融合框架表示的汉语框架网词元扩充
2023-05-08任国华吕国英
任国华 吕国英 李 茹,2,3 王 燕
1(山西大学计算机与信息技术学院 山西 太原 030006) 2(山西大学计算智能与中文信息处理教育部重点实验室 山西 太原 030006) 3(山西省大数据挖掘与智能技术协同创新中心 山西 太原 030006)
0 引 言
语义知识库是自然语言处理中的基础资源,进行语义分析时需要借助语义知识库[1]。作为一种语义知识库,由山西大学2004年开始建立的汉语框架网(CFN)[2]可以在自然语言处理领域进行框架语义分析。CFN是由一些语言学框架组成的,框架是指跟一些激活性语境相一致的结构化范畴系统,是储存在人类认知经验中的图式化情境。框架语义学[3]认为,每个框架都代表着一个特定的语义场景,因此,可以根据语义场景的不同对词语进行分类描述。如果一个词语符合某个框架语义场景,就把它划分到这个框架。例如词元“出售”“售卖”和“零售”等被归入“出售”框架。已登录词是指已经被归入CFN框架的词,未登录词是指暂未被收录到CFN框架的词,CFN词元扩充就是为CFN已有框架收集未登录词,将语义相同的未登录词归入同一框架。
CFN词元库的构建主要是翻译FrameNet[4]已有词元然后通过手工查找汉语字典对某些框架下的词元进行调整补充,并不是对全部的汉语词语做框架语义描述。当使用CFN在大规模真实文本中进行框架语义分析时会出现未登录词,影响文本语义的完整性与准确性。虽然CFN已经应用在汉语句子相似度计算[5]、阅读理解答案句抽取[6]和汉语连贯性研究[7]等阅读理解的研究中,但是由于CFN语义资源的词元覆盖不全,CFN的应用严重受限。
为了缓解人工查找的局限性,本文将研究自动扩充CFN词元库的方法,提高CFN的覆盖率,从而扩大CFN的应用范围。目前CFN词元扩充任务主要通过以下两种框架选择方法解决。第一种是基于CFN框架分类的方法,利用传统机器学习的方法将未登录词根据框架的不同进行分类;第二种是词语相似度方法,利用词语相似度的方法计算未登录词和已登录词的语义相似度。然而随着CFN资源库的不断扩大,框架类别数也不断地增多,使用框架选择的方法难度较大。框架选择会涉及多标签问题,因为有的词语是多义词,可以被分配到不同的框架(如动词“打”可以被分配到“使产生身体伤害”“比赛”和“使产生冲击力”等框架)。框架选择方法不能自动获取未登录词,需要提前从开放文本中选取一批未登录词,实验结果受所选取的未登录词的影响较大。本文受第二种方法的启发,给定一个CFN框架以及该框架下的一个已登录词,为该框架扩充与已登录词语义相似并且符合该框架的词,从而避免了以上提出的框架选择的缺点。
本文采用如下思想解决CFN词元扩充问题:输入CFN已登录词在某一框架下的词典释义,输出字典中符合该释义的词语,实现CFN词元库的扩充。本文提出融合框架表示的CFN词元扩充模型,主要包括以下两个方面的贡献:
(1) 提出一种新的神经网络模型用于CFN词元扩充。
(2) 第一次将框架名向量融入模型,从而捕获词语和框架的相关性。
1 相关工作
英文相关研究主要以FrameNet词元库建设为代表。Johansson等[8]使用WordNet上位树分类方法为WordNet中的每个词设计了一个特征表示,并且为FrameNet每个框架训练了一个SVM分类器,最终在开放文本中获得68.80%的准确率。Pennacchiotti等[9]提出基于分布式模型和基于WordNet模型,并将这两种模型结合,最终在FrameNet数据集的Top10候选框架中取得78%的准确率。Das等[10]提出基于图的半监督学习方法。使用框架语义解析器对没有标签的数据进行语义角色标注,构造了一个以目标词为顶点的图,然后使用标签传播算法为新的谓词学习可能的语义框架,最终在真实语料中达到62.35%的准确率。Tonelli等[11]使用词义消歧系统进行FrameNet已登录词和维基百科页面之间的映射,自动利用维基百科的词汇扩充FrameNet词元库,最终在真实语料中达到40%的准确率。英文相关研究开始时间较早,研究人员众多,各种应用系统比较成熟,语义资源应用广泛。而中文方面相关研究较少,框架语义解析器、中文开放词网和中文维基百科等相关语义资源和系统的发展都不成熟,将以上方法直接用于汉语方面的研究较为困难。
中文相关研究主要以CFN的词元库建设为代表。贾君枝等[12]利用同义词林,提出了基于语义的向量空间相似度计算方法,利用基于视觉的网页数据表格定位算法对实验结果进行评估,最终在257个页面得到的准确率的平均值为85.35%。陈学丽等[13]利用同义词林,提出基于平均语义相似度算法和基于最大熵模型的未登录词框架选择方法,最终在开放文本的Top4框架中分别取得78.61%和70.90%的准确率。但是,当时CFN资源库的框架总数仅为180个,如今CFN的框架总数为1 313个,使用框架分类的方法难度较大。王军[14]提出基于HowNet和Word2Vec的词语相似度方法,并且在开放文本中分别获得70.38%和81.45%的Top4框架准确率。但是该方法仅限于小规模的词元扩充,方法过于简单。
2 融合框架表示的CFN词元扩充模型
本文提出的融合框架表示的CFN词元扩充模型如图1所示。模型主要由三部分组成:主模型、局部知识库得分和最终得分与损失函数。

