融入无监督度量学习的稀疏子空间聚类模型
2023-05-12江雨燕
江雨燕,邵 金,李 平
1(安徽工业大学 管理科学与工程学院,安徽 马鞍山 243032) 2(南京邮电大学 计算机学院,南京 210023)
1 引 言
子空间聚类是目前实现高维数据聚类的有效方法之一,涉及到运动分割[1]、图像识别[2]等各方面应用,如在一个视频序列中可能会包含多个运动对象,通过多个子空间将描述不同对象的运动过程.近年来,已有许多子空间聚类算法被提出,现有方法包括:代数方法[3]、迭代方法[4]、统计方法[5]、谱聚类方法[6,7].子空间聚类的主要思想是将高维数据通过多个低维子空间表达,在子空间的并集中选择一组数据对其进行分割、聚类.但是,类别划分并不明确的特征空间对聚类任务无太大帮助,甚至是负作用[8],这凸显了数据预处理的重要性.
基于低秩表示的子空间聚类[9-11]揭示了数据的相关结构,寻找每个数据的低秩表示,通过低秩表示恢复子空间结构,但缺点是当获得数据不足或数据损坏时性能会明显降低.稀疏子空间聚类(Sparse Subspace Clustering,SSC)[12]一定程度上保证存在损坏数据时正常进行子空间恢复,但缺乏对数据全局结构的描述,仅考虑每个数据的稀疏表示.文献[13]将对抗性或随机噪声添加到无标签的数据中,学习到噪声字典后正确识别底层子空间.文献[14,15]针对数据缺失问题优化模型,通过计算稀疏系数矩阵恢复数据的缺失项.这些方法的优点是有效解决缺失项的稀疏表示问题,但当数据维度很高时寻找稀疏表示或低秩表示的计算是非常困难的.这些文献研究重点在低秩或稀疏约束下考虑子空间聚类的数据缺失、噪声等问题.然而,缺点是大多采用主成分分析(Principal Component Analysis,PCA)[16]、局部线性嵌入(Local Linear Embedding,LLE)[17]等方法作为一个单独的聚类前的预处理步骤,这些经典的无监督方法对数据采集质量要求低,无需数据的标签,能够降低数据维度.但是,这些方法仅能寻找数据之间的相似关系,不能对数据聚类起到关键作用.因此,数据预处理方法也是影响聚类性能的关键因素.
对输入样本的预处理,现有的子空间聚类模型往往使用优秀的特征选择方法[18]选择感兴趣的特征作为输入特征,并大多使用欧氏距离来度量样本之间的相似性,不完全适用于子空间分割过程.目前在度量学习方面,相关研究主要侧重于有监督的度量学习,但此类度量学习方法通常无法直接应用于无监督(未观测到样本的类别信息的)子空间聚类任务中.文献[19]提出面向聚类的自适应度量学习,对输入数据同时进行降维和聚类,使数据可分性最大化,可以有效对高维数据进行聚类.文献[20]将近邻成分分析扩展到无监督场景,对无标签数据点同时进行聚类和距离度量学习.基于上述分析,可以使用度量学习方法将数据间的相似性最大化,同时为了能够提升子空间聚类模型的性能,必须对样本间的距离度量进行详细的设计与验证.
因此,本文提出了一种融入无监督度量学习的稀疏子空间聚类模型(Unsupervised Metric Learning for Sparse Subspace Clustering,UML-SSC).将度量学习与子空间聚类集成在一个统一优化框架中,而不再是聚类前的一个单独的步骤,数据结构的先验可以通过对类别指标的正则化嵌入到子空间聚类模型中.实验结果表明,模型通过针对化的预处理得以提升子空间聚类能力.
本文的主要贡献如下:
1)将无监督度量学习引入作为数据预处理过程,生成伪类标签指导后续子空间聚类工作,提升原始数据的可分性.
