,即SP1-up(SP1),将两个分段组合在一起后,计算组成数据块的CRC32校验值.如计算出的CRC32校验值与数据块首部存储的CRC32校验值相同,说明配对成功,否则,配对失败,将第1个分段缩小1个簇块,第2个分段扩充1个簇块,再次匹配.重复上述过程,直至CRC32校验值正确,或第1个分段大小达到可能的最小值down(SP1′)-SP1′,第2个分段大小达到可能的最大值n×4096+SP1-up(SP1),如仍然无法通过CRC32验证,则当前数据块修复失败.在图4所示例子中,经过两次配对后,正确重组了obj4数据块.
算法5的主要功能是修复第num个Office文档位于分片边界位置数据块的识别错误.算法流程如下:
算法5.
输入参数:第num个Office文档的目录区数据,第num个Office文档每个分片在磁盘内的起始和结束地址,指向第num个新建立Office文档的指针.
输出参数:第num个修复后Office文档.
Step1.第num个Office文档共有u个分片,令整数变量frag=1.
Step2.如果frag<=u,则执行Step 3,否则,算法结束.
Step3.令FLEN=第frag个分片内最后一个数据块长度值,SP1′=第frag个分片内最后一个数据块的起始地址,down(SP1′)=第frag个分片内最后一个数据块的起始地址向下到达的首个簇块边界地址,SP1=第frag+1个分片内第一个数据块的起始地址,up(SP1)=第frag+1个分片内第一个数据块的起始地址向上到达的首个簇块边界地址,CS=磁盘簇块大小.如果(FLEN-down(SP1′)+SP1′-SP1+up(SP1))MODCS=0条件为真,则执行Step 4,否则执行Step 9.
Step4.令整数变量n=(FLEN-down(SP1′)+SP1′-SP1+up(SP1))/CS,设置整数变量cluster=n.
Step5.如果cluster>=0,则执行Step 6,否则执行Step 9.
Step6.令Frag1_pos=SP1′,Frag1_size=down(SP1′)-SP1′+cluster×CS,Frag2_pos=up(SP1)-(n-cluster)×CS,Frag2_size=(n-cluster)×CS+SP1-up(SP1),从地址Frag1_pos开始,提取Frag1_size字节数据作为第1部分内容,从地址Frag2_pos开始,提取Frag2_size字节数据作为第2部分内容,将两部分内容组合成一个数据块.计算组成数据块的CRC32校验值,如该值与数据块首部存储的CRC32值相同,说明配对成功,执行Step 7,否则,配对失败,执行Step 8,将前一部分内容收缩1个簇块,后一部分内容扩展1个簇块,重新配对.
Step7.根据特征值定位受损数据块在第num个新建立待修复Office文件中的逻辑偏移地址为OA,将Step 6重组成功的数据块从磁盘内读出,从逻辑偏移地址OA开始,将读出数据依次写入第num个新建立待修复Office文件,之后,执行Step 9.
Step8.令cluster=cluster-1,执行Step 5.
Step9.令frag=frag+1,执行Step 2,开始修复下一个受损数据块.
6 实验数据统计分析
6.1 办公文档编辑痕迹时间差及分片统计实验
办公文档编辑痕迹时间差是指两组痕迹形成的时间间隔,以“天”为单位进行统计.2007以上版本Office文件采用Ooxml(Office Open Xml)结构,以ZIP压缩格式存储在磁盘内.从磁盘内提取到办公文档编辑痕迹后,利用ZIP算法进行解压缩,提取出core.xml文件,其中存储了文件创建者、最后一次修改者、文件创建时间、修改时间、最后一次打印时间、编辑次序等关键信息.上述信息是在办公文档编辑过程中,由Office软件系统自动写入core.xml文件.由于文件创建时间精确到“秒”,如多组编辑痕迹创建时间相同,且创建者为同一用户,则认定这组数据为同一文档的编辑过程痕迹,可按照文件修改时间对编辑痕迹进行排序.最后一组痕迹(即文件当前数据)可以根据文件系统元数据项确定.如图5所示,3组痕迹创建时间相同,且均由同一用户kyc创建,因此确定为同一文件编辑过程遗留痕迹,由MYMMFT元数据项确定最后一组是文件当前数据,3组编辑痕迹时间差分别为8天和15天.

