基于改进的VGG16网络和迁移学习的水稻氮素营养诊断
2023-05-10张林朋杨红云郭紫微
张林朋 杨红云* 钱 政 郭紫微
(1.江西农业大学 软件学院,南昌 330045;2.江西农业大学 计算机与信息工程学院,南昌 330045)
在水稻的栽培管理中,氮肥对其产量的贡献率约占50%[1],过量施氮则会在土壤中遗留大量氮元素,不仅造成了氮肥的浪费,而且对环境产生一定的污染[2]。精准施氮能够减少水稻生长过程中的无效分蘖,提高有效成穗率,优化群体结构,改善田间植株的生长状况,减少病虫害的发生率,从而提升水稻的产量[3]。因此,对施氮量的管理至关重要,对水稻氮素营养快速准确诊断能够有效的指导合理施氮[4]。
目前,氮素营养诊断主要包括化学分析[5]、光谱遥感[6]、便携式叶绿素仪[7](Soil and plant analyzer development,SPAD)和数字图像技术[8]等。虽然这些技术在一定的条件下可以进行氮素营养诊断,但化学分析需要在实验室进行处理且对相关专业的要求较高[9],光谱遥感试验仪器昂贵,对专业的要求较高[10],便携式SPAD仪需要多点重复测量且SPAD值易受光照影响[11-12],数字图像技术需要人为的设计、提取和优化特征,且提取过程较为繁杂,未考虑到模型的自主学习。
近年来,随着深度学习等技术的广泛应用,使用深度学习等技术用于识别病虫害,识别杂草,营养诊断等也越来越广泛[13]。熊俊涛等[14]使用迁移学习和改进的VGG16模型对大豆叶片缺素数据集进行训练,该模型在测试集上的准确率为89.42%。Kusanur等[15]使用经迁移学习的Inception-V3、ResNet50和VGG16网络模型分别对番茄植物营养缺乏性进行预测和分类,结果表明Inception-v3模型的准确率达到99.99%。Xu等[16]通过微调4种最先进的DCNN:Inception-v3、ResNet50、NasNet-Large和DenseNet121,在水培试验获取的水稻叶片图像数据集上进行训练,所有的DCNN在测试准确率均在90%以上。潘圣刚等[17]研究表明,水稻氮素吸收及快速积累的主要时期是在分蘖期和拔节期。本研究拟在水稻生长的幼穗分化期和齐穗期,分别采集4种不同氮素水平的叶片图像,使用改进的VGG 16网络和迁移学习相结合的方法,构建水稻氮素营养诊断模型,以期为水稻等作物的氮素营养诊断建模提供理论依据。
1 材料与方法
1.1 试验区概况及试验设计
于2017-06-14开始在江西省南昌市成新农场(116°15′ E,28°92′ N)进行水稻氮素营养试验。经测定稻田土壤基本理化性质为:pH 5.30、有机质24.40 g/kg、全氮1.40 g/kg、有效磷12.70 mg/kg、速效钾123.0 mg/kg[18]。
以超级杂交稻‘两优培九’(Liangyoupei 9,LYP9)为供试品种,其最佳施氮(纯氮)量为210~300 kg/hm2[19]。本研究设置N1、N2、N3和N4共4组不同的施氮水平:施氮量分别为0、210、300和390 kg/hm2。将水稻种植于小区中,小区随机区组排列,每小区面积5 m×6 m=30 m2,小区间筑土埂隔开,并用塑料薄膜覆盖埂体,单灌单排,重复3次。氮肥按m(基肥)∶m(分蘖肥)∶m(穗肥)=2∶1∶2施用。钾肥按m(分蘖肥)∶m(穗肥)=7∶3施用,磷肥一次性做基肥施用。各施肥区域中磷、钾肥用量相等,即P2O5为225 kg/hm2和K2O为300 kg/hm2。供试肥料分别为尿素(含N量46%)、氯化钾(含K2O 量60%)和钙镁磷肥(含P2O5量12%)[19]。人工移植前1 d施用基肥,人工移植后7 d施用分蘖肥,在叶龄余数1.5左右施用穗肥料[20]。于5月25日播种,6月14日人工移栽,栽插密度为13.3 cm×26.6 cm,其他操作均按常规的高产栽培要求进行。
1.2 水稻叶片图像获取
本试验所用扫描设备为MICROTEK扫描仪(型号MRS-9600TFU2L,上海中晶科技有限公司生产,分辨率600 dpi),于水稻幼穗分化期(2017-07-24)和齐穗期(2017-08-24)扫描获取水稻图像,每次扫描获取960张,其中每个时期水稻的顶一叶、顶二叶、顶三叶图像均为320张(叶片图像包含对应叶鞘图像),共计1 920张2 515像素×3 997像素的水稻图像。每一张水稻图像视为一组水稻数据。因水稻叶片过长[21],为便于扫描图像,将每片叶片分为叶中和叶尖部分,平铺在同一大小的白色纸张上,同时放置对应叶片的叶鞘和一个已知大小的参照物,以便后续试验处理。
1.3 叶片图像预处理
本研究对水稻叶片图像进行处理,从而获取完整的水稻叶片。因在扫描图像的过程中,有部分水稻叶片产生折叠、蜷缩等现象,将其去除。水稻生长幼穗分化期和齐穗期图像数据集见表1。本试验获取的实际数据量为1 832张,其中幼穗分化期的图像为902张,齐穗期的图像为930张。部分幼穗分化期的水稻叶片图像见图1。

