基于多层卷积神经网络的人脸表情识别方法
2023-05-08曾晴曾小舟申静
曾晴 曾小舟 申静
关键词: 表情识别;卷积神经网络;数据增强;MTCNN;人脸检测
0 引言
表情作为人类重要的情感表达方式之一[1],目前正成为新的研究热点,人们希望通过研究人脸表情识别方法来实现计算机获取人类表情的功能。具备表情识别功能的计算机设备能提高人机交互体验,高效地解决更多实际问题并满足更多的生活需求。例如:及时掌握驾驶员的情绪状态,减少交通事故;监控老人和婴幼儿的情绪状态,及时掌握其身体状况,提高生活质量;实时掌握远程教学过程中学生的上课状态,提高教学效果等。
卷积神经网络具有局部感知和权值共享的特点以及强大的特征提取能力,更适合于表情识别领域的应用[2-7]。李冠杰等人[8]提出一种基于深度卷积神经网络的表情识别方法,实验结果说明基于卷积神经网络的面部表情识别方法优于传统方法;赵彩敏等人[9]将一种改进的LeNet-5卷积神经网络应用于人脸表情识别,在JAFFE表情数据集上的仿真结果表明,在数据集样本很小的情况下,该方法的识别率达到了79.81%。魏赟等人[10]提出了一种引入注意力机制的轻量级CNN通道和卷积自编码器预训练通道的双通道模型,在FER2013和CK+两个表情数据集上分别取得了较高的识别率;王军等人[11]提出一种双通道遮挡感知神经网络模型,用于解决面部遮挡情况下特征提取难的问题,在CK+、RAF-DB、SFEW 3个表情数据集上进行对比实验,其识别准确率分别达到97.33%、86%和61.06%,有效提高了面部遮挡情况下的表情识别精度。
1 數据预处理
1.1 数据增强
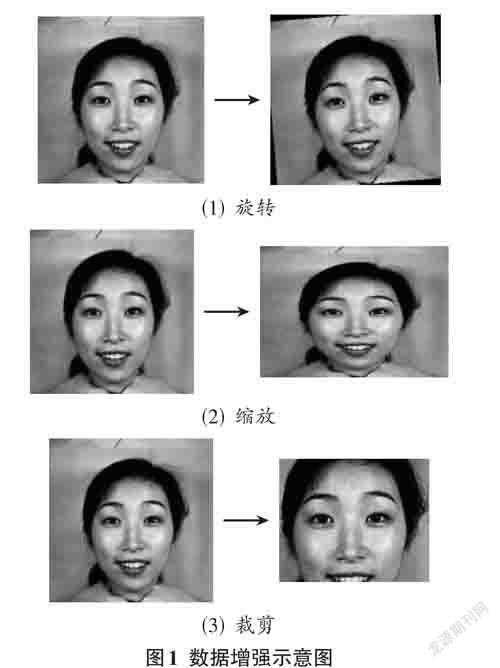
人脸表情数据集大多数据量较小,而多层卷积神经网络的复杂度较高,直接将人脸表情数据集中的图像作为输入,容易出现过拟合的情况,不能训练出适用性强的样本。为了解决这个问题,本文采用了数据增强的方法,即通过对原始图像进行裁剪、旋转、缩放等操作获得大量新的图像,用以扩增数据集,使表情识别模型所能学习到更多特征,从而增强算法的鲁棒性。
本文中数据增强的具体操作包括:将原始图像逆时针旋转5度、缩放成260×180大小、按左上角坐标(50, 60) 和右下角坐标(220, 200) 进行裁剪。如图1所示,以JAFFE 数据集中表情图像为例,进行数据增强操作。
1.2 人脸检测和剪切[12]
为了提高人脸识别的准确率,去除人脸表情以外信息的干扰,在将人脸图片输入训练模型和预测模型之前,先对图片进行人脸的检测和剪切。本文选用MTCNN(Multi-task Convolutional Neural Network,多任务卷积神经网络)实现人脸检测和剪切。MTCNN主要分为P-Net、R-Net和O-Net三层网络结构。具体来说,基于MTCNN的人脸检测和剪切实现流程如图2所示。
1) 将输入的图像按照不同的缩放因子进行不同尺度的变换,依据图像大小生成图像金字塔,从而实现检测不同大小的人脸图像。
2) 通过浅层的全连接卷积网络P-Net(ProposalNetwork) 快速产生人脸候选检测框。将上一步的图像金字塔输入P-Net中的三个卷积层后,通过人脸分类器初步判断所输入图像是否包含人脸,同时使用边框和定位器将初步判断所得的人脸区域和面部关键点进行定位,并输出判断所得的所有可能的人脸区域边框,且将结果输入R-Net,即下一步进行处理。
3) 通过比P-Net结构较为复杂的卷积网络R-Net(Refine Network) ,对上一步输出的多个候选人脸区域框进行精选,删除大部分效果较差的人脸区域框,留下极小部分可信度较高的人脸区域框。该层结构主要是卷积神经网络,与P-Net相比增加了一个全连接层,所以具有更为严格的数据筛选标准,可以对输入的人脸区域框进行细化选择,并再次使用边框和定位器进行人脸边框定位,将结果输出给O-Net,即下一步进行处理。
4) 通过比R-Net 结构更复杂的卷积网络O-Net(Output Network) ,对上一步结果进一步筛选,得到最终的人脸区域框和面部特征点坐标。O-Net比R-Net多了一个卷积层,它的输入图像特征更多,能对输入信息再次进行人脸判别、人脸边框定位和人脸特征点定位,最终输出人脸区域框的左上角坐标、右下角坐标以及人脸的五个特征点(左眼、右眼、鼻子、左嘴角和右嘴角)。
5) 根据上一步的人脸区域框坐标结果,对原始图像进行剪切,得到人脸区域框包含的人脸部分图像。
