基于多尺度自适应注意力网络的剩余寿命预测
2023-04-19刘斌许靖霍美玲崔学英谢秀峰杨栋辉王嘉
刘斌,许靖,霍美玲,崔学英,谢秀峰,杨栋辉,王嘉
太原科技大学 应用科学学院,太原 030024
随着装备智能化程度的提高,剩余寿命预测(Remaining Useful Life,RUL)在维修管理决策中的作用越来越重要,是系统健康管理的关键环节。掌握系统运行状态并对机械系统做出准确的剩余寿命预测,既能很好地保护系统、延长使用时间,又能大幅降低维护成本[1]。近年来针对不同复杂系统的剩余寿命研究取得了许多成果,主要涉及3 种类型的预测方法:基于模型的方法、数据驱动方法和二者的混合方法。基于模型的方法[2-3]具有容易验证的优点,但因其具有计算量大且有达不到预期结果的风险,基于模型的方法远不如数据驱动方法有吸引力。作为一种最具发展前景的数据驱动方法,深度学习逐渐成为剩余寿命预测的主流方法。常用的深度学习模型结构包括卷积神经网络(Convolutional Neural Networks,CNN)、循 环 神 经 网 络(Recurrent Neural Network,RNN)和编-解码器模型[4]。
卷积神经网络在序列预测中得到了良好的应用,其人工神经元可响应一部分覆盖范围内的周围单元,有效地提取数据局部特征。Sateesh Babu 等[5]首先将其应用到时间序列上,建立了基于回归模型的预测系统。Li 等[6]充分利用网络深度优势提出了一种深度模型,提高了其提取数据特征的能力。该网络结构的有效性在涡扇发动机(Company-Modular Aero-Propulsion System Simulation,C-MAPSS)数据集[7]上得到了验证。增加网络深度虽可更好地拟合特征,但会带来梯度不稳定、网络退化等问题。为减少网络深度、避免单一尺度提取信息不充分的缺点,在GoogleNet 中 提 出 了 多 尺 度 卷 积 的 概 念[8]。Li[9]将多尺度块加入预测模型中,通过叠加3 个多尺度卷积层对飞机发动机传感器数据进行剩余寿命预测,算法结果优于文献[6]中的模型。
虽卷积神经网络在寿命预测中取得了一些成果,但它只能识别局部特征,缺乏联系上下文的能力,存在一定缺陷。为弥补这一缺陷,循环神经网络得到了应用[10-11]。Guo 等[12]构建了健康指标并将其应用于轴承数据集。由于梯度消失等问题,循环神经网络预测能力具有一定局限性。Hochreiter 和Schmidhuber[13]引 入 了 细 胞 状态这一概念,提出了解决这些问题的长短期记忆网络(Long Short-Term Memory,LSTM)。Cho等[14]简化了长短期记忆网络的模型,提出了节约计算成本的门控循环单元(Gate Recurrent Unit,GRU)。Chen 等[15]采用核主成分分析对非线性数据进行降维,利用循环神经网络的这两种变体进行预测,门控循环单元的预测结果优于长短期记忆网络[13-14]。Ma 和Mao[16]在长短期记忆网络中融入卷积运算,保留了其时间相关性的优点;相较于传统的长短期记忆网络预测性能得到了提高。刘畅和陈雯柏[17]结合多尺度卷积和长短期记忆网络同时解决了信息提取和数据长时依赖的问题。
以上两个类型的网络虽可自动学习数据的潜在表示,但是在去除噪声及降低数据复杂度方面具有一定挑战[18]。编解码网络通过压缩输入数据后再解压提取原数据中最具有代表性的信息,缩 减 输 入 的 信 息 量。Pillai 和Vadakkepat[19]提出了一种两阶段的多损失编码器用于提取低噪声、低互相关、强退化趋势的特征,在飞机发动机传感器数据和叶片磨损数据上的预测效果强于卷积神经网络和循环神经网络的变体。
以上模型虽能学习到数据的有用特征并减少噪声影响,但都默认不同传感器的指标特征和系统时间特征对预测的贡献是相同的,会忽略不同特征间的差异性。此外参数选择通常依赖于大量实验确定,增加了模型训练的时间。针对特征差异和训练效率问题,本文采用一种参数自适应选择的多尺度注意力网络模型。主要工作如下:
1)采用一种参数自适应卷积注意力模块,通过自动选择参数避免交叉验证手动调整卷积核大小,减少网络训练的时间成本。
2)融合横纵两个维度数据间的信息,即通道特征和时间特征的多尺度融合,从而关注有用信息,抑制无用信息,增强数据特征的提取能力。
3)用分段非线性目标函数模拟传感器退化特征,缩小异常值对预测的影响,减少线性模型预测引起的系统偏差。
首先介绍多尺度自适应注意力模型的结构及其预测流程,然后在C-MAPSS 数据集上进行剩余寿命预测并讨论一些参数的影响,最后将多尺度自适应注意力模型与一些现有方法进行比对。
1 多尺度自适应卷积注意力网络
将一种新的注意力模块用于剩余寿命预测,将其称为多尺度自适应注意力网络(MAAN)。该网络将预处理后的不同传感器数据作为输入,利用多尺度卷积模块提取有用特征。通过加入自适应注意力模块自动选择卷积核大小,从而有效提取数据的时间和空间特征。多个自适应注意力模块能学习特征的高层表示。将3 条路径输出的特征连接起来输入两个大小不同的全连接层,从而估计最终剩余寿命。网络模型结构如图1 所示。

