融合CBAM的YOLOv4轻量化检测方法
2023-05-12任丰仪裴信彪
任丰仪,裴信彪,乔 正,白 越
1(中国科学院 长春光学精密机械与物理研究所,长春 130033) 2(中国科学院大学,北京 100039)
1 引 言
伴随着无人驾驶飞机的广泛普及,促进了城市管理[1],军事侦察、灾害救援,土地变化监控[2]和交通监控[3]等多种应用.过去10年见证了无人机视觉技术的巨大进步,尤其是基于深度学习的目标检测算法,应用于无人机视觉领域会极大提高无人机的场景理解能力,对于无人机获取的航拍图像进行实时目标检测逐渐成为研究热点.
目标检测模型通常由3个部分组成:主干网络,颈部网络和头部网络.主干网络功能是进行初步特征提取,对于在GPU平台上运行的检测模型,可以选用复杂度高的网络,如VGG,CSPDarknet53[4],DenseNet,ResNet或ResNeXt.对于在CPU平台上运行的检测模型,要选择紧凑网络,如SqueezeNet[5],MobileNet[6-8]或ShuffleNet[9].颈部网络的作用是加强特征提取,具体包括FPN,PANet,Bi-FPN等模块.头部网络利用得到的特征进行预测,主要分为两类,一类是基于区域预测的Two stage算法,另一类是基于回归问题的One stage算法,Two stage算法先生成候选框,再利用CNN进行特征提取与分类,其主要代表为R-CNN[10]系列,包括Fast R-CNN[11],Faster R-CNN[12],R-FCN[13]和Mask R-CNN[14].One stage算法不再采用候选框,而是直接对目标物体边界框及类别进行回归,代表算法为YOLO[15],SSD[16]和RetinaNet[17].总体上,前者相对精度更高,后者检测速度更快.
近些年来,很多研究关注于在目标检测算法中添加功能模块,从而在增加少量推理成本的同时,提高目标精度.增强感受野的常见模块是SPP[18]、ASPP[19]和RFB[20];物体检测中经常使用的注意力模块有SE[21]、ECA[22]和CBAM[23];用于筛选模型预测结果的常见后处理方法是NMS[24],但原始的NMS没有考虑上下文信息,因此2017年提出了更加优化的Soft-NMS[25]策略.
到目前为止,在无人机获取的图像上进行实时目标检测面临着挑战和困难,首要就是深度神经网络存在复杂性和存储量高的问题.本文针对这个问题,所做的工作主要分为3个方面:
1)以YOLOv4模型为基础,使用MobileNet模型替换YOLOv4本身的主干网络CSPDarknet53,并利用MobileNet提出的深度可分离卷积思想,将原网络中PANet与Head模块的3×3标准卷积块替换为深度可分离卷积块.
2)在MobileNet-YOLOv4基础上进行模型优化,加入CBAM注意力网络,并在算法后处理部分引入Soft-NMS模块替代网络原先的NMS模块.在不影响模型运行速度的前提下,提高模型的检测精度.
3)将本文模型进行训练后部署到无人机装载的Nvidia Jetson TX2和Raspberry Pi低功耗嵌入式平台,通过飞行试验实时定位和识别无人机航拍图像中的车辆和行人.
2 改进的轻量化YOLOv4模型
2.1 YOLOv4基本模型
如图1所示,YOLOv4整体结构可以拆分成3部分:
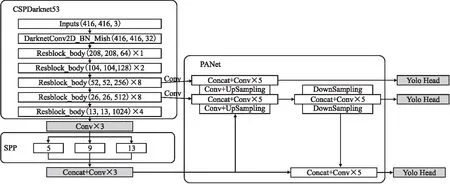
图1 YOLOv4的整体结构Fig.1 Overall structure of YOLOv4
1)主干网络:主干特征提取网络选用CSPDarknet53,进行初步特征提取.可以获得3个初步的有效特征层,分别位于主干网络的中间层、中下层、底层,3个特征层的大小分别为(52,52,256)、(26,26,512)、(13,13,1024),使用3个尺度的特征层进行分类与回归预测.
