三维补全关键技术研究综述
2023-04-10肖海鸿吴秋遐李玉琼康文雄
肖海鸿,吴秋遐,李玉琼,康文雄*
(1.华南理工大学 自动化科学与工程学院,广东 广州 510640;2.华南理工大学 软件学院,广东 广州 510006;3.中国科学院 力学研究所 国家微重力实验室,北京 100190)
1 引言
近年来,随着深度学习和传感器技术的快速发展,三维视觉受到了学术界和工业界的广泛关注,在目标检测[1]、语义分割[2]、三维重建[3]等领域都取得了突破性的进展。然而,一个固有的问题仍然存在,即由于物体遮挡、表面反射、材料透明、视角变换和传感器分辨率的限制,传感器在真实场景下所获取的数据并不完整,阻碍了下游任务的研究进展。在无人驾驶领域,三维补全技术可为环境感知任务提供精确的物体识别和跟踪信息[4]。在生产制造领域,三维补全技术可为机械臂抓取任务提供准确的物体位姿信息[5]。在文物保护领域,三维补全技术可为数字化的文物鉴定、检测和修复提供依据[6]。此外,三维补全技术还可为虚拟数字人的重建[7]和元宇宙生态体系的构建[8]奠定基础,如图1 所示。理解三维环境是人类的一种自然能力,人们可以利用学到的先验知识估计出缺失区域的几何和语义信息,然而,这对计算机而言是比较困难的[9]。

图1 研究目的导向图Fig.1 Research purpose oriented map
针对上述问题,研究人员开展了一系列围绕三维形状补全、三维场景补全和三维语义场景补全方面的研究工作。其中,三维形状补全可以提高场景理解的准确度,其目的是根据已观测到的局部形状恢复出物体的完整几何形状,其补全对象通常是单个物体[10]。传统的三维形状补全方法主要是通过几何对称性[11-12]、表面重建[13-16]、模板匹配[17-20]等方式进行补全。近年来,随着深度学习的发展,基于学习的形状补全工作[21-24]取得重要进展。然而,基于学习的形状补全方法目前大多是在合成数据集上进行,在真实场景下的补全效果仍然存在较大的提升空间。
三维场景补全是形状补全的扩展,需要在扫描的场景中对缺失部分进行补全[25],其核心在于补全后场景细粒度的保持。相较于形状补全,场景补全具有补全面积大和补全对象多的特点[25]。当缺失区域较小的时候,可以采用平面拟合[26]和插值[27]的方法。当缺失区域较大的时候,这类方法难以达到令人满意的结果。因此,一些工作试图通过模型拟合的方法[28-30]来得到干净而紧凑的场景表示。最近,利用深度神经网络直接作用于整个场景的生成补全方法[31-32]显示出了很大的研究潜力。然而,这类方法忽略了语义信息对场景补全的辅助,当补全的场景过于复杂时,其精度会有所下降。
三维语义场景补全是在场景补全的几何基础上同时估计出场景的语义信息。事实证明,语义信息和几何信息是相互交织耦合的[33]。换句话说,当在未完整观测一个物体的情况下,已知它的语义信息有助于估计出它可能占据的场景区域。如图2 所示,看到桌子后面的椅子顶部,推断出椅子的座位和腿的存在。同理,已知一个对象的完整几何信息,有助于识别其语义类别。然而,语义场景补全是相对复杂的,表现为数据的稀疏性和没有真实完整的地面参考值(通过多帧融合形成的参考值仅能提供较弱的监督信号)。相较于形状补全,语义场景补全需要深入了解整个场景,严重依赖于学习到的先验知识来解决歧义性。伴随着大规模语义场景数据集[34-37]的出现,基于深度学习的语义场景补全方法[38-41]相继被提出并取得不错的结果。然而,现有的方法在物体几何细节、模型内存占用、场景不确定性估计等方面还存在诸多不足。

图2 场景信息观测视角图Fig.2 Scene information observation perspective map
在过去几年,关于三维视觉的相关工作,如三维深度学习[42]、三维目标检测[43]、三维语义分割[44]、三维重建[45]、实时重建[46]等方面都有相对应的综述,但系统总结三维补全的工作几乎没有,而与本文并行的工作[47]也仅是总结基于点云输入的形状补全。本文将系统地介绍国内外在三维形状补全、三维场景补全和三维语义场景补全这三方面所展开的相关研究工作,并选取其中部分具有代表性的算法进行客观评价和归纳总结。最后,本文讨论了该领域目前存在的问题并展望了未来的发展趋势。希望本文能够对刚进入这一新兴领域的研究者起到导航的作用,同时,也希望能够对相关领域的研究者提供一些参考和帮助。
本文的后续内容安排为:第2 节整理三维补全相关数据集和评价指标;第3 节根据模型构建过程中有无神经网络的参与,将现有的形状补全算法分为传统方法和基于深度学习方法两大类并进行梳理与小结;第4 节分别从模型拟合和生成式的角度梳理了场景补全任务中具有代表性的算法并进行小结;第5 节根据输入数据的不同类型,分别从深度图输入、深度图联合彩色图像输入、点云输入三方面梳理了语义场景补全任务中具有代表性的算法并进行小结;第6 节讨论了三维补全领域存在的问题,并对未来可能的发展方向进行展望;第7 节对本文内容进行总结。
