高效多注意力特征融合的图像超分辨率重建算法
2023-05-12李方玗贾晓芬赵佰亭
李方玗,贾晓芬,2,赵佰亭,汪 星
1(安徽理工大学 电气与信息工程学院,安徽 淮南 232001) 2(安徽理工大学 省部共建深部煤矿采动响应与灾害防控国家重点实验室,安徽 淮南 232001)
1 引 言
单幅图像超分辨率重建(Single Image super-Resolution,SISR)技术是指将给定的一幅低分辨率(Low-Resolution,LR)图像通过特定算法恢复成相应的高分辨率(High-Resolution,HR)图像,旨在克服或补偿由于图像采集系统或采集环境本身限制,导致的成像图像质量低下、感兴趣区域不显著等问题,目前已广泛应用于医学影像[1]、人脸识别[2]、卫星遥感[3]、公共安防[4]等多个领域.
传统的图像超分辨率重建算法主要依靠基本的数字图像处理技术进行重建,包括基于插值,基于重建,基于学习.基于插值的算法通过对LR图像的相邻像素点插值得到重建图像,但它丢失较多的高频信息,重建后的图像视觉效果不佳;基于重建的算法以原图像退化模型为基础,结合未知重建后图像的先验知识来约束重建结果,计算过程复杂;基于学习的算法是对大量LR图像和对应的HR图像之间的映射关系的学习,需构造大量训练集,其过程较为费时.
传统的方法计算复杂且不能有效恢复图像的原始信息,近年来,随着深度学习在图像超分辨率重建中的广泛应用并逐渐取得了较好的结果,受到越来越多研究人员的关注.Dong等[5]于2014年首次将卷积神经网络应用于超分辨率重建,提出的SRCNN利用3个卷积层以像素映射的方式生成重建的图像,但计算成本高且收敛速度慢.Dong等[6]在此基础上于2016年提出FSRCNN,其中内部采用了更小的卷积层,并在网络末端通过反卷积层放大尺寸,提升速度的同时性能略有提高;同年,Shi等[7]提出的高效的亚像素卷积神经网络ESPCN在重建模块使用重新排列后的亚像素层实现上采样操作,重建效率有明显的提升.以上超分辨率重建模型比较轻量但重建效果有待提高,于是人们开始通过增加网络深度来提高模型性能:Kim等[8]提出20层的深层网络VDSR,它利用残差学习[9]的思想加快网络训练的收敛速度,重建效果比起之前的网络有很大的提升;2018年,Ahn等[10]提出一种在ResNet上实现级联机制的架构CARN,其中间部分基于ResNet,网络的全局和局部使用级联机制以更好融合各层网络的特征,性能大幅度提升但参数量激增;2020年,Zhao等[11]提出像素注意力的超分辨率重建网络(PAN),通过引入轻量的像素注意力机制来提升网络的重建性能;同年Tian等[12]提出的CFSRCNN利用特征提取模块学习长短路径特征,通过将网络浅层的信息扩展到深层来融合学习到的特征,其参数略少于CARN,但PSNR也有所降低.以上方法通过增加网络层数使模型性能得到提升,但随之激增的参数量导致训练难度大幅度增加,有些模型降参后重建效果却不达预期,可见参数和性能很难达到很好的平衡.
综上,早期CNN超分辨率重建网络虽轻量但性能不佳,追求重建效果而增加网络深度的网络尽管性能有所提升,但庞大的参数量导致训练的时间复杂度增大,同时特征信息在深层次网络传递过程中的丢失也会影响重建效果.为此作者提出一种高效多注意力特征融合网络(EMAFFN).它采用渐进式融合的连接方式结合通道随机混合(C shuffle)操作,由浅及深逐步提取并融合提取到的特征信息;同时采用高效多注意力块从通道和空间两个维度学习,自适应的对特征信息赋予不同权重,保证对LR图像中有效特征的充分提取.再设计多尺度感受野块RFB_x进一步增强提取到的有效特征,以此加强特征传递、缓解信息丢失,保留深层次特征,使重建后的图像保留更多的高频细节.