表1 水稻生长幼穗分化期和齐穗期采集的水稻图像数据集Table 1 Rice image data sets were collected at the young panicle differentiation stage and full heading stage of rice growth

图1 幼穗分化期4组不同施氮水平的水稻叶片图像示例Fig.1 Image examples of rice leaves with four different nitrogen application levels at young panicle differentiation stage
因本试验获取的水稻图像数据集较少,构建水稻叶片氮素营养诊断模型难以了解真实的数据集分布,很容易出现过拟合现象。因此需要对原始的数据图像使用数据扩充的方法,用以解决数据量过少的问题。在深度学习中,数据增强是常用的数据扩充方法之一。本研究采用平移变换、旋转任意角度、翻转变换、尺度变换、增加噪声以及调节明亮度等常用的数据增强方式进行水稻叶片扩充,将水稻幼穗分化期采集的水稻叶片每一类的原有数据图像扩充为原来的10倍,图像由原来的902张扩充到9 020张。按照同样操作,将齐穗期采集的水稻叶片数据进行扩充。将原来的930张叶片图像扩充为9 300张(表1)。因经过扫描后的图像的分辨率过大,且经过处理后图像的大小尺寸不一,为了方便网络模型的输入,统一将图像调整为224像素×224像素,图像格式均为jpg。将水稻叶片数据集按照训练集∶测试集=8∶2随机划分为训练集和测试集。其中80%的图像数据用于训练,20%的图像数据用于模型测试。
1.4 试验环境及参数设置
本试验模型的训练与测试均在Windows10 64 bit操作系统下实现。试验的硬件环境为:CPU使用Intel(R) Xeon(R) Silver 4112@2.6 GHz 2.59 GHz,内存为16 GB;GPU使用的是NVIDIA RTX 2080 Ti,显存为11 GB。软件环境为CUDA 11.1、Tensorflow 2.8.2和Python 3.7.13。网络以TensorFlow为框架,调用keras的接口搭建模型。
为使得模型能够取得更好的诊断识别效果,设置模型的超参数,设置批次(batch size)为64,即每次训练和测试都是64张图像。将训练轮数(Epochs)设置为100。使用Adam优化算法[22],初始学习率设置为1×10-5,微调前训练100次,微调后训练50次,微调后的学习率为初始学习率的1/10。
1.5 构建水稻叶片氮素营养诊断模型
选择现阶段比较流行的VGG16[23]网络以作为特征提取模块,去除顶层的全连接层,保留前面的卷积层和池化层。对该网络模型构建分类网络部分,分类网络部分由全局平均池化层(Global average pooling)、批标准化层(Batch normalization)、Dropout层及全连接层构成。
具体步骤如下:
1)使用全局平均池化操作将特征图(Feature map)单位均值化,将每层的特征值合为一个特征值,用以替代卷积神经网络中的多层全连接层分类网络,有效降低参数的数量。
2)使用批标准化操作可以使得模型训练过程更加稳定,提高模型的训练速度,Batch Normalization 具有某种正则化作用,减少过拟合,加快模型的训练速度[24]。
3)因为图像数据样本数量较少,为了减少模型的过拟合,在全局平均池化层后加入Dropout层,在模型训练过程中以某个概率冻结部分神经元,使其失活,减少中间特征的计算量[25-26]。
4)在设计最后的分类网络中,由于数据集中包含4种不同的氮素营养,因此全连接层的输出神经元设计为4个。图2为改进的VGG16网络模型简图及主干部分。