2 数据集和评价指标
2.1 数据集
随着传感器技术的突破和三维视觉的快速发展,三维补全相关数据集的广泛获取成为可能。为了便于研究者能够直接展开相关工作,本文汇总了常用的数据集,并根据数据集的类型不同,将其划分为合成数据集和真实数据集。其中,合成数据集包括:ShapeNet-Part(ShapeNet[48]子 集)、SUNCG[33]、Fandisk[49]、Raptor[49]和NYUCAD[31],真实数据集包括:KITTI[50]、Scan-Net[51]、Matterport3D[52]、DFAUST[52]、MHAD[53]、NYUv2[54]、tabletop[31]、Semantic KITTI[35]和SemanticPOSS[37]。数据集的详细介绍如表1 所示。
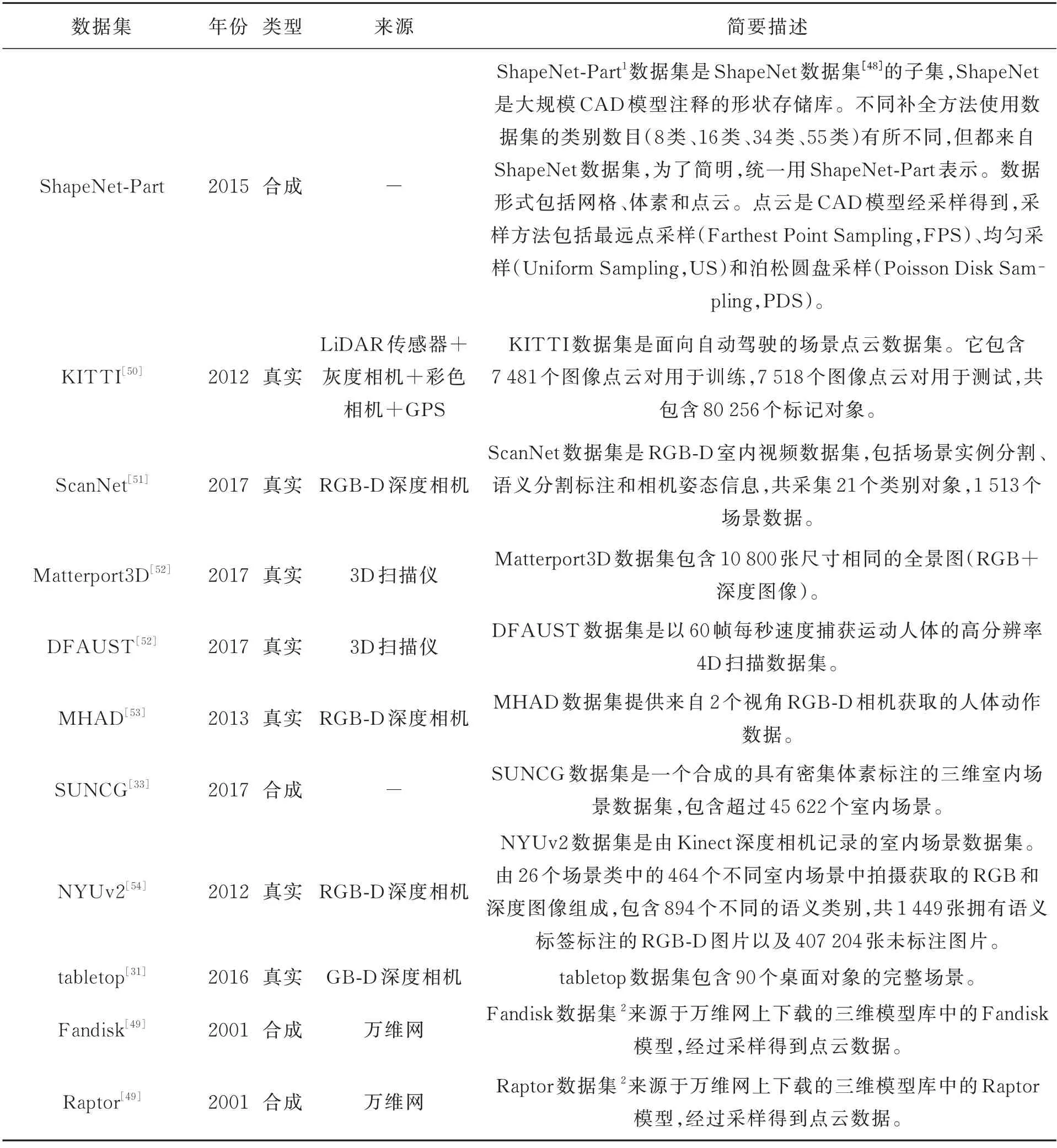
表1 三维补全相关数据集Tab.1 3D completion related datasets

续表1 三维补全相关数据集Tab.1 3D completion related datasets
2.2 评价指标
2.2.1 形状补全结果评价指标
由于三维形状表示的不同形式,补全结果的评价标准也是不同的。针对体素网格形式的补全评价标准,主要采用一定分辨率下的误差率衡量补全性能的好坏(误差率即补全形状和真值之间的差异体素网格数除以真值体素网格总数)[55]。针对三角网格或多边形网格形式的补全评价标准,主要是通过计算补全网格顶点和真值网格顶点之间的平均欧几里得距离(Euclidean Distance,ED)进行评估[56]。针对点云表示的补全评价标准,大多数方法采用补全点云与真值点云之间的倒角距离(Chamfer Distance,CD)[10]或地球移动距 离(Earth Mover′s Distances,EMD)[10]进行评估,其公式定义如下:
其中:P1和P2分别表示生成的点云和真实完整点云,a和b分别表示P1和P2中的点,φ表示双向映射函数。
Shu 等[57]提出弗雷歇点云距 离(Fr′echet Point Cloud Distance,FPD)用于衡量补全点云与真实点云之间相似度,其公式定义如下:
其中:mP1和mP2分别表示生成点云和真实点云的特征向量,ΣP1和ΣP2分别表示生成点云和真实点云的协方差矩阵,Tr(A)表示矩阵A 的主对角线元素之和。
Wu 等[58]提出密度感知倒角距离(Density-Aware Chamfer Distance,DCD),和 原始CD 相比,它对密度分布的一致性更加敏感,而和EMD相比,它更擅长于捕捉局部细节,其公式定义如下:
其中:α表示温度标量,P1和P2分别表示生成的点云和真实完整点云。
Chen 等[59]提出视觉相似度评价指标——光场描述符(Light Field Descriptor,LFD)。它的原理是对3D 形状渲染的2D 视图通过Zernike 矩阵和傅里叶变换(Fourier Transform,FT)进行相似度分析。对于一些无监督的点云补全方法,由于没有真值参考,使用单向倒角距离(Unidirectional Chamfer Distance,UCD)[60]或单向豪斯多夫距离(Unidirectional Hausdorff Distance,UHD)[60]进行评估。
2.2.2 场景补全结果评价指标
在场景补全任务中,由于最终输出场景的表示形式不同,因此也有不同的评价标准。大多数方法输出的场景表示是TSDF[25]编码的矩阵,因此常用L1距离[32]作为评价标准。其中,一些方法的输出是网格或点云。因此,可以使用CD[10]、EMD[10]、FPD[57]和DCD[58]作为评价指标。对于基于模型拟合的场景补全方法,其评价标准大多采用模型对齐精度[28]作为评价指标。Dahnert等[30]使用混淆分数(Confusion Score,CS)衡量嵌入空间的学习程度,以此进一步衡量补全模型和CAD 模型之间的平衡程度。
2.2.3 语义场景补全结果评价指标
在三维语义场景补全任务中,评价指标是相对统一的,为预测结果和真值结果之间的交并比(Intersection over Union,IoU)[33]或平均交并比(Mean Intersection over Union,mIoU)[33],其 公式定义如下:
其中:NTP表示“正阳性”即预测已占用体素结果中的预测正确的样本数量,NFP表示“假阳性”即预测错误的样本数量,NFN表示“假阴性”即未被检测到的已占用体素数量,C表示类别。
3 三维形状补全
3.1 基于传统的形状补全方法
3.1.1 基于对称的方法
对称是自然界广泛存在的一种现象,对称性是重要的科学思维方法之一,最初的形状补全方法主要是利用物体或空间呈现的几何对称性[11-12]恢复缺失区域的重复结构。该方法假设了缺失的几何部分在现有的部分观测信息中具有重复结构,对于大部分呈现立体对称结构的简单物体是有效的。然而,对称性假设并不适用于自然界中的所有物体。