图1 融合框架表示的CFN词元扩充模型结构
2.1 主模型
2.1.1 词嵌入
将每个词映射到一个高维的向量空间,本文使用预先训练好的词向量(在这里采用Word2Vec)得到定长的词嵌入。给定一个句子S={w1,w2,…,wi,…,wn},其中wi表示句子S中的第i个词,每个词wi的词嵌入表示xi见式(1)。
xi=ev×t(wi)
(1)
式中:ev×t表示词向量嵌入映射;v表示词表大小;t表示向量维度。
2.1.2 框架表示
框架名中包含丰富的语义信息,且框架名可以表示该框架所代表的语义场景,因此本文使用框架名获得框架的语义表示。本文将框架名当作句子进行处理,因为有的框架名字较长,如框架“惊讶发现某意外状况”“信息交流方式”等。本文使用双向LSTM作为句子编码器,它将一个句子编码为一个向量,具体见式(2)-式(5)。
(2)
(3)
(4)
(5)
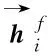
2.1.3 词典释义表示

框架语义学通过建立框架来解释词语的意义,框架与词语具有一定的语义相关性(如“出售”框架与词语“出售”“售卖”和“零售”语义相似)。本文使用词典释义表示词语的语义,框架名的语义代表框架,词典释义和框架名也有一定的相关性(如词语“零售”的词典释义“把商品不成批地卖给消费者”与框架“出售”语义相似)。同时,框架名与词典释义中的每个词的语义相关性具有一定的差异性。为了捕获这种相关性与差异性,本文在对词典释义表示时融入了attention机制,对于与框架名有较强相关性的词语,在进行高级向量表示时赋予较高的权重,具体计算见式(6)-式(8)。
(6)
式中:Wu1、Wu2和Wu3是可训练的参数;sf是框架名表示;ui是第i个词的attention权重。
接着,将ui归一化,使得同一个句子所有词的权重值相加为1,如式(6)所示。
(7)
最后的句子表示是输入序列中每个词的隐层向量的权重和,其计算式表示为:
(8)
式中:sd∈Re为最终的词典释义表示。
2.1.4 主模型得分
本文直接采用sum方式对词典释义和框架名进行融合,因为sum操作能利用两者的所有信息获得丰富的语义信息,具体计算见式(9)。
v=Sd+Sf
(9)
接着,将融合向量v映射到词向量空间,目的是为了与词典中的每个词计算相关程度。式(10)表示将融合向量映射到词向量空间,式(11)表示使用点乘操作计算c与词典中每个词w的相关程度。
c=Wcv+bc
(10)
Scorew,df=c·w
(11)
式中:Wc是权重参数,bc为偏置参数,均为可训练的参数,随机初始化并跟随模型优化;Scorew,df为已登录词词典释义对词典中每个词的主模型得分。
2.2 局部知识库得分
HowNet和同义词林等知识库已被证明能够有效提高NLP任务[15],故本文将HowNet和同义词林融入模型。
2.2.1 局部词林得分
同义词林[16]是梅家驹等按词义分类编著的类义词典,它将语义相似或者相关的词划分为一个类别。而CFN也是一个词汇分类词典,把语义相近或相关的词放入同一框架。本文假设CFN同一框架的词在同义词林的类别也相同(如“出售”框架下的“出售”“售卖”“零售”在同义词林中均属于“He03B01”),将同义词林中类别相同的词归入同一框架。本文首先计算输入释义对全部的同义词林类别的得分,然后计算词典中的词(同时也在同义词林中)在同义词林的局部得分,具体介绍如下。
本节设计一个层次预测器来计算词典中的词在同义词林的预测分数。每个词都属于层次结构的每一层中的某个类别。首先计算每一层的类别得分,如式(12)所示。
Scorecilin,k=Wcilin,ksd+bcilin,k
(12)
式中:下标k表示第k层;Scorecilin,k∈Rck表示输入释义序列对第k层每个类别的得分;ck表示第k层的类别数;sd是词典释义表示,Wcilin,k∈Rck×e是权重矩阵;bcilin,k∈Rck是偏置矩阵。
词典中的词在同义词林的最终预测得分就是各层分类的预测得分的加权和,如式(13)所示。
(13)
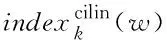
2.2.2 局部HowNet得分
在语言学中,义原是自然语言的最小语义单位[17]。一个词的义原集可以准确地表达出这个词的意思。HowNet[18]是面向义原的知识库。而CFN也是用来解释词语意义的词汇语义知识库,框架可以描述词语及句子的语义[19]。本文假设同一框架的词,义原相同或相似(如“出售”框架下的“出售”“售卖”“零售”在HowNet中均有义原“卖”),将义原相同的词归入同一框架。本文首先计算输入释义对全部义原的得分,然后计算词典中的词(同时也在HowNet中)在HowNet的局部得分,具体介绍如下。
首先将词典释义的每个隐藏状态传递给一个单层感知器,如式(14)所示。
(14)