图2 改进的VGG16网络模型简图(a)和主干部分(b)Fig.2 Improved VGG16 network model diagram (a) and backbone (b)
1.6 主要算法流程
模型的算法流程(图3)如下:

图3 模型算法流程Fig.3 Algorithm flow chart of the model
1)数据预处理。将获取的水稻叶片数据进行平移、翻转、旋转、缩放等预处理操作,用以实现数据集的扩充,并将图像全部调整为224像素×224像素。
2)输入水稻叶片数据。在4种不同的氮素营养的水稻叶片图像数据中随机抽取80%作为训练样本集。
3)构建水稻叶片氮素营养诊断模型,将训练集送入模型进行训练。
4)迁移学习和微调。使用迁移学习策略将ImageNet大型数据集上预训练的VGG16网络模型的权重参数迁移到构建的网络模型中,优化模型参数,调整训练时的学习率、Batchsize等超参数,更新参数,优化分类网络的结构和参数。
5)测试模型。抽取剩余的20%的水稻叶片图像数据用于模型的测试,以验证模型的诊断识别效果。
1.7 迁移学习及微调
采用迁移学习策略[27],将ImageNet大型数据集上预训练的VGG16网络的权值参数迁移到本研究所构建的改进的VGG16网络模型中,将其作为特征提取模块,应用在水稻氮素营养诊断的数据集上,提取水稻叶片图像的特征信息,减少因训练神经网络模型所需的时间成本、数据量和试验所需的算力,可以解决小型数据集在深度神经网络上产生的过拟合现象。本试验利用迁移学习策略与改进的VGG16网络模型相结合,构建水稻氮素营养诊断模型。迁移学习与全新学习的不同在于,迁移学习可以加快网络的训练时间,使得模型能够更快收敛。微调是指预先将网络的特征提取部分冻结为不可训练状态,只对分类网络部分进行训练,最后解冻网络的特征提取部分的某些隐藏层,对这些网络层进行不同程度的解冻并参与到模型的训练中,可以更好的提升模型的分类能力。
2 结果与分析
2.1 改进的VGG16网络模型的准确率及参数
以水稻幼穗分化期的图像数据为例,对改进的VGG16网络与原始的VGG16网络模型进行准确率和模型参数的对比,结果见表2。可以看出,迁移学习在一定的时间内加速模型的收敛,提高模型的准确率。改进的VGG16网络模型的识别准确率更佳,其训练时间只有迁移学习的VGG16网络模型训练时间的60%左右,且模型的大小约为迁移学习的VGG16网络模型的1/6。同时,改进的VGG16网络模型在精准率和召回率上均优于迁移学习的VGG16网络。

表2 改进前后VGG16 网络模型的准确率及参数对比Table 2 Comparison of accuracy and parameters of VGG16 network model before and after improvement
图4示出迁移学习的VGG16和改进的VGG16网络模型训练过程损失曲线。可见,迁移学习的VGG16网络模型训练过程中出现了损失曲线的震荡,而改进的VGG16网络模型,震荡小,更稳定,表明改进的VGG16网络模型更稳定,更趋近于收敛。在齐穗期时,本模型亦优于迁移学习的VGG16网络。

