基于步态与声纹特征融合的人物身份识别
2023-05-11熊经文岳文静
熊经文,陈 志,倪 康,岳文静
(南京邮电大学 计算机学院,江苏 南京 210023)
0 引言
步态与声纹作为典型的生物特征,具有非配合性等特点,广泛应用于门禁控制、法医鉴定和安保系统等领域,但其单一模态的生物特征仍存在不足,如步态识别会受到复杂背景下难以提取步态轮廓图、人物衣着覆盖人体轮廓等因素影响,造成识别率不佳;声纹识别中的环境噪声可能对说话人声纹特征造成干扰,导致系统无法准确学习说话人特征,从而产生误判。多模态的生物特征识别使用不同的生物特征,将不同层面的互补身份信息相结合,能从多层面表征人物的身份信息,相比于单一模态的识别系统能够更好地增强生物识别系统的鲁棒性与准确性。因此,采用多种模态联合进行生物身份识别是未来的研究趋势,并且在科研和实际应用领域都受到广泛关注。
国内外学者在该领域已开展了许多研究工作。文献[1]提出将说话人声纹与唇部相结合进行身份识别的方法,在特征层将两种特征进行拼接,证明了声纹与嘴唇特征的互补性,取得了不错的效果;文献[2]将视频中的人脸与语音模态融合以进行维度情感识别,该方法使用注意力机制融合人脸与语音特征,为解决数据集中语音干扰较大的问题,将人脸特征与融合后的特征相加,增加人脸的权重,针对特定场景提升了模型的鲁棒性;文献[3]提出一种将虹膜与眼周特征融合的方法,通过共同注意力机制进行特征融合,取得了较好效果。目前的研究主要集中于人脸与语音、模态等方面,而基于步态与声纹融合的研究较少。
针对上述情况,本文提出一种融合步态与声纹的身份识别方法,使用GaitSet 网络提取步态特征,通过提取声音的MFCC 频谱图,将MFCC 特征输入ResNet 网络,使用CBAM 注意力机制关注频谱图的有用信息,提取声音的高级语义特征,并将提取的特征通过门控注意力机制进行融合,设计与实现一个身份识别系统。
1 基于多模态融合的身份识别网络
本文所提出的步态—声纹多模态融合身份识别网络模型框架如图1 所示。该网络使用预处理的提取的步态轮廓序列和音频的MFCC 特征作为步态输入及声音输入,分别通过步态、声音模型提取各自的高级特征,之后进行特征融合。
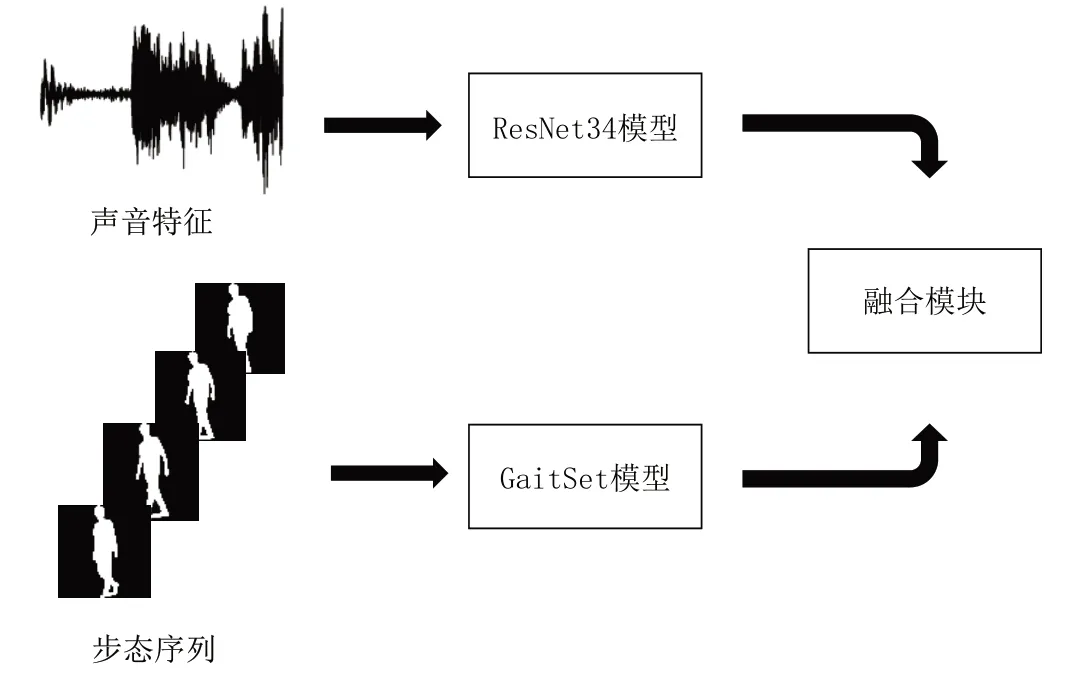
Fig.1 Gait-voiceprint joint recognition network architecture图1 步态声纹联合识别网络架构
