基于XGBOOST特征选取的LSTM模型评估股票走势分析
2023-05-08张训韬范永胜
张训韬 范永胜
关键词:XGBOOST;LSTM;特征排名;股票预测
自1990年沪深两大证券交易所开市以来,中国股市蓬勃发展。中国证券登记结算有限责任公司于2022年2月披露,中国股民占全总人口七分之一,突破2亿[1]。可见,随着经济的快速发展,人民的可支配收入显著提高。除去日常开销外,越来越多的人选择股票投资来实现剩余资金的最大价值。虽然A股投资者大量增加,但投资者投资的技术水平参差不齐。陈兴松等研究者发现A股投资者中,小散户数量远远大于专业机构投资者[2]。大量散户投资理念不成熟,有较强的从众心理,无法很好地利用历史数据对股票走势进行分析判断,更倾向于追涨杀跌。盲目投资的结果往往是亏损,更有甚者倾家荡产。因此,通过一定的技术手段指导股票买卖,规避买家主观的无效抉择是很有必要的。
1 研究综述
学者为了让投资者方便地看出股票的未来趋势,研究了很多的技术指标。传统的技术指标预测法主要将K线图和KDJ,MADC等技术指标结合来预测股票走势,带有一定的主观性,且很难分析出多维数据间的关联。统计学预测法处理线性问题具有一定优势,Li等应用统计学的ARIMA模型预测了股价的变化趋势[3]。但随着机器学习和深度学习在非线性预测问题上取得了卓越表现,研究者们把研究股票预测问题的重心转移到了机器学习和深度学习上。机器学习预测法一般就是把时序问题转换为监督学习,通过特征工程和机器学习方法去预测。Hassan提出了一种结合隐马尔可夫模型和模糊的方法预测股票,其预测的精度远高于普通隐马尔可夫模型和ARIMA 模型[4]。Wei等引入了最小二乘支持向量机(LS-SVM) 预测股票,通过动态惯性权重粒子群(W-POS) 优化参数,其训练速度优于SVM,预测结果优于BP神经网络[5]。机器学习在股票预测上取得了一定成就,但是股票作为时序数据,机器学习忽视了数据的前后关系。目前,研究者热衷于用深度学习,尤其是LSTM模型训练时序数据。Lstm在处理非线性问题上效果良好,三个门实现了对时序数据的保护和控制,并且解决了rnn长期和梯度消失的问题。Althelaya利用标准普尔500指数评估变种LSTM模型和GRU模型。实验表明叠加的LSTM的体系结构有更好的预测性能[6]。有了成熟的预测模型,需要考虑的是特征的选取。充足的技术指标可以让预测结果更准确,但可作为模型输入数据的金融技术指标已有上百种,若将所有的指标应用于股票预测势必会降低算法运行效率和增加模型复杂度。现有的降维算法很多,主要分为特征提取和特征选择两大类。特征提取通过训练分析原有特征,提取出新的特征,且这些新的特征并未包含于原特征中,其中代表的算法就是主成分分析。而特征选择主要是将原有特征按重要性排序,最终筛选的特征是原有特征的子集,代表算法有遗传算法和决策树算法。本次研究是选择后者中的XGBOOST算法选择特征,选择排名靠前的金融指标训练LSTM模型,达到预测未来股价的目的。
