基于hadoop的舰船通信网络数据并行处理方法研究
2023-05-10赵健
赵 健
(长治学院计算机系,山西长治 046011)
0 引言
随着舰船通信网络应用的普及,舰船通信网络数据量持续提升[1],由此导致舰船通信网络的处理与解析效率成为舰船通信网络数据应用过程中亟需解决的问题[2]。相关领域研究学者对于通信数据的处理方法进行了大量研究。龙草芳等[3]针对通信网络数据,采用分布数据数据加密方法对通信网络数据进行加密处理。但该方法实际应用过程中无法保障数据处理的实时性。杜海宾等[4]针对交互量巨大的通信网络数据处理问题,引用基于FlatBuffers的数据序列化技术提升数据通信效率。但该方法实际应用过程中受到数据规模的约束性,且方法可扩展性较差。针对上述问题,本文研究基于hadoop的舰船通信网络数据并行处理方法,提升舰船通信网络数据处理能力,降低数据处理时间。
1 舰船通信网络数据并行处理方法
1.1 基于hadoop的舰船通信网络数据并行处理架构
舰船通信网络数据处理过程中,结合舰船通信网络数据特性[5],设计基于hadoop的舰船通信网络数据并行处理架构。该结构是基于hadoop以Master-Slave架构为核心的分布式集群,通过分布式文件系统HDFS与My SQL 关系型数据库处理舰船通信网络数据。舰船通信网络数据并行处理架构的设计以MVC三层功能结构为基础,图1为架构的功能分层。

图1 基于hadoop 的舰船通信网络数据并行处理架构Fig.1 Data parallel processing architectureof ship communication network based on hadoop
基于hadoop的舰船通信网络数据并行处理架构共分为3层,由上至下分别是数据应用层、数据处理层和数据存储层。
数据应用层是用户与数据处理架构的交互工具,用户可以操作舰船通信网络与数据并行处理架构实施交互,上传所采集的舰船通信网络数据,也能够利用Web网页或各类智能终端查看舰船通信网络数据。
数据处理层运行MapReduce程序,主要功能为实现舰船通信网络数据存储、舰船通信网络数据解析、舰船通信网络数据聚类等的并行化处理,同时完成数据并行处理架构维护的相关操作,如数据上传与下载、集群间数据同步等。