图1 MANN 预测流程Fig.1 MAAN prediction framework
1.1 数据预处理
采用信号x={x1,x2,…,xK}作为MAAN 的输入,其中K是传感器的数量。此时信号x直接输入到网络中,网络可能会因其不同量级的数据而无法收敛。为学习到更有效的特征,采用最小最大归一化将原始数据缩放到[0, 1]:
式中:x'k为归一化后的数据;xk为第k个传感器的数据;min(xk)和max(xk)分别为xk的最小值和最大值。
此后采用步长为l=1、大小为S的窗口在总周期为T的归一化数据上滑动生成输入数据,则第i个传感器的第j+1 个样本(窗口)实际剩余寿命为T-S-jl(如图2 所示,图中RUL 为实际剩余寿命),此时输入样本大小为SK。

图2 滑动时间窗口示意图Fig.2 Schematic diagram of sliding time window
现有关于计算复杂系统剩余寿命预测目标函数模型的构建大都沿用Heimes[20]提出的分段线性模型。然而系统退化过程是复杂的,线性函数不仅容易扩大异常值对预测结果的影响,还容易扩大系统性偏差。为此设计了一种非线性目标函数:
式中:RULit为第i个涡轮发动机在循环时间t时的寿命;T0为初始剩余寿命值;A为退化系数;t1和t2为发动机发生退化改变的循环时间临界值,由其总循环时间确定;Tl为再次发生退化改变的剩余寿命值。
1.2 多尺度自适应注意力网络
如图1 所示,多尺度自适应注意力网络由3 条并行的支路组成。每条支路都由两部分组成,分别是卷积块和堆叠的自适应注意力模块。为更好地提取特征,这3 条支路上卷积层分别选取不同大小的卷积核。
1.2.1 卷积块
在MAAN 中使用一维卷积提取经过滑动窗口的数据。一维卷积的运行过程如图3 所示。在所提方法中3 条路径上卷积分别使用3 个不同大小的卷积核,可提取出不同特征(如图1 所示)。在卷积后添加非线性激活函数可增强网络的表示能力。每条路径上的卷积结果为

图3 一维卷积神经网络示意图Fig.3 One-dimensional convolution neural networks diagram
式中:W'为权重;x'为滑动窗口生成的数据;b'为偏置项;X为卷积输出特征图,作为自适应注意力网络的输入;f(·)为Logish激活函数[21],其表达式为
1.2.2 自适应注意力模块
如图1 所示,自适应注意力网络由通道注意力和时间注意力组成,中间由一个一维扩张卷积连接。如图4 所示,经由卷积层学习到的特征X作为自适应注意力网络的输入,其中k为一维卷积的卷积核大小,与通道维数n相关,σ为Hard sigmoid 函数。首先经过全局平均池化(Global Average Pooling, GPA)得到每个输入通道特征图的平均值,接着通过使用大小为kca的一维卷积考虑通道间跨信道交互。一般认为信道维度n与kca存在某种非线性映射关系,使n越大长期交互作用越强,反之短期交互作用越强。在经典核技巧中,处理未知映射问题时往往使用指数族函数(如高斯函数)作为核函数,因此kca的大小由信道维度n的指数映射自适应确定[22]:

图4 通道注意力Fig.4 Channel attention
式中:φ为确定卷积核大小的函数;|·|odd为取最近的奇数。
使用Hard sigmoid 函数计算得到每个通道的注意力权重,并对特征X进行加权:
式中:Xca为通道注意力生成的注意力向量;W和B分别为一维卷积层的权重和偏置;xca为自适应通道注意力的输出;⊗为元素乘法。
一个一维扩张卷积用于学习通道注意力特征表示,从而可捕捉到每个通道的上下文,增强学习特征的时序性。卷积表达式为
式中:xd为学习到的信息,作为时间注意力的输入;w和b分别为扩张卷积的权重和偏置;*d表示扩张率为d。
时间维度注意力机制作为通道注意力机制的补充,充分考虑每个时间维度上的特征。与通道注意力类似,使用一维卷积考虑时间维度上的相互关系自适应产生一维卷积核大小,其关系可表示为
式中:kta为自适应生成的一维卷积核大小;s为时间信道维度。
通过式(10)、式(11)得出时间方向的注意力权重并进行加权:
式中:x'ta为时间方向上的注意力向量;Wta和Bta分别为学习到的权重和偏置;xta为自适应注意力网络的输出。
1.3 剩余使用寿命预测
利用多尺度选择机制可自适应提取和学习多传感器数据中潜在的相关性信息,其3 个路径上的输出特征可表示为
式中:xM为MAAN 的输出;xM1、xM2和xM3分别 为从3 个路径中学习到的特征;concatenate(·)函数表示将数据串联合并。
通过全连接层学习MAAN 的输出可获得最终剩余寿命预测结果:
式中:RUL'i为最终预测的剩余寿命;w1、w2和b1、b2为全连接层中可学习的参数。在每个全连接层后使用Dropout 技术。
1.4 模型训练
在每条支路上分别使用1 个卷积神经网络和3 个堆叠的自适应注意力网络学习特征。各个卷积层的权重和偏置是在训练过程中学习得到的。在Tensorflow 的Kreas 模块上实现训练和测试过程,使用Adam[23]优化器,最小化损失函数为
式中:L为平方误差损失;N1为总训练样本数量;RULi为剩余寿命真实值。
1.5 模型预测流程
MAAN 模型预测过程分为3 部分:数据预处理、训练模型、测试模型和RUL 估计。该算法可通过以下步骤实现:
1)从原始训练集和测试集中选择对预测结果有影响的数据,并将其标准化。
2)通过滑动时间窗处理标准化数据,以生成模型的训练集和测试集。建立如式(2)所示的目标函数生成与训练集对应的训练标签,由RUL数据集生成与测试集对应的测试标签。训练集和训练标签用于训练模型,测试数据集和测试标签用于测试模型和估计剩余寿命。
3)选择适当超参数建立MAAN 模型并初始化网络参数。
4)训练模型并更新参数,将训练好的模型应用于测试集并生成预测值。
5)评估网络性能。预测值和真实值(测试数据标签)之间的误差通过评分函数(Score)和均方根误差(RMSE)计算。
2 实验结果及分析
用飞机发动机数据评估多尺度自适应注意力模型的预测性能[7]。先介绍相关数据集,再介绍评估指标,接着展示模型的预测结果并与一些先进模型进行比较,最后分析一些影响模型预测结果的因素,如时间窗口大小、自适应注意力模块数量、卷积层的使用及自适应注意力模型中激活函数的使用等。为减少随机性的影响,所有实验都进行10 次并取平均值作为最终结果。
2.1 数据集介绍
C-MAPSS 数据集是由美国国家航空航天局发布的飞机发动机从运行到失效的时间序列数据。该数据集包括4 个子数据集,每个子数据集又包含训练集、测试集及剩余寿命数据集。训练集和测试集中的每个发动机都包含21 个传感器序列和3 个操作设定序列。每个子数据集中发动机个数不同,故障模式和运行条件不同,造成4 个子数据集的复杂度不同。FD001 和FD003 数据集的复杂程度较低,均只有1 种运行条件,故障模式分别为1 和2。FD002 和FD004 的数据较为复杂,均包含6 种运行条件,故障模式分别与FD001 和FD003 相同。数据集的具体样本数如表1 所示。考虑数据冗余造成的时间成本及对预测结果的消极影响,在训练和测试过程中抛弃每个子集中的恒定值传感器数据和3 个操作设定数据。4 个子数据集选择的传感器个数及抛弃指标如表2所示。
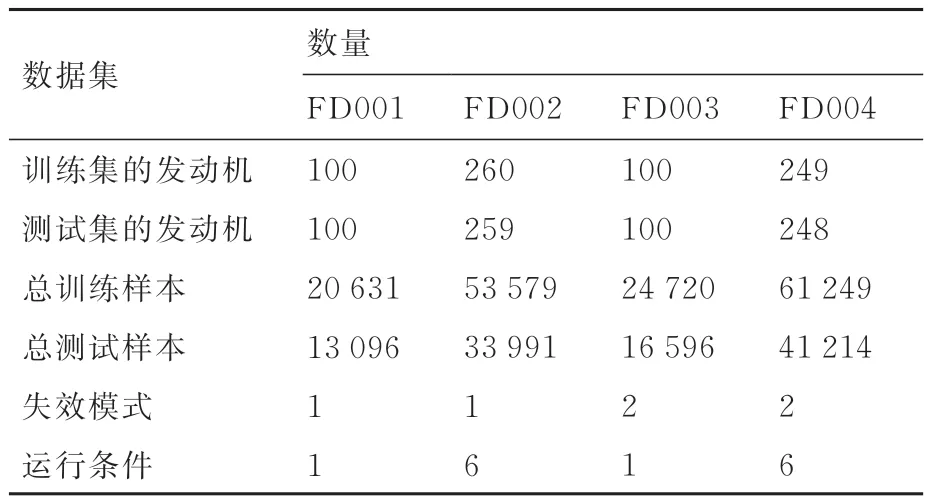
表1 C-MAPSS 数据集细节Table 1 Details of C-MAPSS dataset