2 理论基础
2.1 XGBOOST 模型
XGBOOST(极值的梯度提升树)是陈天奇等人提出的一种基于树构造的算法,其构造思想和GDBT(梯度提升决策树)大致相同,只是在其功能上进行提升,两者都是属于boosting方法[7]。这种算法的构造原理集成多个弱分类器形成一个强分类器。XGBOOST不停地迭代,且每次生成的新树都拟合了前一棵树的残差,迭代的次数越多,训练的精度越好。增强学习的构建模型如下所示:
其中:n表示总共构建的决策树个数,xi 代表输入的特征值,F为所有生成决策树的集合,ft 是单棵决策树的训练函数,yi 则表示最终的预测值。每一棵树对应的ft 都包含了一种特征值和叶节点值的对应关系。为了更好地阐述XGBOOST树与弱学习树的关系和更好的训练模型,我们定义了如下的目标函数:
其中:yi 是预测结果,yi 表示真实值或者标签,(1)是预测结果和实际情况损失函数的简单表示。(2)是一个正则化项,是每棵树复杂度之和。fk 依旧表示的是第k棵树的模型,T是每棵决策树的叶子节点数目,ω是每棵树叶子节点分数,γ和λ代表着系数,用于保证叶节点分数和叶结点个数不会太大。通过正则化的引入,防止了勾结树的过程中过拟合的情况出现。
2.2 XGBOOST 重要性排名
其中X 是分类到每个叶节点的集合,Gainx 是每个节点的增益,Coverx 是每个节点上的样本数目。
2.3 LSTM 模型
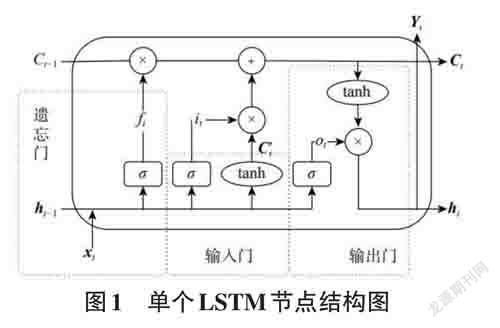
LSTM一共包含三个门控单元,即遗忘门,输入门和输出门。通过三个门更新参数和实现“记忆”功能,并通过引入“记忆细胞状态”对其进行长期保存[8]。
LSTM状态由图1所示。
1) 遗忘门。遗忘门通过选择性地抛弃上一时刻的数据,决定了上一时刻有多少信息可以保留在当前时刻。其公式如下:
3 实证分析
3.1 实验流程与实验环境
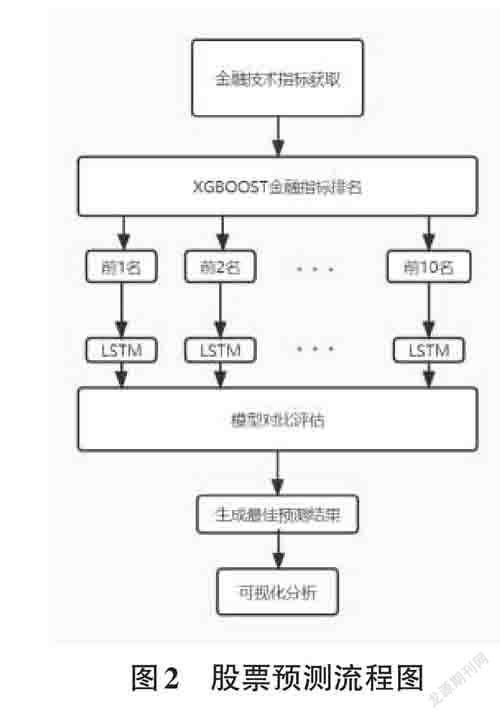
1) 获取目标股票的金融指标,通过XGBOOST重要性分析,求得这些金融指标的排名。2) 选择排名将靠前的十个指标做成多组组合数据训练LSTM模型。3) 利用均方差等指标对模型进行评估,选出最佳的指标组合,并通过最佳组合数据预测股票。4) 利用可视化分析工具对比最佳组合的预测值和真实值的差距。实验流程图如图2所示。本文选用Python3.7,Tensor⁃flow2.3.0,和Sklearn0.22.1的语言环境,通过交互式笔记本jupyter_notebook 实现编译。操作系统是Win⁃dows10。硬件方面是10 代inter-CORE-i7 搭配一块NVIDIA-RTX2060。
