结合改进Alphapose和GCN的人体摔倒检测模型研究
2023-05-09曲英伟梁炜
曲英伟,梁炜
(大连交通大学 软件学院,辽宁 大连 116028)
已有的基于计算机视觉的摔倒检测模型主要有基于传统机器视觉方法和基于深度学习方法两类。基于传统机器视觉方法提取特征易受场景、光线等因素影响,准确率较低;由于硬件突破带来的算力大幅提升,基于深度学习的方法得到高速发展。郭欣等[1]搭建了使用注意力机制轻量化结构的深度卷积网络,并提取了骨骼关键点信息,检测摔倒行为依据视频帧间骨骼关键点的变化来判断。曹建荣等[2]先使用YOLOv3检测得到人体目标区域矩形框,将跌倒过程中的人体运动特征与卷积提取的特征融合,再进行摔倒判别,该方法比传统方法有更强的环境适应性。卫少洁等[3]提出一种结合Alphapose和LSTM的人体摔倒模型,主要思想是将姿态估计提取出来的人体骨骼关键点的坐标集分为x坐标集和y坐标集,将这两个坐标集分别输入长、短期记忆网络来提取时序特征,最后用一个全连接层进行分类,判断人体是否发生摔倒,但受制于LSTM需要存储的特性,不能进行实时检测。Chen等[4]提出了一种基于对称性原理的意外摔倒重组的方法,通过OpenPose提取人体的骨骼关键点信息,并通过髋关节中心的下降速度、人体中心线与地面的角度、人体外部矩形的宽高比等3个关键参数来识别摔倒。
本文提出一种基于改进的Alphapose[5]结合GCN[6]的人体摔倒检测模型,该模型采用YOLOX[7]结合Deepsort[8]对出现在视频中的人体目标进行跟踪,检测得到每一帧的目标检测框,将目标检测框所框定的部分送入改进后的SPPE进行推理,得到人体骨骼关键点信息。将得到的骨骼点以图信息的形式传入图卷积神经网络(GCN)进行图卷积,将图卷积后的张量传入Linear层进行分类,实现人体摔倒检测。采用Alphapose与图卷积相结合的方法,很好地避免了对视频环境的依赖,本模型在公开数据集上与多个模型进行了对比试验,结果表明本模型具有较高的检测准确率和较低的场景依赖性。
1 模型总体架构
本模型主要由人体目标检测(Detections)、人体目标跟踪(Tracks)、人体姿态估计(SPPE)、人体行为识别(GCN)组成,见图1。
2 人体目标检测网络结构及优化
本模型目标检测部分使用YOLOX-S轻量化网络模型,旨在快速得到人体目标检测框信息、置信度得分以及分类信息。经过阅读源码发现,YOLOX中使用的SiLU激活函数具有很强的非线性能力,而SiLU是Swish在β=1时的情况,其计算公式为:
f(x)=x·sigmoid (x)
(1)
式(1)保持了ReLU的优势,在x>0时不存在梯度消失的问题,与此同时也不存在x<0时轻易死亡的问题,但有计算量较大的缺陷,相比之下,ReLu激活函数的计算简单而高效。ReLU的计算公式为:
f(x)=max (0,x)
(2)
本模型同时使用ReLU和SiLU两种激活函数,以较少个数的SiLU来保持良好非线性,再加上较多个数的ReLU来减少计算量,提升推理速度。
由于YOLOX中置信度分支使用BCE损失函数进行计算过于简单,应该进一步优化。在目标检测领域,不同的算法可能会生成不同数量的候选框,而其中大部分都是不包含目标的负样本,只有少部分是包含预期检测到的目标的正样本,于是就导致了样本类别不均衡的情况。负样本比例太大,且多数是容易分类的,占据了总的损失的大部分,这就使得模型在回归的时候优化的方向并不如预期。针对这种情况,Lin 等[9]提出了Focal loss,它改进了交叉熵损失函数,通过动态的减少容易样本的权重,使得模型的注意力集中在更难以分类的困难上。Focal loss公式为:
Focal loss=-α(1-Pt)γ·log(Pt)
(3)
当错误地分配了一个样本时,Pt是一个很小的值,而式(3)前面的调整系数就趋近于1,不会影响对错误样本的损失计算。而当一个样本很容易被准确分类时,Pt就趋近于1,这时式(3)前面的调整系数就趋近于0了,减少了很容易被准确分类的样本的损失对于总的损失的贡献。因此本文采用 Focal loss 代替 BCE loss计算置信度损失。
3 人体目标跟踪架构
本模型人体目标跟踪部分使用DeepSort结合YOLOX的方法,其中每个跟踪实例需要与YOLOX所得的目标检测结果进行匹配,根据不同的情况可分为3个状态,初始化时设定为临时状态,如果没有匹配上任何检测结果则会被删除;如果连续匹配上一定次数,则被设定为已跟踪状态;在已跟踪状态时如果未匹配超过设定的最大次数次,则被删除。使用级联匹配的方式进行跟踪实例和检测实例的匹配,见图2。

图2 级联匹配过程
级联匹配中需要计算成本矩阵,分为两种:一种是余弦距离计算的成本矩阵,一种是IOU关联计算的成本矩阵,然后通过匈牙利算法解决线性指派问题。图2中级联匹配层使用的是余弦距离计算的成本矩阵,IOU匹配使用的是IOU关联计算的成本矩阵且只用来计算没匹配上和无跟踪状态的跟踪实例。卡尔曼滤波器在多目标跟踪的应用中分为两个部分,一个是预测,一个是更新。预测有状态预测和协方差预测,状态预测是用跟踪实例在t-1时刻的状态来预测其在t时刻的状态,公式为:
x′=Fx
(4)
式中:x是跟踪实例在t-1时刻的均值;F为状态转移矩阵。
做协方差预测,新的不确定性由上一不确定性得到,并加上外部干扰,如式(5):
P′=FPFT+Q
(5)
式中,P为跟踪实例在t-1时刻的协方差;Q为系统的噪声矩阵(一般初始化为很小的值)。
更新基于t时刻得到的检测实例,矫正与其关联的跟踪实例状态,以得到一个更精确的结果。计算检测实例和跟踪实例的均值误差为:
y=z-Hx′
(6)
式中:z是检测实例的均值向量;H为测量矩阵,它将跟踪实例的均值向量x′映射到测量空间。
将协方差举证P′映射到测量空间,再加上噪声矩阵R,如式(7):
S=HP′HT+R
(7)
式中:噪声矩阵R是一个4×4的对角矩阵,对角线上的值分别为中心点两个坐标值和宽高的噪声,以任意值初始化。
计算卡尔曼增益K,用于估计误差的重要程度,如式(8):
K=P′HTS-1
(8)
式(9)和式(10)分别计算了更新后的均值向量x和协方差矩阵P:
x=x′+Ky
(9)
P=(I-KH)P′
(10)
4 基于滑动窗口注意力改进的SPPE
原Alphapose中SPPE的backbone为Resnet50,网络结构较为简单。本文引入Swin Transformer[10]算法以期在SPPE的backbone部分进行改进。Swin Transformer算法以其特有的滑动窗口注意力机制结合原本SENet所特有的通道注意力机制,更准确地提取特征,进而提升pose提取的准确率。