3.1.2 基于表面重建的方法
现有的表面重建方法主要分为插值和拟合两种方式[13]。插值是将表面上集中的数据点作为初始条件,通过不同算法执行插值操作得到密集表面。拟合是利用采样点云直接重建近似表面,通常以隐式形式表示。
Lee 等[14]提出基于多层B 样条的快速分散数据插值算法。该算法在插值效果和计算时间上都具有较好的优势。但在选点方式和定义权重上存在一定的困难,导致重建的表面存在不连续情况。Price 等[15]采用分形插值方法来重建三维曲面。与传统插值方法相比,分形插值在拟合具有分形特征或较为复杂的事物时具有优势。但它计算复杂,并且分形的参数H较难估计。泊松表面重建[13]是一种隐函数表面重建方法,它通过平滑滤波指示函数构建泊松方程,将表面重建问题等同为泊松方程的求解问题。通过对该方程进行等值面提取,得到具有几何实体信息的表面模型;其构建的表面能容忍一定程度的噪声,但存在过度平滑问题。针对泊松表面重建的过度平滑问题,Kazhdan 等[16]通过引入样本点的位置约束,将其表示为屏蔽泊松方程进行求解,生成更为贴合的表面,但该方法比较依赖于准确的点云法向量。尽管以上基于插值和拟合的表面重建方法都取得了较好的结果,但这类方法通常用于孔洞修复,存在补全面积小的限制。
3.1.3 基于模板匹配的方法
基于模板匹配的形状补全方法主要包括部分形状匹配方法[17]和整体形状匹配方法[18]。部分形状匹配主要是在预先定义的大型形状模型库中寻找能够最佳拟合的对象部件,然后将它们组装起来获得完整形状。整体形状匹配是在模型库中直接检索完整的最佳拟合形状。其中,寻优算法的选取对最终模板匹配的结果起到至关重要的作用。
Rock 等[19]提出模型变形的匹配方法,其核心是将从数据库中检索到的候选模型执行非刚性曲面对齐使其形状变形以拟合输入。Sun 等[20]进一步提出基于补丁的检索-变形方法。该方法首先从输入形状中选择候选补丁,其次,对检索到的候选对象执行变形操作并缝合成完整形状。该方法可以重建在拓扑结构上不同于训练数据的形状。尽管基于模板匹配的方法取得了较好的补全结果。但这类方法通常存在寻优速度慢和对噪声比较敏感的问题。同时,它依赖于较大的模型库来覆盖补全的全部形状,这在真实世界中往往是不切实际的。
3.2 基于深度学习的形状补全方法
目前常用的三维数据表示形式包括点云[61]、体素[62]和网格[63]。尽管最近基于深度隐式表示的方式,如占用网络(Occupancy Networks)[64]、连续符号距离函数(Sign Distance Function,SDF)[65]和神经辐射场(Neural Radiance Field,NeRF)[66]在三维重建和三维语义场景补全任务中有相关的工作。但在形状补全任务中,目前大多数补全方法都依赖于点云的数据形式,这不仅与点云自身的特性有关,即存储空间小且表征能力强,还与点云数据集相对容易获取有关。
基于学习的形状补全方法根据其算法原理,可归纳为6 种主要类型:基于逐点的多层感知机(Multi-layer Perceptron,MLP)方法[10,21-24,67-68]、基于卷积的方法[69-72]、基于图的方法[56,73-76]、基于生成对抗的方法[77-81]、基于Transformer 的方法[82-83]和其他方法[65,84-85],其发展历程如图3 所 示。下面,本文将对其中具有代表性的一些算法进行介绍和总结。

图3 基于深度学习的三维形状补全方法发展历程Fig.3 Development history of 3D shape complementation methods based on deep learning
3.2.1 基于逐点的MLP 方法
点云是三维形状补全任务中最常使用的数据形式。尽管它具有存储空间小且表征能力强的优点,但是它的无序性和不规则性也给特征提取带来了巨大挑战。PointNet[61]是首个被提出直接作用于点云数据的深度学习网络,它采用MLP 对每个点进行独立地特征提取。然后,使用最大池化(Max Pooling)函数得到点云的全局特征。得益于这项工作的启发,基于逐点的MLP 形状补全算法相继被提出[10,21-24,67-68]。
作为点云形状补全的开创性工作,PCN[10]遵循编码器-解码器范式来完成点云补全任务。编码器主要由堆叠的MLP 层构成,解码器包括全连接层解码器[21]和折叠解码器[22]两部分。其中,全连接层解码器负责估计点云的几何形状,而折叠解码器负责近似出局部几何形状的光滑表面。尽管该算法能够获得较好的完整点云和稠密点云,基于折叠的二维网格变形操作在某种程度上会限制三维点云的几何表达。Tchapmi 等[23]提出分层的树结构点云补全网络TopNet,其核心思想是采用基于MLP 的树解码器生成结构化的完整点云。该算法允许网络学习任意的拓扑结构,而不是强制执行某一种拓扑结构。然而,该算法需要足够的冗余空间来学习任意的体系结构,因此,解码器的容量在某种程度上会限制学习到的拓扑结构。
