融合先验信息的残差空间注意力人脸超分辨率重建模型
2023-05-12李佳慧
袁 健,李佳慧
(上海理工大学 光电信息与计算机工程学院,上海200093)
1 引 言
超分辨率(Super Resolution,简称SR)重建是指把低分辨率图像重建成具有良好视觉质量的高分辨率图像.该技术广泛应用于医学诊断、航空遥感检测、刑事调查和安防监控等领域[1].
人脸图像是图像处理、计算机视觉等领域研究的重要对象之一,其识别技术已较成熟,因此大量的人脸识别系统被广泛应用.但是想要人脸被准确识别还必需质量达标的人脸图像.在一些特殊的公共场所比如道路旁、商场、超市、小区、银行营业网点等地方安装的监控设备,考虑到在这些场景下需要监控的时间长,产生的视频数据量多,要求数据存储介质的容量足够大,网络带宽的要求高等因素,通常所设置的监控图像的分辨率较低,再加上此类公共场所的摄像头往往在高处,拍摄出的人脸图像尺寸较小,使用现有的人脸识别系统识别的准确率较低.因此研究对此类低分辨率人脸图像进行预处理的技术使之满足现有人脸识别系统识别具有实用价值.超分辨率重建技术恰好可以把低分辨率人脸图像重建出高分辨率的人脸图像,可满足上述要求.
目前相对广泛的超分辨率图像重建的方法分为3类:基于图像插值的方法、基于图像重建的方法以及基于深度学习的方法.基于图像插值的方法,如双三次插值、最邻近插值[2],其算法简单,重建出的图像容易造成细节丢失.基于图像重建的算法涉及到了概率论和集合论等知识,如迭代反投影[3]和最大后验法[4],此类方法具有计算量小收敛速度快的优点,但是限制了重建性能.
近年来基于深度学习的超分辨率图像重建成为了主流的方法,Dong[5]等提出了超分辨率卷积神经网络(SRCNN),第一次把深度学习方面的相关知识应用于图像超分辨率重建中,在性能和重建结果上都超过了传统图像重建方法,从而大大提升了重建图像的视觉效果.Zhang[6]等提出残差通道注意力网络(RCAN),该算法引入通道注意力机制区别对待不同的通道.Tai[7]等提出一种深度循环网络(DRRN),将残差学习和循环学习引入到图像超分辨率重建的技术上.生成对抗网络(GAN)[8]的提出推动了超分辨率技术重建的发展.Leding[9]等提出了一种基于GAN的超分辨率图像重建方法(SRGAN),利用生成对抗网络技术可以得到逼真的视觉效果.Wang[10]等提出了一种ESRGAN模型,以残差密集连接模块做为网络的主要组成部分,在自然图像的纹理细节上获得了更好的视觉效果.以上算法网络的主体部分都是堆积残差块结构,随着网络加深虽然能提取到丰富的语义特征,但是随之也会提取出过多的冗余特征信息.同时都没有考虑到人脸图像的特点,如面部结构信息,因此容易导致细节重建不到位、边缘轮廓模糊,无法恢复出面部组件的高频细节特征信息,视觉感受效果不好.
人脸图像具有独特的特征信息,如身份信息和面部组件信息.研究表明,将人脸属性信息融入超分辨率重建中,对重建的结果有一定的帮助.YuX[11]等提出条件 GAN ,在网络的中间层添加额外的人脸属性信息,从而实现人脸图像SR重建.Yu Chen[12]等提出了FSRNet,使用堆叠沙漏网络模型从人脸图像中提取几何先验信息,经过解码器恢复出高分辨率图像.Yu X[13]等提出了一种利用多任务卷积神经网络的方法,将人脸的结构信息显式地合并到人脸超分辨率重建的过程中.Zhang[14]等提出联合重建任务和身份识别任务的模型,以人的身份特征信息来约束重建的结果.但是这些结合人脸先验信息的算法仅将提取到的先验特征级联到网络的一层,且仅使用了一次,弱化了先验信息的约束力度,导致生成的人脸图像纹理细节不充足,其次,融合身份信息和身份识别的网络结构导致模型体积较大,需要借助庞大的人脸数据集训练网络,耗费大量的训练时间,对机器设备也有要求.