2)重构了稀疏子空间聚类模型,将度量学习融入到子空间聚类中,对于数据的预处理不再是一个单独的步骤.
3)为解决所提出优化模型,更新了迭代优化过程.
2 相关工作
2.1 度量学习
假设输入X=[x1,x2,…,xN]∈D×N,其中N为输入数据的数目,D为输入数据的维度,大多度量学习方法使用马氏距离进行度量,一般来说,马氏距离的度量表现优于欧氏距离的度量.
(1)
(2)
其中,d(xi,xj)是表示两点之间的马氏距离,为了确保满足非负性和三角不等式的度量,其中M必须是半正定的[21]且M=ATA,M≥0.因为本文主要研究的是正交变换,即ATA=Il,其中Il是大小为l的单位矩阵.对线性变换后的数据进行欧氏距离的计算等于在输入空间进行马氏距离的计算,这表明了度量学习和数据投影问题被视为一个统一的概念[22,23].
2.2 稀疏子空间聚类

(3)
其中,Z的第i列对应的是X的第i个稀疏解,diag(Z)=0是为了避免数据点对自身用线性组合表示的平凡解,上式的解Z是块对角结构,块的个数代表子空间的个数,块的大小代表子空间的维度.令W=|Z|+|Z|T,其中W为数据的相似度矩阵,最终使用谱聚类中Ncut或Ratio Cut方法得到聚类结果[24].
3 算法及提出的模型
3.1 无监督度量学习
令A∈D×l作为初始投影矩阵,通过矩阵A对输入数据进行线性变换,即yi=ATxi,从D维空间中转换到l维空间中.在无监督模型中,由于没有任何标签信息指导我们模型的学习过程,使用K-means方法初始化K个聚类中心[25],给予输入点伪标签,然后通过最小化目标函数J对输入数据点进行进一步优化A.
(4)
其中C=[c1,c2,…,cK]指的是在新投影空间中的K类的中心,yi=ATxi,A∈D×l是投影矩阵.这里引入表示数据点标签的聚类指示矩阵H,H=[H1,H2,…,HK],令hij为聚类指示向量,如式(5)所示:
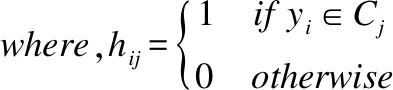
(5)
再定义一个加权聚类指示矩阵F,F=[F1,F2,…,FK],如下[26]:
(6)
其中,Fi表示F的第i列,Ni表示F中第i列的值.当yi对应的项是非零项时,则表示yi是属于该伪标签中的数据点,对目标函数J最小化问题则可以转化为式(7):
(7)
然而,由于该优化问题是非线性并且很难求解的,使用交替最小化方法(Alternating Minimization,AM)计算.
1)固定F,优化A:当F是已知的情况下,通过拉格朗日乘子法解决式(7)中的优化问题,对于F中的每一列,优化问题可以转化为广义特征值问题.
PA=ηA
(8)
其中η为拉格朗日乘子(在这里也是特征值),且P=XXT-FTXTXF,根据特征值计算出A,从而更新A.
2)固定A,优化F:C是在新投影空间中对数据点进行K-Means算法计算后的伪类别中心,加权指示向量F与数据点的伪类别中心C直接相关,根据固定的A,直接计算出F.
3.2 提出的模型
首先采用无监督度量学习对原始数据进行预处理,给予数据伪类标签以指导后续工作,再将谱聚类损失、度量损失加入到模型中,我们的目标函数如式(9)所示:
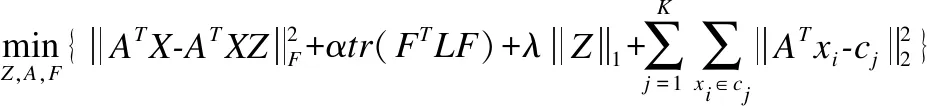
(9)
其中,X为N个输入数据点,X=[X1,X2,…,XN].A为投影矩阵,M=ATA.F∈N×K为加权聚类指示矩阵,F=[F1,F2,…,FK],其中K是对数据点进行分类的类别数量,L为拉普拉斯矩阵,L=R-W,R为对角矩阵,Rii=∑Wij,W为相似度矩阵,W=|Z|T+|Z|.