Huang 等[24]提出点云分形网络PF-Net。首先,该算法使用FPS 采样方法将输入点云下采样为不同分辨率的点云。其次,使用提出的组合多层感知机(Combined Multi-layer Perception,CMLP)分别进行特征提取并融合成全局特征向量。最后,将得到的全局特征向量输入到点云金字塔解码器(Point Pyramid Decoder,PPD)进行多阶段预测。该算法采用的多分辨率特征提取方法能够更好地捕获输入点云的局部特征。然而,PF-Net 仅预测缺失的点云,对已有的部分不进行预测,导致生成的点云和已有的点云在拼接时存在间隙。Liu 等[67]提出两阶段的稠密点云补全算法MSN。首先,该算法通过自动编码器预测一个完整但粗粒度的点云。其次,通过采样算法将粗粒度的预测和输入点云合并生成致密点云。值得一提的是,为了防止参数化表面元素的重叠,文中提出扩展惩罚损失来引导表面元素集中在一个局部区域。Tang 等[68]提出基于关键点-骨架-形状预测的点云补全算法LAKe-Net,该算法主要包括3 个步骤:(1)使用非对称关键点定位器(Asymmetric Keypoint Locator,AKL)定位出输入点云和完整点云中对齐的关键点;(2)利用基于几何先验的关键点生成表面骨架来充分显示拓扑信息;(3)使用递归细化模块辅助点云骨架的精细化完成。该算法严重依赖于缺失和完整的形状匹配对进行监督训练。在某些情况下,完整的点云数据是无法获取的,从而限制了其在实际场景下的适用性。
尽管基于逐点的MLP 形状补全算法表现出不错的性能,但仍然存在着以下局限:
(1)基于逐点的MLP 算法大多沿用PointNet的特征提取思路,而这种方式是独立的处理每个点,忽略了相邻点之间的几何关系。
(2)一些方法采用了由粗到细的点云生成策略,但是它们对形状的高频信息并不敏感,难以对复杂的拓扑结构进行友好生成。
3.2.2 基于卷积的方法
卷积神经网络(Convolutional Neural Network,CNN)[86]近年来在视觉图像领域取得了巨大的成功,其相关工作也启发了研究者使用体素来表示三维形状。相较于点云的无序形式,体素更贴近于规则像素的表达方式,同时也更容易使用CNN 进行特征提取和学习。
3D-EPN[69]使用三维卷积层组成的编码-解码器网络预测部分输入的完整形状,但是随着分辨率的提升,计算量会呈指数增加,给网络的训练带来了极大挑战。Xie 等[70]提出网格残差网络GRNet,通过将无序点云转为规则网格的中间表示,然后利用3DCNN 进行特征提取和中间数据生成,最后将生成的网格单元再次转化为点云形式。此外,该算法设计了立方特征采样(Cubic Feature Sampling,CFA)层来提取相邻点信息和上下文信息。然而,该方法存在以下2 个缺点:(1)点云体素化的过程不可避免的导致信息丢失;(2)体素表示仅适用于低分辨率的形状重建。
Wang 等[71]提出基于体素的多尺度点云补全网络VE-PCN。相比于GRNet 采用逆体素点云化策略生成粗糙点云,VE-PCN 增加了边生成器(Edge Generator)将补全对象的高频结构信息注入到形状补全分支中,并取得较好的补全结果。需要注意的是,这里的高频结构信息指代三维对象的边缘结构信息[71]。Liu 等[72]提出多分辨率各向异性卷积网络MRAC-Net。文中设计了一种多分辨率各向异性卷积编码器(Anisotropic Convolutional Encoder,ACE)提取三维对象的局部和全局特征,以提高网络对语义和几何信息的理解能力。此外,该网络提出的组合金字塔解码器能够分层输出不同分辨率的完整结构点云,实现更好的监督。
尽管基于卷积的形状补全算法均表现出不错的性能,但是仍然存在着以下局限:
(1)内存随分辨率呈立方增加,现有的网络算法依旧局限于相对较低的分辨率。
(2)使用体素的中间表示会不可避免的导致细节丢失。
3.2.3 基于图的方法
点云作为一种无序的非欧几里德结构数据,无法直接将经典的CNN 应用于点云学习,点云中的拓扑信息由点之间的距离隐式表示。因此,一种可行的思路是将点云中的点看作图顶点,使用图卷积网 络(Graph Convolutional Network,GCN)[87]提取邻域顶点间的结构信息。动态图CNN(Dynamic Graph CNN,DGCNN)[87]使用一种可插拔的边卷积(EdgeConv.)模块动态地捕获点云的邻域特征,该工作也启发了后续基于图卷积的形状补全工作[56,73-76,88]。