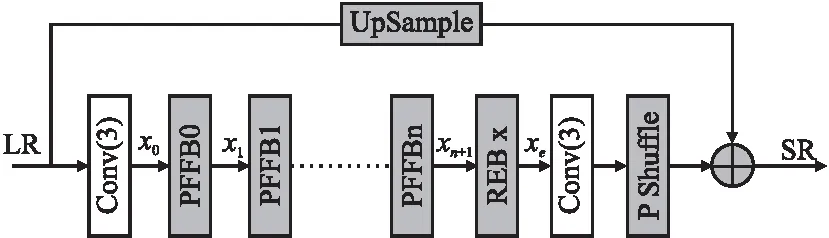
图1 高效多注意力特征融合网络EMAFFN结构Fig.1 Efficient multi-attention feature fusion network EMAFFN structure
2 高效多注意力特征融合网络
2.1 网络结构
图1即为高效多注意力特征融合网络(EMAFFN)的结构,它主要包括特征提取模块和重建模块这两个部分.特征提取模块分为浅层特征提取模块和深层特征提取模块,浅层特征提取模块为一个3*3卷积层,对输入的LR图像在低维空间进行初始特征提取,有效减少其计算量;深层特征提取模块包含n个渐进式特征融合块(PFFB),PFFB采用渐进式融合的连接方式逐步提取图像的深层次特征信息以加强特征传递,同时结合其内部的高效多注意力块(EMAB)对提取到的特征信息进行加权使网络更多的关注高频信息;重建模块由多尺度感受野块RFB_x、一个3*3卷积和一个亚像素卷积层组成,RFB_x块的多分支结构对PFFB块提取的特征进一步增强,并融合多尺度的特征信息来提升模型的重建性能,随后将LR图像的双三次上采样结果与亚像素卷积层上采样结果进行叠加得到重建后的图像.具体来说:
x0=fIFE(ILR)
(1)
xn+1=fPFFBn(…fPFFB1(fPFFB0(x0))…)
(2)
xe=fRFB_x(xn+1)
(3)
ISR=fP(xe)+fup(ILR)
(4)
其中,ILR是输入的LR图像,fIFE为一个3*3大小的卷积操作,x0即提取到的初始特征;fPFFBi为第i个渐进式特征融合块的映射函数,i=0,1,…,n.使用RFB_x对经过n个PFFB块提取到的深层特征xn+1进行增强,fRFB_x即为此过程,xe为增强结果;fP是对增强结果进行3*3卷积和亚像素卷积操作,fup是将输入的LR图像进行双三次上采样操作,最后得到输出结果SR图像ISR.
2.2 特征提取模块
首先利用3*3卷积提取输入图像的浅层特征信息,再将这些信息送入n个串联的渐进式特征融合块(PFFB)逐步提取图像的深层次特征.
2.2.1 渐进式特征融合块
为解决超分辨率重建模型由于网络过深导致低层次信息在传输时丢失的问题,受启发于MAFFSRN[13],设计图2的渐进式特征融合块(PFFB),它通过多次通道随机混合(C shuffle),实现对EMAB块中卷积层结果的“信息交互”,将输出的通道进行重新分组,然后混合不同通道的信息,解决卷积层之间的信息流通不畅,不增加计算量的同时使通道充分融合.PFFB中采用4个高效多注意力块(EMAB)层层递进,逐步提取图像的深层次信息.对每个经EMAB块提取到的特征进行C shuffle,随后连接相邻两个经C shuffle处理的特征再次进行C shuffle以提高网络的泛化能力,使用1*1卷积移除冗余信息,产生的结果与下一个经C shuffle操作的信息进行特征融合.在PFFB内的EMAB块间重复此操作,逐步收集局部信息并进行特征融合,加强特征传递,有助于提升重建图像的精度.最后采用残差学习将输入特征xi与融合后的特征叠加得到第i个PFFB块的输出特征xi+1,最大限度的利用了LR图像信息来缓解特征在传递过程中的丢失.
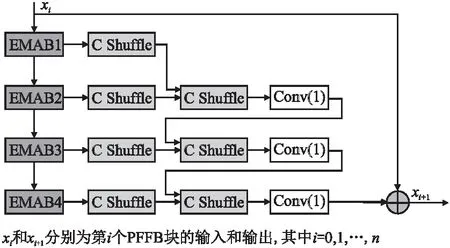
图2 渐进式特征融合块PFFB的结构Fig.2 Progressive feature fusion block PFFB structure
综上,PFFB通过“渐进式”特征融合的连接方式,加强特征提取并对提取到的多层信息进行融合,方便每一层充分利用前面层数学习到的所有特征,使有限的特征实现更好的传递和重用.