目标函数的第1项在投影空间的自表示模型的损失,第2项是谱聚类的非负正交约束,第3项是稀疏表示的约束,第4项是投影空间上的度量损失.α是非负权衡的参数,λ是平衡稀疏解的参数.约束项ATA=I是为了得到防止得到平凡解;约束项diag(Z)=0要求数据不能使用线性组合表示自身;约束项ZT1=1要求数据分布在仿射子空间上;约束FTF=I是必须对F进行非负正交的约束.因此,式(9)可以重写为式(10):
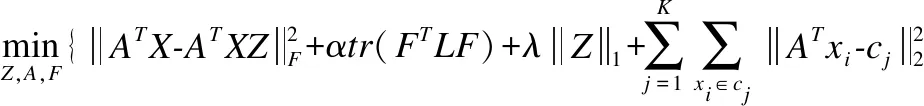
(10)
UML-SSC模型的核心思想是在保证局部数据几何结构不变的前提下先将数据在低维流形空间中通过度量学习将数据可分性最大化;然后将预处理后的数据在稀疏约束下进行自表达并执行子空间选择过程,通过改进模型使预处理不再是单独的步骤,然后迭代地更新稀疏表示矩阵Z,加权伪类标签矩阵F,投影矩阵A,随着迭代次数增加,获得的结果会更加精确.
3.3 优化与算法
1)固定A、F,更新Z
去掉不相关的项,优化目标函数可以转化为式(11):
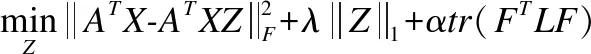
(11)
引入拉格朗日乘子η,删去上式等式约束,则有:
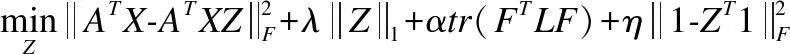
(12)
根据文献[27],将X替换为[XT,η×1]T,其中η是一个接近无穷的量,则式(12)可以更新为式(13):
(13)
同时,这里引入定理1结论重构该优化问题.
定理1.对于拉普拉斯矩阵L∈N×N,其加权类标签矩阵为F∈N×K,存在:

由于A是固定的,Y=AX根据输入数据点X而改变.根据定理1的结论,式(13)可以改写为:
(14)
上式可以使用迭代的方式求解,固定Z除了第i行以外的所有行,仅对第i行进行求解:
(15)
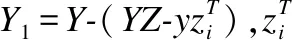
(16)
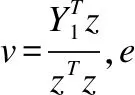
(17)
其中zk、vk、pk指的是z、v、p中第k个元素.
2)固定Z、A,更新F去掉不相关的项,优化问题可以转化为:
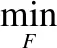
(18)
对上式中加入拉格朗日乘子Φ,同时消去上式等式、不等式约束,则转化为:
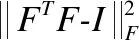
(19)


(20)
根据Karush-Kuhn-Tucker(KKT)条件[29]ΦijFij=0,计算得到下式以更新F.
(22)
3)固定Z、F,更新A去掉不相关的项,优化问题为:
(23)
求解式(23)最小化问题,对A进行求导:
(24)
由于上式没有闭合解,令求导后的梯度为Q.
Q=2(XTAX-XTAXZ-ZTXTAX+ZTXTAXZ)
+2(XTAX-FTXTAXF)+4δA(ATA-I)
(25)
根据梯度Q利用随机梯度下降法进行迭代,直至目标函数收敛.
A(t+1)=A(t)-ξQ
(26)
其中ξ为学习率,取值范围为ξ∈{10-1,…,10-4},A(t)指的是第t次迭代的值.