Litany 等[56]提出基于可变形的形状补全方法GCNet,其核心是通过一个带有图卷积的变分自动编码器(Variational Autoencoder,VAE)来学习完整真实形状的潜在空间表示。然而,该方法假定所有的形状都与一个共同的参考形状相对应,从而限制了对某些类别形状的适用性。Zhang等[73]提出3D 目标检测网络PC-RGNN。他们首次使用点云补全技术辅助三维目标检测任务,设计了一种基于注意力的多尺度图卷积(Attention Based Multi-scale Graph Convolution,AMSGCN)模块来编码点之间的几何关系,增强对应特征的传递。在点云生成阶段,该方法沿用了PF-Net 的思路,采用PPD 生成多阶段的完整点云,在补全数据集和检测数据集上均表现良好。Pan[74]提出具有图卷积的边缘感知点云补全网络ECG。该网络包括两个阶段,第一阶段生成粗糙的骨架,以方便捕获有用的边缘特征;第二阶段采用图卷积层次编码器来传播多尺度边缘特征,以实现局部结构的细化。为了在上采样时保留局部几何细节,作者进一步提出边缘感知特征扩展(Edge-aware Feature Expansion,EFE)模块来平滑上采样点的特征。实验结果表明,该算法在稠密点云的生成方面具有一定的优势。
Shi 等[75]提出一种以输入数据和中间生成为控制点和支撑点的图引导变形网络GGD-Net,通过利用网格变形方法模拟最小二乘的拉普拉斯变形过程,这为建模几何细节的变化带来了自适应。据公开文献[75],这是第一个通过使用GCN引导变形操作来模拟传统图形算法优化的点云补全工作,在室内和室外数据集上均表现良好。Cai 等[76]提出无监督 点云补全方 法LSLS-Net。他们认为不同遮挡程度的缺失点云共享统一完整的潜在空间编码,其核心思想是引入遮挡码对潜在空间的统一编码进行掩码,再通过解码器对掩码的潜在编码解码成不同遮挡比例的残缺点云。编码器主要包括多个EdgeConv 层,解码器主要由多层MLP 组成。尽管该方法在泛化性上取得了较好的结果,但是该方法设计的解码器较为简单,在补全结果的细节性上还有待提升。
基于图的形状补全算法在邻域特征提取上表现出良好的性能,但是仍然存在着以下局限:
(1)基于图的形状补全方法大多是采用K 近邻(K-nearest Neighbor,KNN)算法选取每个点的n个最近点作为它的邻居集合,然后利用图滤波操作来学习这些点的表示。然而,n的取值会极大地影响网络的性能。此外,KNN 算法对点云的密度分布非常敏感。
(2)基于图的算法是相对耗费时间的,当点云数据更大或者堆叠的图模块更多时,其内存消耗更为明显。因此针对点云的图浓缩(Graph Condensation)[88]技术是值得探讨的。
3.2.4 基于生成对抗的方法
生成对抗网络(Generative Adversarial Network,GAN)[89]创新性地采用了相互对抗的网络框架,通过生成模型和判别模型进行最小化和最大化博弈学习不断提升数据的生成能力。为了提升点云的生成质量,相关研究者结合GAN 来完成形状补全任务。
Sarmad 等[77]提出将自动编码器(Autoencoder,AE)、GAN 和强化学习(Reinforcement Learning,RL)相结合的点云补全网络RL-GANNet。通过RL 代理优化GAN 的潜在变量输入,并使用预训练解码器对GAN 生成的潜在全局特征向量解码为完整点云。然而,多阶段训练过程增加了网络的复杂性。此外,基于RL 的代理控制难以找到最优的潜在变量输入。Wang 等[78]提出级联细化补全网络CRNet,该方法遵循由粗到细的生成策略。在第1 阶段采用PCN 的特征提取方式通过全连接层生成粗糙点云,在第2 阶段引入条件迭代细化子网络生成高分辨的点云。为了提升生成点云的逼真性,文中提出了块判别器(Patch Discriminator)来保证每个区域都是真实的。此外,该方法加入类别的平均形状先验信息来提升补全结果的完整性,但同时也降低了类内补全结果的多样性。此外,由于块之间的互斥性易导致生成点云的不均匀分布。
Hu 等[79]将点云的补全问题转化为深度图补全问题。通过将点云从固定视角渲染成8 个多视图,并执行每个视图的补全。值得一提的是每个视图的补全并不是独立的,而是利用所有视图的信息来辅助每一个视图的补全。此外,为了提升深度图补全的逼真性,采用深度图判别器对补全结果和真实点云的渲染结果进行真假判断。然而,该方法缺乏对点云的直接监督,通过渲染的方式会导致信息的丢失。Xie 等[80]提出基于风格生成和对抗渲染的点云补全网络SpareNet。该算法分别从特征提取、点云生成和优化三个方面进行了改进。针对特征提取部分,引入通道注意力的边卷积(Channel-attentive EdgeConv,CAEdgeConv)模块来增强点云的局部特征提取能力。针对点云生成部分,通过将学习到的特征作为样式码(Style Code)来提高折叠生成能力。为了进一步优化生成质量,引入了可微分对抗渲染器来提升点云的视觉逼真度。该方法在ShapeNet-part和KITTI数据集上均表现良好。
