一种轻量化非结构化道路语义分割神经网络
2023-04-29金汝宁赵波李洪平
金汝宁 赵波 李洪平


非结构化道路由于没有明显车道线且道路特征多、地域差异大,现有的结构化道路分割方法无法满足非结构化道路分割在实际应用中的实时性与准确性要求.为了解决上述难点,本文基于DeepLabv3+网络提出一种G-lite-DeepLabv3+网络结构,使用Mobilenetv2网络替换解码器中的Xception特征提取网络,并通过在Mobilenetv2网络与空洞空间金字塔池化模块中使用分组卷积替换普通卷积,且有选择地取舍批规范层来减少参数量,在不影响精度的同时提升分割效率.同时针对非结构化道路在图像里分布位置相对较固定的特点,引入注意力机制对高级语义特征进行处理,提升网络对有用特征的敏感度与准确性.选用与我国非结构化道路路况相似的印度道路驾驶IDD进行训练,并与其他经典语义分割网络进行实验对比,结果表明,相比于其他网络,本文提出的G-lite-DeepLabv3+准确率与实时性均表现较好、误分割与边缘清晰度均好于对照网络;与经典算法进行对比,平均交并比mIoU提升1.3%,平均像素精度提升6.2%,帧率提升22.1%.
语义分割; 非结构化道路; 分组卷积; 注意力机制
U461A2023.012003
收稿日期: 2022-02-22
基金项目: 四川省重大科技专项项目(2020YFSY0058)
作者简介: 金汝宁(1998-), 男, 辽宁锦州人, 硕士研究生, 主要从事图像处理研究. E-mail: 872995841@qq.com
通讯作者: 赵波. E-mail: zhaobo@scu.edu.cn
A lightweight unstructured road semantic segmentation neural network
JIN Ru-Ning1, ZHAO Bo1,2,3, LI Hong-Ping1
(1. School of Mechanical Engineering, Sichuan University, Chengdu 610065, China;
2.State Key Laboratory of Mining Equipment and Intelligent Manufacturing, Taiyuan Heavy Machinery Group Co., Ltd, Taiyuan 030024, China;
3. Sichuan Provincial Collaborative Innovation Center for Intelligent Agricultural Machinery in Hilly Areas, Deyang 618000, China)
In unstructured roads, there is no obvious lane line, many road characteristics and large regional differences. As a result, the existing structured road segmentation methods can not meet the real-time and accuracy requirements of unstructured road segmentation in practical application.To solve these problems, a new neural network called G-lite-DeepLabv3+ is proposed based on the DeepLabv3+ network. Specifically, the Xception network is replaced by the Mbilenetv2 network in the decoder, the convolutions in Mobilenetv2 and ASPP are replaced by group convolution and the batchnorm layer is chosen selectively to reduce the amount of parameters, improving the segmentation efficiency without affecting the accuracy; at the same time, attention mechanism is introduced to deal with high-level semantic features to improve the sensitivity and accuracy of the network to useful features, considering relatively fixed distribution position of unstructured roads in the image. India driving dataset(IDD) is chosen to train the model taking into account that the roads included in the dataset are similar to the unstructured road in China. The established model is compared with other classical semantic segmentation networks, and the results show that the accuracy and real-time performance of g-lite-deeplabv3+ proposed in this paper are better than those of other networks. The proposed network also outperforms other networks on the indices of improper segmentation and edge clarity. Compared with the traditional network, the mean Intersection over Union(mIoU) is improved by 1.3%; the average pixel accuracy(mPA) is improved by 6.2% and the frame per second (FPS) is improved by 22.1%.