2)颈部网络:为了加强特征提取,从特征获取预测结果的过程可以分为两个部分,首先构建SPP模块、FPN+PAN特征金字塔结构进行加强特征提取;接下来利用YOLO Head对3个有效特征层进行预测.YOLO Head本质上是一次3×3卷积加上一次1×1卷积,作用分别是特征整合和调整通道数,可以对3个初步的有效特征层进行特征融合.
3)预测:第3部分为预测网络,利用更有效的特征层获得预测结果.
2.2 MobileNet基本模型
2017年Google提出了MobileNet v1网络结构,它使用了深度可分离卷积以及缩放因子,主要特点是模型小、计算速度快.MobileNet卷积神经网络极低的参数量和运算量的优点使其更适合部署在运算量低的嵌入式设备上,可以更好的平衡检测模型的准确度和运行的效率.
MobileNet v1是一种流水型网络结构,它的主要特点分为两方面:1)使用深度可分离卷积替代了传统的卷积操作,构建轻量级神经网络.如图2所示,深度级可分离卷积可以分解为两个更小的操作:深度卷积和逐点卷积.深度卷积将卷积核拆分成单通道形式,对每一通道进行卷积操作,得到与输入特征图通道数一致的输出特征图;逐点卷积就是1×1卷积,主要作用就是对特征图进行升维和降维;2)引入宽度α和分辨率ρ缩放因子.α对网络输入和输出通道数进行缩减,ρ用于控制输入和内部层表示,即控制输入的分辨率,都可以进一步缩小模型.
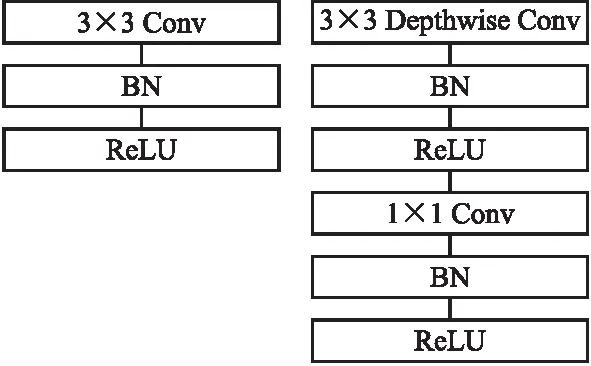
图2 左图:标准卷积,右图:深度可分离卷积Fig.2 Left standard convolution rightdepth separable convolution
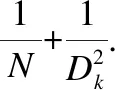
除此之外,加入了更多的ReLU6激活函数,增加了模型的非线性变化,从而提高泛化能力.ReLU6函数与其导函数如下:
relu6(x)=min(max(x,0),6∈[0,6]
(1)
(2)

表1 深度可分离卷积与标准卷积的对比Table 1 Comparison of factorized convolutions and standard convolution
本文将MobileNet作为YOLOv4的主干特征提取网络,利用MobileNet模型强大特征提取能力、极低参数量和运算量的优势,可以提高模型的运算效率,并且将YOLOv4中的部分3×3标准卷积替换为深度可分离卷积,在降低模型计算量的同时提高性能.
2.3 MobileNet-YOLOv4优化模型
近年来,有很多研究尝试将注意力机制引入到卷积神经网络中,以提高其在大规模分类任务中的性能.CBAM是一种能对特征图像局部信息聚焦的模块.它通过学习的方式在空间和通道上对特征图像进行权重分配,促使计算资源更倾向于重点关注的目标区域,从而加强感兴趣的信息,同时抑制无用信息.CBAM 包含两个模块,输入特征依次通过通道注意力模块、空间注意力模块的筛选,最后获得经过了重标定的特征,即强调重要特征,压缩不重要特征.模块划分如图3所示.