(15)
式中:j表示第j个义原;[Scoresem]j表示输入序列对第j个义原的得分。
词典中的词w在HowNet的得分计算式如式(16)所示。
(16)
式中:s表示w的义原;indexsem(s)表示s在所有义原的索引值;[Scoresem]indexsem(s)表示词典中的词w对应的义原得分。式(16)表示将词典中的词对应的义原得分相加得到该词的得分。
2.3 最终得分与损失函数
将主模型得分Scorew,df和两个通道的得分Scorew,cilin、Scorew,sem求加权和,得到最终的词典中每个词的得分,如式(17)所示。
Scorew=λdfScorew,df+λcilinScorew,cilin+λsemScorew,sem
(17)
式中:λdf、λcilin和λsem是控制相关权重的超参数。
本文使用交叉熵损失函数作为该模型的损失函数。
3 实 验
本文使用PyTorch实现模型结构,所有实验在NVIDIA GeForce GTX 1080上运行。
3.1 数据集与评价指标
本文使用现代汉语词典(第6版)抽取的69 000个词的释义作为训练集。对于现代汉语词典中的每一个词,如果该词属于CFN已登录词,就在训练集中添加对应的CFN框架标签。测试集是CFN数据库的已登录词。
词典编纂任务中需要较高的准确率、,因此本文选取准确率P对实验结果进行评估。在专家进行人工确认的基础上,只要输出的结果能和对应的测试集输入的已登录词归入同一个框架,就代表结果正确,计算如式(18)所示。
(18)
式中:C表示结果正确的词语个数;M表示总的输出个数。TopN对应的概率表示前N个结果的准确率。
3.2 实验设置
本文参数设置如表1所示。

表1 参数设置
3.3 实验结果与分析
3.3.1 比较实验与结果分析
为了验证本文方法的有效性,设计了以下六个实验,实验结果如表2所示。

表2 不同方法实验结果(%)
前四种方法都是词语相似度方法,计算已登录词和词典中每个词的词语相似度,然后将词典中的词按照相似度值排列。第五种方法是反向词典模型。
(1) W2V-Ws:王军[14]提出的基于Word2Vec词向量模型的未登录词框架选择方法。
(2) HowNet-Ws:王军[14]提出的基于HowNet语义词典的未登录词框架选择方法。
(3) Cilin-Ws:朱新华等[20]提出的基于词林的词语语义相似度计算。
(4) HowNet-Cilin-Ws:将以上基于词林和基于HowNet词语相似度计算方法结合。
(5) Multi-Channel:Zhang等[15]提出的多通道反向词典模型。
(6) F-CS-BiLSTM:本文方法。
由表2可以看出:
(1) 本文方法都明显优于其他方法,说明本文方法可以有效地实现词元扩充。
(2) W2V-Ws、HowNet-Ws和Cilin-Ws三种方法实验结果较低,主要原因是这三种方法仅仅利用了词信息,从而无法捕获更多的语义信息,导致准确率较低。HowNet-Cilin-Ws将三种方法进行融合,从而提高了实验结果。
(3) Multi-Channel和F-CS-BiLSTM方法相对于其他方法的准确率更高,说明词典释义的上下文信息对CFN框架词元扩充是有效的。
(4) F-CS-BiLSTM方法的准确率优于Multi-Channel方法,说明F-CS-BiLSTM方法能够有效地捕获框架与词元的相关性,提高了实验结果。
3.3.2 框架信息对实验结果的影响
为了证明框架信息的有效性,设计了以下对比实验,实验结果如表3所示。