为了加强人脸先验信息的约束力度,并充分利用高频特征和减少冗余特征信息,结合生成对抗网络在恢复纹理细节特征的优势,本文提出了融合先验信息的残差空间注意力人脸超分辨率重建模型(Residual spatial attention face prior super-resolution model,简称RSAFSR模型)来实现人脸图像的超分辨率重建,以便现有人脸识别系统的识别.RSAFSR模型的创新工作体现如下:1)首次提出在残差网络的每个残差块中都融入面部先验信息作为网络的面部组件补偿信息,可以帮助重建出更精细的面部边缘轮廓信息及五官轮廓信息;2)提出了融合人脸先验信息的残差空间注意力激活算法(Residual spatial attention activation algorithm based on face prior information ,简称RSAAF),使用DepthWise[15]逐通道卷积代替全局平均池化,对携带高频信息的面部细节结构赋予更高的注意力权重,使网络更加关注于人脸轮廓特征和面部五官特征;3)提出了多阶特征融合算法(Multi-StageFeature Fusion algorithm,简称MSFF算法),使不同尺度的浅层和深层特征的信息有效融合,补充特征信息在卷积传播过程中的丢失,增加了感受野信息,能够让网络学习出更多的面部细节特征,提升了网络对人脸图像局部纹理区域的重建效果.
2 相关理论
2.1 残差学习
残差网络(ResNet)[16]的思想是在主干卷积网络的侧边增加一个恒等跳线连接,将输入直接通过这个跳跃连接线快速传输到输出层,网络可以直接学习输入与输出之间的残差部分F(X).残差学习的基本结构单元如图1所示.残差公式如式(1)所示:
φ(x)=F(X)+X
(1)
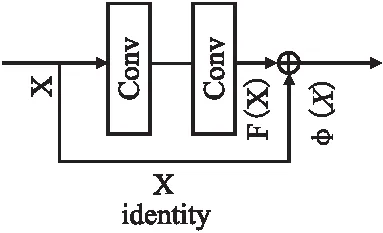
图1 残差结构图Fig.1 Residual structure
式中F(X)表示输入输出之间的残差函数,X表示特征输入,φ(x)表示特征输出.
2.2 通道注意力
通道注意力的核心思想是使网络在训练过程中更加关注有高频信息的通道.通道注意力机制的结构如图2所示.
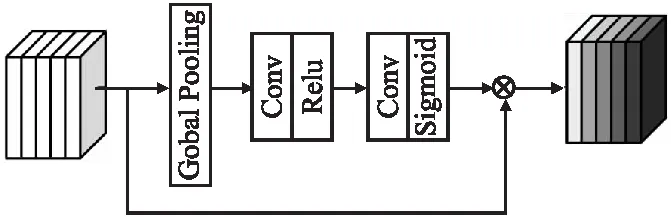
图2 通道注意力机制的结构Fig.2 Channel attention mechanism structure
通道注意力的输入是U=[u1,u2,u3,…,uc]∈RH×W×C,其中H、W、C分别对应特征图的高度、宽度和通道.经过全局平均池化(Global pooling)对空间维度压缩,得到1×1×C的通道描述符,计算公式如式(2)所示.将通道描述符1×1×C进行特征降维,得到1×1×C/r的描述符.经过Relu激活函数之后,进行扩张升维,将1×1×C/r的描述符恢复成原来的维度.经过缩放后的特征与输入的特征进行逐像素相乘,得到每一个通道的注意力权重,计算公式如式(3)所示:
(2)
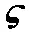
(3)
2.3 损失函数
图像的损失函数通常包括像素损失、感知损失[17]和对抗损失3部分.
1)像素损失:本文的图像像素损失采用L1范式计算,即为重建的超分辨率图像(SR)和原始高分辨率图像(HR)之间的差值.函数表达式如式(4)所示:
(4)
其中N表示批量大小.IHR原始高分辨率图像,G(ILR,θg)代表重建出的超分辨率图像.θg表示生成器模型里的参数.
2)感知损失:为了增加重建图像的纹理细节信息,使用感知损失来进行约束.感知损失函数表达式如式(5)所示:
(5)
其中,φ(·)表示预训练的神经网络.φ(i,j)中的i和j表示VGG19网络中第i个最大池化层前经过第j个卷积所提取到的特征图.
3)对抗损失:利用生成对抗网络相互对抗的机制,通过神经网络的学习和对抗训练,使生成器能够生成更加清晰、逼真的超分辨率图像.对抗损失的函数表达式如式(6)所示:
(6)
式中,N表示训练人脸样本的数量,G表示生成网络.D(G(ILR,θg))为判别器网络判定生成图像为真实图像的概率.
4) 图像的损失函数:图像的损失函数表达式如式(7)所示:
Lloss=λ1Lcon+λ2Ladv+γLVGG19
(7)
其中λ1、λ2、γ表示权重参数,在反向传播中通过修改权重参数来优化网络.
