融合全局编码与主题解码的文本摘要方法
2023-05-08张志远
张志远 肖 芮
(中国民航大学计算机科学与技术学院 天津 300300)
0 引 言
近年来,深度学习在自动文摘上面的应用越来越火热,其中,序列到序列(Seq2Seq)作为一种主流的生成式摘要模型,它在“理解”原文的基础上生成摘要,取得了显著成就。但与语言翻译相比,由于原始文档和摘要之间无法直接进行短语对齐,系统必须全面准确地理解文档所表达的意思后再生成摘要,因此具有很强的挑战性,利用全局信息显得尤为重要。另外有研究表明,传统的注意力机制也存在一些问题,由于原文和目标摘要之间没有明显的对齐关系,可能导致编码器的注意力模块产生噪声。例如在表1的例子中,Seq2Seq生成的摘要中“选举”后面又生成了一个“选举”,这是因为无论这个词是否生成过,注意力机制会一直关注得分高的词,导致模型产生词语重复的问题。
另外,Seq2Seq模型倾向于包含原文中所有的信息,这可能导致错误地将注意力集中在无关主题上。在表2中,这篇文章的主题是林志颖旗下公司爱碧丽涉嫌虚假销售,而Seq2Seq生成的摘要中只提到了林志颖而没有涉及爱碧丽公司,但却包含了“成本仅每瓶4元”这样的具体细节,这对原文主旨的反映是不完整的。因此,在生成摘要时有必要确定一个主题信息来指导摘要的生成。

表2 例2
为解决上述问题,本文在Seq2Seq模型的基础上提出融合全局编码与主题解码的文本摘要生成方法,在编码器中有效加入全局信息,在解码器中充分利用能高度概括原文的主题信息。在LCSTS数据集上的实验数据显示,综合二者的模型在ROUGE-1、ROUGE-2和ROUGE-L上都有较大的提升。
1 相关工作
抽取式和生成式是两种最常见的自动文摘方法。Rush等[1]提出将序列到序列(Seq2Seq)模型应用于生成式摘要,该模型使用一个编码器(encoder)-解码器(decoder)的结构,其工作机制是先用encoder将输入编码到语义空间,得到一个固定向量作为输入的语义表示,然后再用decoder将这个向量解码获得输出。Bahdanau等[2]在Seq2Seq模型中引入了注意力机制,在生成每个词的时候,对不同的输入词给予不同的关注权重。输出序列的每个词都对应一个概率分布,这个概率分布决定了在生成这个词的时候,对于输入序列的各个词的关注程度,进而可以使生成的词“更好”。
编码方面,Zhou等[3]提出了带有门控的选择性编码模型并对编码器生成的词隐层进行权重计算,使解码器能够有选择性读取原文;Zeng等[4]提出的“再读(read-again)”模型用另一个GRU对原文再次编码而不是直接用权重更新当前词的隐层;Nallapati等[5]提出层级注意力模型并用序列到序列模型处理长文本摘要;Chen等[6]构造了CNN-LSTM句子抽取器和RNN生成器,两个都是Seq2Seq模型,并用强化学习训练如何抽取句子。