图5 办公文档编辑痕迹时间差计算方法Fig.5 Calculating of time difference in document editing
受磁盘空闲存储空间及文件大小等因素影响,办公文档编辑痕迹可能分为多段存储在磁盘内,分段个数即为文档的分片数量.由于办公文档编辑痕迹遗留在磁盘空闲存储空间内,相当于被删除数据,因此在文件系统元文件中没有对应的目录项,应用本文方法在识别、重组Office数据块时对编辑痕迹分片情况进行统计.办公文档当前数据(即最后一次编辑痕迹)的分片情况可以根据文件系统元记录项中存储的数据运行属性确定.
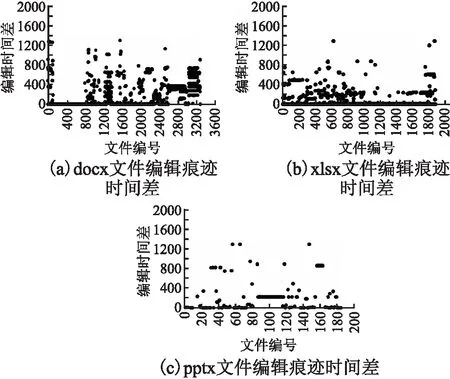
图6 办公文档编辑痕迹时间差分析Fig.6 Analysis of time difference in document editing
本文采用如下实验环境统计办公文档编辑痕迹时间差及分片存储情况.硬件设备为HP台式笔记本,Intel i7双核处理器、1.5TB容量HDD硬盘、16GB内存,安装2013版Office办公软件、WIN8操作系统.该设备于2018年1月采购,用于笔者的日常办公和科研管理工作,未更换过硬件设备,未进行过操作系统重装或磁盘格式化操作.实验设备F盘主要用于存储日常教学、科研、办案等资料数据,F盘容量为361.91G,剩余空间容量为51.2GB,采用NTFS文件系统.
应用本文方法识别、恢复F盘内Office办公文档编辑痕迹,实验统计结果如图6所示,对分类识别出的编辑痕迹按文件大小递增排序,依次编号,编辑时间差统计单位为“天”.实验共提取到3287组docx文档痕迹,1879组xlsx表文档痕迹,183组pptx幻灯片文档痕迹.3类办公文档痕迹与当前文件的编辑时间差统计结果如图6(a)-图6(c)所示,可见绝大部分编辑痕迹与当前文档时间差较近.与当前文档编辑时间差为0(即在同一天产生的痕迹)占比如下,docx文件占比45.23%、xlsx文件占比27.94%、pptx文件占比15.3%.这部分编辑痕迹与当前文档内容基本相同,其它与当前文档时间差较近的编辑痕迹也可近似还原文件原始内容.

图7 办公文档编辑痕迹分片情况分析Fig.7 Analysis of document editing trace fragmentation
3类文档编辑痕迹分片存储情况统计结果如图7(a)~图7(c)所示.由于文件编号是按照文档大小递增排序,可以看出docx编辑痕迹分片情况与文件大小有直接关联,随着文件容量的增加,编辑痕迹分片数量也在同步增长.xlsx文件产生的二分片编辑痕迹较多,pptx文件基本不分片.应用本文提出的办公文档编辑过程痕迹恢复方法可有效识别、恢复分片存储状态的编辑过程痕迹.
6.2 勒索病毒对办公文档处理方式实验
为测试勒索病毒对办公文档的处理方式,本文选择5种典型勒索病毒样本程序进行实验分析.为防止病毒对计算机系统及局域网安全构成威胁,全部实验任务均在虚拟机环境下进行.虚拟机采用15.1.0 build-13591040版本VMware®Workstation 15 Pro,实例安装Windows 8.1 Enterprise Evaluation操作系统,Intel i7双核处理器,16GB内存,40GB硬盘.实验准备任务包括:在虚拟机D盘上建立实验测试文件夹,内部放置docx、xlsx和pptx文件各10组,文件大小从10KB到20MB之间.使用20.3版winhex记录这些办公文档的磁盘存储位置,提取文档相应的MFT元记录.之后,制作虚拟机镜像文件.实验开始阶段:关闭虚拟机网卡(防止病毒对物理机和局域网环境造成影响),运行勒索病毒,观察病毒运行现象.待勒索信息出现后,使用winhex分析原始文件存储位置数据内容是否发生改变,分析MFT元记录变化情况,分析密文数据的存储状态,做好相关实验结果记录.之后,使用镜像文件还原虚拟机运行环境,再分析下一个病毒样本.利用虚拟机镜像技术可以彻底清除病毒数据,使得每个病毒样本在同一环境下进行测试分析,确保实验结果的准确性.

表1 勒索病毒对办公文档处理方式Table 1 Processing of office documents by ransomware
实验结果表明,全部勒索病毒均采用RSA、AES或DES算法对实验文件夹内的Office文档进行了加密处理,原始文件被删除,但对“Windows”,“Program Files”,“Program Files(x86)”等系统目录下的文本文档不进行加密、删除处理.如表1所示,4种病毒对办公文档进行了全文加密,而NOSTRO病毒仅对文档前1024字节进行加密(这部分数据通常存储了文档的重要信息,如被加密,将使文档无法正常使用),这种方式可以获得更快的加密速度.实验结果表明,Mindlost病毒仅对原始文件进行了删除处理,未覆盖原始文件数据,这部分内容可以使用常规数据恢复方法进行有效还原.其余4种病毒将密文数据写回原始文件存储位置,造成原始文件内容被完全或局部覆盖,这部分数据无法采用常规数据恢复方法进行还原.出于效率原因,全部勒索病毒均未对办公文档编辑过程痕迹进行处理,因此可利用编辑过程痕迹还原被勒索病毒删除、覆盖的原始办公文档.
6.3 勒索病毒删除文档编辑痕迹恢复实验
共有10名成员参与了实验测试,每人使用一台Windows系统主机,磁盘均采用NTFS格式文件系统,测试主机配置如表2所示,测试周期为10天.为防止勒索病毒破坏测试主机软、硬件系统,在测试开始前,对全部测试主机硬盘制作镜像,将原盘拆除,安装克隆磁盘.待全部测试任务结束后,重新装回原始磁盘,恢复测试机正常工作状态,同时对10块测试磁盘执行低层格式化操作,彻底清除病毒数据.