3 RSAFSR模型结构
人脸超分辨率重建的网络设计是影响着重建结果的一个重要因素.RSAFSR模型结构设计了人脸先验信息、空间注意力激活和多级特征融合等策略.网络模型结构如图3所示,主要由人脸先验模块(Facial PriorBlock,简称FPB)、低维特征提取模块(Low Feature Extraction Block,简称LFEB)、特征重建模块(Feature Reconstruction Block,简称FRB)与上采样模块(Upsampling Block,简称USB)4部分组成,其中FRB模块是关键部分,它包含两个子模块:残差空间注意力激活模块(Residual Spatial Attention Activation Block,简称RSAAB)和多阶特征融合模块(Multi-StageFeature Fusion Block,简称MSFFB),这两个模块对人脸纹理细节和边缘轮廓的重建有着很大的贡献(详细介绍见3.3节和3.4节).RSAFSR模型的处理流程为:先将低分辨率人脸图像(32×32)经过LFEB模块处理得到浅层特征信息,然后将通过FPB提取到的面部先验特征图并融入到每个RSAAB中得到空间权重特征值,接着将各个RSAAB提取的空间权重特征经过MSFFB处理得到人脸图像的深度特征,再与由LFEB模块提取的浅层特征进行长距离跳跃连接(Long skip connection,简称LSC)相加得到重建特征图,最后经过USB模块进行×4放大因子的上采样,输出SR人脸图像.
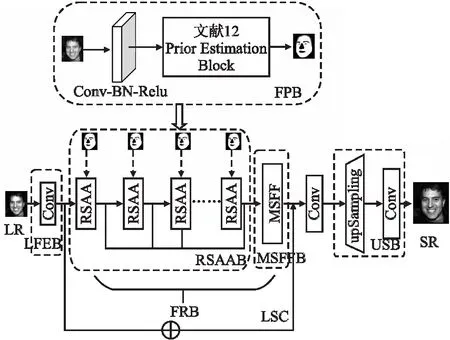
图3 RSAFSR模型结构Fig.3 Residual spatial attention face prior super resolution structure
3.1 人脸先验模块FPB
低分辨率人脸图片丢失了大部分纹理细节信息,但是面部轮廓等形状信息很好的保存下来.结合低分辨率人脸图像的特点,本文提出利用面部组件作为先验信息,从低分辨率的面部图像中获取有效的人脸特征信息,引导网络重建出细致的面部细节.
现有的面部超分辨率重建方法已经证明,使用面部先验补偿信息约束重建结果,其表现出的结果优于其他通用的超分辨率重建方法.本文利用文献[12]所提出人脸解析模型提取眼睛、鼻子等众多关键点几何先验信息.提取的关键点区域有面部轮廓、左右眼睛、左右眉毛、鼻子和嘴巴等8个关键点,并将每个关键区域可视化在一张图像上.
3.2 低维特征提取模块LFEB
低维特征提取模块主要提取人脸图像的浅层特征,使用3×3的卷积核对低分辨率人脸图像进行特征提取,这个卷积层只能提取人脸图像的轮廓特征.将此特征做为下文中空间残差注意力激活模块的输入,卷积计算表示如式(8)所示:
(8)
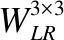
3.3 残差空间注意力激活模块RSAAB
图像超分辨重建的核心要点是尽可能多地恢复图像中的高频信息,但是低分辨率的图片含有大量的低频信息和少量的高频信息,如果所有的特征信息都被“一视同仁”,随着网络加深,网络的低频信息特征冗余就会越多,将造成网络缺乏重要特征信息的学习能力.引入通道注意力能够提高网络的自适应学习能力.考虑到常规的通道注意力使用的全局平均池化层将特征图上每个空间像素值看作等同重要,并没有关注空间像素的高频信息.因此,本文提出了融合人脸先验信息的残差空间注意力激活算法RSAAF,使其能关注空间像素的高频信息.
RSAAF算法有两个重要优化:1)残差空间注意力激活块希望特征图中的每一个像素位置都可以学习到相对应的权重值.在2.2小节的通道注意力中使用全局平均池化层笼统的将特征图的全局像素信息加以平滑,破坏了特征的空间像素信息和语义特征,每个空间像素区域学习的权重应该不同,本文使用DepthWise[15]的逐通道卷积代替全局平均池化,不同于常规卷积,DepthWise逐通道卷积的特点是一个通道只被一个卷积核卷积,因此可以得到通道不同的空间位置上的特征信息.具体优化的过程为:输入的特征图首先经过一个1×1的卷积核提取不同通道之间融合的特征,再经过Relu激活函数之后,使用DepthWise逐通道卷积学习空间像素的权重信息,经过sigmoid激活函数将学习的空间特征权重取值范围特征映射到[0,1]之间,最后和输入的特征进行逐像素相乘得到空间层面上不同区域的权重分配特征图.使用改进的注意力机制对人脸图像特征的边缘高频区域和五官区域的像素位置赋予更多的空间注意力,使网络更注重保留人脸图像的高频细节部分.