Wen 等[81]提出双向循环的无监督点云补全网络Cycle4Completion,与现有的无监督形状补全方法不同[60,76],之前的方法都只考虑从缺失点云到完整点云的正向对应关系,而该算法同时考虑了正向和逆向的对应关系。此外,该算法中判别器的输入是潜在表示而不是点云。潜在表示在这里代表一个完整点云的特征向量,根据这个特征向量能够恢复出点云结构。然而,双向循环网络需要单独建模,这对训练过程提出了较大的挑战。Zhang 等[60]提出无监督形状反演补全网络ShapeInversion,首次将GAN 逆 映射(GAN Inversion)引入到点云补全任务中。类比GAN 逆映射在二维图像修复中的应用,文中提出了kmask 退化函数将生成的完整点云转化为与输入点云对应的残缺点云。利用GAN 提供的先验知识,ShapeInversion 在多个数据集上表现出优异的结果,甚至超过了部分有监督方法。然而,该方法需要额外的预训练生成模型,降低了其在实际情况下的适用性。
尽管基于生成对抗的形状补全算法在相关数据集上均表现良好,但是仍然存在着以下限制:
(1)虽然相比于直接训练GAN 生成完整点云的方式,在潜在空间表示上训练GAN 会相对容易。但是,训练GAN 需要达到纳什均衡,因此其训练过程充满着不稳定性。
(2)在无监督形状补全方法中,一些算法需要借助额外的预训练生成模型,这会大大降低算法在实际情况下的适用性。
3.2.5 基于Transformer 的方法
近 两年,Transformer[90]在自然语言处理、计算机视觉和语音处理领域取得了巨大成功,吸引了研究者的广泛关注。原始的Transformer 模型主要包括编码器和解码器,其中编解码器主要由多头注意力(Multi-head Self-attention,MSA)模块和前馈神经网络(Feed-forward Network,FFN)组成;而解码器的内部结构与编码器类似,在MSA 模块和FFN 模块之间额外插入了一个交叉注意力(Cross-attention,CA)模块。受此启发,Zhao 等[91]提出Point transformer 框架,在点云分类和语义分割任务上达到了当时的最先进水平。几乎同一时间,Guo 等[92]提出了Point cloud transformer 网络,在点云分类、法向量估计和语义分割任务上均表现优异。
Yu 等[82]首次将Transformer 应用到点云补全任务中,即PointTr。该方法将无序点云表示为一组带有位置嵌入的无序点组,从而将点云转换为一系列点代理,并使用几何感知的Transformer 编码-解码器生成缺失部分的点代理(Point Proxy)。最后,基于生成的点代理结合折叠网络生成细粒度的缺失点云。然而,Transformer 模型的二次方计算量需要极大的显存和内存占用。Zhang 等[83]提出具有骨架-细节Transformer 的点云补全框架SDTNet,该方法遵循由粗到细的生成策略。该算法探索了局部模块和骨架点云之间的相关性,有效地恢复出点云细节。此外,文中引入了一种选择性注意力机制(Selective Attention Mechanism,SAM),在显著降低Transformer 记忆容量的同时而不影响整体网络性能。
尽管基于Transformer 的形状补全方法在相关数据集上表现优异,但仍然存在着以下局限:
(1)Transformer 的二阶计算量和内存复杂度极大地限制了它的可适用性。
(2)由于Transformer 的计算复杂度会随着上下文长度的增加而增长,这使其难以有效地建模长期记忆。
(3)Transformer 对形状补全的增益需要更多的训练数据作为基础。
3.2.6 其他方法
Pan 等[84]提出变分关系点云补全网络VRCNet,它由概率建模子网络和关系增强子网络级联而成。在第1 阶段,通过重建路径引导补全路径学习生成粗粒度完整点云,实现从高层次的特征分布到低层次的信息流动。在第2 阶段,通过并联的多尺度自注意力模块增强点云的细节生成,该算法显著提升了点云的细节生成能力。
Zhang 等[85]提出视觉引导的跨模态点云补全网络ViPC。不同于现有的算法仅依赖部分点云作为输入,该算法从额外输入的单视图中挖掘缺失点云的全局结构信息作为引导。此外,该算法引入动态偏移预测器(Dynamic Offset Predictor,DOP)和差分精调策略(Differential Refinement Strategy,DRS)对低质量点进行维精调,对高质量点执行重度精炼,并在所提出的ShapeNet-ViPC 数据集上取得了最好的结果。
Park 等[65]提出基于学习的深度隐式形状补全算法DeepSDF。该方法利用连续SDF 生成像水一样密集的封闭形状表面,不仅具有良好的视觉效果,需要的内存空间也大幅降低,为在复杂形状的生成方面提供了新的思路。
3.3 分析与小结
分析不同类型的三维形状补全方法,并根据表2、表3 和图4 所示的部分方法对比结果,得出下列结论:

图4 部分形状补全方法结果对比Fig.4 Comparison of the results of some shape completion methods
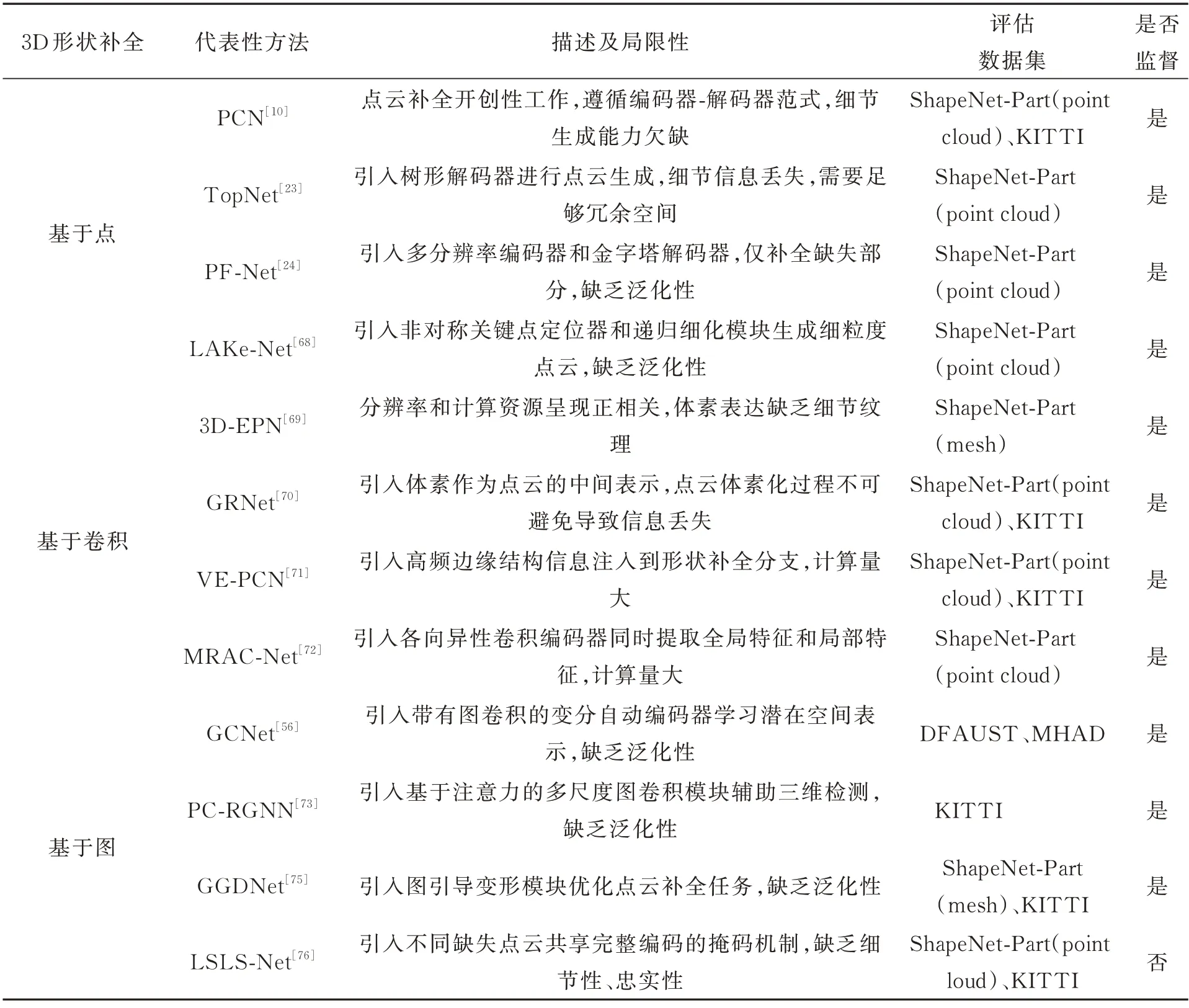
表2 基于深度学习的三维形状补全主要方法对比Tab.2 Comparison of the main methods of 3D shape completion based on deep learning
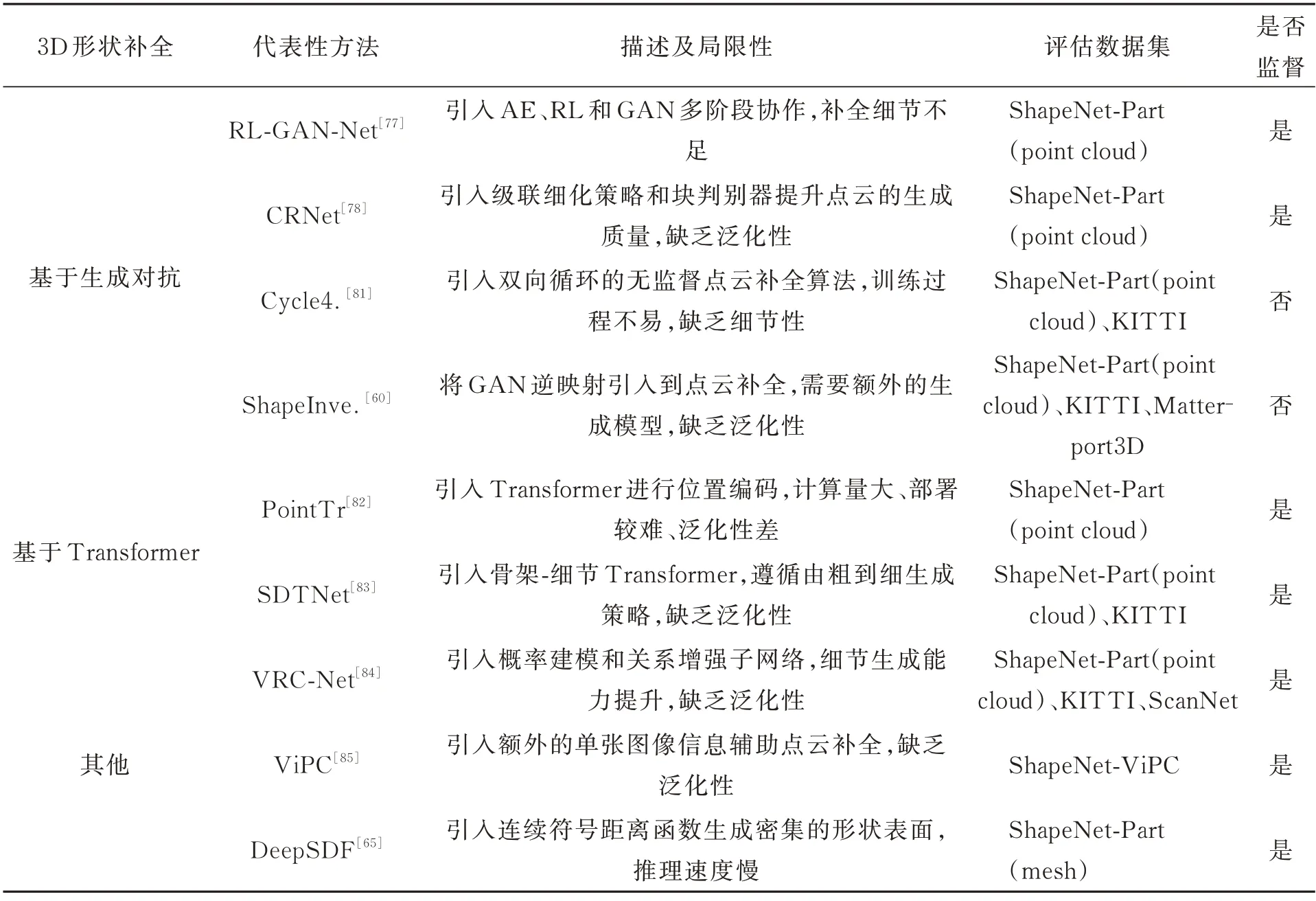
续表2 基于深度学习的三维形状补全主要方法对比Tab.2 Comparison of the main methods of 3D shape completion based on deep learning

表3 Completion3D 数据集上部分方法的定量结果Tab.3 Quantitative results of partial methods on the Completion3D dataset
(1)在基于深度学习的三维形状补全工作中,点云因其存储空间小、表征能力强的特点,成为广泛使用的三维数据表示形式。因此,基于点云的深度学习补全算法也成为当今的研究热点之一。
(2)之前的形状补全方法严重依赖于形状匹配对的形式进行监督训练,在域内数据集上能够表现出较好的结果,当扩展到其他部分形状数据集或真实世界所观测的部分数据时,模型泛化性还存在较大的提升空间。同时,考虑到在真实情况下获取的数据是没有对应真值的。因此,无需匹配对的无监督形状补全方法仍然是进一步研究的方向。
(3)现有方法难以对形状细节进行精细补全。同时,很少有方法考虑补全结果的忠实性,即补全生成的点能否忠实地落在真值参考点或面上。在最近的深度隐式重建[65]和点云上采样[93]工作中,忠实性问题有被提到。因此,点云补全的忠实性也是形状补全任务需要考虑的因素。
4 三维场景补全
围绕三维形状补全的研究已经有较多的工作,但关于场景补全的工作仍然较少。一方面原因在于相较于形状补全,场景补全具有补全面积大和补全对象多的特点[28]。另一方面在于场景补全任务希望补全的缺失内容与现有场景内容的语义信息是一致的[32],而这也是场景补全的主要挑战。
尽管场景补全面临着以上挑战,但其中仍不乏优秀的研究工作,根据场景补全算法所遵循的主要策略,可将其归纳为2 种主要类型:基于模型拟合的场景补全方法[28-30,94]和基于生成式的场景补全方法[25,31-32,95-98],其发展历程 如图5 所示。下面,本文将对发展进程中具有代表性的算法进行介绍和总结。

图5 三维场景补全方法发展历程Fig.5 Development history of 3D scene complementary methods
4.1 基于模型拟合的场景补全方法
针对场景缺失区域较小时,可以通过平面拟合[26]和表面插值[16]这类早期方法进行补全。然而,这与艺术家所需求的精细化场景模型相比是远远不够的。一个可行的思路是通过从预先创建的形状数据库中检索一组CAD 模型,并将它们与不完整扫描场景中的形状对象进行对齐、替换,以此来得到干净而紧凑的场景表示,如图6所示。

图6 模型拟合场景Fig.6 Model fitting scenario
Avetisyan 等[28]提出CAD 模型对齐的场景补全算法Scan2CAD。首先,将RGB-D 扫描的场景数据通过体融合(Volumetric Fusion)方式[99]转换成有符号距离场表示,并使用Batty 提供的SDFGen 工具包计算CAD 模型的无符号距离场。其次,使用3DCNN 学习场景对象和CAD 模型对象之间的嵌入关系,并预测出对应的热图。最后,基于对应的热图,通过变分优化公式(Variational Optimization Formulation,VOF)优化对齐的结果。该算法在Scan2CAD 基准上超越了基于手工特征的方法和基于CNN 的方法。Avetisyan等[29]提出一种端到端的CAD 模型检索对齐算法RALNet。该算法提出了可微概率对齐策略和对称几何感知策略,并通过全卷积网络(Fully Convolutional Network,FCN)一次对齐场景中检测到的所有对象,在速度上具有较大的提升。Dahnert 等[30]提出联合嵌入的场景补全方法,简称JENet。利用堆叠沙漏方法(Stacked Hourglass Approach)从扫描场景中分离出对象并将其转化成类似CAD 模型的表示形式,以学习一个共享的嵌入空间用于CAD 模型检索。该算法在实例检索精度方面比当时最先进的CAD 模型检索算法提高12%。Zeng 等[94]提出基于数据驱动的三维匹配描述符3DMatch。该算法通过学习局部空间块的描述符来建立局部三维数据的对应关系。为了获取训练数据,提出了一种自监督的特征学习方法在现有的RGB-D 重建结果中获取大量的对应关系。实验结果表明该描述符不仅在重建的局部几何匹配上表现良好,还可以泛化到不同的任务和空间尺度中。