舰船通信网络数据存储层的设计参考大数据平台的特性,采用HBase与HDFs 等多种不同的存储方式保障舰船通信数据存储的可扩展性(主要针对不同格式数据的存储问题),并利用MySQL 数据库保障舰船通信网络数据的安全性问题。
1.2 舰船通信网络数据处理层设计
舰船通信网络数据处理层的主要功能是利用MapReduce程序实现舰船通信网络数据的并行化处理。
1.2.1 改进的K-means算法
舰船通信网络数据处理层利用改进的K-means聚类算法实现舰船通信网络数据聚类处理。X={X1,X2,···,Xi,···Xn}表示初始舰船通信网络数据集合,其中Xi和分别n表示不同的舰船通信网络数据或数据集和舰船通信网络数据数量。模糊C均值聚类算法划分舰船通信网络数据类别过程中对通信网络数据集内的相似数据实施归类处理,直至划分为最小的数据集为止,其函数表达式如下:
式中,sij和d(Xj,Qi)分别为第j个舰船通信网络数据集内的第i个数据或数据集和第j个数据集同其他数据集内第i个数据中心的欧式距离;Qi为第i类或第i个数据集。
式中,m为对舰船通信网络数据集划分的次数。
以g表示第g次数据集的划分,利用式(3)表示函数表达式内的欧式距离:
式中:xik和xjk分别为舰船通信网络数据集X内的第i个和第j个数据集中的第k个数据或数据集。
利用表达式描述改进后K-means算法内的聚类中心数据集或中心点,以h表示聚类中心点的数据集,由此得到:
式中:dw(xa,xb)为改进后K-means算法内不同舰船通信网络数据类别的加权欧式距离,其计算公式如下:
式中,wi为第i个舰船通信网络数据集的权重。
1.2.2K-means算法的MapReduce并行化实现
K-means算法内,单独进行不同元素同质心距离的计算,此过程中各元素间不存在相关性,所以,可通过MapReduce 模型实现基于K-means 算法的舰船通信网络数据聚类MapReduce 并行化处理,图2为并行化处理流程图。
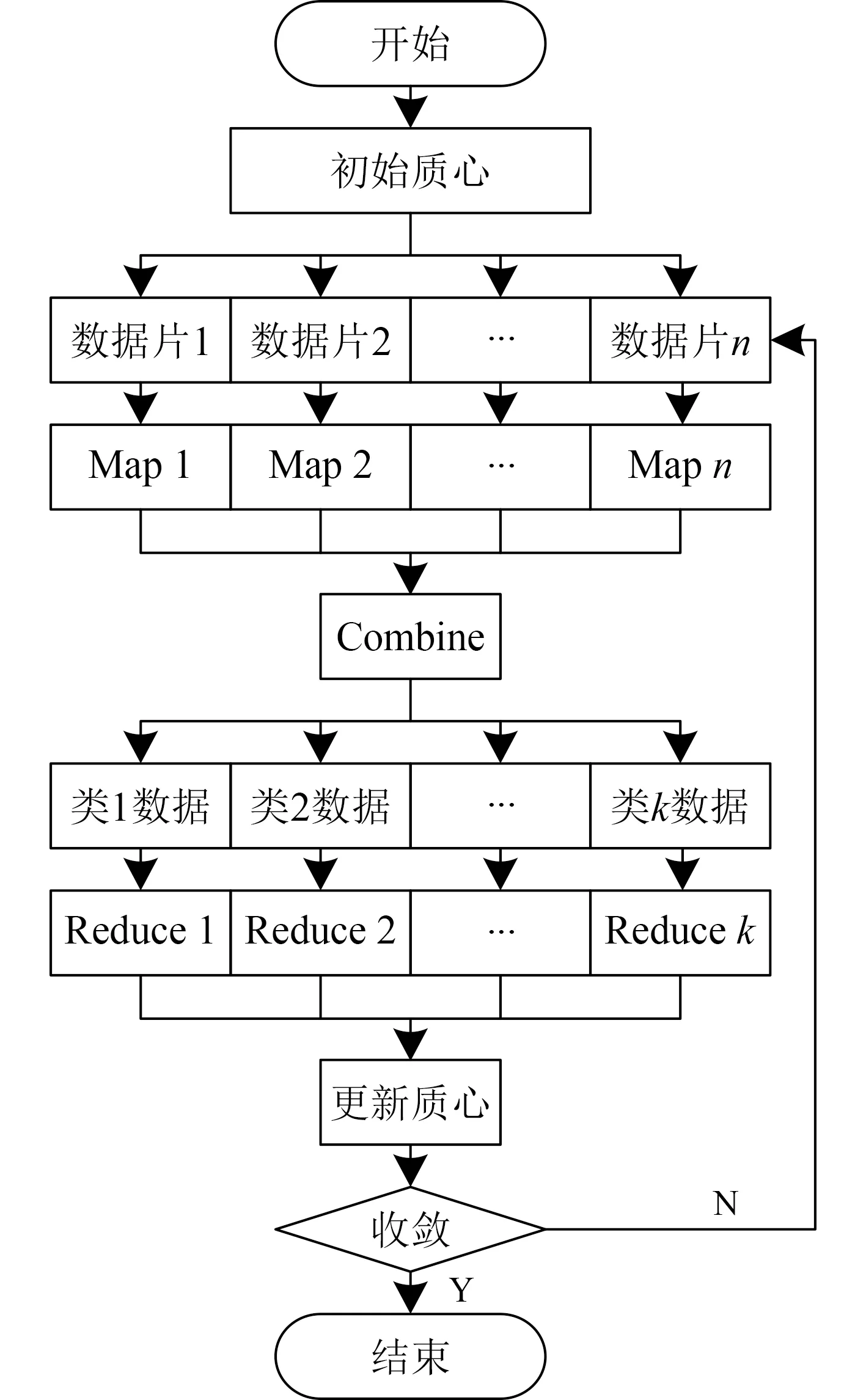
图2 聚类算法的MapReduce 并行化处理过程Fig.2 MapReduce parallelization process of clustering algorithm