2)将提取的面部先验信息融入到残差空间注意力激活块中.为了充分利用面部先验信息,引入一种先验信息补偿机制,即在每个残差空间注意力块中都加入人脸组件特征图,增加了先验组件信息的约束力度,加强了人脸图像的先验信息的再利用,更有利于恢复人脸图像细节特征.根据残差学习思想,在图像中低频信息区域的像素残差值通常趋向于 0,而高频信息区域的像素残差往往大于0,所以加入短跳跃连接局部残差学习和长距离跳跃连接学习,将描述人脸图像细节的特征信息由前面的卷积层直接传播到后面的卷积层,提高了上下文之间的信息流通,能够有效的缓解训练过程中的梯度消失问题和退化问题.
RSAAF算法步骤示意图如图4所示.
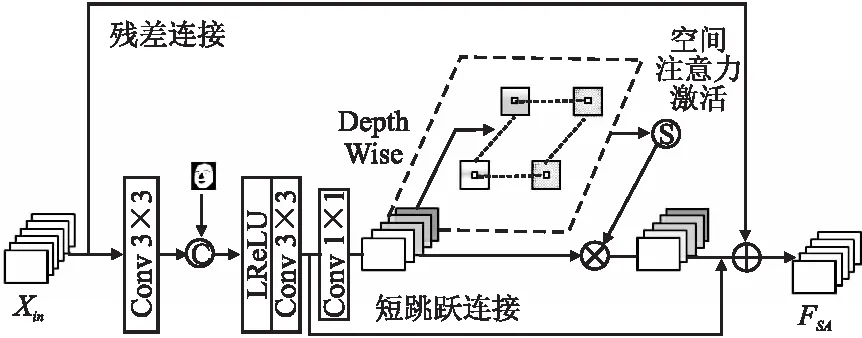
图4 RSAAF算法步骤示意图Fig.4 RSAAF algorithm schematic diagram of algorithm steps
RSAAF算法描述如下:
输入:人脸图像的浅层特征
输出:残差空间注意力特征
步骤1.提取先验级联特征
(a)对于输入特征Xin,使用3×3的卷积核按式(9)进行卷积计算.将卷积层的输出和人脸先验特征级联,得到先验级联特征值F0.
(9)
式中,f0(·)表示卷积运算,Xin表示输入特征,PLR表示低分辨率人脸先验特征图,[·]表示级联运算.
(b)经过LRelu激活函数后再使用3×3的卷积核按式(10)对激活后的特征提取,得到激活特征F1.
(10)
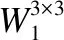
步骤2.计算空间激活注意力
把式(10)得到的输出特征F1做为空间激活注意力块的输入,经过注意力模块的提取后,得到注意力权重值,进而可以得到输入特征在空间上注意力的分配.公式(11)和公式(12)分别计算空间激活注意力描述符S和由S得到的人脸先验注意力特征F2.
(11)
F2=S(F1)
(12)
步骤3.局部残差学习
为了让对重建有效的上下文信息流通,在空间激活注意力结构上加入一个短跳跃连接,形成一个局部残差学习,得到空间激活注意力结构的残差信息.
步骤4.计算残差空间注意力特征
使用残差连接按式(13)将步骤1得到的F1特征和步骤2得到的F2以及输入特征Xin进行残差计算,得到最终的输出FSA.
FSA=F2+F1+Xin
(13)
3.4 多阶特征融合模块MSFFB
人脸超分辨重建时往往会忽略不同深度的特征图的依赖性,从而削减重建网络对人脸图像纹理细节的恢复能力,而且不同深度的特征图携带不同尺度的感受野信息,这些提取的特征都对人脸图像超分辨率的重建起到一定的贡献.同时考虑到人脸图像的纹理信息在网络的深层传播阶段很容易丢失,导致重建出的结果存在纹理细节模糊的问题.为了充分利用每个模块携带的不同尺度的特征信息,本文结合先卷积后再统一融合的思想,提出了多阶特征融合算法MSFF,该算法融合了网络各层提取到的不同深度的特征信息,加强了特征重用,将多层深度特征图进行了卷积融合,防止了人脸图像的高频特征信息在传播过程中出现损失,使得人脸图像在五官局部细节特征上的纹理表现得更加细腻.