1.1 步态特征提取
本文使用步态识别中的经典网络GaitSet 提取步态特征,该网络模型在步态识别任务中取得了良好效果,能够有效提取步态轮廓序列的高级特征[4]。模型中以二值化的步态轮廓序列作为输入,使用多个共享权重的CNN 卷积提取初步特征,通过集合池化的思想将帧级特征聚合成独立序列级特征,很好地保留了空间和时间信息。经过验证,当Gaitset 网络输入30 张步态序列图片时,模型的准确率达到相对稳定,继续增加步态序列数量,准确率提升不多,但计算量相对增加。因此,本文从一段视频中抽取30帧作为模型的输入,进而提取步态特征。
1.2 声纹特征提取
在声纹识别领域已进行了许多研究,如基于传统方法的GMM-UBM[5],该方法采用高阶高斯模型对说话人进行建模,适合于文本无关说话人识别;i-vector 方法描述说话人信息时,将语音映射到一个固定的低维向量,该方法有效降低了参数量,在与文本无关的声纹识别中有较好表现[6];x-vector 利用时延神经网络提取帧级特征,使用统计池化将帧级特征聚合为段级特征,在短语音情形下有着更强的鲁棒性[7]。
本文采用基于ResNet34 的网络进行声音特征提取[8],ResNet 网络在各种任务中都取得了较好效果,模型中使用残差连接增强模型训练的鲁棒性,可有效解决梯度爆炸问题。本文网络中使用自注意池化层[9]将帧级特征聚合为语句级特征,并在每个网络块的末端加入CBAM[10]注意力机制。通过结合通道注意力与空间注意力机制,CBAM 能增强声音频谱图像的特征表达,关注其中的重要特征并抑制非重要特征。网络模型具体参数如表1所示。
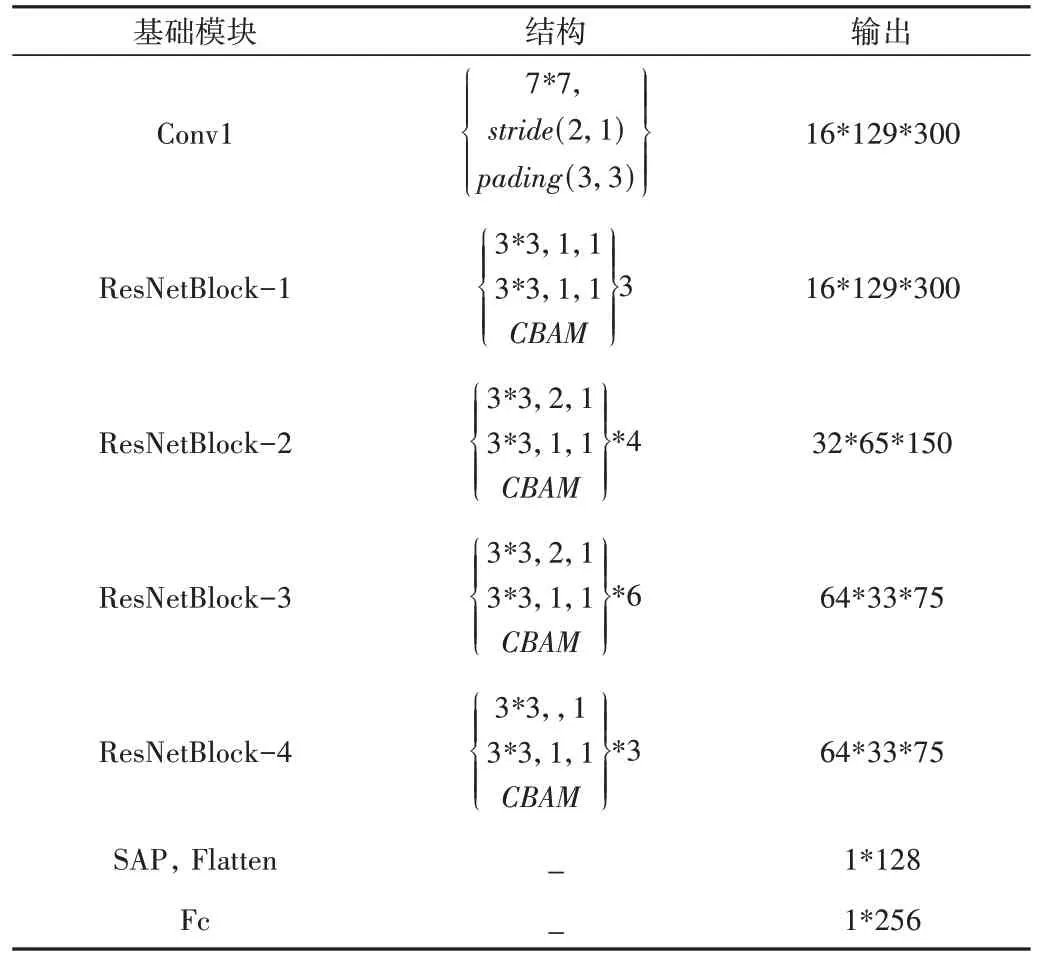
Table 1 Voiceprint model parameters表1 声纹模型参数
1.3 融合模块
生物特征具有多样性,不同的生物特征相对于其他生物特征都具有独特优势,同时也有其不足,没有一种生物特征能同时满足所有需求,因此多特征识别则显得尤为重要。在众多生物特征中,人物的步态信息和声纹信息相较于其他生物特征信息更易于获取,且具有一定的非配合性,适用于非配合场景下的身份识别。但在实际的室内场景中,目标人物的步态视角可能会发生变化,或者受到遮挡等因素影响,一定程度上影响了步态识别的识别率。对于声纹识别,在目标距离较远的远场景下,其声音信息易受到噪声干扰,而其步态受干扰较小;在近场景下且有遮挡的环境中,步态信息容易缺失,却可以较好地采集声音信息,两者之间具有一定互补性。同时,人物的步态与声音信息都包含了目标对象的性别[11]、年龄[12]等信息,具有一定的相关性,所以选择将两者进行融合。