解码过程中,See等[7]提出混合指针生成网络,既能从原文中复制词,也能从词表中去生成词,并使用覆盖机制避免重复生成;Kingma等[8]提出解码器内注意力控制重复,将已生成的词隐层用于计算解码器语义向量;Li[9]等提出深度循环生成解码器(DRGD),把原文和摘要输入VAE模型进行训练,得到有潜在结构信息的向量;Perez等[10]提出基于目标摘要内容的结构化卷积解码器,在生成摘要时可以知道每一句话所涉及的主题以及它们在目标摘要中的位置,与Transformer模型效果不相上下。侯丽微等[11]融合主题关键词信息生成自动摘要,Amplayo等[12]利用维基百科识别文本主题,证明先验知识可以帮助模型更好地理解文本。
本文积累前人在编码器和解码器上的研究经验,借鉴Zeng等[4]和侯丽微等[11]的思想,提出融合全局编码与主题解码的Seq2Seq模型框架,试图解决传统Seq2Seq模型生成文本摘要时的重复和主题模糊等问题。不同的是,Zeng等[4]是先读一遍原文,将得到的隐藏状态作为全局特征向量并计算权重用于再次阅读,而本文的门控单元采用卷积和自注意力来筛选信息。侯丽微等[11]采用基于图模型的TextRank算法抽取主题关键词,而本文采用提取原文实体再编码的方法构建主题向量。另外,本文还有效融合了二者以达到更好的生成效果。
2 融合全局信息编码与主题信息解码的方法
2.1 整体流程
本文对基于Seq2Seq的文本自动摘要模型进行了以下优化:第一,添加全局信息编码GIE(Global Information Encoder)模块,在信息源端进行全局编码以实现核心信息的重用;第二,添加实体主题模块E2T(Entity2Topic),通过将原文中的实体编码为主题向量,并采用注意力机制,结合原文主题和实体常识指导解码器生成摘要。模型示意图如图1所示,主要包括基于BiLSTM的全局信息编码器、配备主题解码与注意力机制的LSTM解码器两部分。其中编码器按字读取输入文档,采用双向LSTM构建每个字的全局语义表示;全局门控单元首先通过多卷积核提取不同长度的短语结构信息,然后通过自注意力机制进一步筛选重要信息后提供给解码器。为获取有效的主题信息,使用BiLSTM+CRF提取原文中的实体,将其编码后的特征表示拼接在门控单元的特征表示之后,采用注意力机制在解码过程中关注重要的实体信息以指导解码器生成和原文主题相关的摘要。

图1 融合全局信息编码与主题信息解码的文本摘要生成模型
给定一篇文档D,其单词序列表示为D=(w1,w2,…,wd),其中,每个单词wi来自固定的词汇表V,d为文档的长度(字个数)。自动文摘就是输入原文序列D,输出摘要序列Y=(y1,y2,…,yn),通常情况下,输入文档序列长度d大于生成摘要序列长度n。

(1)
(2)
st=LSTM(wt-1,st-1,ct-1)
(3)
上下文向量ct是使用加性注意机制[2]计算的,它计算当前的解码器状态st和每个编码器状态hi的重要性评分gt,i,a(.)是前馈神经网络,然后送入softmax函数,最后采用加权求和得到上下文向量ct,计算方法如下面的公式所示(Va,Wa,Ua都是训练参数):
(4)
(5)
(6)