3.2 數据选取
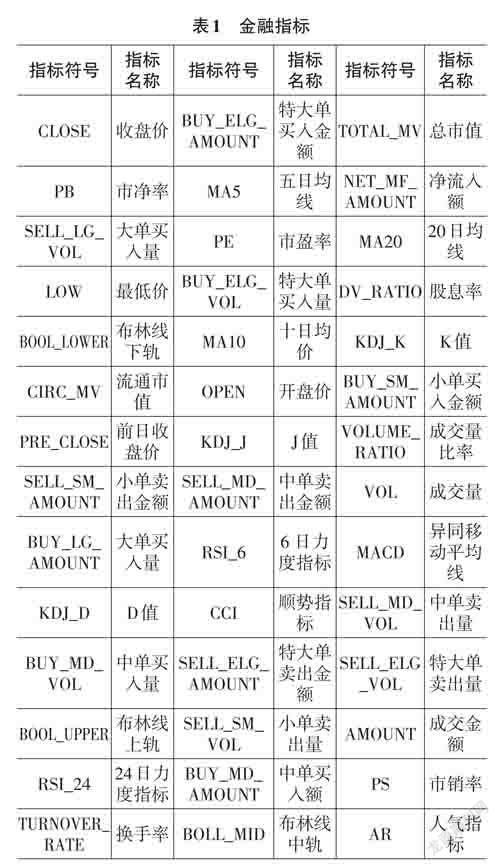
Tushare是一个免费、开源的Python财经数据接口包。主要实现对股票等金融数据从数据采集、清洗加工到数据存储的过程,能够为金融分析人员提供快速、整洁、和多样的便于分析的数据。本次研究的金融数据依托于该接口包,通过对应的API 采集了2017-8-1至2022-8-1的某股票5年1237个交易日的股票数据。在以往的研究中,研究者们希望通过修改算法提高股票预测的准确率,在金融指标的选择上仅仅依赖常规五项指标,即开盘价,收盘价,最高价,最低价和成交量。本次研究通过金融接口直接提取和人工编程计算,在常规五项指标基础上,将金融技术指标扩展到42项。所有指标汇总如表1所示。
3.3 数据归一化处理
金融属性取值范围很大,若直接用于预测模型训练,程序运行收敛很慢。通过归一化处理,可加快收敛。具体的公式如下:
归一化以后的数据虽然方便模型训练,但该模型预测的值也是归一化的状态,为了方便预测值和真实值比较,还要对预测值进行反归一化处理。具体公式如下:
其中,x 是真实值,x'是归一化以后的值,max(x)和min(x) 分别代表最大值和最小值。y'代表归一化的预测值,y 代表反归一化后的预测值。
3.4 XGBOOST 特征选择
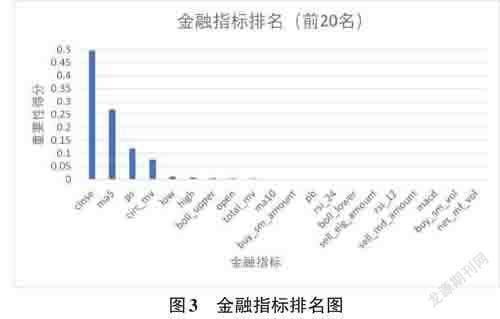
以每日42个金融属性作为输入,第二日收盘价作为输出构建决策树。借助于第三方库XGBOOST下的feature_importances_方法对属性打分。该方法首先借助GINI系数求得各个属性重要性,再将所有重要性做归一化处理,最后依据重要性对特征进行排名。排名前二十的属性如图3所示。
其中对第二日收盘价影响最明显的是前一日的最收盘价,五日均价,市销率,流通市值,最低价和最高价。由图可知,排名靠后特征对收盘价影响太小,本研究仅保留排名前十的特征。通过累加属性种类,将前十的属性分为十组。如:第一组一个属性,第二组两个属性,以此类推。将十组属性分别投入到LSTM,通过预测结果对比找到最优的金融属性预测组合。
3.5 LSTM 模型构造
首先需确定LSTM的输入数据类型。本次研究将通过前5天金融指标对第6日的收盘价进行预测。原始的数據包含了一年内所选股票1237个交易日的42个金融指标,其张量的维度为(1237,42)。若将连续5天数据作为一个输入单元,则整个数据输入张量的维度变为(1232,5,42),对应的标签张量维度为(1232,)。所以,根据我们所选的属性个数知道模型的训练数据张量维度为(1232,5,X),5代表前五天的数据,X代表所选择的金融属性个数。