Semantic segmentation; Unstructured road; Group convolution; Attention mechanism
1 引 言
目前,自动驾驶技术发展迅速,其中最重要的核心技术之一就是对可通行区域的划分.对于具有清晰的道路标志线的结构化道路的分割在现阶段较为成熟,Lu等[1]利用结构化交通环境中车道具有平行的线性边缘作为可通行区域检测的依据,提出一种基于灰度特征的识别方法;为减轻光照变化和阴影对检测结果的影响,Yuji等[2]利用大部分道路边界存在朝向扩张中心的边缘点都位于道路边界的特征,提出了一种基于车道标志线的分割方法.但以上方法并不适用于非结构化道路检测,原因是非结构化道路缺乏可识别的车道线,没有清晰的道路边缘,背景差异性较大[3],难以完成检测任务.近年来,深度学习的出现为非结构化道路检测提供了新思路.语义分割作为一种热门的研究方向,以准确率较高,算法简便,鲁棒性较好成为最适合可通行区域检测的一种方法,其中全卷积网络FCN(Fully Convolutional Networks)[4]实现了端到端的语义分割,大大提升了卷积神经网络的泛化能力.为了提升分割精度,学者们在FCN的基础上进行了一系列改进.SegNet[5]改进了上采样过程,使用记录下来的最大池化的索引来对其做上采样处理,使分割精度大大提高.DeepLabv1[6]通过使用条件随机场CRF(Conditional Random Field)[7]处理FCN得到的分割结果,优化边界细节.DeepLabv2[8]使用空洞卷积代替原Deeplabv1中的上采样方法,并且提出空洞空间金字塔模块(Atrous Spatial Pyramid Pooling,ASPP),在减少参数量的同时增加准确率.DeepLabv3[9]对空洞空间金字塔模块进行了优化,使其能够更好的捕捉多尺度信息.DeepLabv3+[10]在DeepLabv3的基础上引入了编码器-解码器结构,能够更好地融合低级语义特征与高级语义特征.PSPNet[11]提出了金字塔池化模块,能够充分利用上下文信息.UNet[12]提出了U型结构,可在使用数量更少数据集的同时,不降低分割精度.
由于非结构化道路具有特征多、分布范围广、地域差异大以及对环境因素敏感等特点[13],若想使用上述语义分割网络进行识别,不但需要大量、种类丰富的非结构化道路数据集,而且对网络结构也需要做针对性修改,否则过深的网络会导致实时性差和过拟合的现象.本文选择分割精度较高,鲁棒性较强,结构相对简洁的DeepLabv3+网络进行针对性改进,具体工作有:(1) 将DeepLabv3+网络的backbone由Xception[14]替换为MobileNetv2[15],减轻网络结构,提升特征提取速度,防止过拟合现象的发生;(2) 在MobileNetv2与空洞空间金字塔模块中使用分组卷积[16]替换传统卷积,并且删除批规范层[17],在不影响精度的情况下减少参数量与计算量,提升分割效率;(3) 在空洞空间金字塔模块后加入注意力模块,提升网络识别速度与精度.
2 网络结构
图像可以看成是一种像素的合集,而语义分割的本质是一种对属于特定标签的每个像素进行分类的任务.目前在街景语义分割任务中效果比较好的结构是编码-解码结构,其中编码器的功能主要是提取特征,解码过程主要是根据解码器提取的特征对像素进行分类.
本文选取对街景语义分割较好,结构较为简单,分割速度较快的DeepLabv3+网络进行针对性改进.因为原版backbone为Xception的网络在进行本文的任务时会出现过拟合现象,且速度达不到实时性要求,所以首先将backbone替换成经过轻量化改造的MobileNetv2网络,在避免网络过深出现过拟合现象的同时,提升特征提取效率.为提升分割效率,对空洞空间金字塔池化结构进行轻量化改进.同时,为了提升解码器对目标区域的敏感度,在编码器的空洞空间金字塔池化结构后引入注意力模块,然后用解码器融合高级、低级特征图并对像素进行分类.完整网络结构如图1所示.