在K-means算法的MapReduce 并行化实现过程中最重要的2 个步骤就是Map函数的设计与Reduce函数的设计。
1)Map函数的设计
基于K-means算法的舰船通信网络数据聚类MapReduce并行化实现过程中,Map函数的主要功能为由HDFS文件内采集舰船通信网络数据,针对不同舰船通信网络数据,确定其至不同质心的距离,同时针对此舰船通信网络数据进行类别标记。将初始舰船通信网络数据与聚类质心作为M a p函数输入〈key,value〉,即输入数据为舰船通信网络数据的〈行号,记录〉 ;将中间结果 〈key′,value′〉作为输出,即输出数据为舰船通信网络数据的〈 所属类别,记录〉。
2)Reduce函数的设计
基于K-means算法的舰船通信网络数据聚类MapReduce并行化实现过程中,Reduce函数的主要功能是依照Map函数的数据结果,更新聚类中心,便于下一轮Map函数应用。确定标准测度函数值,基于该值确定迭代过程都满足终止条件。
MapReduce并行化处理过程在运行Reduce函数前会合并处理Map函数的〈key′,value′ 〉,将其中key 值一致的多组〈key′,value′ 〉合并为一对。以 〈所属类别,{记录合计} 〉和 〈 类别号,均值向量+该类的平方误差和〉分别作为Reduce函数的输入 〈key′′,value′′ 〉和输出〈key′′′,value′′′〉 。
基于K-means 算法的舰船通信网络数据聚类MapReduce并行化实现过程中调用以上MapReduce 过程,不同迭代过程中均获取一个新的job,直至2次获取的平方误差和差值低于设定阈值,即可终止迭代过程。Map函数最后一次输出的 〈key′,value′〉即为舰船通信网络数据最终分类结果。
2 实验结果
本文研究基于hadoop的舰船通信网络数据并行处理方法,为验证本文方法在实际舰船通信网络数据并行化处理过程中的应用性能,从某系统中选取任意一艘舰船,采集其通信网络数据生成数据集。该数据集内共包含37874658条通信数据,对该数据集实施处理将其划分为5个大小有所差异的实验数据集,具体划分结果如表1所示。本文方法性能检验过程中搭建基于hadoop部分的6台计算机并行运行环境,将其中1台计算机和剩余5台计算机分别为子任务中的主要任务节点和其他子任务节点。