在多模态融合中,不同模态的特征所分布的语义空间相差较大,要进行特征融合,必须使不同的模态特征映射到相同的语义空间中,才能对特征进行有效融合。由于步态与声纹是两种不同的生物模态,两者差异较大,为了更有效地融合多源信息,分别将声纹特征fs通过全连接层映射到256 维空间中,将步态特征fg映射到256 维空间中[13]。具体操作如下式所示:
在语音识别等时序任务中,GRU 和LSTM 将门控机制应用于模态融合[14],该结构可根据来自不同模态的数据组合找到中间表示,每个模态的输入通过tanh 激活函数编码,得到一个模态内部的表示特征。对于每个输入的模态,通过门神经元σ 计算特征对单元整体的输出贡献度。本文使用门控注意力机制的方法[15]将输入的特征进行拼接,通过注意力层关注两个模态之间的交互。通过门神经元σ 得到不同模态的贡献度,分别将每个模态的贡献度与对应的模态特征相乘,计算出加权特征,将加权后的步态特征与声纹特征相加作为最后的融合特征。公式如下:
式中,σ 为sigmod 激活函数,用来计算融合后的注意力分数,最终的融合特征为。经过tanh 激活函数,增加非线性变化,分别乘以注意力权重z与1-z,计算得到不同模态加权和ep,即融合特征。
2 身份识别系统设计
基于多模态的步态与声纹身份识别网络设计身份识别系统,主要框架如图2 所示,分为行人检测、数据预处理、融合身份识别几个模块。
2.1 行人检测
身份识别系统使用YOLO 算法[16]检测并提取行人图像框。YOLO 算法是目标检测的经典算法,研究者们已经提出了多个版本,比较经典的有YOLOv3、YOLOv4、YOLOv4-tiny、YOLOv5 等。经过比较,综合层面YOLOv4 算法的性能最优,YOLOv5 算法模型较小,速度最快,但识别精度较低。综合考虑计算力和实时性的要求,选择使用YOLOv5 算法进行行人检测,当检测到行人时再进行声音检测。

Fig.2 Main framework of the system图2 系统主要框架
2.2 数据预处理
在实际场景中,图像帧可能出现复杂背景,受到地面反光或者光照产生倒影等因素影响,使用传统的背景减除法、帧差法虽然效率高、运行速度快,但会产生噪点。在极端情况下,步态轮廓信息会被破坏。本文选择使Mask RCNN 算法[17]进行分割,并对图像进行二值化处理,得到步态轮廓图。