2.2.2 高效多注意力块
注意力机制根据不同特征信息的重要性来分配权重,以强化网络中的关键信息、弱化无用信息[14],可分为空间注意力[15]和通道注意力[16]等.为有效提取图像的特征信息,利用增强空间注意力(ESA)[17]和高效通道注意力(ECA)[18]提出了图3高效多注意力块(EMAB),它充分利用通道和空间的特征信息逐步对图像的浅层特征去噪,使网络侧重于关注图像中高频细节,有助于增强重建后图像的纹理细节信息.空间注意力分支受启发于ESA,在两个3*3卷积核后使用1*1卷积层缩减通道尺寸,通过步长为2的步长卷积扩大感受野并结合2*2的最大池化层进一步降低网络的空间维数.之后使用空洞卷积层进一步聚合感受野的上下文信息,降低内存的同时提升网络性能,将得到的特征进行上采样操作恢复空间维度,并通过1*1卷积恢复通道维度.另外,在图3中所示的3个卷积层后加入激活函数Frelu[19]来加快收敛速度防止梯度爆炸;在通道注意力分支采用高效注意力块ECA,它避免了SE-Net[20]中维度缩减带来的问题,通道注意力由快速的一维卷积生成,通过通道维数的非线性映射自适应确定内部卷积核的尺寸.该一维卷积可以高效实现局部跨通道交互,通过捕获局部跨通道的信息,完成其间的相互交流,学习有效的通道注意力.ECA块轻量高效,它的加入使得网络性能提高的同时也不会增加模型复杂度.

图3 高效多注意力块EMAB的结构Fig.3 Efficient multi-attention block EMAB structure
2.3 重建模块
人类视觉系统中,群体感受野(pRF)的规模随着视网膜定位图中离心率而增加,它能够强调靠近中心区域的重要性,受此启发感受野块RFB被提出[21].它模拟人类视觉感受野来增强从轻量CNN模型中学习到的深度特征,其结构主要包括两部分:多分支卷积层和空洞卷积层.多分支卷积层模拟多种尺寸的pRF增强了网络的特征提取能力,空洞卷积层再现pRF大小与离心率之间的关系增强了感受野.
在RFB块中,不同尺寸的卷积核如1*1、3*3、5*5对应于不同大小的感受野,其中较大的卷积核会使得模型复杂度增加,因此对RFB的结构进行微调得到RFB_x,如图4:将RFB块结构内部的5*5卷积层使用3*3卷积层替代,同时3*3卷积层被1*3和3*1卷积替代,这种微调有效减少了参数量和时间复杂度,同时能够提取到更加精细的特征.本文算法在n个PFFB块之后加入RFB_x来增强提取到的深层次特征,多尺度的融合特征并重建,保留了深度丰富的特征、恢复了图像细节.具体来说,将第n个PFFB块的输出特征xn+1作为RFB-x块的输入,使用不同大小的多分支卷积层进行多尺度特征提取,同时引入不同空洞率的空洞卷积[22],空洞卷积的空洞率越大则采样点离中心点越远,感受野就越大,有助于在更大的区域捕获信息以生成效果更好的特征图,同时不增加参数量.最后连接多个分支的输出以多尺度的融合不同特征.