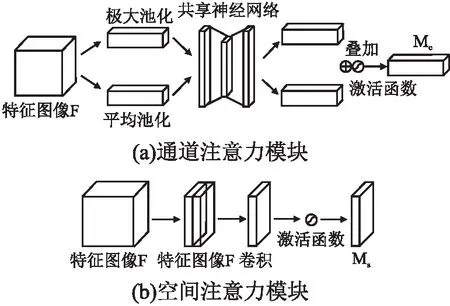
图3 CBAM模块划分Fig.3 CBAM module division
将 CBAM、SE注意力机制通过Grad-CAM[26]方法进行可视化,并与MobileNet网络的可视化结果进行比较,结果如图4所示.可以看出MobileNet与CBAM方法同时存在时,Grad-CAM掩码很好地覆盖了目标对象的区域,与SE算法相比,有效预测区域范围更大,结果也更加准确.使用CBAM注意力机制可以很好地学习利用目标区域中的信息并从中聚合特征.

图4 Grad-CAM可视化结果Fig.4 Grad-CAM visualization results
目标检测算法中,非极大值抑制策略(NMS)是很重要部分,对重叠框的处理方式如式(3)所示:
(3)
其中IoU表示重叠度,NMS保留在其阈值内的检测框,它的问题在于它会将与目标框相邻的检测框的分数强制归零,导致漏检和目标定位错误,如图5所示,对于置信度不高的目标检测结果,容易出现因图像微小变化导致两个预测框置信度大小关系产生变化,使得在NMS阶段舍弃保留关系改变,最终第1 帧检测结果偏左上方,第2帧偏右下方.

图5 NMS损害预测框定位稳定性的原因Fig.5 Reason for origimal NMS reducing the stability of bounding box
本文在YOLOv4模型中引入Soft-NMS算法来代替 NMS 算法.Soft-NMS同时考虑了得分和重合程度,对于与最高得分的检测框重叠度较高的框设置一个惩罚项,避免重叠框如果包含目标却被删除造成漏检的情况,同时不保留同一个目标两个相似的检测框.处理方式如式(4)所示:
(4)
Soft-NMS实现过程如下:
Input:B={b1,…,bN},S={s1,…,sN},Nt
begin:
D←{}
whileB≠emptydo
m←argmaxS
M←bm
D←D∪M;B←B←M
forbiin Bdo
ifiou(M,bi)Ntthen
B←B-bi;S←S-si
endNMS
si←sif(iou(M,bi))
Soft-NMS
end
end
returnD,S
end
提出的模型以MobileNet-YOLOv4为特征提取网络,并且将PANet和YOLOHead中的标准卷积替换为深度可分离卷积,进一步地减少计算量.此外,在模型3个不同尺度的预测部分加入CBAM注意力机制,从而能够增强空间维度和通道维度的有效特征,抑制无效信息的流动,并且将非极大抑制阶段的NMS 替换为Soft-NMS.模型整体框架如图6所示.