对采集的声音信号进行静音检测,保留声纹音量大于阈值的声音信息。本系统仅针对单人情况下进行身份识别,即每次只识别一名人员,同时目标人员需要正常走动与说话,以确保获取步态与声纹信息。
对采集的所有音频进行预加重处理,避免声音在低频的强度大于高频,采样率为16KHz。以25ms 每帧进行分帧,为避免两帧间变化过大,在帧与帧之间加入10ms 帧移,并采用汉明窗进行加窗,然后进行傅里叶变换,得到语谱图,对每帧语谱图进行均值和归一化处理。
2.3 身份识别
身份识别模型使用上述提出的步态—声纹联合识别网络。由于实验采集的数据量有限,为防止小数据的过拟合,步态、声纹特征提取模型分别使用CASIA-B 和VoxCeleb1[18]公开数据集上的预训练模型。
3 实验与结果分析
实验代码采用的语言为Python3.8,使用深度学习框架Pytorch1.7 实现。实验环境如下:操作系统为Ubuntu20.04,硬件设备为英特尔i9-10090K 处理器,显卡为英伟达3090。实验使用反向传播与交叉熵损失函数训练模型,并采用五折交叉验证法对数据集分开进行训练测试。
3.1 实验数据集
本文使用在实际场景中自采的步态—声纹数据集,数据集中包括10 人的步态与声纹数据。其中,步态使用英特尔D435i摄像头,分为与摄像头夹角成90°与270°的两个行走方向进行采集。主要考虑人员衣着正常的情况,每位人员一共采集20 段行走视频,每段视频约120 帧,然后提取出人物轮廓图,并手动剔除人员进入与走出画面的无效帧,最后每段视频得到约90 帧。声音数据使用NX 开发板外接的麦克风采集,声音数据与步态数据在相同角度下采集,每位人员一共采集20 段音频,手动去除开始与结束的静音片段。
3.2 实验结果与分析
为了验证所提出的多模态步态和声纹身份识别网络的有效性,首先对融合特征与声纹特征以及步态特征进行比较。由于声音数据是在实际场景中进行采集的,包含风扇、空调等环境噪音,所以对音频进行降噪处理,降低噪声对识别结果的影响。处理后的单模态与融合模态在测试集上的性能如表2 所示。根据表2 的实验结果可见,声音数据经过降噪处理后,在5 个子集上都取得了较高的准确率,平均准确率可达到81.95%,高于步态识别方法。使用步态加声纹融合特征的方法,在数据集上的平均识别率可达到83.64%,并且在所有子集上都取得了比声纹、步态识别更好的实验结果。由此可见,步态与声纹融合识别方法相比两个单模态识别方法具有更好的性能。