最终,当前字ot由上一个字yt-1,当前的上下文向量ct,以及当前解码器的隐藏状态st共同得到,并通过softmax从词汇表中计算当前要生成的字的概率p,公式如下(Ww、Wc、Ws都是可训练矩阵参数):
ot=Wwwt-1+Wcct+Wsst
(7)
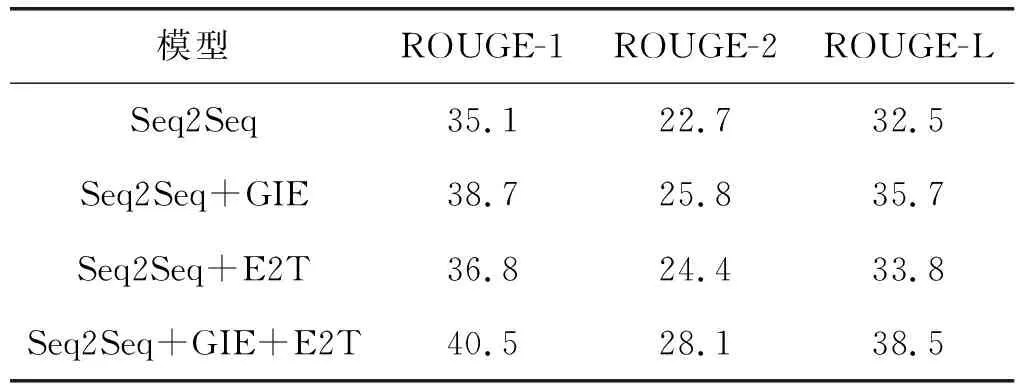
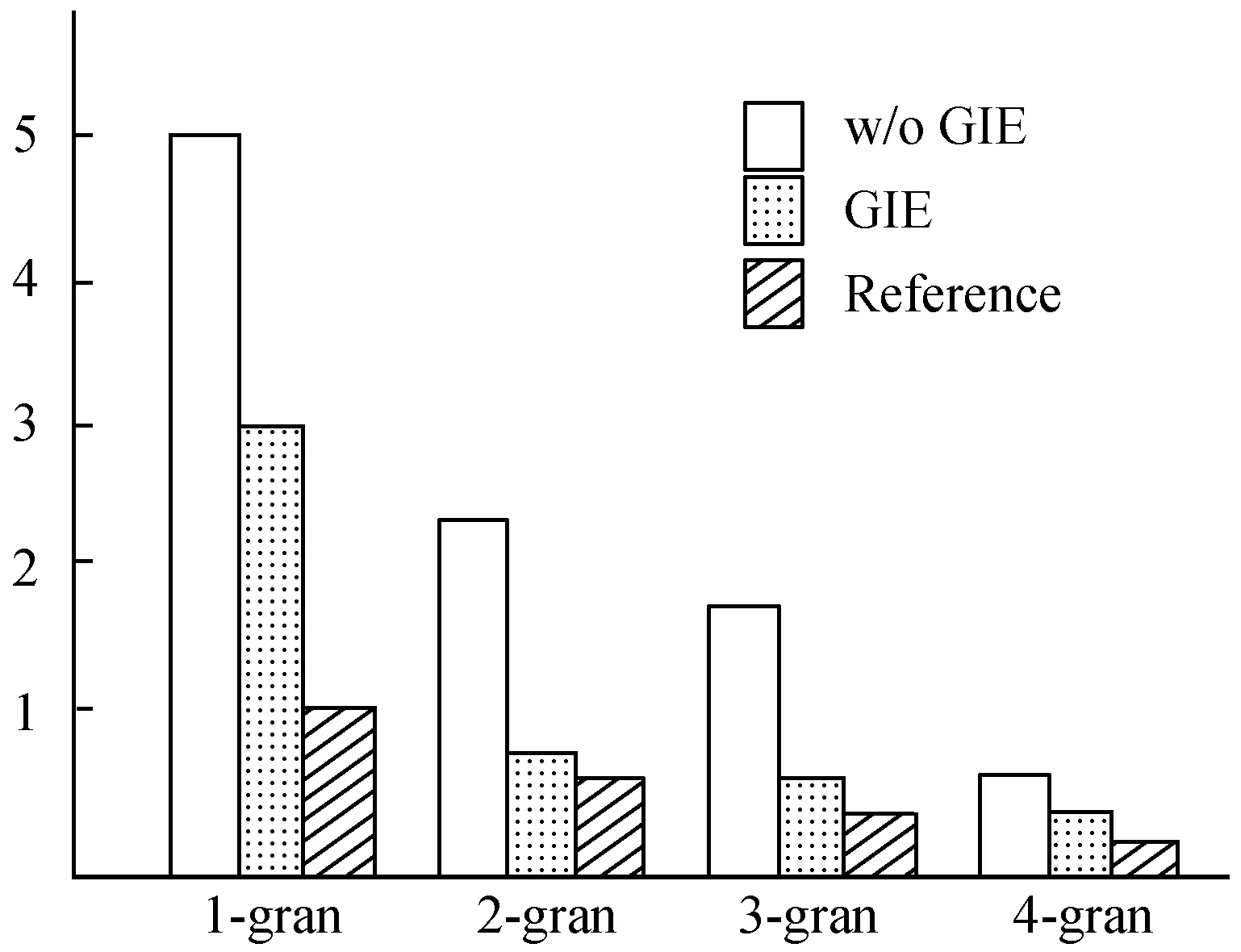
p(yt|y (8) 与即时信息一样,语言也存在局部相关性,卷积核的参数共享使模型能够提取这些N元特征,也就是短语结构;另外,Vaswani等[13]提出,自注意力可以通过挖掘当前时间步与每一步的相关性来加强全局信息。所以本文在Seq2Seq的encoder和decoder之间加一个全局信息过滤单元,包含卷积CNN结构和Self-attention机制,通过参数共享和综合全局信息过滤每个编码器的输出。具体步骤如下: 2.2.1 卷积提取N-gram特征 由于文本输入以字而非词为单位,为保证生成摘要的通顺性和连贯性,在采用双向LSTM全局编码字的隐藏状态之后设计一层CNN,由多个不同大小的卷积核组成,以获得多个与N-gram语言模型类似的特征。具体地,本文使用一个类似于Inception结构的网络如图2所示。 图2 卷积结构图 卷积网络结构采用1、3和5三种不同大小的卷积核来获取不同尺度的特征,最后把它们拼接起来能有效融合这些特征。选取k=5是因为希望数据的中间表示尽可能多地考虑上下文环境,但使用k=5的卷积核会带来巨大的计算量,所以用两个k=3的卷积核代替。在inception结构中,大量采用了1×1的矩阵,主要起两点作用:1) 对数据进行降维;2) 引入更多的非线性,提高泛化能力。卷积后要经过ReLU激活函数。 gi=ReLU(W[hi-k/2,…,hi+k/2]+b) (9) 2.2.2 自注意力挖掘全局信息 经过CNN获取短语结构之后,使用自注意力对这些表示做进一步筛选。输入一个句子,编码器最终输出的每个词都要和卷积后的所有词向量进行attention计算,目的是学习句子内部的词依赖关系和句子的内部结构。这样就能在避免重复生成的同时获取全局核心信息。采用缩放点积注意力[13]计算编码器每一个时间步的输出与卷积得到的全局信息的关系,把注意力表达成Q(query)、K(key)、V(value)三元组。其中Q是编码器每个时间步的输出,K和V是输入的文本序列经过编码和CNN卷积之后的表示矩阵。Q=WattV,Watt是学习矩阵,然后使用softmax函数对这些权重进行归一化;最后,将权重和相应的V进行加权求和得到融合自注意力之后的向量gglobal。在softmax计算之前,进行尺度缩放,除以维度dk,防止内积过大,公式如下: (10) 接下来就是计算基于CNN和自注意模块的门控单元筛选后的信息表示,其中σ是sigmod函数。其计算式为: (11) σ(g)在每个维度输出一个介于0和1之间的值向量。如果值接近0,则gate删除原表示的相应维度的大部分信息,如果接近1,则保留原表示的大部分信息。