表3 有无框架实验结果(%)
(1) CS-BiLSTM:无框架信息,其他保持不变。
(2) F-CS-BiLSTM:有框架信息。
由表3可以看出,加入框架信息显著地提高了实验结果,说明了框架信息的有效性。如“探悉”属于CFN框架“获知”下的已登录词,“探悉”的词典释义为“打听后知道”,既包含打听的语义又包含知道的语义,CS-BiLSTM方法输出的结果为“打探”“探听”等,预测结果侧重于打听的语义,无法归入“获知”框架。加入框架信息后,该词预测的实验结果为“获知”“知晓”等,可以与“探悉”归入同一个框架。
3.3.3 融合方式对实验结果的影响
本文分别对词典释义向量和框架名向量使用了max操作、门控机制和sum操作,实验结果如表4所示。

表4 不同融合方式实验结果(%)
(1) F-CS-BiLSTM-Max:对词典释义向量和框架名向量对应维度求最大值。
(2) F-CS-BiLSTM-Gate:使用门控机制对词典释义向量和框架名向量加权求和。
(3) F-CS-BiLSTM-Sum:将词典释义向量和框架名向量对应维度相加。
由表4可以看出,F-CS-BiLSTM-Max方法的实验结果最低,是因为Max操作选择了只选了词典释义和框架名中值最大的,利用了较少的信息。F-CS-BiLSTM-Sum方法明显优于其他两种方法,主要是因为Max操作和门控机制只利用了词典释义和框架的部分信息,而相加操作利用了两者的全部信息,从而融合了更丰富的语义信息,提高了实验结果。
3.3.4 不同知识对实验结果的影响
为了证明知识库的有效性,设计了以下对比实验,实验结果如表5所示。

表5 不同知识实验结果(%)
(1) F-BiLSTM:不加任何知识,只加入框架信息,其他与本实验一致。
(2) F-C-BiLSTM:只加入词林和框架信息,其他与本实验一致。
(3) F-S-BiLSTM:只加入HowNet和框架信息,其他与本实验一致。
(4) F-CS-BiLSTM:加入词林、HowNet和框架信息。
由表5可以看出,F-S-BiLSTM、F-C-BiLSTM和F-CS-BiLSTM三种方法都优于F-BiLSTM方法,说明加入知识库的有效性。加入了同义词林和HowNet的F-CS-BiLSTM方法达到了最好的效果,说明加入词林和义原知识能够融合更多的语义信息,从而提高实验结果。
3.3.5 案例分析
为了说明本文方法的有效性,以“询问”框架的已登录词“探问”为例,使用W2V-Ws、Multi-Channel、F-CS-BiLSTM方法的Top10实验结果如表6所示。(阴影部分为正确结果)。

表6 案例

续表6
可以看出,本文方法Top10正确的词语最多,说明本文方法对词元扩充任务是有效的。已登录词“探问”的词典释义中既包含试探的语义,又包含询问的语义,只有包含询问语义的词才能归入该框架。W2V-Ws和Multi-Channel的Top10实验结果有很多词只包含试探的语义,如“试探”“揣测”和“斟酌”等,不能归入“询问”框架。本文方法的Top10实验结果中没有该类词语,说明加入框架信息以及attention后,机器对于释义中与框架名不相关性的词语赋予较低的权重,而对与框架名相关的词语赋予较高的权重,从而输出包含“询问”语义的词。
4 结 语
本文提出一种融合框架表示的汉语框架网词元扩充方法,通过结合BiLSTM、注意力机制、框架定义、Hownet和Cilin扩充词元,充分发挥各网络模型和知识库的优势。本文将框架名向量融入模型,从而捕获词语和框架的相关性。实验结果表明,本文方法达到了最好的效果,验证了本文方法对CFN词元库扩充的有效性。但是本文仅仅使用了汉语词典中的词语,未来考虑扩大词典大小。另外,本文方法仅仅通过词典释义判断词典中的词能否归入框架,没有考虑词语所在例句是否符合框架语义场景。下一步可以考虑在模型中加入例句,进一步判断实验结果的准确性。