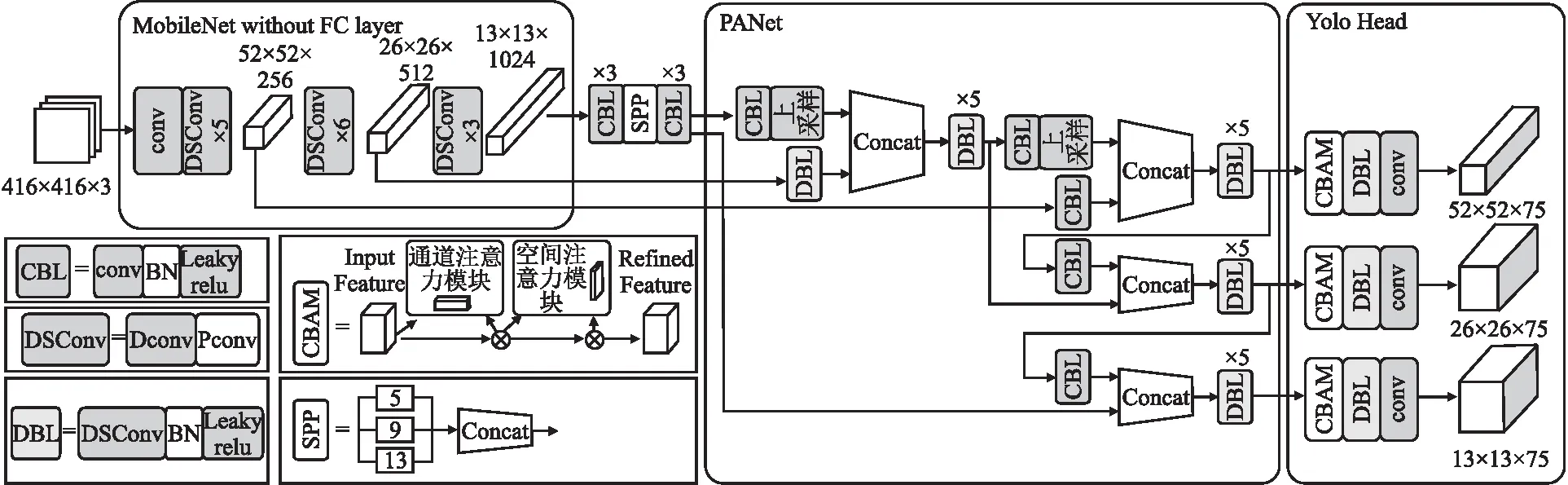
图6 轻量级网络模型总体结构Fig.6 Overall structure of lightweight network model
3 实 验
为了训练和评估所提出的轻量级模型,实验使用深度学习框架Pytorch,CPU选用Core i9-10900K,GPU选用Nvidia Geforce GTX 3080.此外,为了验证模型在无人机飞行时的适用性,在嵌入式系统Nvidia Jetson TX2和Raspberry Pi 4B上也进行了模型部署和实验结果的分析.
3.1 实验训练数据集
一般模型在进行训练和性能评估时,有很多数据集可以选择,其中最常用的是ImageNet数据集[27]、MS COCO数据集[28]和PASCAL VOC数据集[29].本次实验选用包含20个类别的PASCAL VOC作为模型训练和测试的数据集,划分验证子集和训练子集的比例为1:9.为了降低各方面额外因素对识别的影响,对原始数据集进行数据增强.对构建好的模型进行训练微调时,设置momentum=0.9,lr=0.001,batch_size=16,Init_Epoch=0,Freeze_Epoch=50,去除掉了优化器的权重衰减因子,即weight decay=0.
3.2 实验过程与结果分析
通道剪枝和紧凑型网络设计,是轻量化网络的常见方法.
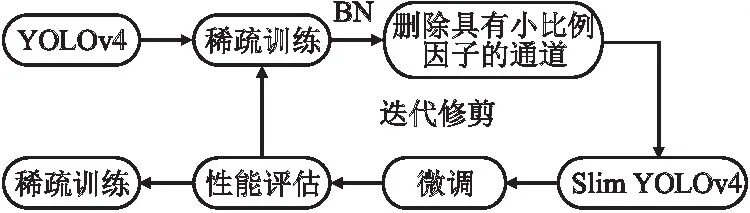
图7 YOLOv4通道剪枝流程图Fig.7 Flow chart of YOLOv4 channel pruning
为了完成对比实验,本文首先按照如图7所示的步骤在 YOLOv4 中应用通道修剪以获取Slim YOLOv4.Network slimming[30]基本原理是对各个通道加入缩放因子,将其与通道的输出相乘,通过训练进行网络权重和缩放因子的更新迭代,将小缩放因子对应的通道进行删减,然后进行网络微调,实现模型压缩.紧凑型网络实验是将MobileNet系列的3个网络分别替换原始YOLOv4本身的主干网络CSPDarkNet53,实验结果如表2所示.可以看出利用MobileNet模型强大特征提取能力、极低参数量和运算量的优势,模型可以在小幅减少精度前提下,极大提高运算效率,比通道剪枝的效果更优,并且MobileNetv1作为主干网络时效果最佳.