图1 G-Lite-Deeplabv3+结构
Fig.1 The structure of G-Lite-Deeplabv3+
2.1 分组卷积
为了减少参数量,提高网络效率,本文受文献[16]启发,采用了分组卷积替换了MobileNetv2与空间金字塔结构中的普通卷积操作.分组卷积操作是在对特征图进行卷积时,先对特征图分组后,再卷积,其原理如图2所示.若一个未分组的网络得输入特征图尺寸为C×W×H,卷积核的组数为N,卷积核尺寸为C×K×K,若想输出N组特征图,则需要学习C×K×K×N个参数,若将特征图分为G组,则只需要学习 (C/G)×K×K×N 个参数,总参数量降为原来的1/G.同时,分组卷积也可以看作是对原来的特征图进行了一个dropout,有正则化的效果,避免出现过拟合现象.
(a) 普通卷积 (b) 分组卷积
图2 分组卷积原理图
Fig.2 The schematic diagram of groups convolution
2.2 轻量化backbone
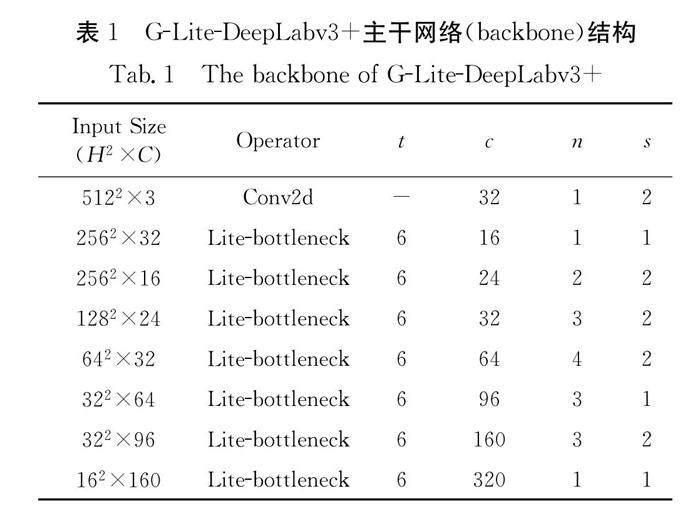
在本文中,新网络的backbone采用了MobileNetv2网络主要模型结构,具体结构如表1所示.
表1中,H2为输入图像的像素数量;C为输入通道数;t为输入通道的倍增系数;n为此尺寸的Lite-bottleneck的重复次数;s为各个Lite-bottleneck模块第一次重复时的卷积步长.
此结构中,Lite-bottleneck是本文提出的一种对原bottleneck的轻量化改进.Lite-bottleneck与原bottleneck原理相同,可以分为“升维层”、“卷积层”、“降维层”.首先,使用升维层中的1×1卷积将特征图的空间维度提升,再经过卷积层3×3的深度可分离卷积提取每个通道特征图的特征,最后经过1×1卷积将其降维.其中,“升维层”和“卷基层”的激活函数为ReLU函数,为了防止ReLU函数破坏压缩后的特征,“降维层”后的激活函数使用Linear函数,如图3所示.不同的是,Lite-bottleneck将“升维层”和“降维层”中的普通卷积替换成了组数为2的分组卷积,减少参数量;同时,因为分组卷积可以在较浅网络中防止过拟合现象的发生,所以将Lite-bottleneck中的批规范层删除,减少计算量.在提取特征的过程中,将尺寸为1282×24的特征图输出作为低级语义特征输入到解码器中,将最后得到特征图输入空洞空间金字塔池化结构中.网络的具体算法如表2所示.若输入图像为X,bottleneck总共有N层,则有如下运算过程.
新结构与DeepLabv3+的原主干网络Xception相比,大大降低的网络深度与参数量,更加适合本文的实时非结构化道路检测任务.