通过固定二者,更新另一者,交替地更新A,F,Z,直到目标函数收敛.设置最大迭代次数iter为100次,每迭代1次,都获得更有判别能力的投影矩阵A、更优的加权类标签矩阵F、更优的稀疏系数矩阵Z.根据得到的最终结果构建相似度矩阵进行谱聚类,最终得到聚类结果,算法流程见算法1.
算法1.UML-SSC
输入:数据矩阵X=[X1,X2,…,XN]∈D;超参数α,λ.学习率ξ
输出:数据X的所属类别
1.初始化投影矩阵A,FandZ
2.根据式(8)、式(9)计算出投影矩阵A,伪类别矩阵F;
3.For循环iter=1,2,….
4.固定A和F,更新Z通过式(17);
5.固定A和Z,更新F通过式(22);
6.固定F和Z,更新A通过式(26);
7.直到目标函数收敛;
8.End for
9.构建相似度矩阵W=|Z|T+|Z|;
10.使用谱聚类得到聚类结果.
4 实 验
4.1 实验设置
在本节中,为验证所提出模型的有效性,我们选取两个公开真实的标准数据集:The Extend YaleB数据集、COIL-20数据集,具体描述见表1.

表1 实验中两个数据集的描述Tabel 1 Descriptions of two datasets
1)The Extend YaleB数据集是38个人正面人脸图像,每一个人在不同光照下的64张图像.原始的每张人脸图像分辨率为192×168,根据文献[12]的实验设置,将图像降至48×42像素,为保证实验精确性,选取前m1={5,10,20,30,38}个对象进行聚类.
2)COIL-20是20个物体的1440副灰度图像构成,物体包括鸭子玩具、汽车模型等,每副图像的像素大小为32×32,拥有1024个特征.为更好地分析实验精确性,选取前m2={5,10,15,20}个对象进行聚类.
在以上数据集中将我们的算法与以下几种先进的聚类算法进行对比:局部子空间分析[30](Local Subspace Analysis,LSA),曲率谱聚类[31](Spectral Curvature Clustering,SCC),最小二乘回归[32](Least Squares Regression,LSR),低秩表示[11](Low Rank Representation,LRR),低秩子空间聚类[33](Low Rank Subspace Clustering,LRSC),SSC[12],基于正交追踪的稀疏子空间聚类[34](SSC by Orthogonal Matching Pursuit,SSC-OMP),l0稀疏子空间聚类[35](l0Sparse Su-bspace Clustering,l0-SSC).
算法中涉及到的输入参数包括α,λ,设置取值范围α∈{10-6,10-5,…,105,106},λ∈{10-6,10-5,…,105,106},令超参数δ=106,γ=106,K根据不同数据集实验目标数设置.由于实验结果对参数值非常敏感,在不同数据集中根据实验结果调整相对应合适的参数值.