2 基于多层卷积神经网络的人脸表情识别方法
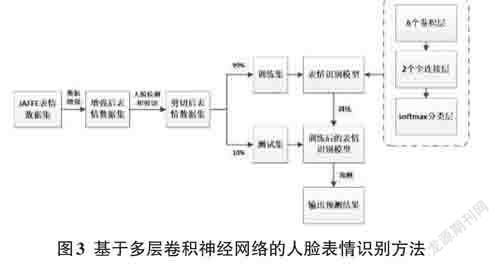
本文提出的基于多层卷积神经网络的人脸表情识别方法如图3所示,具体步骤如下:
1) 选择数据集:本文选取JAFFE 表情数据集,输入多层卷积神经网络中进行训练。JAFFE 表情数据集共213张图像,包含了10个日本女学生的7种面部表情:Angry(愤怒)、Disgust(厌恶)、Fear(恐惧)、Happy(高兴)、Sad(悲伤)、Surprise(惊讶)和Neutral(中性)。
2) 数据预处理:首先对JAFFE表情数据集中的图像进行数据增强,包括裁剪、旋转和缩放操作,得到增强后的表情数据集,从而提高模型的学习能力;然后基于MTCNN实现人脸检测和剪切,将剪切后得到的人脸图像作为表情识别网络模型的输入,从而去除多余的干扰。本文在预处理后的图像数据集中随机选取90%作为训练集,10%作为测试集。
3) 设计表情识别网络模型:本文设计的用于人脸表情识别的多层卷积神经网络模型共包含8个权重层,即6个卷积层和2个全连接层。其中,卷积层的第1、2层分别使用3个卷积核,每个卷积核大小为3×3,卷积层的第3、4层分别使用4个卷积核,每个卷积核大小为3×3,卷积层的第5、6层分别使用5个卷积核,每个卷积核大小为3×3;池化层采用最大池化,窗口大小为2,步长为1;两个全连接层的节点数分别设置为512和64;最后通过Softmax分类层进行分类,得到7种表情的预测结果,模型结构如图4所示。
4) 训练表情识别网络模型:将第2步得到的训练集输入第3步设计的表情识别模型进行训练,得到训练后的表情识别模型。
5) 人脸表情预测:将第2步得到的测试集输入第4 步训练后的表情识别模型,进行预测并输出预测结果。
3 实验
本文实验基于Python语言和TensorFlow平台,在JetBrains PyCharm 集成开发环境下实现。笔者将JAFFE人脸表情数据库的图片共213张进行压缩、剪切、旋转后得到增强后的图片,加上原来表情库中图片一起共818张,其中90%的图片用于模型训练,10%的图片用于预测,即训练图片736张,预测图片82张。训练时,选择优化器Adam,誤差函数categorical_cros⁃sentropy,迭代次数100,学习率0.005,激活函数选择Relu。
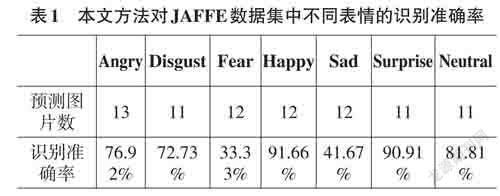
预测结果如表1所示,其中高兴的预测准确率为91.67%,惊讶的预测准确率为90.91%,中性的预测准确率为81.82%,愤怒的预测准确率为76.92%,厌恶的预测准确率为72.73%,效果较好,而恐惧和悲伤的预测准确率都低于50%,效果不理想。主要原因包括:1) 本文方法将JAFFE表情数据集进行数据增强后得到的表情数据集作为输入,能提高模型的学习能力,另一方面,基于MTCNN对输入图像进行人脸检测和剪切,去除了多余的干扰;2) 本文设计的多层卷积神经网络模型对于所输入的数据集,能够较好地提取出相应的表情特征,所以大多数情况能很好地识别出人脸表情;3) 恐惧和悲伤的表情特征相对于其他几种表情来说不够明显,提取难度更高,所以实验得到的预测准确率较低;4) 要获得更高的表情识别率,一是要从数量角度和多样性角度进一步丰富输入的表情数据集,二是要设计出更合适的神经网络模型,能够提取出更多有效的表情特征,从而提高整体的表情识别能力。
4 总结
人脸表情识别功能可以提升智能设备人机交互体验和解决问题的能力。本文提出了一种基于多层卷积神经网络的人脸表情识别方法,先对JAFFE表情数据集中的图像进行数据增强,包括裁剪、旋转和缩放操作,得到增强后的表情数据集;然后基于MTCNN实现人脸检测和剪切,将剪切后得到的人脸图像作为表情识别网络模型的输入;接下来设计表情识别网络模型,模型共包含8个权重层,即6个卷积层和2个全连接层;再把预处理后的人脸图像数据集中90%的图像输入模型进行训练得到训练后的模型;最后将预处理后的人脸图像数据集中剩下的10%的图像作为测试集进行预测。实验结果表明,本文方法对高兴、惊讶、中性、愤怒和厌恶五种表情的预测准确率较高,而恐惧和悲伤的预测准确率较低。为了进一步提高本文方法的表情识别能力,可以从以下两个方面进行改进,一是从数量角度和多样性角度进一步丰富输入的表情数据集;二是设计更合适的神经网络模型,能够提取出更多有效的表情特征。