MSFF算法步骤如下:
输入:残差空间权重特征
输出:深层特征
步骤1.计算8个RSAAB的融合值
按式(14)、式(15)计算8个由3.3小节得到的残差空间注意力模块的输出FSA,得到融合后的特征值Fcon.
FSAi=Rs(FSAi-1)=Rs{Rs-1[…R1(FSA1)]}
(14)
Fcon=Concat(FSA1:FSA2,…:FSA8)
(15)
式中,Rs表示RSAAF算法的计算函数.Concat(·)表示特征融合卷积层,FSAi表示第i个残差空间注意力激活块提取的特征,依次,可知FSA2和FSA8.
步骤2.计算深层特征值
将融合后的结果Fcon经过长跳跃连接学习(LSC)与LFEB提取的浅层特征Xf相加,得到深层人脸特征FMSFFB.计算公式如式(16)所示:
(16)
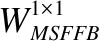
3.5 上采样模块USB
上采样模块主要由亚像素卷积组成.亚像素卷积又称为像素洗牌,即把深度特征FMSFFB上采样成高分辨率图像.
首先把上述处理得到的深层特征FMSFFB用一个3×3的卷积核进行通道扩充,放大因子为通道数的平方.接着使用3×3卷积核对上采样后的特征图FSub进行超分辨重建,可得到人脸超分辨率图像ISR,计算公式如式(17)、式(18)所示:
(17)
(18)
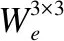
4 实验结果及分析
4.1 数据集与训练细节
本文的模型训练与网络结构实现均采用 Pytorch 框架.操作系统为64位的 Ubuntu16.04,配置显卡是 GPU RTX 2080Ti,11G显存.在实验过程中,使用CelebA[18]和Helen[19]两个公开的人脸数据集对本文改进的模型训练.CelebA是一个超大规模的名人人脸标注数据集,它共有20多万张人脸图片,总共有10177个名人,并为图片做好了必要的特征标记.在CelebA 数据集中采用前 18000 张面部图像用于训练,测试数据使用 CelebA 数据集中后1800个人脸图像.Helen数据集是一个相对较小的人脸数据集,有2230张人脸图像,每张图像都有对应的解析图,在Helen 数据集采用后1800 张图像做为训练样本,前180 张人脸图像做为测试样本.为了减轻训练的难度,需要对CelebA 数据集和Helen数据集图像做预处理,即图像样本重新采样和裁剪.先选择人脸图像的面部中心区域,从人脸图像的中心区域开始裁剪,统一裁成128×128的高分辨率人脸图像.再将高分辨率人脸图像降采样至32×32的大小,作为实验中低分辨率人脸图像的输入.实验均进行×4 放大因子的超分辨率重建.
选取Adam算法作为本实验的优化器,将算法中的参数设置为β1= 0.9,β2= 0.99,ε= 1e -8.初始学习率设定为0.0001.当网络经过10000次迭代后,学习率缩减为初始值的90%.
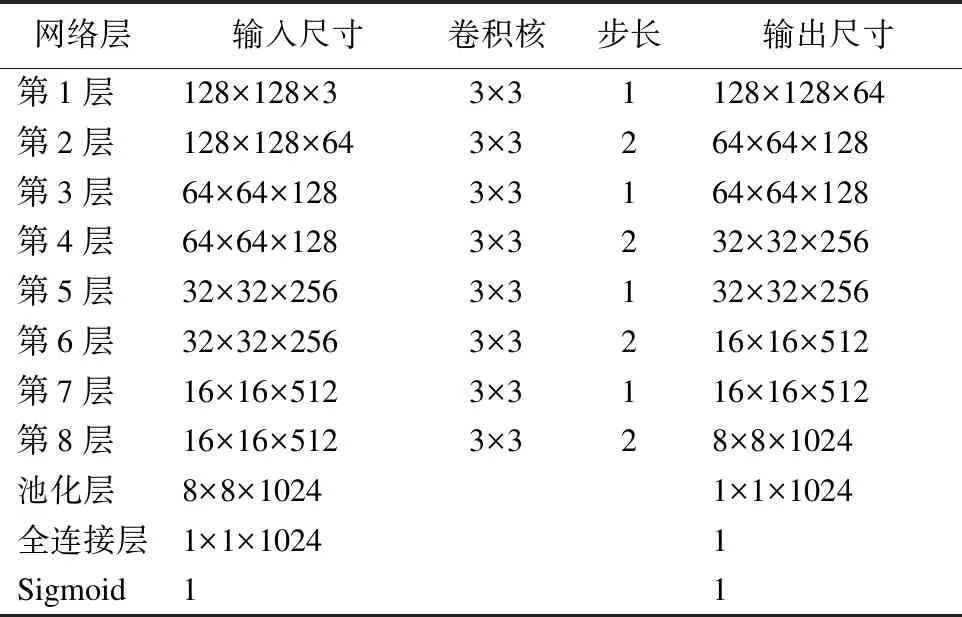
表1 判别器网络参数配置Table 1 Discriminator network parameter configuration
根据文献[8],生成对抗网络(GAN)能够让生成的图像更加逼真.RSAFSR模型是GAN中的生成网络,同时,需要构建一个判别器用于对抗训练.判别器是一个二分类器,将生成的SR“伪”图像和原始的HR“真”图像输入到判别器中,通过交替循环训练生成器网络和判别器网络,最终使整个网络到达一个Nash 均衡(判别器的输出概率为0.5),此时训练结束.通过神经网络对抗训练,判别器不断提高鉴别真伪图像的能力,使生成器能够生成更加清晰逼真的超分辨率图像.判别器的网络结构如表1所示.