表2 YOLOv4网络轻量化前后对比Table 2 YOLOv4 network lightweight before and after comparison
接下来对MobileNet-YOLOv4模型进行优化.首先将模型PANet和YOLO Head部分中的3×3标准卷积替换为深度可分离卷积块,再将CBAM卷积注意力机制嵌入MobileNet-YOLOv4模型,并在模型后处理阶段引入 Soft-NMS 算法来提高网络性能,NMS和Soft-NMS策略时间消耗的差距几乎为零,但是后者检测精度有小幅度的提升.在各个阶段的优化之后,最终表现如表3所示.将本文算法与MobileNet-YOLO4算法对比发现,改进后的算法时间消耗差距只增加了0.0007s,速度FPS减少了4.57,但是mAP增长了2.58%,记录每个实验的20个目标类的检测平均精度AP如图8所示.将本文算法的与原始YOLO4算法对比发现,本文模型参数量只有原模型的1/4,速度FPS提升了26,精度mAP只下降了0.52%.
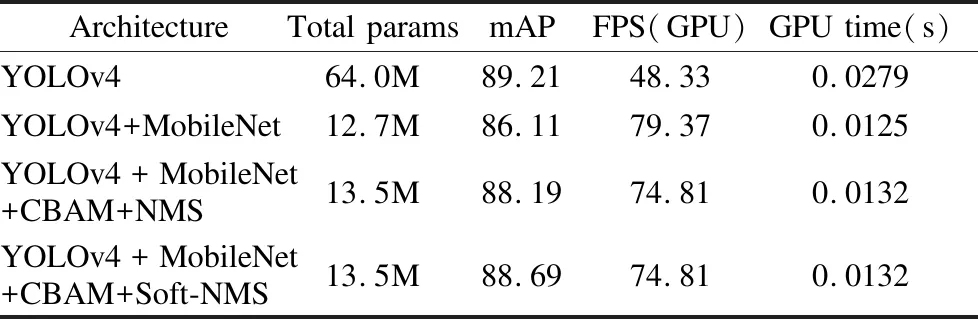
表3 本文算法优化过程中各个阶段的模型对比Table 3 Comparison of models in each stage of the algorithm optimization process in this paper
可见本文基于CBAM机制的MobileNet-YOLOv4实时目标检测算法利用MobileNet网络中的深度可分离卷积网络层的技术,在检测精度达到主流水平的同时,检测速度有了进一步的提升,同时参数量也大大减小,这有利于部署在计算能力和内存等资源有限的嵌入式设备上.利用VOC 2007和VOC 2012的训练集进行联合训练,然后基于PASCAL VOC2007测试集进行评估,图8(a)展示了和该训练网络对20个目标类的检测平均精度AP值和总的mAP.
为了进一步验证改进模型的性能,引入误检率MR,并将本文算法与MobileNet-YOLOv4算法进行误检率比较,如图8(b)所示,由图可知,本文算法明显优化了MobileNet-YOLOv4,降低了大部分类别的误检率,提高了目标检测的平均检测精度.