2.3 融合注意力机制的轻量化空洞空间金字塔池化模块
为了扩大感受野,并提取多尺度特征图,DeepLabv3+网络中使用了空洞空间金字塔结构,其中采用了不同空洞率的空洞卷积,在参数量不变的情况下提取不同尺度大特征图,可以更好地检测类似道路这种大目标,同时,可以捕获多尺度上下文信息,更加精确地定位目标.图片经过空间金字塔池化后输出维度统一且信息充足的特征图[18].为了加速分割进程,实现实时检测的功能,本文提出了一种轻量化空洞空间金字塔池化模块,将空洞卷积替换为组数为2的空洞分组卷积,在减少参数量的同时承担批规范层的作用,再删掉批规范层以减少计算量.将经过轻量化空洞空间金字塔池化模块的特征图融合在一起,用1×1的卷积调整通道数,再经过注意力模块.
注意力模块可以通过赋予像素不同的权重来达到将调整整个网络关注重点,提升识别效果与效率.本文中的注意力模块由通道注意力模块与空间注意力模块串联而成.通道注意力模块可以关注输入特征有意义的部分,空间注意力模块则可以获取场景中的全局信息[19,20].
通道注意力模块的结构如图4所示.输入特征X首先经过全局平均池化和全局最大池化,得到两组尺寸为1×1的特征图Xcavg、Xcmax,再将它们分别送入两层全连接神经网络,此两层全连接神经网络对于两组特征图是共享参数的,然后将得到的两组特征图相加,通过Sigmoid函数得到0到1之间的权重系数,将其与特征图相乘得到优化过的特征图.用W0和W1分别表示共享网络隐藏层(Shared MLP)的两层参数,用σ表示Sigmoid函数,可以得到通道注意力计算公式如下式.
Mc(X)=σ(MLP(AvgPool(X))+
MLP(MaxPool(X)))=σ(W1(W0(Xcavg))+
W1(W0(Xcmax)))(1)
空间注意力模块结构如图5所示.将经过通道注意力模块优化的特征图X输入,首先分别经过只有一个通道维度的最大池化和平均池化,将得到的两个特征图Xsavg、Xsmax拼接起来,再经过一个卷积层,将为一个通道,采用7×7的卷积核进行卷积操作,同时保持特征图尺寸不变,将得到的特征图通过Sigmoid函数生成空间权重系数,将其与输入的特征图相乘得到最终的特征图.计算公式如下式.
Ms(X′)=σ(f 7×7([AvgPool(X′);
MaxPool(X′)]))=σ(f7×7([Xsavg;Xsmax])) (2)
2.4 解码器
首先将编码器输出的高级语义特征进行4倍上采样,将其尺寸恢复到与低级语义特征相同的124×124,然后将低级语义特征XLowLevel-Feature与高
级语义特征XHighLevel-Feature串联到一起,使用3×3的卷积细化特征,将其变为1个通道的特征图,最后使用4倍上采样完成解码过程,得到预测结果.具体算法如表3所示.
3 数据集
非结构化道路检测任务不同于高速公路、城市干道等具有清晰道路标志线的结构化道路检测任务可以把检测任务简化为车道线或道路边界检测,它没有明显的车道线与清晰的道路边界,传统城市街景语义分割数据集并不适用于非结构化道路识别.经过对比Cityscapes等其他街景语义分割数据集后,印度道路驾驶数据集(India Driving Dataset,IDD )更加适合训练非结构化道路检测的任务.印度道路驾驶数据集包含34个类别,像素尺寸为1920×1080.经过挑选,选出了6792张符合要求的街景图片,如图6所示.针对印度道路驾驶数据集涵盖种类较多,对其进行有针对性的改造,将road类与parking类划分为可通行区域,其余32个类别划分为不可通行区域.将筛选后的6792张图片按8∶1∶1的比例随机分为训练集、验证集与预测集.训练集用于训练网络参数,验证集用于反馈训练结果、及时调整网络参数,预测集用于评估训练得到的网络的好坏.
4 训练细节参数和损失函数
4.1 网络参数
本文网络的训练环境为:操作系统:Windows 10专业版;CPU:Intel(R) Core(TM) i5-10400F;内存:16 GB;GPU:Ge Force RTX 3060,显存为12 GB.使用PyTorch 深度学习框架,采用名为Adam的一种自适应学习率的算法更新神经网络的权重.在训练中,batchsize=8;图片为jpg格式,标签为png格式.初始学习率为0.000 001,权重衰减为0.0005.