图4 迁移学习的VGG16(a)和改进的VGG16(b)网络模型训练过程损失曲线Fig.4 Loss curves during training of VGG16 (a) and improved VGG16 (b) network models for transfer learning
2.2 其他不同网络模型的准确率和参数对比
为更好的验证改进的VGG16网络模型的有效性,在使用水稻幼穗分化期的图像数据条件下,与经典的AlexNet、VGG19、ResNet50网络模型和轻量级网络模型MobileNet V1进行对比,结果见表3。可以看出:不同网络模型在识别准确率、运行时间及模型大小等方面存在较大差异。迁移学习可以加快模型的收敛,在一定程度上提高模型的泛化能力,且模型的训练时间更短。改进的VGG16网络模型在水稻氮素营养上的准确率,运行时间以及模型大小均优于全新学习的AlexNet、VGG19和迁移学习的ResNet50、MobileNet V1模型。本模型在齐穗期时,亦同样优于其他模型。
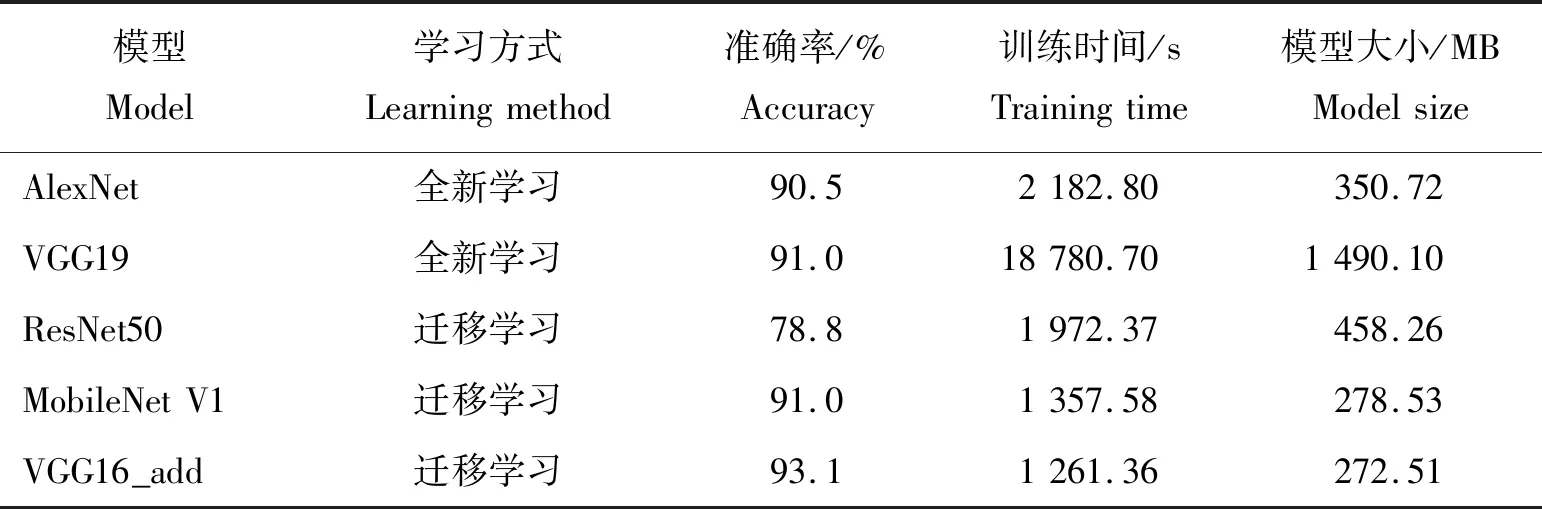
表3 不同网络模型学习方式和参数对比Table 3 Comparison of learning methods and parameters of different network models
2.3 微调前后网络模型的识别准确率
微调是指对模型的特征提取部分从一开始设置的冻结权重的状态调整为解冻权重。使其更好的拟合所训练的网络模型。在使用幼穗分化期和齐穗期的水稻叶片图像的条件下,对改进的VGG16网络模型预训练100轮,再分别解冻前5、10、15和全部的特征提取网络层数。模型在水稻生长2个不同时期测试集上的准确率见表4。微调全部的特征提取网络,模型在测试集上的识别准确率最好。

表4 改进的VGG16模型微调前后在水稻幼穗分化期和齐穗期测试集的准确率Table 4 Accuracy of the improved VGG16 model before and after fine-tuning on the test set at the young panicle differentiation and full heading stages of rice
以模型在幼穗分化期为例,其训练过程曲线见图5。微调后模型的准确率有着较大的提升,且损失曲线更趋向于收敛。齐穗期时,微调模型,亦有准确率的提升。表明微调后,模型在测试集上的准确率能够有提升。

图5 改进的VGG16模型在微调全部特征提取层训练过程的准确率(a)和损失(b)曲线Fig.5 Accuracy (a) and loss (b) curves of the improved VGG16 model during the training process of fine-tuning all feature extraction layers
2.4 在幼穗分化期和齐穗期的准确率及评价指标
在水稻生长幼穗分化期和齐穗期,使用上述改进的VGG16网络模型,将2组不同生长期的图像数据分别对该模型预训练100轮,微调50轮,其在测试集上的准确率及评价指标见表5。本模型不但适用于幼穗分化期的水稻氮素营养诊断,同样适用于齐穗期的水稻氮素营养诊断识别。