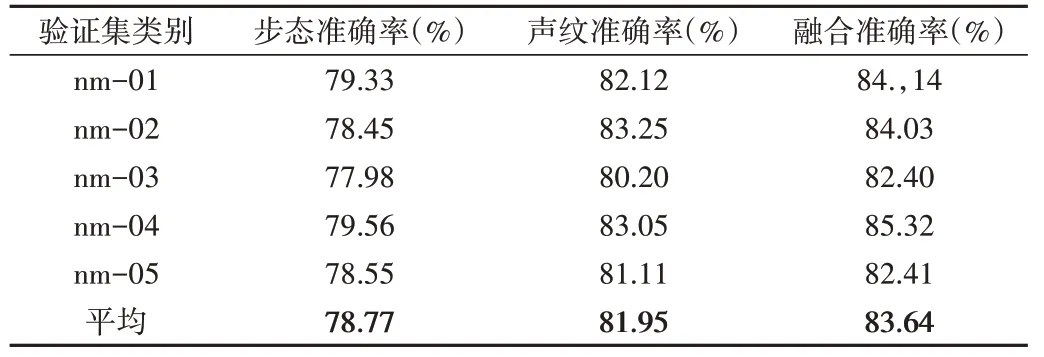
Table 2 Experimental results after data set noise reduction表2 数据集降噪后实验结果
为进一步验证融合模态系统的鲁棒性,使用步态与声音未进行降噪的原始数据进行实验,同时采用拼接的方法,将1*256 维步态特征与1*256 维声纹特征拼接成1*512维融合特征,并与本文方法进行了对比,实验结果如表3所示。
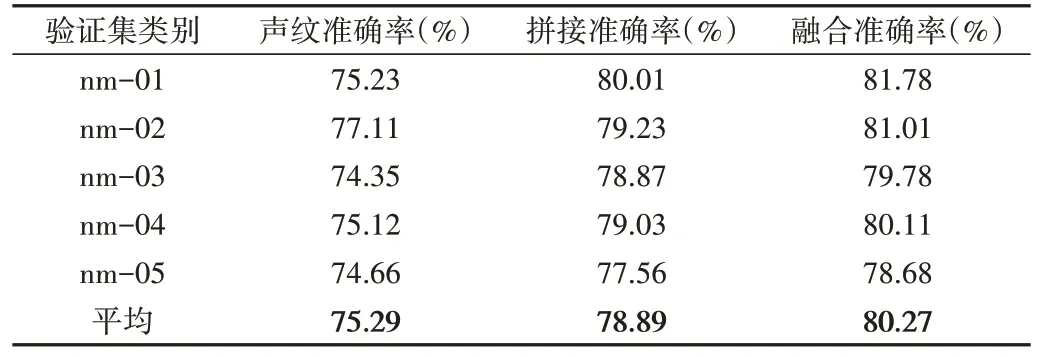
Table 3 Original dataset experimental results表3 原始数据集实验结果
从表3 的实验结果可以看出,当声音信息源被噪音干扰时,声纹识别的准确率受到了较大影响,平均识别准确率为78.89%,相比降噪后的识别率有所下降。而将两种特征直接拼接的方法取得了81.95%的准确率,高于声纹识别方法,说明该方法受到干扰较小,具有一定的鲁棒性。本文方法的识别率均高于前两种方法,获得了最好的识别效果,因为该方法会根据单模态对系统所作的贡献进行权值分配,对于信息干扰较大的模态分配较小的权值,减弱其对系统的影响。因此,进一步验证了多模态联合模型对单模态噪音干扰具有一定的鲁棒性,效果优于单模态方法。
4 结语
本文在实际场景下采集了注册人员的步态—声纹数据集,设计了联合步态声纹多模态身份识别系统,并在自采数据集上对所提出的步态—声纹联合模型进行验证。使用经过降噪处理的音频数据,模型取得了83.64%的准确率,证明了所提出模型的有效性,并进一步在具有噪音干扰的原始音频数据集上进行验证,模型取得了80.27%的准确率,两种情况都优于单模态系统与简单拼接的多模态系统,进一步证明了模型的抗干扰性与鲁棒性。
在未来的研究中,以下方面需要作进一步改进:步态声纹数据集数据量仍需进行扩充,后续研究将采集更多的行走视角以及行走状态的数据,进一步验证模型的鲁棒性;在监控视频中,人脸信息也可能会被捕捉到,将来可考虑使用决策层融合的方式实现步态、人脸和声音三模态联合系统,进一步提高系统的准确率与鲁棒性;此外,本文只针对视频中单人出现的场景进行识别,对于多人场景下的身份识别,还需要作进一步探索。