表2 输入的传感器序列信息Table 2 Input sensor sequence information
在训练过程中选择70%的数据用于训练,30%的数据用于验证。则4 个子数据集中用于训练和验证的样本数及输入样本大小如表3 所示。

表3 输入样本信息Table 3 Input sample information
2.2 评价指标
RMSE 和评分函数[7]被广泛用于剩余寿命预测结果的评价,这两个指标值越小则代表模型预测能力越高。
均方根误差具体表示为
式中:N2为测试集总样本大小;di为真实值与预测值之间的误差,di=RUL'i-RULi。
评分函数定义为
2.3 模型参数及预测结果
MAAN 共训练150 次,数据批次大小设置为256。前10 次学习率为0.001 0,余下140 次学习率为0.000 3。其他各层参数如表4 所示。
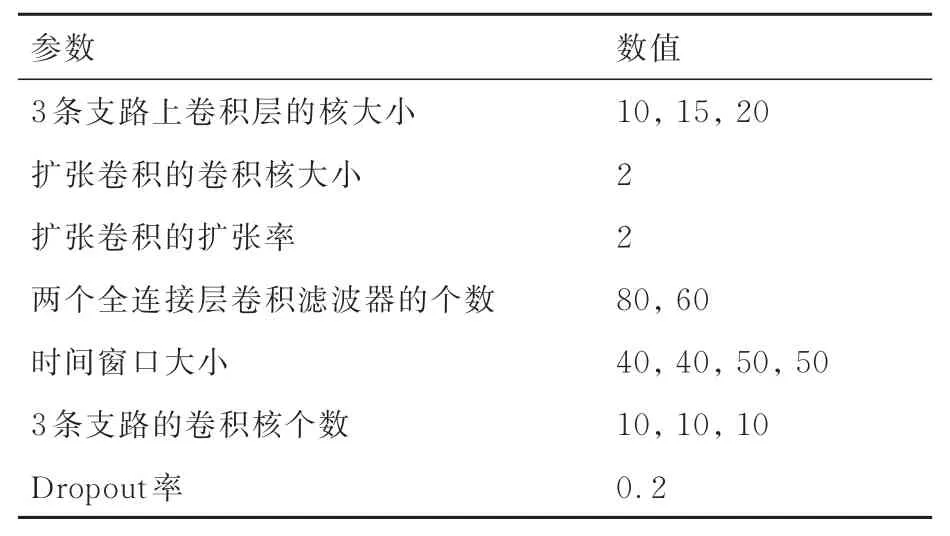
表4 MAAN 预测模型的超参数Table 4 Hyperparameters of MAAN prediction model
设 置T0=125[20]、Tl=100、A=1/900 并 以FD001 和FD004 为例观察其损失函数曲线。图5展示了其收敛过程,可看出MAAN 具有较快的收敛速度,约在30 次训练后趋于平稳,直至收敛。