表5 微调后模型在水稻生长幼穗分化期和齐穗期测试集上的准确率及评价指标Table 5 Accuracy and evaluation index of the model after fine adjustment in the test set of rice growth young spike differentiation stage and full heading stage
将微调后模型分别在水稻幼穗分化期和齐穗期的测试集上进行评估,得到混淆矩阵见图6。当施氮水平为N1和N4及施氮水平为N2和N3时,彼此分类的错误率较大,可能是田间稻田土壤肥力不均匀,以及田间管理不规范、数据预处理时未对图像进行消噪处理等因素造成的。齐穗期时,在测试集上氮素营养的识别的准确率从高到低依次为N4、N1、N2、N3。

图6 微调后的模型在水稻幼穗分化期(a)和齐穗期(b)测试集上的混淆矩阵Fig.6 The confusion matrix of the finely tuned model on the test set of young panicle differentiation stage (a) and full heading stage (b)
3 讨 论
研究表明[28]在水稻生育后期合理施肥可以使灌浆期保持一定的氮素供应,延缓功能叶的衰老,维持生育后期较高的光合速率和蒸腾速率,有利于光合作物的积累与运输,使水稻籽粒灌浆充分,从而提高产量。近年来,由于高产品种的推广和肥料的大量使用,稻谷产量大幅提升,稻米品质却未明显改善,肥料利用率也呈现出下降趋势[29]。因此,合理施用氮肥是非常重要的,对氮素营养诊断识别可以有效的指导施氮。已有研究只涉及某个日期或某个时间段内的水稻营养诊断识别,没有涉及几个具体的水稻生长期。本研究在齐穗期时,使用改进的VGG16网络和迁移学习相结合的氮素营养诊断模型进行诊断识别,得出第一类和第四类的氮素营养识别准确率高于第二类和第三类,这与周琼等[30]得出的结论相同,证明了改进的VGG16网络和迁移学习相结合的水稻氮素营养诊断模型操作的可行性。关于幼穗分化期的识别准确率高于齐穗期,正好说明超级杂交稻生育后期易出现早衰现象,叶片的含氮量快速衰减,难以通过叶片直接进行区分[31]。
在幼穗分化期,改进的VGG 16在模型大小和运行时间上优于其他几个经典模型。与VGG 19相比,本研究重构顶层,增加全局平均池化可以减少模型的参数,提升模型的诊断识别效果。与ResNet50对比,可能是模型的网络层数增加,其参数量过多,本研究所采用的数据不足以训练ResNet50网络。而MobileNetV1 网络在准确率和训练时间上弱于改进的VGG 16网络,表明MobileNetV1所使用的深度可分离卷积具有较好的提取特征的效果,且模型的所占内存较为合适,可以为后续的开发应用提供参考。试验结果也表明改进的VGG16网络模型对水稻氮素营养诊断具有较好的识别准确率及鲁棒性。
本研究所构建的水稻氮素营养诊断模型,虽能较好地判定其氮素含量的缺失,但水稻的最佳施氮量仅为一个范围。因此,在后续研究中,将在最佳施氮范围内增设多个施氮梯度进行研究。本研究只试验了一种水稻品种的幼穗分化期和齐穗期的图像数据,在后续的研究中,还应考虑其他品种,不同水稻生长关键期,多个不同梯度的氮素施肥以及使用数码相机、手机拍照等非扫描方式获取图像等因素的影响。水稻氮素营养诊断的核心及目的是建立适合的追施肥体系,并据此进行推荐施肥[32],因此,如何更好的进行氮素营养诊断,使其更加科学与合理的指导使用肥料还需进一步研究探索。
4 结 论
本研究通过构建氮素营养诊断模型,对采集的图像数据进行识别,在训练过程中迁移预训练的权重,并对此进行微调,得出以下结论:
1)改进的VGG16网络模型在水稻的氮素营养诊断识别中具有较高的准确率。
2)迁移学习可以加快模型的收敛速度,在一定的程度上使得模型减少训练时间与训练成本,提高模型的准确率。微调能够加快模型的收敛速度,节约计算资源。
3)本模型对幼穗分化期和齐穗期的水稻氮素营养诊断是有效、可行的。