Swin Transformer算法由Patch Embedding、Patch Merging、相对位置编码、Window based Multi-head Self-Attention(窗口多头自注意力机制)、Shifted Window based Multi-head Self-Attention(滑动窗口多头注意力机制)等模块组成。Patch Embedding解决了后续操作的数据输入问题。Swin Transformer算法采取了对图像进行相对位置信息编码的方式,将相对位置信息融合到attention矩阵中。先以feature map的每个像素点为原点,配置其他点的对应坐标;然后按照顺序依次纵向拉平;再横向拼接起来形成像素点个数为宽高相等的正方形坐标矩阵;再统一加上偏移量后除以小于零的坐标值;而为了防止x+y坐标值一样,又将x坐标值统一乘以y坐标值的最大值;最后将横、纵坐标相加,得到最后的position id,用于索引embedding的值,就可以在attention矩阵中融合图像的相对空间位置信息。其公式为:
(11)
式中:B即为相对位置矩阵。
Swin Transformer block使用窗口多头注意力后,前面划分的每一个窗口内部的像素就建立了关系,但是不同窗口之间,有的像素也是相邻的,这时候就需要进行一个窗口的滑动,然后再做自注意力操作,这样就使得不同窗口之间产生了信息的交互。而窗口的滑动,将特征图先向上移动3个像素,再向左移动3个像素,就将原来的特征图划分为9块不同的区域,以window_size大小的窗口在滑动后的特征图上做多头注意力,在做注意力之前,需要使用mask的方法避免本来不相邻的像素之间做自注意力操作。窗口滑动的效果见图3。这样一层窗口多头注意力后接一层滑动窗口多头注意力,就实现了当前阶段的全局信息交互。
Patch Merging是对图片进行切片操作,在行方向和列方向每隔一个像素采样一个值,类似于近邻下采样,然后将每个区域中采样的每个像素按原图的位置拼接起来,这样通道数就会变成原来的4倍,再接一个线性层后将通道数减少变成原来的2倍,宽高就变为原来的1/2,且在没有信息丢失的情况下得到下采样的特征图。
Swin Transformer算法对每一层特征图的信息都做了较好的信息交互。但是在每一通道上特征图的重要程度不应该都是相同的,本模型将SENet这一强大、有效的通道注意力机制引入Swin Transformer中,在进行每一次下采样之后,再增加执行一次SENet模块,给不同的通道赋予不同的权重,使模型容易学习到重要的特征信息。
本模型设计了FastPoseSwin人体姿态估计网络,用于提取pose信息,其结构图见图4。FastPoseSwin结合了Swin Transformer与原Alphapose中的SENet[11]、DUC[12]、 Pixshuffle[13]等模块, 主要是添加了SENet模块的Swin Transforme,作为更高效和更准确的backbone来提取特征图,以期得到更准确的人体骨骼关键点提取结果。其中,DUC是一种用通道数来弥补H和W尺寸上的损失的网络结构。PixelShuffle通过卷积和周期性筛选来提高特征图的分辨率。
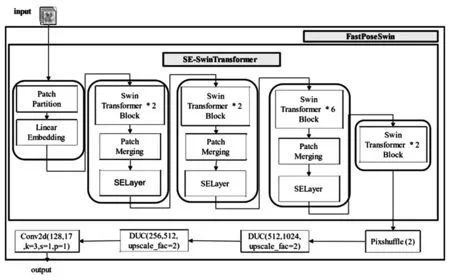
图4 FastPoseSwin 网络结构
本模型得到13个人体骨骼关键点在每一帧图像上对应信息的一个列表,列表里存储着对应人体目标的bbox、bbox得分、骨骼关键点、骨骼关键点得分和proposal_score,其中proposal_score是骨骼关键点得分的均值+bbox得分+1.25倍最高骨骼关键点得分。
5 基于图卷积的摔倒检测方法
图卷积(GCN)是一种具有强大的图表达能力的深度学习模型,区别于卷积神经网络,它对非欧几里得结构的数据有较好的空间特征提取能力。而所提取出来的姿态图就属于这种非欧几里得数据,因此本文采用图卷积的方式对人体骨骼关键点进行处理,将骨骼图送入图卷积神经网络进行训练,模型推理输出得到分类结果,如坐着、站立、行走、摔倒等。