根据表1可知,判别器网络主要由8个卷积层、一个池化层和一个全连接层组成.每个卷积核的大小都为3×3,经过8个卷积层提取图像特征,最后经过全连接层和sigmoid激活函数输出一个0~1之间判别值.
4.2 评价标准
4.2.1 客观评价
本文使用峰值信噪比(Peak Signal to Noise Ratio,简称PSNR)、结构相似性(Structural Similarity Index,简称SSIM)作为重建图像质量的客观评价指标,峰值信噪比是为了比较两幅图像之间的像素均方误差[20].PSNR的数值越高则表示重建出的图像失真度越小,PSNR的单位为dB.计算公式如式(19)和式(20)所示:
(19)
(20)
其中,y为原始HR图像,y′为生成器重建后的SR图像,H对应图像的高度,W对应图像的高度.
结构相似性反应出人眼的真实感受,它主要是用来比较两幅图像之间的结构相似度的指标.SSIM的取值范围在[0,1]之间,它的取值靠近1附近时,表示两幅图片间的相似度越高,重建效果就越好.计算公式如式(21)所示:
(21)
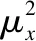
4.2.2 主观评价
本文使用主观评价(Mean Opinion Score ,简称MOS)它是用来衡量不同的方法所重建的人脸超分辨率图片的质量.本文中具体的做法是,选取了24位实验者去测评人脸超分辨率图片的质量,要求每一位测试者都要为每一种重建的图像进行主观打分,分值区间为:1(质量差)-5(高质量) .测试者在本文使用的数据集上测评了每个图像的20个版本.每组包含6个模型: Biubic、SRCNN、RCAN、SRGAN、FSRNet和本文算法(RSAFSR)得到的超分辨率图像,总共120张人脸图像进行评分.
4.3 客观指标分析
为保证对比结果的公平性,实验中的每个模型的上采样因子都设置为4.实验选取传统超分辨率重建模型Biubic[2]和具有代表性基于深度学习的模型SRCNN[5]、RCAN[6]、SRGAN[9]、FSRNet[12]与本文模型RSAFSR进行对比.
表2列出了6种超分辨率重建模型在celeA和helen数据集上的PSNR(单位:dB)、SSIM和MOS值.根据表2的数据可知,PSNR、SSIM和MOS值的变化趋势基本一致.且6种不同算法的评价指标的值基本呈现出“上升”趋势.
从表2可以看出,后5个模型的指标要明显高于第1个传统模型.RSAFSR模型的PSNR、SSIM和MOS值均大于Biubic、SRCNN 、RCAN和SRGAN.观察表2的数据发现,FSRNet模型的PSNR值比RSAFSR算法略高,但是在SSIM和MOS数值上,RSAFSR模型相比于FSRNet均有所提升.因为融入了人脸先验信息,重建图像的面部细节得到了补充也就更接近真实的人脸图像.因此上述6个模型中,RSAFSR模型最优.