经过这两步,CNN模块可以提取原文的N元特征,自注意力能够学习词之间的依赖关系,因此该门控单元可对编码器输出进行全局编码。 (12) (13) (14) (15) (16) 摘要应反映原文的主要信息,而序列到序列模型则倾向于包含原文中的所有信息而不管其是否重要。这可能导致错误地将注意力集中在与摘要主题不相关的信息上。所以在解码生成摘要时,需要一个聚焦原文重要信息的主题来指导生成过程,本文试图寻找一个这样的主题向量。 (1) 经过大量对比和统计发现,大部分摘要除助词外,主要由原文中的实体组成。本文从文本摘要常用数据集的原文中提取出实体,发现大多数摘要中的名词短语至少包含一个原文中的实体,这证明原文的实体信息对摘要具有有效性。 (2) 通常在读一条新闻的时候,经常会用“谁在哪里做了什么”这样的结构来捕捉它所要表达的主要信息,当表示“谁”和“哪里”这样信息的实体都是十分重要的,所以原文中出现的人名、地名、组织机构这些实体对反映整个文本信息来说至关重要。 (3) 本文采用维基百科中文预训练向量嵌入实体,词向量含有百科相关信息,因此实体所具有的常识性信息也可供生成摘要时利用。比如,在“洛杉矶道奇在周三以四人交换的方式从纽约大都会队手中收购了韩国的右投手徐承载”这句话中,维基百科知道“洛杉矶道奇队”和“纽约大都会”都是美国著名的职业棒球队,“徐承载”是与棒球队有关的棒球运动员,这三个实体就具有相关性,就可以把这种信息传递给解码器并利用它来生成更加连贯的摘要。 为此,本文在序列到序列模型上添加Entity2Topic(E2T)模块。该模块对从原文本中提取实体进行编码,提取的实体包括原文中的人名、地名、组织名,将提取的所有实体按照在原文中的位置以及先人名再地名最后组织名的顺序输入到LSTM中进行编码,再解码构造一个表示要生成的摘要主题的向量。 本文使用基于字的LSTM+CRF来提取实体,主要参考的是文献[14-15],采用Bakeoff-3评测中所采用的BIO标注集,即B-PER、I-PER代表人名首字、人名非首字,B-LOC、I-LOC代表地名首字、地名非首字,B-ORG、I-ORG代表组织机构名首字、组织机构名非首字,O代表该字不属于命名实体的一部分。如:于大宝帮中国队获胜B-PER I-PER I-PER O B-ORG I-ORG I-ORG O O。 本文采用的实体提取方法在人名、地名、组织机构这三个类别的识别准确率都可以达到90%左右,可以证明提取实体的有效性。 (17) (18) (19) 本文按照原文长短确定提取实体的个数,接着用新的实体向量来创建主题向量t,该主题向量就表示摘要的主题。对实体向量使用软注意来确定每个向量的重要性值,这一步通过将每个实体向量与文本编码器中的文本向量作为上下文向量进行匹配来实现。然后使用加权求和的方式合并实体向量得到本文的主题向量(Ve,We,Ue都是训练参数)。其计算式如下: (20) (21) (22) 然后将主题向量t连接到解码器的隐状态向量: (23) 最后使用连接向量创建输出向量: (24) (25) (26) (1) 实验数据。