拉普拉斯矩阵被用来定义图卷积神经网络,对于一个图G=(V,E),其中V代表顶点(node)的几何,E代表边(edge)的几何。其拉普拉斯矩阵由这个图的度矩阵和邻阶矩阵共同定义。度矩阵就是对图中各个顶点的度的描述,即这个顶点与多少个顶点有联系,度矩阵是一个对角矩阵,其对角线上元素即每个顶点的度。邻接矩阵是对图中各个顶点连接关系的描述,因为在图卷积神经网络中,图都为无向图,由无向图的邻接矩阵表示方法可知,GCN中的邻接矩阵是沿对角线对称的。拉普拉斯矩阵的计算公式为:
L=D-A
(12)
式中:D为图的度矩阵;A为图的邻接矩阵。
本模型使用如下方式构建图卷积神经网络:
(13)

(14)
具体到每一个节点,Symmetric normalized拉普拉斯矩阵中的元素为:
(15)
式中:deg (vi)和deg (vj)分别为节点i,j的度,即度矩阵在节点i,j处的值。该方法引入了自身度矩阵,解决自传递问题的同时,对邻接矩阵进行了归一化操作,再通过对邻接矩阵两边乘以节点的度矩阵开方然后取逆。
本模型设计了一个简单有效的人体行为分类模型,将姿态估计部分预测所得到的13个人体骨骼关键点的坐标及其置信度得分作为一个形如(13,3)的向量,作为人体行为分类模型的输入,通过图卷积层、线性变化层、Dropout等模块处理,最后输出一个形状为(batch_size, num_classes)的特征向量,算法执行过程见图5。
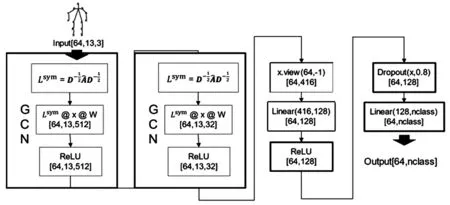
图5 GCN摔倒检测算法执行过程
图5中,input的输入形状为[64,13,3],其中64为batch_size,13为关键点个数,3为通道数,代表了关键点的横、纵坐标和置信度得分。整个基于GCN的摔倒检测算法结构设计较为简单,先将关键点输入GCN模块中,求出Symmetric normalized拉普拉斯矩阵Lsym,将Lsym与关键点特征向量和初始化的权重W相乘,进行图卷积后输入ReLU非线性激活函数,此时特征向量的形状变为[64,13,512]。随后再输入一个GCN模块,特征向量变为[64,13,32]。这时将特征图转换为二维张量,再使用线性层配合ReLU激活函数实现一个简单的神经网络,对其特征进行学习。再使用Dropout将激活函数输出的值以一定的比例随机置为0,用来防止模型过拟合。最后用一个输出通道为nclass的Linear线性变换作为分类器,得到分类结果。
6 试验与结果分析
为了从各方面对本文摔倒检测模型进行验证,本文进行以下三部分试验,分别验证目标检测部分、人体姿态估计部分和人体行为识别部分。
6.1 优化后的YOLOX算法性能测试
目标检测部分的试验采用CrownHuman[14]数据集进行训练,其中,训练集为15 000 张,验证集为4 000 张,测试集为4 000 张。其中,CrownHuman数据集的标注信息是.odgt文件,只采用其中vbox即可视人体的标注信息,将其转为COCO数据集所需要的json文件进行训练。
本节用AP、Parameters、FPS、GFLOPs、Latency等指标来对试验结果进行评估。AP是指在同一个类别、不同阈值和不同召回率下的准确率,AP越大证明模型准确率越高;Parameters是参数量所占内存空间,体现了模型的大小和复杂度;FPS是每秒所检测图片的数量;GFLOPs是指模型每秒执行多少次浮点数运算;Latency是指第一个输入到第一个输出所需要的时间延迟。