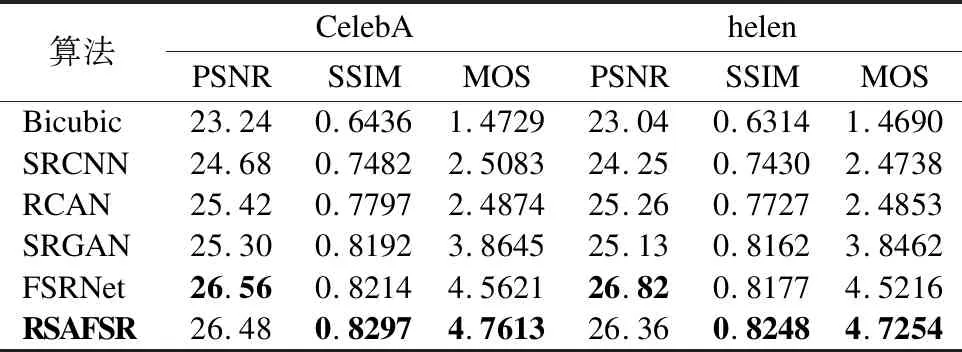
表2 celeA和helen数据集在不同模型上的评价结果Table 2 Evaluation results of celebA and helen datasets in different models
4.4 主观效果分析
图5展示了6种超分辨率重建模型对人脸面部图像的重建结果.其中,HR表示数据集中的原始图像.Bicubic 是传统插值方法,重建出的人脸图像感观效果最差,仅能恢复出人脸的大体轮廓,面部的五官区域较为模糊.SRCNN与RCAN基于像素损失的重建,恢复出的人脸图像锐度有了提升,但是其仅关注于低频特征信息,从而丢失了高频细节特征.SRGAN和FSRNet的重建效果较好,但是重建出的人脸图像的整个面部都显得过于平整,整个面部像是使用了磨皮滤镜.RSAFSR算法考虑到了面部结构特征,使用了人脸先验知识.重建出的五官能看出比较清晰的锐度,面部轮廓等部位恢复得更加逼真,重建之后得到的结果接近于原始HR图像.

图5 面部图像超分辨重建效果对比Fig.5 Comparison of facial image super resolution reconstruction
图6展示了低分辨率的人脸图像局部区域的重建结果.测试结果分为(a)和(b)两个部分,其中(a)部分测试图像主要研究眉毛、眼睛和鼻子区域的重建情况,(b)部分的测试图像主要研究嘴巴、下颌线轮廓和脸部区域的重建情况.由图6分析,SRCNN 、SRGAN与 Bicubic算法相比,经过4倍放大因子之后,在图6的(b)部分老人面部皱纹及下颌线周围边缘轮廓区域整体看起来比较模糊.如图6中(a)(4)所示,SRGAN算法的重建结果在示例中女孩眼睛部位、眉毛区域的形状上有稍微的变形;FSRNet算法的重建的结果相对良好,由于缺乏足够的面部高频信息,在示例中老人图片的下颌线周围等边缘区域有模糊的现象.RSAFSR算法在眼睛、鼻子等人脸的关键部位重建出的结果更加清晰,面部纹理细节更加丰富,边缘细节信息和轮廓形状较其他的方法保留的更加完整,更接近真实图像.

图6 局部细节图像超分辨重建效果对比Fig.6 Comparison of super resolution reconstruction results of local detail images
4.5 模型效率分析
算法效率也是反应算法模型优劣与否的一个主要指标,因此需要衡量模型的大小、测试算法的运行效率.本文从单幅图像测试时间和模型规模两个方面分析.
单幅图像测试时间是表示网络模型对一幅低分辨率图像进行重建所耗费的时间.实验选取一幅分辨率为32×32人脸图像进行超分辨率重建测试,为了得到相对公平的结果,表3中所有算法的测试时间的计算均在本文所使用的实验环境和实验数据集上进行.如表3所示,RSAFSR的测试时间相对于EDSR算法慢了8ms,由于本文提出的RSAFSR在每个残差空间注意力激活模块(RSAAB)加入了人脸先验信息,在处理图像的过程中相对慢了一些,但是PSNR的值比EDSR提升了0.46dB.
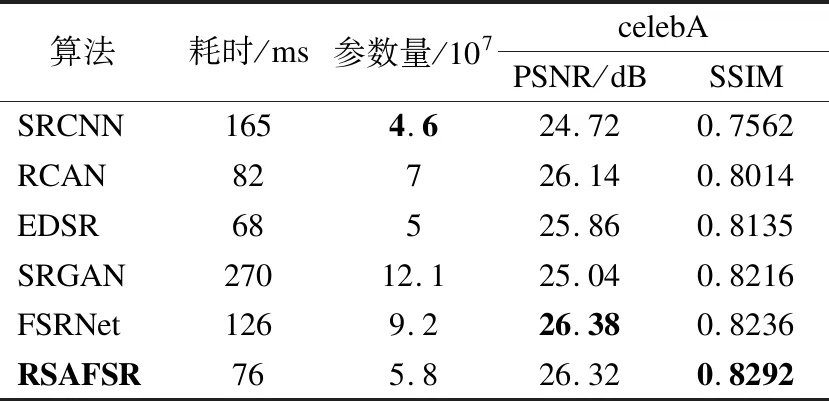
表3 不同模型的运行时间与规模对比Table 3 Comparison of running time and scale of different models
模型规模即神经网络中所有带参数层的权重参数总量.如表3所示,RSAFSR模型的参数量相较于FSRNet减小了大约2个数量级,可以在保证原有重建图像的质量不受影响的基础上大大减少模型参数数量和计算量.