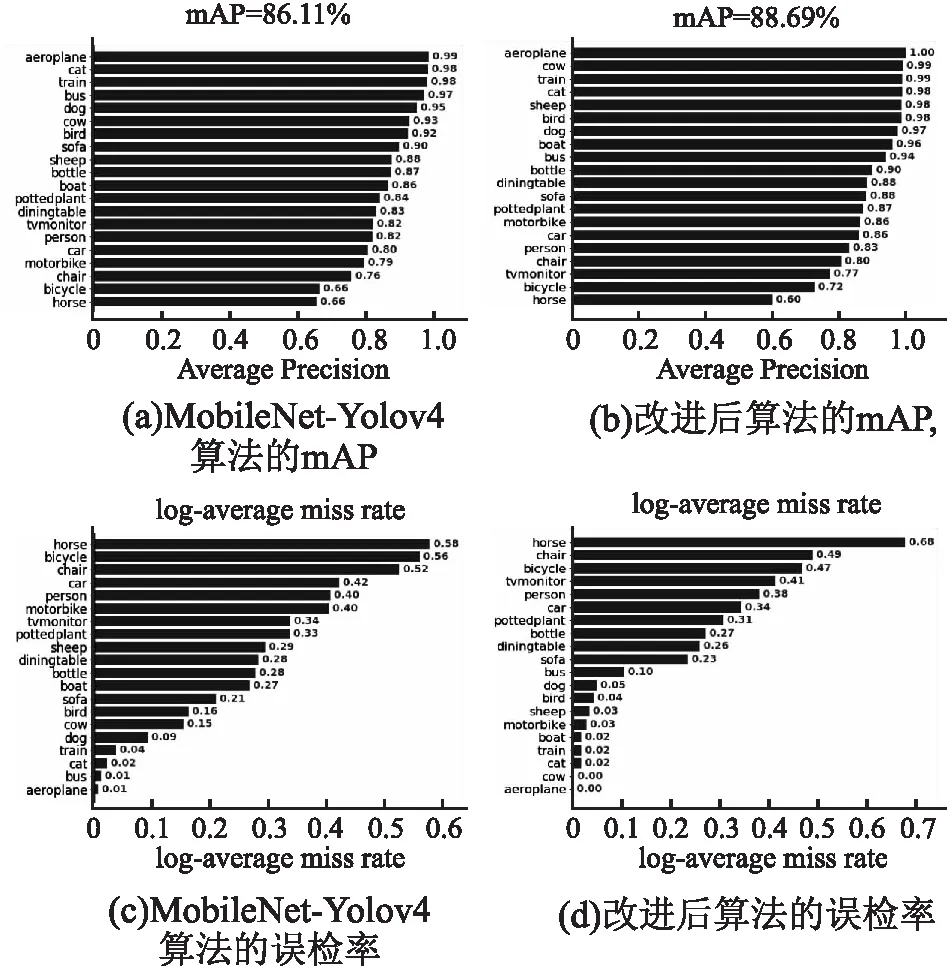
图8 mAP比较和误检率比较Fig.8 mAP comparison and error detection rate comparison
为了更直观的体现改进的目标检测算法的性能,如图9所示,列举了本文设计的轻量化YOLOv4模型在航拍图片和视频上的运行结果.每行分别表示不同的航拍条件,从左到右依次是:正常路面情况、拍摄光照不足、画面有遮挡、相机视角倾斜、拍摄停下的车辆、拍摄实时视频.每列分别表示不同的检测算法,从上到下依次是:拍摄的原始图像、原始的YOLOv4模型、本文提出的优化后的MobileNet-YOLOv4模型.从图中可以看出,本文提出的模型能够有效地对图像、实时视频中所包含不同车辆的大小位置进行检测.相比于原算法来讲,检测结果并没有很大差别,但是实时性更佳.最后,将本文模型与近3年来目标检测模型在同一编程环境以及相同数据集上进行训练,结果对比如表4所示.