将本节算法结果YOLOv3、YOLOv5-S和优化前的YOLOX算法在CrownHuman数据集的可视身体框部分进行对比试验,试验结果见表1。
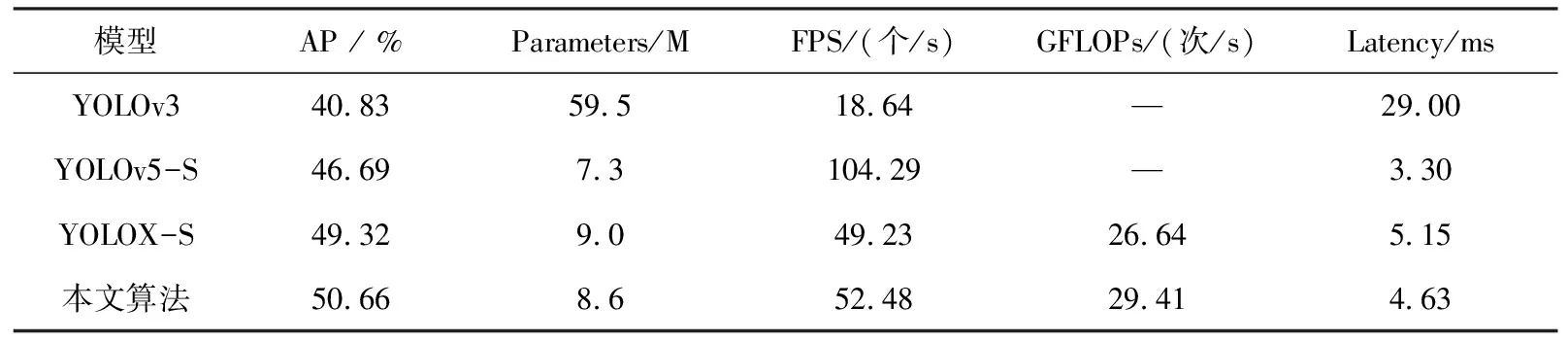
表1 CrownHuman数据集上的试验结果对比
由表1可以看出,本模型所优化后的YOLOX算法在CrownHuman数据集可视身体框部分的表现满足预期,其中,AP相对YOLOv3提高了9.83%,相对YOLOv5-S提高了3.97%,相对优化前的YOLOX-S提高了1.34%,参数量仅8.6M,比优化前少了0.3 M,较为轻量。而FPS虽然不如YOLOv5-S那么优异,但相较于优化前每秒提升了3帧左右,并且能够满足完成实时检测的要求。优化后的算法时延比优化前缩短了0.52 ms,时延包括了前向推理时间和非极大值抑制处理时间。
6.2 改进后的SPPE算法性能测试
本文人体姿态估计模型使用MsCOCO2017[15]数据集来进行训练,采用每个目标所有的关键点的平均AP即以KeyPointsAP为指标来对模型进行评估,该值越大,证明模型的准确率越高。将本节所训练的模型与Mask-RCNN、OpenPose、文献[16]等在COCO2017姿态测试集上进行对比试验,试验结果见表2。
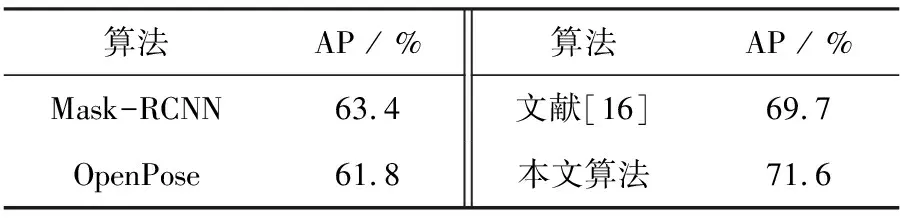
表2 COCO2017测试集上的结果对比
由表2可知,本文改进后的人体姿态估计算法在COCO2017测试集上AP比Mask-RCNN、OpenPose、文献[16]分别提高了8.2%、9.8%、1.9%,说明本文算法在准确率方面具有一定的优越性,能够提取更高质量的人体骨骼关键点。
6.3 基于图卷积的摔倒检测算法性能测试
本模型摔倒检测部分的训练数据是从Le2i[17]数据集中随机选取的100个视频,从这些视频中截取10 000帧图片,其中8 000帧用作训练集,2 000帧用作测试集。对每一帧图片使用改进后的Alphapose提取到pose,对这些pose信息进行人工标注,标定其人体状态,并保存为二进制文件。将属于不同类别的图片和标注二进制文件放入不同的文件夹中以待训练。采用准确率和FPS两个指标对本文的人体行为分类模型进行评估,准确率和FPS的值越大,模型越好。
在Le2i数据集上与做类似工作的文献[18]、YOLOv4-tiny+pose和YOLOv5-S+pose的结果进行比较,所得结果见表3。

表3 在Le2i数据集上摔倒检测结果对比分析
对比发现,本文所提出的基于改进的Alphapose结合GCN的摔倒检测算法, 在FPS优于YOLOv4-tiny+pose和YOLOv5-S+pose的情况下,准确率达到了92.2%,较好地满足了实时摔倒检测的要求。
7 结论
本文提出了一种基于改进Alphapose结合GCN的摔倒检测模型,该模型使用优化后的YOLOX结合DeepSort对视频中的人体目标进行目标检测、目标跟踪,得到每个人体的检测框,然后再使用改进后的SPPE对检测到的每个人体进行姿态估计,提取人体骨骼关键点,最后再使用GCN对人体骨骼关键点进行人体行为分类,判断是否摔倒。本文在CrownHuman、COCO2017、Le2i等公开数据集上分别对人体目标检测算法、人体姿态估计算法和人体摔倒检测算法进行对比试验,结果表明,本文所提出的摔倒检测模型在目标检测、姿态估计上的算法改进和整体的模型设计都具有可行性,并且比其他模型提高了检测的准确率和实时性,具有一定的使用价值。
