数字科技馆展品个性化推荐系统设计
2023-04-11赵智姚爽韩丹
赵智 姚爽 韩丹

摘要:随着科技馆行业的蓬勃发展,在互联网技术的推动下,数字科技馆应运而生。但国内外科技馆的种类、数量众多,展品数量更是不计其数,因此用户很难从大量的展品信息中快速搜索到自己需要的信息。本文分析了原有的协同过滤(CF)算法,指出了两种CF算法存在的不足之处,在此基础上进行了修正,提出了一种改进的基于相关相似性的CF算法,并设计了一套具有推荐功能的数字科技馆展品个性化推荐系统。
关键词:数字科技馆;协同过滤技术;MAE;个性化推荐系统
引言
2021年12月,中国科学技术协会印发《现代科技馆体系发展“十四五”规划(2021—2025年)》,其中对全国科技馆智慧化建设以及利用信息化手段促进科技馆体系协同联动发展做出了明确说明[1]。因此,为全面提高公众科学素质,满足新时代公众对科普服务的新需求,我国科技馆行业实现了线上线下相结合,线上虚拟科技馆、网上虚拟浏览,网上互动展品展示等基于互联网的新型数字科技馆。然而各类科技馆众多,馆内展品的种类和数量也是不计其数,面对海量展品数据人们很难快速搜索到自己需要的信息。针对这一难题,开发一款个性化推荐系统为用户推荐其感兴趣的展品信息势在必行[2]。
个性化推荐可以实现根据不同用户的需求量身定制个性化的服务。纵观已有的个性化推荐系统,主要存在以下问题:
(1)缺乏有效数据
在收集用户有效信息时,大多数推荐系统都是要求用户在浏览网页时通过调查问卷的形式对所关注的商品进行评价,这很容易引起用户的反感,因此无法保证数据的真实性、准确性,导致新用户的推荐信息匮乏,降低了系统的推荐精度。
(2)计算效率问题
针对一个用户,以往的推荐系统可以实现实时查找其上万个邻居,但实际应用时同时浏览网页的用户不计其数,算法的计算复杂度高,推荐系统的实时推荐效率低。
1. 数字科技馆展品推荐系统的关键技术
1.1 核心工作原理
本文所设计的科技馆展品推荐系统,算法的计算过程如下:
将输入数据表述为一个i*j的用户-展品评价矩阵R,矩阵元素ri,j表示第i个用户对第j个展品的评分值。
第一步:输入为评价矩阵R,即用户-展品评价矩阵,表述为i*j。i是原用户数,j是用户浏览的展品数。矩阵元素ri,j表示第i个用户对第j个展品的评分值。
用户已评分的展品信息数目用|Ii|表示,即用户i评分向量的长度。
通过上式计算出原用户对其所有浏览过的展品信息的平均打分。
第二步:预测新用户对其未浏览展品的预测值。这一步关键是计算与新用户兴趣度相似的N个原用户,即最近邻用户。根据其最近邻用户对展品信息的评价预测新用户对相同展品的评价值paj。在该算法中,只有与用户相似的N个邻居参与计算。因此算法的核心是计算用户a与用户i的兴趣相似度sim(a,b)。
1.2 原有相似性算法分析