4.2 损失函数
损失函数通常被用来估计模型的预测值与真实值的拟合程度,它是一个非负的实值函数,损失函数越小,模型的鲁棒性就越强.非结构化道路属于一种二分类任务,通常所采用的交叉熵函数不能很好地处理类别不平衡的现象,不能有效地监督网络,因此采用Dice系数差异函数(Dice-loss)[21]来表示训练中的语义分割效果,它可以惩罚低置信度的预测,如果置信度较高,就会得到较小的Dice系数差异函数.Dice系数是一种集合相似度的度量函数,常被用于计算两个矩阵的相似度.其计算方法如式(3)所示.
s=2|X∩Y||X|+|Y|(3)
就语义分割的问题而言,其中X为标签图像;Y为预测输出图;|X∩Y|可以近似为将预测图与分割图之间的点乘,并将结果的元素结果相加的和.对于|X|和|Y|的量化计算则可以采用简单的元素相加.最终得到Dice系数差异函数如下式.
LDice=1-2X∩YX+Y(4)
5 实验结果与分析
使用上述配置对挑选的印度道路驾驶数据集进行训练,训练从第49个epoch开始收敛,训练集和验证集的Dice-loss分别稳定在0.074与0.062.此外,在相同的训练配置与环境下,将本文网络分别与文献[13]、PSPNet、UNet和以Mobilenetv2为backbone的DeepLabv3+网络进行对比,对比结果如图7所示.
对比分割效果,可以看出,本文的算法最贴近于标签图像,对于前三张图的分割,文献[13]虽然边缘分割的比较好,但是容易出现误分割,如第一张示例原图与第二张示例原图的分割结果所示,车辆上都出现了小块误分割,并且第二张示例原图分割结果中的车辆下边缘分割也并不十分精确,PSPNet虽然速度最快,但是分割精度比较差,边缘细节丢失较多,无法准确识别可通行区域与障碍物边缘,UNet分割较为精准,但第二张示例原图中的车辆下边缘分割不准确,而且分割速度较慢,对于第四张示例原图,除了PSPNet,其余三种算法都可以勉强分割出左侧土坑轮廓,但对于右侧的路缘,文献[13]、PSPNet和UNet都出现了不同程度的误分割,而本文提出的G-lite-DeepLabv3+则没有出现此情况.
在同样的环境与配置下使用挑选的印度道路驾驶数据集训练本文的G-lite-Deeplabv3+网络,并且与文献[13]、PSPNet、UNet和以MobileNetv2为backbone的DeepLabv3+网络进行对比,对比标准有平均交并比(mIoU),可通行区域交并比(IoU),平均像素精度(mPA)和每秒帧数(FPS).由表4可知,由于融合了注意力机制并且再次进行了轻量化,对比只使用MobileNetv2进行轻量化后的DeepLabv3+网络,新网络在平均交并比与可通行区域交并比的性能全面提升的情况下,平均像素精度提升6.2%,每秒帧数更是提升了22.1%,达到了39.4帧/s,满足了非结构化道路分割任务的实时性的要求.
6 结 论
为了更好地完成非结构化道路识别的任务,本文使用了经过挑选的印度道路驾驶数据集,印度道路驾驶数据集与我国的非结构化道路路况非常相似,经过训练后,可以得到非常适合非结构化道路路况的语义分割网络模型.针对结构化道路分割方法无法满足非结构化道路分割在实际应用中所需的实时性与准确性问题,本文提出了一种轻量化方法G-lite-DeepLabv3+.为了避免网络过深产生过拟合现象且参数过多导致效率变低,文中使用MobileNetv2取代Xception作为特征提取网络,并在MobileNetv2与空洞空间金字塔池化模块中使用分组卷积替换普通卷积并且合理取舍掉它们的批规范层,大大减少了网络参数量,在不影响分割精度的同时提高了分割速度,满足实时性的要求.同时,为了放大非结构化道路图像分布的共同特性以提高分割精度,本文加入两种串联的注意力模块处理空洞空间金字塔池化模块输出的高级图像特征.实验表明,本文提出的G-lite-DeepLabv3+网络在精度以及效率方面均优于对照网络.为语义分割在非结构化道路识别任务上的应用提供了一定改进依据.