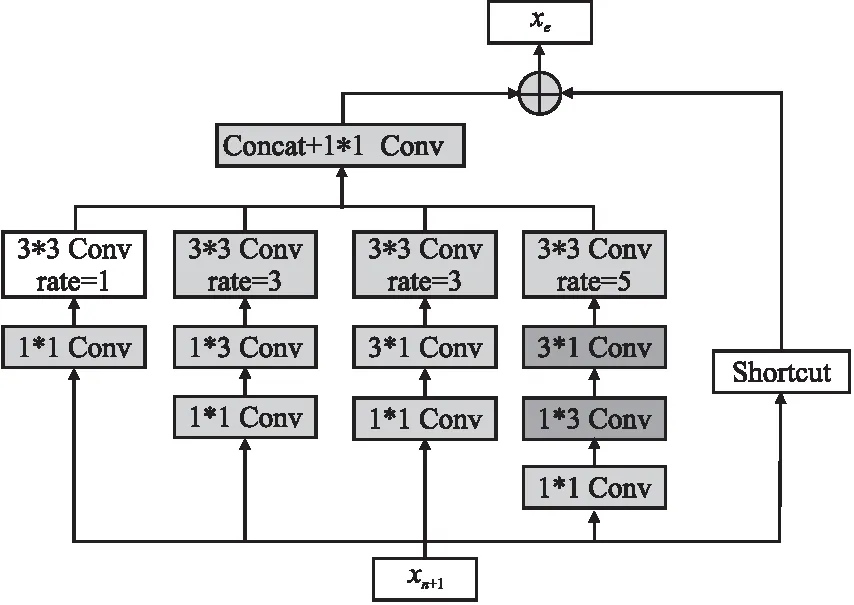
图4 RFB_x结构Fig.4 RFB_x structure
之后将RFB_x块输出的特征xe进行3*3卷积并通过亚像素卷积层放大,同时对输入LR特征进行双三次上采样,并将LR图像的双三次上采样结果与亚像素卷积层上采样结果进行叠加得到重建后的图像.
2.4 损失函数
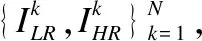
(5)
其中,k表示训练集中的第k对LR-HR图像,k∈[1,N]且k∈Z,N取800,θ={wk,bk}为模型的学习参数,HSR即本文模型.通过不断训练优化模型参数使L(θ)达到最小值,使得重建后的图像尽可能接近于真实图像.
3 实验与结果分析
本文实验应用Pytorch-1.7的深度学习框架,在windows10,3090Ti平台上完成.网络经过1000个epochs的训练,初始学习率参数设置为2e-4,每经过200个epochs学习率将衰减为原来的0.5倍,批量大小设置为16,采用L1损失函数和AdamP优化器来训练模型.
3.1 数据集及评价指标
采用超分辨率重建的公共数据集DIV2K[24]作为训练数据集,它包括1000张分辨率为2K的高质量图像,选用其中的800张HR图像进行双三次下采样得到LR图像,使用构成的LR-HR图像对来训练本文模型.在测试阶段,采用SR重建中广泛使用的基准数据集:Set5[25],Set14[26],BSD100[27],Urban100[28].实验使用峰值信噪比(PSNR)和结构相似性(SSIM)这两个参数作为本算法重建性能的客观衡量标准.PSNR和SSIM这两个指标越高,说明图像失真程度越小,图像质量越好.
3.2 消融实验
3.2.1 确定渐进式特征融合块(PFFB)的数量
为验证EMAFFN中PFFB块个数对网络重建性能的影响,分别对包含7、8、9个PFFB块的模型训练1000个epochs,在Set5测试集上得到放大系数为2倍的PSNR和SSIM值,实验结果如表1所示.可见,随着PFFB块的增加,重建效果均有所提升.其中,使用8个PFFB块较7个的网络PSNR值提升了0.14dB;使用9个PFFB块比使用8个的网络PSNR值提升0.04dB,重建效果不显著,且因参数量过多导致时间复杂度增加,故最终确定选用8个PFFB块作为本文网络的特征提取模块.
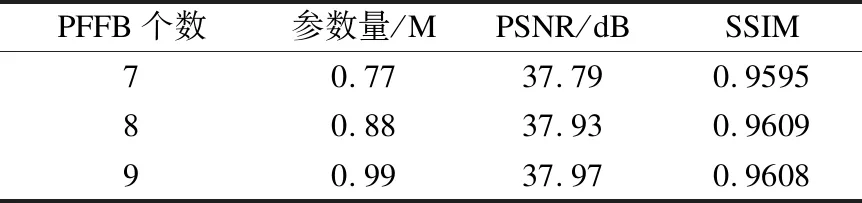
表1 特征提取模块数量选取Table 1 Number of feature extraction modules selected
3.2.2 验证注意力机制EMAB及多尺度感受野块RFB_x的有效性
为充分验证EMAFFN模型中所加注意力块及多尺度感受野块的有效性,分别对实验1,2,3,4中的模型训练1000个epochs,并使用测试数据集Set5进行放大系数为2的测试.如表2所示,实验1中的模型是将EMAFFN网络中EMAB块和RFB_x块使用3*3卷积替代,实验2和实验3分别是将EMAFFN网络中的EMAB块、RFB_x块使用3*3卷积替代,实验4为EMAFFN.较实验1而言,实验2在普通卷积构成的PFFB及RFB_x作用下PSNR和SSIM分别提升了0.13dB和0.0004,实验3在由EMAB块构成的PFFB作用下,PSNR和SSIM分别提升了0.34dB和0.0010.实验1与实验4相比,本文算法的PSNR提升了0.52dB,SSIM提升了0.0027;综上,EMAFFN模型中的EMAB块和RFB_x块是有效的,均有助于提升网络的重建性能,有较好的重建效果.