余弦相似性度量方法:
在余弦相似性度量方法中,將新用户没有评分的项目的评分均假设为0,这样可以有效提高计算性能。但在展品信息量巨大,而用户评价信息极少的情况下,这种假设的可信度不高。因为实际应用中庞大的用户喜好千差万别,不可能全部一样。这样的假设会导致推荐质量下降。
相关相似性的度量方法:
在相关相似性的度量方法中,所选用的数据是两用户共同评分的项目,保证了参与计算的数据都是真实数据。但实际情况是,在大多数情况下两用户共同评价的展品少之又少,并且很难找到。因此,仅凭两用户对几项展品有相同的兴趣就判断两用户为相似用户,将原有用户的所有浏览展项都推送给新用户,这种推荐质量是极低的。
综上,在相似度的计算中,首先,要保证参与计算的评分数据都是真实数据,不能一概假设为0,从而满足推荐精度;其次,在数据选择上要选取共同评分数量较多的两用户才能成为最近邻居,同时对项目评分较少的用户不能考虑;最后,实现实时推送就要降低算法的计算复杂度从而提高算法的计算效率。
1.3 基于相关相似性的CF算法改进
基于以上分析的三点,我们对原有基于相关相似性的计算方法做了两点改进,设计了一种新的度量方法:
第一,将用户a和用户b共同评分的项目数量与用户a选择的项目总数的比值作为调节系数,即S=∩(a,b)/∪(a)(比值公式:将用户a和用户b共同评分的项目数量与用户a选择的项目总数的比值作为调节系数)。从该式中可以看出,当原用户与新用户共同评分的展品数目较多时,S值偏大;反之则较小。由此可以控制共同评分数量较多的两用户才能成为最近邻居,从而提高推荐精度。
第二,在实验中发现,最终结果会受raj和ra及rbj和rb差值符号的影响。若raj 和 rbj一个大于其均值,另一个小于均值,那么其乘积结果为负数,导致计算后得出的相似度值为负数,造成新用户对其未评分的展品信息的推荐分数明显偏小,最终影响推荐结果。因此,为了保证相似度结果为正数,我们将raj和ra及rbj和rb差值的乘积加绝对值。纠正因计算结果负数带来的误差。
上式为最终改进的相似度计算方法。从式中可以看出,此计算结果可以保证大量参与评分,且评分项目种类大致相同的用户才能成为最近邻。
2. 实验结果及分析
实验选用MovieLens数据集。我们抽取了943位用户对1682部电影的评价数据共10万个。评价数据为1到5,5分为评价数据最高值,其余依次降低。
本文选用统计精度度量方法。MAE值越小,预测的准确度越高。
{p1,p2, …, pN}表示预测的用户评分集合, {q1,q2, …,qN}为对应的实际用户评分集合,则平均绝对偏差MAE 表示为:
我们分别计算了原有的两种相似性MAE值和在相关相似性基础上进行改进的MAE值。
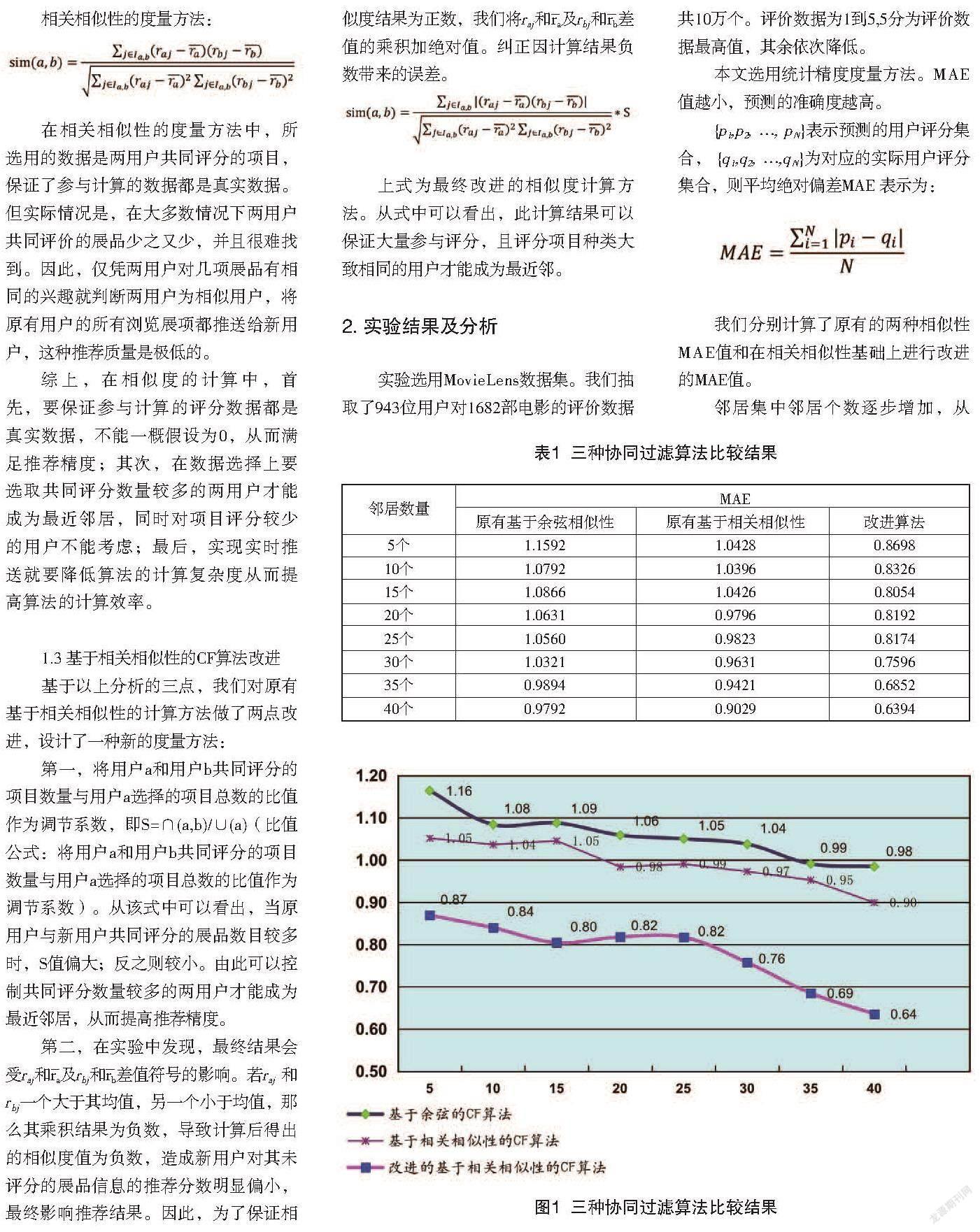