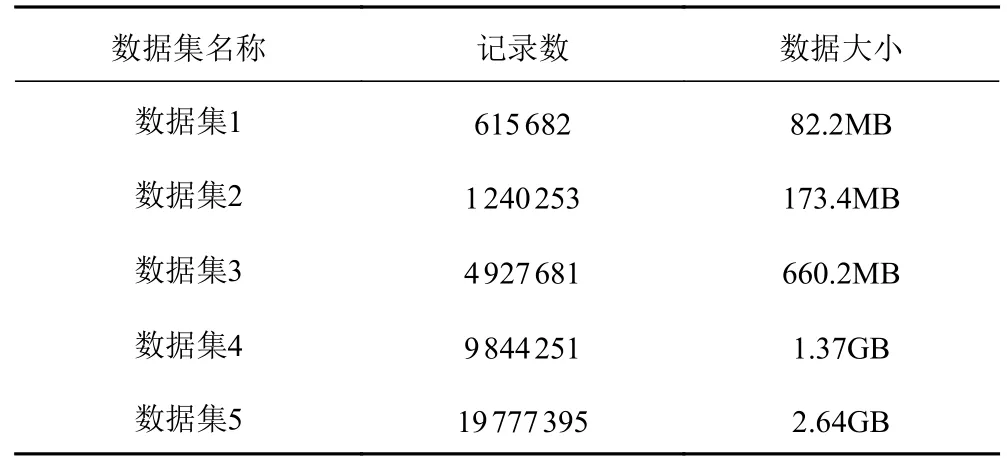
表1 实验数据集划分结果Tab.1 Experimental data set division results
2.1 聚类算法的有效性分析
为验证本文方法中数据聚类算法的有效性,采用本文方法对数据集1实施聚类中心确定,并同数据集的实际聚类中心进行对比,结果如表2所示。分析表2可得,针对数据集1,本文方法所得的聚类中心同实际聚类中心基本一致,误差控制在百分数级别,由此表明本文方法能够获取较为准确的聚类中心,为后续实现高精度的数据聚类结果打下坚实基础。

表2 通信数据聚类性能分析结果Tab.2 Communication data clustering performance analysis results
2.2 并行化处理性能分析
表3为不同集群节点数量条件下5个数据集的运行时间。分析表3可得,在数据规模一致的条件下,集群节点数量越多任务完成时间越短。由此说明通过提升集群节点数量能够大幅提升数据处理能力,表明本文方法具有较好的扩展性。
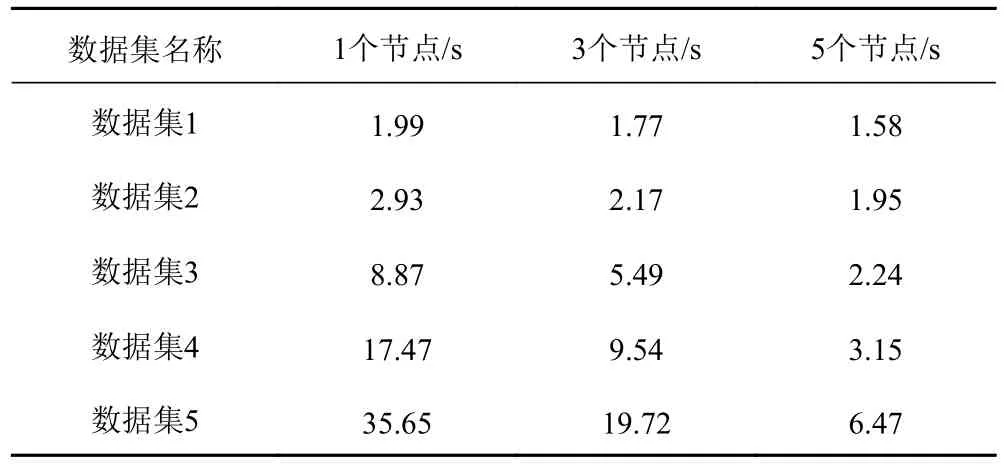
表3 本文方法运行时间Tab.3 Operation time of thismethod
通过加速比能判断本文方法的并行处理性能,其能够呈现通过降低运行时间呈现的性能提升效果。图3为本文方法的加速比测试效果。分析可得,本文方法的加速比趋于线性。因Hadoop集群初始运行需要花费一定时间,因此在数据量较少的条件下,本文方法的加速比性能并不明显。但在数据量较大的条件下,本文方法的加速比性能同数据量之间表现出正比例相关。表明在数据量越大的条件下本文方法的加速比性能越好,也就是本文方法适于应用在海量舰船通信网络数据的处理中。

图3 加速比分析结果Fig.3 Acceleration ratio analysis results
3 结语
本文研究基于hadoop的舰船通信网络数据并行处理方法,利用MapReduce实现舰船通信网络数据的并行化聚类,同时通过实验验证了本文方法的应用性能。在后续研究过程中将进一步优化本文方法,探索舰船通信网络数据其他处理过程的并行化实现。