图9 在不同拍摄条件下,不同算法得到的检测和分割结果Fig.9 Detection and segmentation results obtained by different algorithms under different shooting conditions
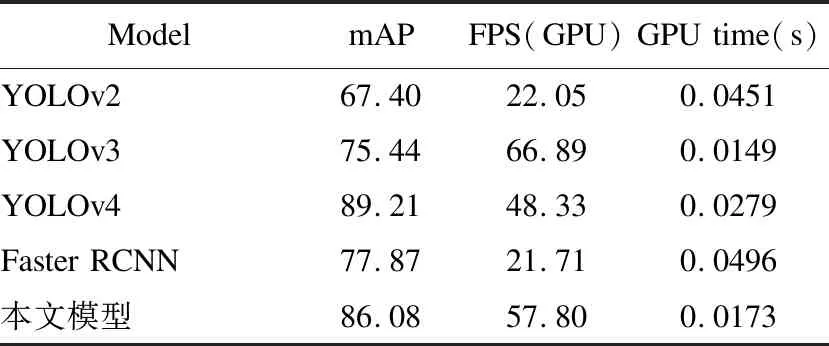
表4 本文模型与近年来目标检测模型的对比Table 4 Comparison between the model in this paper and the target detection model in recent years
3.3 基于无人机的飞行试验
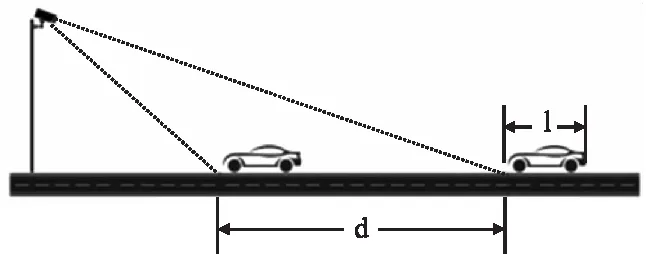
图10 估计所需的最低帧处理速率Fig.10 Minimum required frame processing rate
实验使用四旋翼无人机,无人机飞控为Pixhawk,平台搭载ZED双目立体相机,获取丰富的环境信息,提高无人机的智能感知和场景理解能力.在无人机平台上,图像处理模块要使用体积较小且算力足够嵌入式平台,常用的是Nvidia Jetson TX2和Raspberry Pi 4B.

表5 NVIDIA Jetson TX2的系统规格和软件Table 5 NVIDIA Jetson TX2 system specs and software

表6 Raspberry Pi 4B的系统规格和软件Table 6 Raspberry Pi 4B system specs and software

表7 使用 Nvidia Jetson TX2和Raspberry Pi的FPSTable 7 FPS using Nvidia Jetson TX2
表5和表6展示了这两种嵌入式系统的规格.将轻量级模型分别部署到两个嵌入式系统中,对无人机航拍图像进行检测处理,所得到的检测结果如图11所示,检测速度如表7所示,飞行试验显示TX2上的FPS达到了21.8,相比于YOLOv4提高了3.74倍.并且在Raspberry Pi上,FPS也达到了8.5,故将本文算法部署到无人机装载的嵌入式平台上,能够对航拍视野中的车辆目标进行实时识别和定位.

图11 对无人机采集的视频进行实时目标检测的结果Fig.11 Target detection and insance segmentation on images collected by drones
4 总结与展望
本文提出的基于CBAM机制的MobileNet-YOLOv4实时目标检测方法,首先将MobileNet替换为YOLOv4的主干网络,并且利用MobileNet中的深度可分离卷积技术,将YOLOv4中的部分标准卷积替换为深度可分离卷积.接下来优化MobileNet- YOLOv4模型,通过嵌入卷积注意力机制CBAM提高了卷积神经网络输出特征图的全局特征;其次通过引入 Soft-NMS 有效地降低了因为传统非极大抑制NMS算法导致的密集物体的相邻框漏检问题.最终在PASCAL VOC数据集上的测试结果,表明算法在保证检测精度的前提下,有效地降低了参数量和复杂度,检测速度有了大幅度的提升.这有利于将算法部署到计算能力和内存等资源有限的无人嵌入式平台上,使得无人机能够对视野中的目标进行实时识别,提高无人机的场景理解能力,广泛应用于无人机检测和跟踪车辆、捕获违规行为的智能交通领域以及灾害救援、土地变化监控等应用.