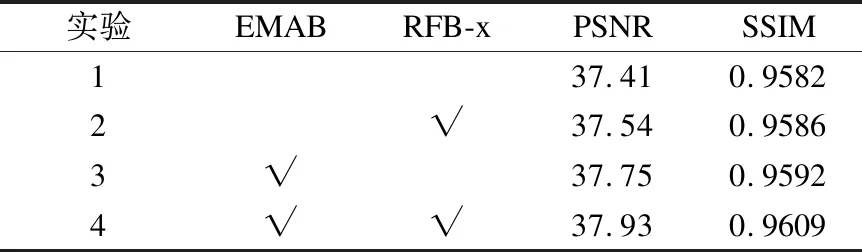
表2 注意力机制及多尺度感受野块的有效性验证Table 2 Validation of attention mechanism and multi-scale perceptual wild blocks
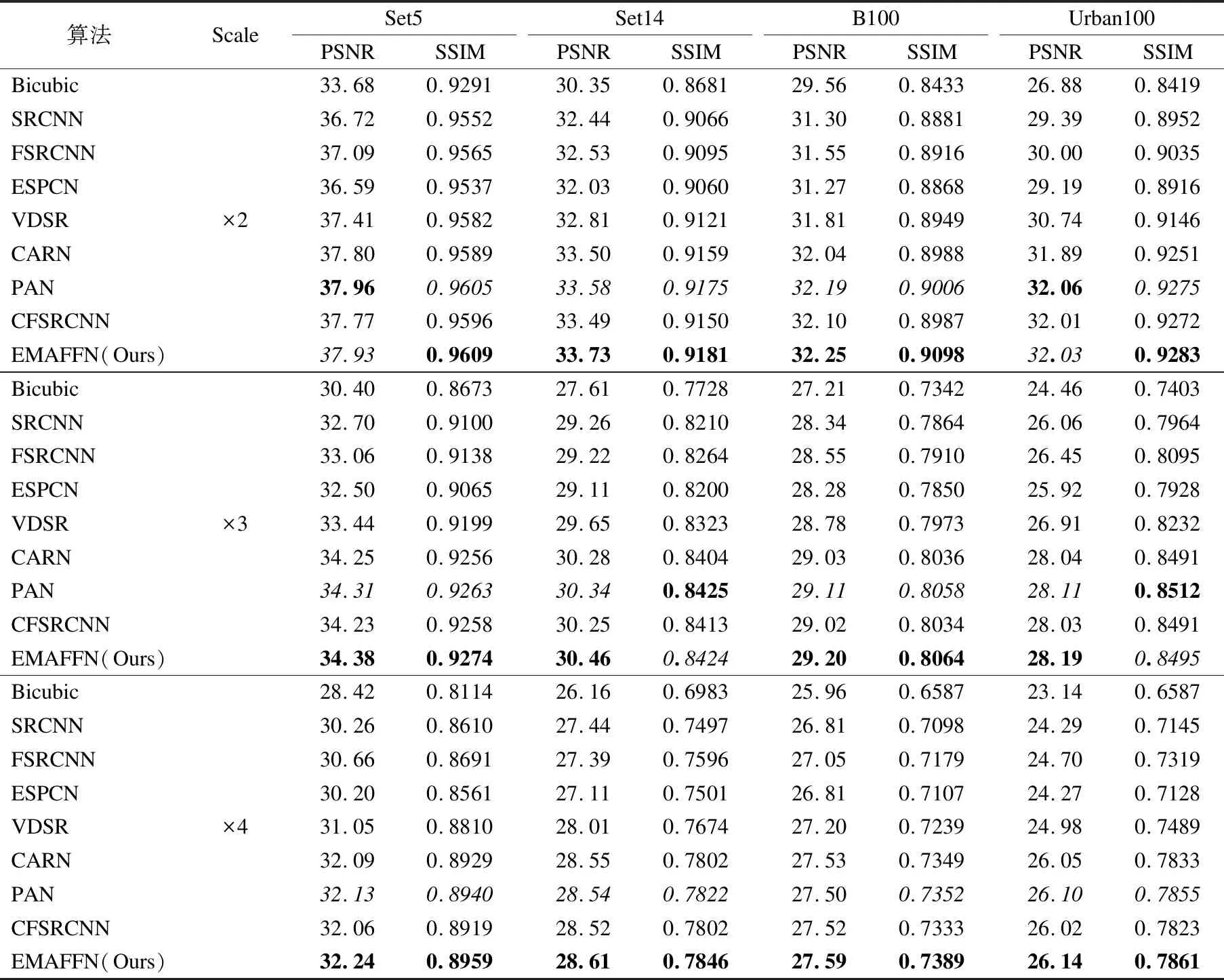
表3 不同算法在测试集上的PSNR和SSIM值Table 3 PSNR and SSIM values for different algorithms on the test set
3.3 对比实验
实验针对低分辨率图像的2,3,4倍进行超分辨率重建,将EMAFFN在公开数据集上与传统的Bicubic算法和以下几个超分辨率重建网络SRCNN[5],FSRCNN[6],ESPCN[7],VDSR[8],CARN[10],PAN[11],CFSRCNN[12]进行对比,并从定性和定量两个方面对结果进行分析.
3.3.1 客观定量分析
表3列出了EMAFFN与其它算法在4个基准数据集上放大2,3,4倍测试的PSNR和SSIM值,其中加粗的数字为当前表格中的最优值,斜体数字表示次优值.除了在部分数据集上PAN模型的PSNR和SSIM值略高于EMAFFN以外,与其它网络比较EMAFFN均取得最优值.其中,EMAFFN的PSNR平均值最高达到37.93dB,SSIM最优达到0.9609.实验表明,EMAFFN优于当前主流的CNN超分辨率重建算法,重建效果优势较明显.
3.3.2 主观视觉效果
为了更加直观地感受EMAFFN的重建效果,选用数据集B100和Urban100中的图像,展示出不同算法在放大因子为×2、×3、×4时的重建视觉效果对比,将图像中纹理细节丰富的区域用矩形框标记并放大,如图5、图6和图7所示.