从以上分析可以看出,RSAFSR模型综合性能与现有几种流行模型相比较而言,虽然在PSNR和SSIM的得分上没有很大的提升,但是具有占用存储空间小、运行时间短等优点,并且在单幅图像的超分辨率重建的速度上,有一定的优势同时又能够重建出质量较高的超分辨率人脸图像.
4.6 人脸识别准确性测试
为了验证超分辨率图像重建结果对人脸识别算法识别准确率的影响,本文选取常用的基于FaceNet[21]、CosFace[22]和ArcFace[23]3种原生人脸识别算法的识别系统进行人脸识别.选用人脸识别算法中的常用LFW[24]数据集进行测试.
每种人脸识别算法都设置了3类测试图像.第1类:将原始HR图像进行下采样处理得到的32×32低分辨率图像(如:LR+FaceNet).第2类:数据集中的原始128×128的图像(如:HR+FaceNet).第3类:采用本文提出的模型进行4倍因子放大,得到分辨率为128×128的SR人脸图像(如:RSAFSR+FaceNet).如表4显示了3类测试图像的准确率以及第3类相对于前两类准确率的增长幅度.
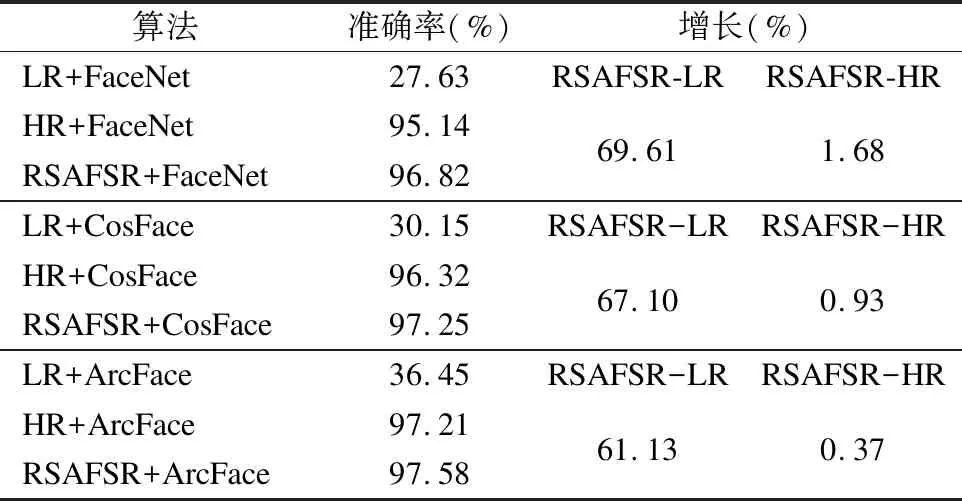
表4 人脸识别算法准确率对比Table 4 Comparison of face verification algorithm results
由表4可知,经过RSAFSR的预处理可以有效提高人脸识别的准确度.相较于使用LR测试图像3种识别算法的识别准确率可分别提升69.61%、67.10%、61.13%,甚至比原始图像的识别准确率分别提升了1.68%、0.93%、0.37%,这是因为RSAFSR模型重建出的人脸图像不仅扩大了人脸图像的分辨率,得到了更加清晰的图像,而且还抑制了原始图像中影响人脸识别的噪声.
综合上述实验结果,RSAFSR模型通过对低分辨率人脸图像进行超分辨率重建的预处理,使得现有人脸识别算法对低分辨率的人脸识别的准确率有了很大的提升.
5 结 论
本文提出的融合先验信息的残差空间注意力人脸超分辩率重建模型RSAFSR借助面部先验信息从低分辨率图像中先获取人脸不同组件部位的先验特征,然后嵌入到生成对抗网络模型中,再采用残差空间注意力激活算法突出空间位置中携带高频信息特征,能够学习到更多面部细节信息,使用的多阶特征融合算法充分利用不同尺度的特征图,防止携带高频信息的人脸特征在网络传播中丢失.实验结果表明重建出的超分辨率人脸图像具有真实的细节信息和更加丰富细腻的纹理特征,大大提升了利用现有人脸识别算法的人脸系统对低分辨率人脸图像的识别准确率,并且与其他5种模型相比,RSAFSR模型具有较低的耗时和较少的参数.
今后将进一步研究更低分辨率人脸图像的超分辨率重建技术,同时结合具体的安防监控设备或者移动设备,实现该技术的落地应用.