参考文献:
[1] Lu J Y, Yang M. Vision-based real-time road detection in urban traffic [J]. Physica A, 2002, 75:82.
[2] Yuji O, Shoji M. Multitype lane markers recognition using local edge direction[C]//Proceedings of the IEEE Intelligent Vehicle Symposium. Changshu: Chinese Association of Automation, 2002.
[3] 张凯航, 冀杰, 蒋骆, 等.基于 SegNet的非结构道路可行驶区域语义分割[J].重庆大学学报,2020,43: 79.
[4] Shelhamer E, Long J, Darrell T. Fully convolutional networks for semantic segmentation [J]. IEEE T Pattern Anal, 2017, 39: 640.
[5] Badrinarayanan V, Kendall A, Cipolla R. SegNet: a deep convolution encoder-decoder architecture for image segmentation[J]. IEEE T Pattern Anal, 2017, 39: 2481.
[6] Chen L C, Papandreou G, Kokkinos I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs [J]. Comput Sci, 2014, 4: 357.
[7] Krhenbühl P, Koltun V. Efficient inference in fully connected CRFs with gaussian edge potentials [J].Adv Neural Inf Proc Syst, 2011, 2: 109.
[8] Chen L C, Papandreou G, Kokkinos I, et al. Deeplab: semantic image segmentation with deep convolutional nets, atrousconvolution, and fully connected CRFs [J]. IEEE T Pattern Anal, 2018, 40: 834.
[9] Chen L C, Papandreou G, Schroff F, et al. Rethinking atrous convolution for semantic image segmentation [J]. Computer Vision, 2017, 423: 438.
[10] Chen L C, Zhu Y, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [J]. Computer Vision, 2018, 833: 851.
[11] Zhao H, Shi J, Qi X, et al. Pyramid scene parsing network [J]. IEEE Comt Socie, 2017, 211: 223.
[12] Zhou Z, Siddiquee M M R, Tajbakhsh N, et al. UNet++: a nested U-Net architecture for medical image segmentation [J]. Comput Meth Prog Bio, 2018, 56: 64.
[13] 龚志力, 谷玉海, 朱腾腾, 等.融合注意力机制与轻量化DeepLabv3+的非结构化道路识别[J].微电子学与计算机, 2022, 39: 26.
[14] Chollet F. Xception: deep learning with depthwise separable convolutions[J].Ieice T Fund Electr, 2017, 32: 1952.
[15] Sandler M, Howard A, Zhu M,et al. MobileNetv2: inverted residuals and linear bottlenecks [C]//Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2018, 26: 1481.
[16] Ioannou Y, Robertson D, Cipolla R,et al. Deep roots: improving CNN efficiency with hierarchical filter groups [J]. Ieice T Fund Electr, 2017, 35: 1542.
[17] Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift [J].Ieice T Fund Electr, 2015, 21, 1054.
[18] 王卜, 何扬. 基于改进YOLOv3的交通标志检测[J]. 四川大学学报: 自然科学版, 2022, 59: 012004.
[19] 晋儒龙, 卿粼波, 文虹茜. 基于注意力机制多尺度网络的自然场景情绪识别[J]. 四川大学学报: 自然科学版, 2022, 59: 012003.
[20] 蔡英凤, 朱南楠, 邰康盛, 等. 基于注意力机制的车辆行为预测[J]. 江苏大学学报:自然科学版, 2020, 41: 125.
[21] 田宝园, 程怿, 蔡叶华, 等. 基于改进U- Net深度网络的超声正中神经图像分割[J]. 自动化仪表, 2020, 41: 36.