4.2 时间复杂度分析
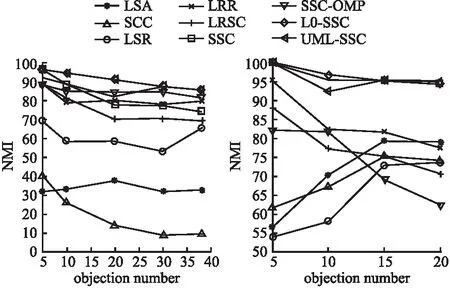
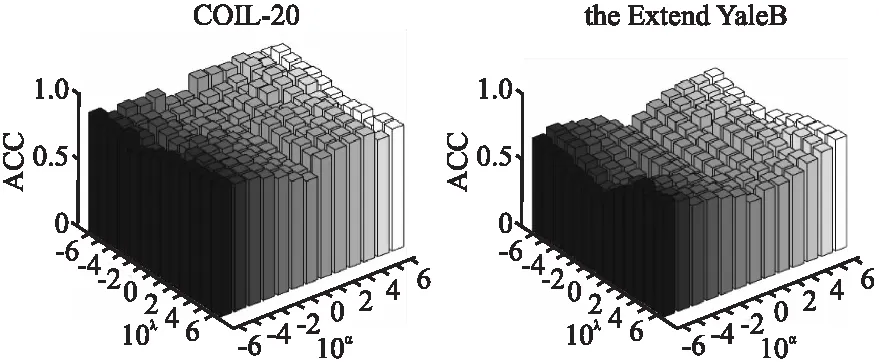
由于提出的模型更新包括3个子步骤,需要通过对每个子步骤的复杂度进行分析来计算模型的总时间复杂度,假设迭代次数为t.更新投影矩阵A,由于d 为了评估所提出模型的性能,与几类常见聚类算法进行对比,均使用作者提供的代码进行测试,并将参数设置到最优的聚类性能.实验报告了包括UML-SSC在内的9种算法在不同数据集中不同数量的对象的聚类性能,如表2~表5所示,并分别以ACC和NMI对不同算法进行评价,对比结果如图1、图2所示.由于所选取的参数不同,其ACC、NMI值会有变化,因此需要分析不同参数下不同的聚类结果,以直观地看出最佳参数选择,如图3、图4所示.实验结果均为重复20次实验的均值. 表2 9种算法在Extend YaleB数据集上的ACC值Table 2 ACC of nine algorithms on Extend YaleB 表3 9种算法在COIL-20数据集上的ACC值Table 3 ACC of nine algorithms on COIL-20 表4 9种算法在Extend YaleB数据集上的NMI值Table 4 NMI of nine algorithms on Extend YaleB 表5 9种算法在COIL-20数据集上的NMI值Table 5 NMI of nine algorithms on COIL-20 图1 不同算法在两个数据集上的ACC对比Fig.1 ACC of different algorithms on two data sets 图2 不同算法在两个数据集上的NMI对比Fig.2 NMI of different algorithms on two data sets 由于算法的聚类结果对参数很敏感,聚类性能很大程度取决于参数组合.这里将不同的参数α,λ的实验结果进行记录并展示.通过对图3的分析,我们的方法在Extend YaleB数据集中设置α=10-6,λ=106可以得到较好的聚类表现,其ACC达到82.2%.在COIL-20数据集上设置α=106,λ=106,其聚类准确率ACC达到最高值89.3%.从图4中可以看出在Extend YaleB数据集中取值α∈{10-3,10-6},λ∈{103,106}时NMI值普遍较高,在α=10-6,λ=106时NMI达到最高值85.8%.不同的数据集需要不同的参数组合才能达到最佳性能,在COIL-20数据集上设置α=106,λ=106时,NMI得到最优值95.0%. 图3 UML-SSC算法在不同数据集上不同参数的ACC值Fig 3 ACC values of different parameters of UML-SSC on different data sets 图4 UML-SSC算法在不同数据集上不同参数的NMI值Fig.4 NMI values of different parameters of UML-SSC on different data sets 本文主要研究了将度量学习融入到子空间聚类过程,重构了稀疏子空间聚类模型.为了克服子空间聚类模型精度提升受限、大多使用传统PCA方法进行预处理等问题,针对输入数据的预处理进行详细设计.本文优点如下:1.通过使用无监督度量学习的方法可以在保留局部数据结构的情况下,自适应地学习数据间的相似度将数据的可分性最大化;2.将稀疏子空间聚类与度量学习结合,提出联合框架模型同时执行子空间选择与聚类,将度量学习与子空间聚类过程融合.通过迭代求解的方式,学习到更精确的数据分布及更优的相似度矩阵,实验证明模型有效提高了子空间聚类效果,提升了泛化能力. 虽然提出的模型提升了聚类的准确率,但仍然存在改进的空间.例如,可以考虑加入深度神经网络来处理非线性高维数据,未来将进一步进行研究.4.3 实验结果






5 结束语