图5 FD001 和FD004 的训练损失曲线Fig.5 Training loss curves for FD001 and FD004
以FD001为例,选取其49号发动机,图6 为MAAN 学习到的发动机退化过程。可见MAAN模型在预测前期波动较大,后期趋于稳定;同时MAAN 预测的退化趋势与建立的目标函数趋势相同,能准确模拟飞机发动退化趋势。MAAN 对FD001 剩余寿命预测结果如图7 所示。

图6 模型在FD001 第49 号发动机的预测结果Fig.6 Model prediction results for FD001 No.49 engine

图7 MAAN 模型在FD001 的预测结果Fig.7 Prediction results of MAAN model on FD001
将MANN 与文献[5-6,9,11,19,24]中的几种先进模型进行比较,结果表明MAAN 网络模型在每个数据集上都展现出良好效果(如表5 和表6 所示)。MAAN 除在FD003 上的均方根误差不如DSCN[24]低,在4 个子数据集中均显示了较低的均方根误差和评分函数值。

表5 MAAN与一些先进预测方法的RMSE比较Table 5 Comparison of RMSE between MAAN and some advanced prediction methods
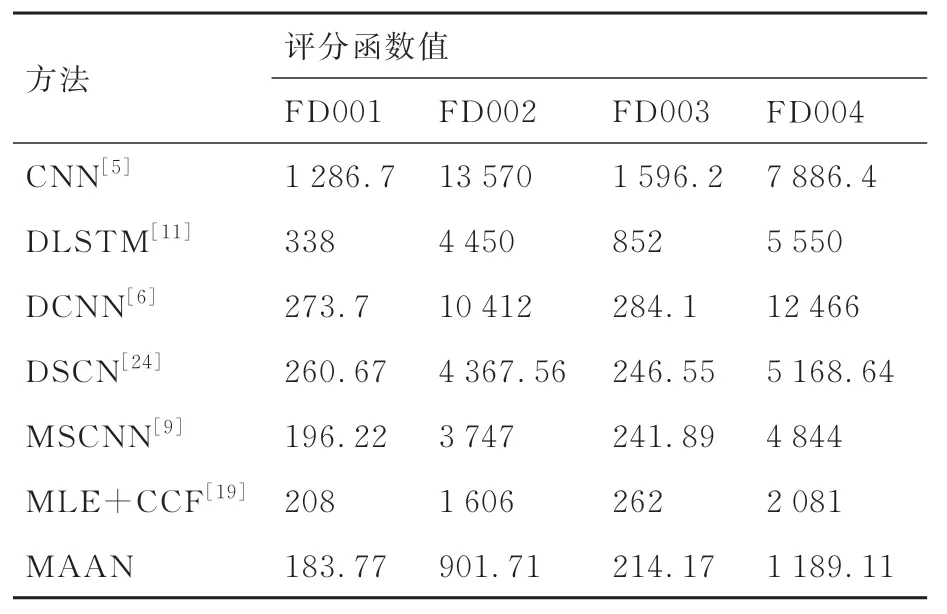
表6 MAAN 与一些先进预测方法的评分函数值比较Table 6 Comparison of score values between MAAN and some advanced prediction methods
2.4 参数的影响
2.4.1 时间窗口大小
图8 为4 个子数据集上时间窗口大小S分别选择20、30、40、50 和60 时多尺度自适应注意力网络的预测结果,仅改变了时间窗口大小,其他参数不变。可看出随S增大,模型在4 个子数据集上的预测精度都得到了提高,但窗口过大也会表现出较差的性能。对于FD001,当窗口S>50后均方根误差有增大趋势;对于FD002,当S>50后,虽均方根误差变化趋于稳定,但评分函数值增幅明显;对于FD003,在S=50 时有最小的均方根误差;对于FD004,两个指标值在S=50 时最小。因此4 个子数据集的时间窗口大小S分别选择40、40、50、50。
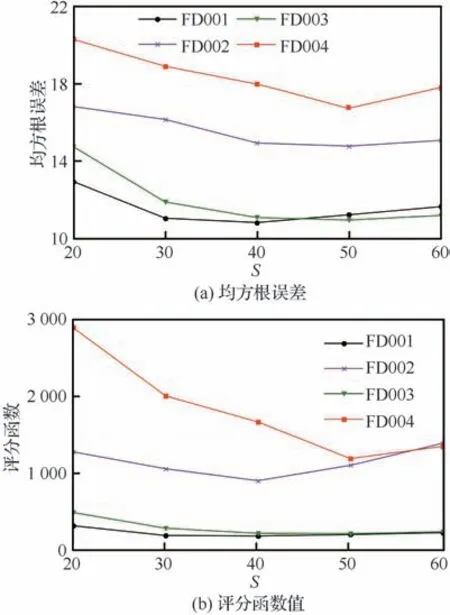
图8 4 个子数据集在不同时间窗口下的MAAN 预测结果Fig.8 MAAN prediction results of four subdatasets in different time windows
2.4.2 自适应注意力模块数量
适当增加网络深度可使网络表现出更优秀的性能,分别研究了不同深度MANN 模型的性能。如图9 所示,分别使用1~5 个注意力模块进行预测。可知虽对于FD001 和FD003 1 个和3 个自适应注意力结构的预测结果相差不大,但是对于FD002 和FD004 仅使用1 个注意力模块进行特征学习会产生更大的均值和标准差。使用3 个自适应注意力模块时模型的鲁棒性最强,所以在训练过程中选择使用3 个自适应注意力模块。