LCSTS大规模中文短文本摘要公开数据集,共包含3个部分:Part1包含240万文本-摘要对,可用于训练模型生成摘要;Part2包含10 666个人工标注的文本-摘要对;Part3包含1 106文本-摘要对,文档的平均长度在98个字左右。在本文实验中,本文使用Part1作为训练集,Part2作为验证集,Part3为测试集。 (2) 实验环境如表3所示。 表3 实验环境 (3) 评价指标。ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是评估自动文摘的一组指标,它基于摘要中n元词(n-gram)的共现信息来评价摘要,ROUGE准则由一系列的评价方法组成,包括ROUGE-N(N取N-gram的N,取值有1、2、3、4)、ROUGE-L,是摘要评价方法的通用标准之一。 (4) 参数设置。部分参数设置见表4,本文使用PyTorch的代码,在NVIDIA 1080Ti GPU上进行实验。优化器选取默认的Adam,训练时从第4轮迭代开始学习速率减半。本文按字分割文本,这是因为数据集较大分词需要构建超大的词表,训练速度也会降低,生成摘要的时候还会生成大量未登录词。 表4 实验参数设置表 3.2.1 整体实验 为评估本文提出的模型在自动摘要任务中的表现,与其他自动摘要方法在同一个数据集LCSTS上进行了对比,ROUGE值如表5所示。 表5 LCSTS数据集上的实验结果(%) 表中的数据前六行是其他方法在相同数据集上的实验结果:(1) RNN[16]:没有注意力机制的Seq2Seq模型。(2) RNN-context[16]:有注意力机制的Seq2Seq模型。(3) copyNet[17]:添加拷贝机制的带注意力机制的Seq2Seq模型。(4) SRB[18]:改善源文本和摘要之间语义相关性的模型。(5) DRGD[8]:在Seq2Seq增加深度循环解码器学习目标摘要的潜在结构信息。(6) R-NET[19]:基于过滤机制的阅读理解模型用于文本摘要。可以看出:本文的模型效果比其他模型都好,比之前最好的R-NET模型在ROUGE-1、ROUGE-2和ROUGE-L也分别有2.7百分点、1.2百分点和2.0百分点的提升,说明本文提出的融合全局信息编码和主题信息解码的模型是有效的。 3.2.2 消融实验 为了分析不同组件对模型的影响程度,本文在基础的Seq2Seq模型上分别加入全局信息编码GIE模块和主题信息解码E2T模块并进行比较。实验结果如表6所示。其中seq2seq是有注意力机制的序列到序列模型复现的结果,四个模型使用的网络结构都保持一致。 表6 具有不同组件的模型性能(%) 从表中数据分析可知:相比Seq2Seq模型,Seq2Seq+GIE在ROUGE-1、ROUGE-2和ROUGE-L上分别有3.6百分点、3.1百分点和3.2百分点的提升,Seq2Seq+E2T在ROUGE-1、ROUGE-2和ROUGE-L上分别有1.7百分点、1.7百分点和1.3百分点的提升,这说明本文添加的两个模块对文本摘要任务都是有效的,且Seq2Seq+GIE比Seq2Seq+E2T的提升更明显,二者融合的效果更佳。 