邻居集中邻居个数逐步增加,从而查看最近邻居集数量对预测效果的影响,实验结果如表1所示。
实验表明:本文提出的改进算法邻居集从5到40个绝对偏差由0.87到0.64逐渐降低,同原有基于余弦相似性和基于相关相似性算法相比,MAE值明显变小,取得较好效果,如图1所示。
3. 科技馆展品推荐系统工作流程设计
3.1 构造用户兴趣集
科技馆展品推荐系统中自动分析数据库中存入的用户个人信息。用户信息可以通过以下三种方式获取:
(1)邀请用户注册。在注册过程中,直接收集用户的喜好,这种方式收集到的兴趣信息直接且准确。
(2)隐式搜索用户信息。对于没有注册的用户,则采用跟踪用户浏览展品信息的行为进行兴趣的收集,如浏览展品的频次、下载展品的类型、检索、收藏等信息。这种方法收集到的信息会存在“杂音”,需要在后台进行修正和筛选,从而不断完善用户的兴趣信息。
3.2 构造展品资源集
收集各科技馆的展品信息,将展品数字化,构建展品信息库。
3.3 构造用户——展品评价矩阵
根据收集的用户兴趣集合展品信息集建立用户——展品评价矩阵。
3.4 计算用户之间的相似度,找出最近邻居
根据用户之间的共同喜好,计算最近邻的相似度。算法采用改进的基于相关相似性的相似性度量方法。
3.5 计算推荐集,产生推荐
根据计算出来的用户相似度计算推荐结果,预测新用户对其未浏览展品的预测值,产生新用户推荐。
结语
实体科技馆在其数字化演进的过程中,逐步由“解释它们是谁”变成“与它们的公众之间建立对话关系”,科技馆再也不仅仅是展品的“储藏室”,而是与用户进行社交互动的平台[3]。利用人工智能,通过数据挖掘技术实现展品信息的个性化推荐势在必行。
本文主要针对个性化推荐系统中协同过滤算法进行了分析和研究。在分析过程中,发现了原有相似性度量方法中存在的问题,并对其进行了两点改进:引入调节系数 S=∩(a,b)/∪(a),保证共同評分较多的两用户成为最近邻居;纠正了相关相似性取值正负的问题。实验证明,该算法同传统CF算法相比能显著提高推荐精度。最后基于改进的算法,设计了数字科技馆展品个性化推荐系统的工作流程。在展品推荐系统的工作流程中,展品资源的完善是我们需要努力解决的问题。将展品转化为可以利用的数字资源,集合整理国内外数字展品信息构造展品资源集是我们今后努力的方向。
参考文献:
[1]任贺春,赵铮.智慧服务智慧管理智慧共享——数字科技馆转型升级促进科技馆体系智慧化发展[J].自然科学博物馆研究,2022,7(1):58-63,113.
[2]马宇罡,莫小丹,苑楠,等.中国特色现代科技馆体系建设:历史、现状、未来[J].科技导报2021,39(10):34-47.
[3]何如珍.干部在线学习资源个性化推荐系统研究[J].电子技术与软件工程,2022,(13):259-262.
作者简介:赵智,硕士研究生,高级工程师,研究方向:人工智能与数据挖掘。