整个股票预测模型采用了两层LSTM和一个全连接层来构造,每个LSTM层各有64个神经元。为了防止过拟合的出现,每个LSTM层后面添加了一个失活率0.2 的Dropout 层。LSTM 层的激活函数选择的‘relu’,优化器选择的是‘adam’,损失函数选择的是均方差‘mse’。
将排名前十的属性分为十组,第一组包含排名第一的属性所有数据,第二组包含排名前二属性的所有数据,以此类推。将每一组数据放入LSTM 中,batch_size设置为32,每一组数据训练100次。
3.6 预测结果分析
本次实验通过MSE,MAE 和R2 作为模型好坏的评价指标。三个评价指标公式如下所示:
其中m 代表预测值数目,yi,yi 和yˉ分别代表真实值,预测值和平均值。其中MSE,MAE 越小预测误差越小,R2越接近1说明模型拟合效果越好。
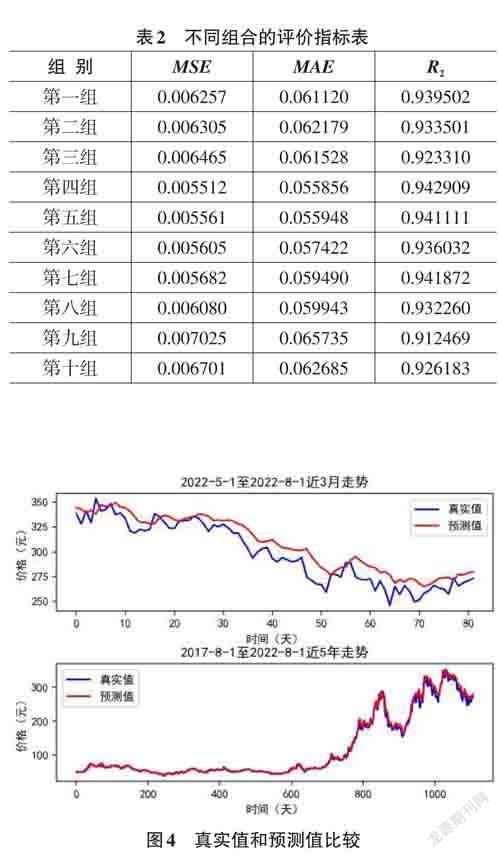
用十组组合数据训练LSTM,每一组数据分别训练十次,取十次指标的平均值作为该组的评测指标。十组指标如表2所示。
由表2可知在包含开盘价,五日均价,市销率和流通市值四个金融指标的第四组数据训练结果中MSE值和MAE 值最小,且R2值最接近1。该组模型的预测效果最好。用第四组指标预测数据并与真实数据进行可视化分析,近三个月和近五年的对比结果如下图4所示。
从上图可知,近来三个月预测数据和真实数据略有偏差,但价格走势基本一致。近五年的预测值走势和实际价格走势完全重叠。这表明用排名前四的金融指标训练的LSTM模型对长线交易有一定的指导作用。
4 结论
为了找到预测股票收盘价的最佳金融指标组合,本文提出了一种结合XGBOOST和LSTM的股票预测方法。利用某股票五年的历史数据进行实验,结果表明以前五日开盘价,五日均价,市销率和流通市值为组合的金融数据预测第六日的收盘价效果最好。因此本文提出预测方法对股民判断股市价格变化有一定的作用。
本次研究的重心是寻找预测股票走势的最佳金融指标组合。虽然得出了有一定参考价值的结论,但还存在一些可进一步研究的方向:
1) 本次研究未能对预测的LSTM参数进行优化。比如未曾通过优化算法寻找适合本次算法的最佳神经网络层数和每层神经网络的神经元个数,而是直接地指定这些参数。在后续研究中,可以进一步调整和优化模型,使得预测结果更加准确。
2) 这次使用的模型中未曾考虑市场情绪对股票的影响。在后续的研究中,可以尝试加入股民的情绪因子作为输入指标帮助预测。这样可以提高预测的精度和时效性。
3) 本次研究的模型,对于长期走势的判断基本吻合,但短线的效果吻合度仍然不理想。