能够观察到,3幅图中的SRCNN和FSRCNN的重建图像较模糊,视觉效果不佳;相对来说,VDSR和CARN的视觉效果很大程度上优于SRCNN和FSRCNN,尤其在低放大系数下效果较好,如图5所示.但在放大因子为3和4的时候同样出现边缘模糊,局部细节失真较为严重;PAN和CFSRCNN重建后的图像视觉效果良好,但对比来说,EMAFFN在更大程度上恢复出图像的边缘轮廓和纹理细节,比如图6中3倍放大系数下EMAFFN重建出最为清晰的桥面纹理,图7中4倍放大系数下,EMAFFN几乎准确的恢复出条纹形状,对比其他算法来说重建后的边缘轮廓最为清晰.

图5 放大因子×2时不同模型的视觉效果图Fig.5 Visual effects of different algorithms with scale factor×2

图6 放大因子×3时不同模型的视觉效果图Fig.6 Visual effects of different algorithms with scale factor×3

图7 放大因子×4时不同模型的视觉效果图Fig.7 Visual effects of different algorithms with scale factor×4
因此,EMAFFN算法的重建效果的优势较为明显,重建后的图像恢复了较多的高频信息,更接近于原始图像.
4 总 结
本文提出的高效多注意力特征融合网络能够充分利用图像特征、降低参数量,它的渐进式特征融合块的连接方式能够缓解特征在传递过程中丢失的问题,同时其内部的高效轻量化的注意力块能从空间和通道维度加强网络对重要特征的判别能力,帮助恢复重建后图像的更多高频信息.在重建模块通过RFB_x进行多尺度特征融合能够有效保留深层次特征,将LR图像的双三次上采样结果与亚像素卷积层上采样结果进行叠加有助于提高重建图像的质量.实验结果表明,EMAFFN在Set5数据集上的平均PSNR值最高达到37.93dB,SSIM达到了0.9609,重建后的图像恢复了更多的高频信息,纹理细节丰富,更接近于原始图像.