表2 测试系统配置参数Table 2 Test system configuration parameters
在实验测试期间,每名成员每天创建1个Office文档,随后对文档进行10次编辑操作,编辑行为包括插入、修改、删除、复制和粘贴,编辑操作时间间隔为随机值.创建文档类型包括docx、xlsx和pptx,经过编辑之后,文件大小在24KB至10MB之间.每次编辑完成后,详细记录编辑行为发生的时间和被测文件在磁盘内的存储位置.可以使用winhex提取文件存储位置,方法是先搜索被测文件的MFT记录项,再根据数据运行属性定位文件数据具体位置.测试期间内,测试员正常使用计算机处理日常工作.10天测试结束后,进行勒索病毒实验,选择“永恒之蓝”(WannaCry)勒索病毒作为测试样本,测试开始前,断开测试主机网络连接通道,在10台测试主机上种植勒索病毒,随后使用X-way forensics v20.8和本文方法对Office文档进行数据恢复,同时比较恢复结果.全部实验任务完成后,关闭测试主机,拆除测试硬盘,重新安装原始磁盘,恢复测试主机正常工作,对测试磁盘执行低层格式化操作,彻底清除勒索病毒.

图8 恢复结果统计分析Fig.8 Statistical analysis of restoration results
实验结果显示,10台测试主机内全部办公文档均被勒索病毒加密,原始文件被删除,同时勒索病毒未对编辑过程痕迹进行加密和删除处理.图8(a)显示的是测试员1记录的一个被测Excel文档在磁盘内的10次编辑痕迹.其中编辑2和编辑6的痕迹数据处于两分片存储状态,其余痕迹未分片.编辑1与编辑6的数据内容存在局部交叉覆盖,导致编辑1的痕迹数据从0X2800F簇开始的1个簇块内容被覆盖.编辑5的全部数据内容和编辑6从0X0B8F簇开始的15个簇块内容被编辑8的痕迹数据覆盖.编辑1和编辑6痕迹数据的文件头均遭到局部覆盖,首部特征值丢失,X-way无法识别恢复这两组痕迹数据.本文工具可以根据Office文档目录区数据恢复编辑1和编辑6遗留痕迹数据,但是这两组痕迹内容残缺,打开恢复出的Office文件时提示出错,但文档内容可以正常查看.除了编辑1、编辑5和编辑6的痕迹数据遭到局部或完全覆盖,其余7组痕迹数据完好地遗留在磁盘内.勒索病毒运行之后,第10组痕迹(即当前文件内容被加密),原始数据被密文覆盖,导致这组痕迹无法还原.本文方法可以完整恢复出其余6组痕迹数据,对这个被测Excel文档的10组编辑痕迹来说,恢复率为60%,且第9组痕迹与被加密文档内容基本相同.由于编辑2的痕迹数据处于两分片存储状态,X-way无法有效恢复,因此X-way的恢复率为50%.
图8(b)显示了10组测试员的平均统计结果,按照文件创建时间对文件进行分组,即10组测试员第一天建立的10个文档为第一组,之后每天建立的文档分为一组,全部100个文档分为10组,统计每组文件编辑过程痕迹恢复率.图8(b)显示了10名测试员使用本文方法和X-way恢复率的平均统计结果.通过这组统计数据可见,越晚建立的Office文档,其编辑过程痕迹恢复率越高.这是因为随着时间的推移,早前遗留的编辑痕迹遭到局部覆盖的可能性也在增加.由于本文工具可以有效恢复分片存储的Office文档数据,因此本文工具在Office文档恢复方面,总体效果好于X-way等现有数据恢复工具.
7 结 语
针对勒索病毒加密、删除办公文档分片无法有效恢复问题,本文提出一种Office电子文档数据分片识别、重组方法,该方法通过ZIP标志位和修改时间字段识别全部Office文档编辑过程数据分片,再利用特征值匹配技术确定一个Office文档的全部数据块,根据目录项确定数据块在文档内的逻辑偏移地址,进而完成文档重组.对重组后的文档,采用CRC32校验技术修复分片边界数据块识别错误.该方法有效解决了分片存储的Office电子文档编辑过程痕迹数据恢复问题,可用于感染勒索病毒主机办公文档数据恢复任务.但当办公文档目录区数据遭到局部覆盖时,无法利用目录区数据重组数据块.针对这一问题,笔者计划进一步研究不依赖目录区数据的Office电子文档数据分片识别、重组方法.