验证1:全局信息编码模块能有效利用全局信息降低重复率。由于本文的GIE负责从RNN编码器中选择重要的输出信息,以提高注意力分数的质量,因此它应该能够减少重复。本文通过计算句子层次上重复词的百分比来评价重复的程度。通过对1-gram-4-gram重复的模型的评估,证明该模型与传统的Seq2Seq模型相比,重复率显著降低,如图3所示,其中w/o GIE表示WithOut GIE,即不添加GIE模块的Seq2Seq生成的摘要;GIE表示Seq2Seq添加GIE模块生成的摘要;Reference表示参考摘要。 图3 句子中的N-gram重复率 验证2:E2T模块能通过提取实体有效聚焦主题。对引言中提到的示例进行实验并对生成的摘要作简要分析,如表7所示。 表7 例2添加E2T的生成结果 基线模型Seq2Seq生成了一个不完整的摘要。本文认为这是因为输入文本的长度较长,而解码器没有指导它应该关注哪些主题。Seq2Seq生成的是林志颖虚假推销,实际上文章的主题是林志颖旗下公司爱碧丽而不是林志颖本人;因为E2T会在原文中提取到林志颖和爱碧丽以及方舟子这三个实体,并将该信息作为整个文本的主题传递给解码器指导它生成摘要,所以最后生成的结果能够定位到虚假推销的主体是林志颖旗下公司爱碧丽以及推送这条消息的人方舟子,因此更准确地概括了原文主旨。这也证明了本文的E2T模块能通过提取实体聚焦到原文主题。 3.2.3 生成摘要示例 如表8所示,由于“中国”在原文中出现了两次,基线模型Seq2Seq很难把它放在一个不那么重要的位置,但对于本文的Seq2Seq+GIE模型来说,它能够过滤那些与原文的核心意义无关的琐碎细节,只是在对主要思想贡献最大的信息上进行关注,生成摘要中“中国贵75%”就是核心信息,但它没有指明是比哪里贵;而带有E2T模块的模型生成的摘要涵盖信息比较全面,能找到比对对象是“美国”的“星巴克”和“中国”的“星巴克”,摘要中出现的“星巴克”“美国”“中国”,以及消息来源“财经日报”都是它捕捉并利用的实体信息,可以看到参考摘要中也是有消息来源“媒体”的,但Seq2Seq+E2T生成的摘要比较繁琐;相比之下,二者结合生成的摘要与参考摘要更为接近。 表8 生成摘要示例 随着对模型研究的不断深入,序列到序列模型生成摘要的效果越来越接近人工生成的结果。本文提出的融合全局编码与主题解码的Seq2Seq模型也取得了较好的效果。虽然Seq2Seq模型还存在处理长文本效果欠佳、时间复杂度高等很多问题,但它仍是文本摘要研究方向上的引领者,之后可以继续在网络结构、多重注意力机制、适当引入先验知识等方面继续改善模型的学习能力,主要还是提高模型对原文的理解能力以及生成句子的质量。2.2 全局信息编码(GIE)


2.3 主题信息解码
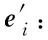


3 实 验
3.1 实验设置


3.2 实验结果对比与分析



4 结 语