图9 自适应注意力模块数量对预测结果的影响Fig.9 Influences of adaptive attention module number on prediction results
2.4.3 卷积层
多尺度自适应模型使用多尺度卷积层初步提取数据信息。为确保其有效性,以FD001 为例比较使用卷积层的MAAN 和不使用卷积层的DAAN,及使用单一尺度卷积的DaAAN、DbAAN 及DcAAN 的结果,其中DAAN、DaAAN、DbAAN 及DcAAN 均 只 包 含1 个 支 路,DAAN表示仅由3 个堆叠自适应注意力模块组成的网络,DaAAN、DbAAN 和DcAAN 分别表示使用卷积核大小为10、15、20 和3 个堆叠自适应注意力模块组成的网络。结果如图10 所示,与MAAN 模 型 相 比,除DbAAN 在FD001 上 预 测结果的均值具有较小优势外,其他模型都表现出较差的性能,证明了使用具有多尺度卷积及多个自适应注意力模块的MAAN 模型预测优势。
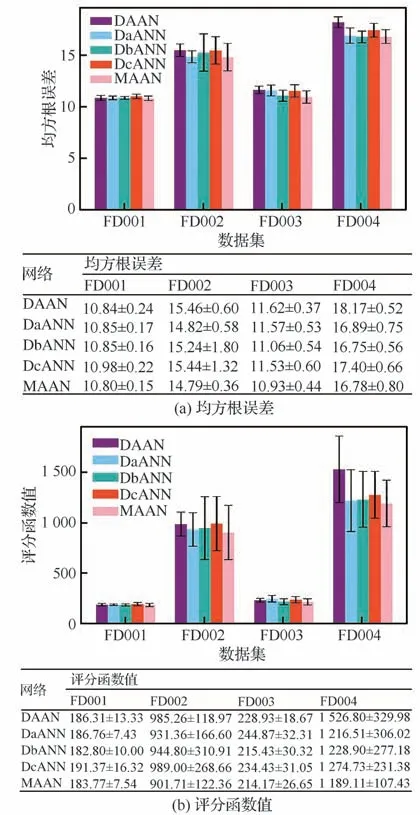
图10 卷积层对MAAN 预测的影响Fig.10 Influences of convolution layer on MAAN prediction
2.4.4 自适应注意力模型中激活函数
使用自适应注意力模块的一维扩张卷积中未使用任何激活函数,图11 为分别加入ReLU、Tanh、Sigmoid 及Logish 函数的预测结果,不使用激活函数的模型即为MAAN 模型,虽在FD001 上的性能比其他加入非线性激活的模型有一定劣势,但在其他3 个子数据集上取得了最低的评分函数值和均方根误差。这是因为加入激活函数会强化模型非线性变换程度,对模型后期预测产生消极影响。因此在自适应注意力模型中不使用激活函数。

图11 激活函数对MAAN 预测的影响Fig.11 Influences of activation function on MAAN prediction
2.4.5 非线性目标函数
使用分段非线性目标函数模拟传感器退化过程。表7 和表8 给出了该目标函数与经典分段线性目标函数的预测对比结果,表明使用非线性目标函数建立发动机退化模型可更好地模拟传感器退化效果。在4 个子数据集上均方根误差分别下降了18.18%、14.90%、19.81%和14.52%,评分函数值分别下降了39.38%、47.22%、43.65%和35.87%。一般来说建立非线性目标函数可提高测试模型的预测精度。更具体地,相对于FD002 和FD004 数据集,非线性目标函数对FD001 和FD003 数据集的均方根误差具有更大影响,表明采用非线性目标函数能更准确地表示简单系统的退化趋势。
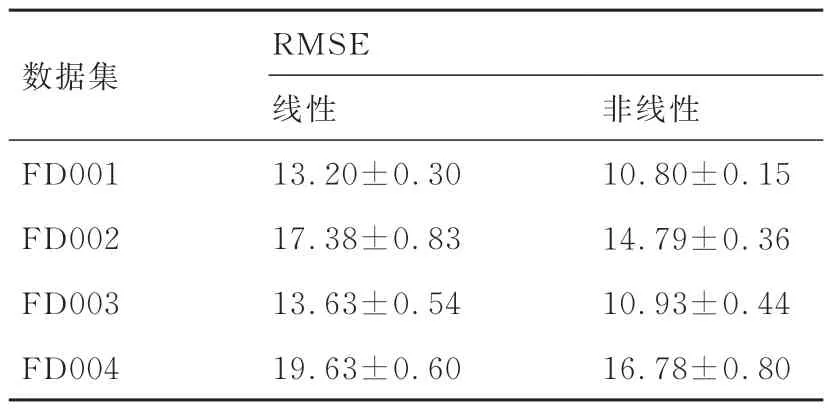
表7 不同目标函数的RMSETable 7 RMSE of different objective functions

表8 不同目标函数的评分函数值Table 8 Score values of different objective functions
3 结 论
1)采用一种多尺度自适应注意力网络研究复杂系统的剩余寿命预测问题。该网络采用一种一维选择机制——自适应注意力网络,该结构不仅能自适应选择卷积核大小,还能突出数据通道与时间维度上的重要特征,提高模型预测能力。
2)多尺度卷积的使用可增强网络学习能力,避免因单一尺度造成特征提取不充分的问题。
3)对C-MAPSS 数据集进行测试实验,结果表明多尺度自适应注意力模型能在该数据集上取得较好的精度,与一些现有方法相比具有明显的优势。