尽管基于模型拟合的场景补全方法取得了一定的进展,然而,这类方法存在固有的自身局限性,主要包括两个方面:
(1)模型库中模型并不能包括真实场景中的所有对象。
(2)模型拟合方法对场景中的实例对象进行补全,但对场景中的背景信息通常不进行补全,例如墙壁和地面。
4.2 基于生成式的场景补全方法
近两年,基于深度学习从部分RGB-D 观测信息中生成完整场景的方法显示出较大的研究前景。其中,基于截断符号距离函数(Truncated Signed Distance Function,TSDF)[25]的体素编码是常用的数据处理形式和场景输出表征形式,如图7 所示。

图7 场景生成补全Fig.7 Scene generation complementary
Dai 等[25]提出能够处理任意比例大小的场景补全网络SCNet。首先,将RGB-D 观测的局部场景深度图通过体融合方法生成TSDF 编码的场景表示;其次,利用3DCNN 进行场景生成补全。其算法补全过程遵循由粗到细的策略,在补全质量和处理速度方面都有大幅度的提升。Firman 等[31]提出一种结构化预测的场景补全算法Voxlets。算法核心是使用结构化的随机森林(Structured Random Forest,SRF)从局部观测的深度图中估计出周围表面形状。然而,该算法补全的场景较小,仅适用于桌面大小的场景。Wang 等[95]提出基于八叉树卷积神经网络(Octree-based Convolutional Neural Networks,OCNN)的场景补全算法。该算法以类似U-Net[100]的结构进行特征提取,并引入以输出为引导的跳跃连接方式来更好地保持输入数据的几何信息。值得一提的是,该算法具有较高的计算效率,并支持深层次的O-CNN 结构,在形状补全数据集和场景补全数据集上取得了较好的实验结果。Azinović 等[96]同时使用NeRF 和TSDF 实现高质量的场景表示。该方法具有两个优势:(1)虽然目前使用NeRF 的体渲染新视图合成方法显示出了良好的结果,但是NeRF 不能重建实际的表面,当使用标记立方体(Marching Cube,MC)提取曲面时,基于密度的曲面体积表示会导致伪影。因此,该方法使用隐式函数来表示场景曲面。在这里,隐式函数为截断符号距离函数。(2)该方法整合了深度先验信息,并提出了姿态和相机细化技术来改善重建质量,在真实数据集ScanNet 上取得了较好的场景表示结果。Han等[101]提出基于深度强化学习的场景表面生成算法。该算法创新性地引入了深度强化学习策略来确定场景补全的最优视点序列。此外,为了保证不同视点之间的一致性和更好地利用上下文信息,该算法进一步提出了体素引导的视图补全框架产生高分辨率的场景输出。
尽管上述方法在大规模域内数据集,如SUNCG[33]、ShapeNet[48]和NYUv2[54]上,取得了较好的补全效果,但扩展到其他观测的不完整场景数据集时,由于数据集间的域差距,其补全的效果仍然是有限的。同时,在大部分真实场景下,是没有与之对应的完整场景真实值的。为了解决上述有监督方法的缺陷,一些无监督的场景补全方法被提出。
Dai 等[32]首次提出自监督的场景补全算法SG-NN,该算法直接在不完整场景数据上进行训练,其核心思想是在RGB-D 扫描的场景信息中移除部分图像以此得到更加不完整的场景信息。然后,通过在这两个不同程度的缺失场景中构建自监督信号进行训练,并最终得到以TSDF 表示的高分辨率场景。受SG-NN 的启发,Dai 等[97]提出一种能够同时补全场景几何信息和颜色信息的自监督算法SPSG。值得一提的是该算法对于几何信息和颜色信息的推断不是依赖于模型补全的3D 损失,而是依赖于在模型渲染所得到的2D 图像上进行监督引导,这样充分利用了原始RGD-D 扫描的高分辨率图像信息。Chen 等[98]介绍了一种基于点云中间表示的场景补全框架CIRCLE。该算法首先将RGB-D 深度图在已知相机位姿的情况下转化为点云数据,其转换过程遵 循Kinectfusion[102]。其 次,分别使用Point Encoder、UNet 和SDF Decoder 进行特征提取和几何补全。最后,使用可微分隐式渲染(Differentiable Implicit Rendering,DIR)模块进行补全细化。该算法不仅具有更好的重建质量,而且在速度上比第2 名快10~50 倍。
尽管以上无监督场景补全方法在真实数据集上取得了令人振奋的结果,但是他们在复杂场景的生成方面仍存在不足。由于缺乏先验信息的引导,在面对更加复杂的场景时,不同对象的生成结果具有歧义性。
4.3 分析与小结
对比分析不同类型的三维场景补全方法,并根据图8 和表4、表5 中的部分方法对比结果,得出下列结论:
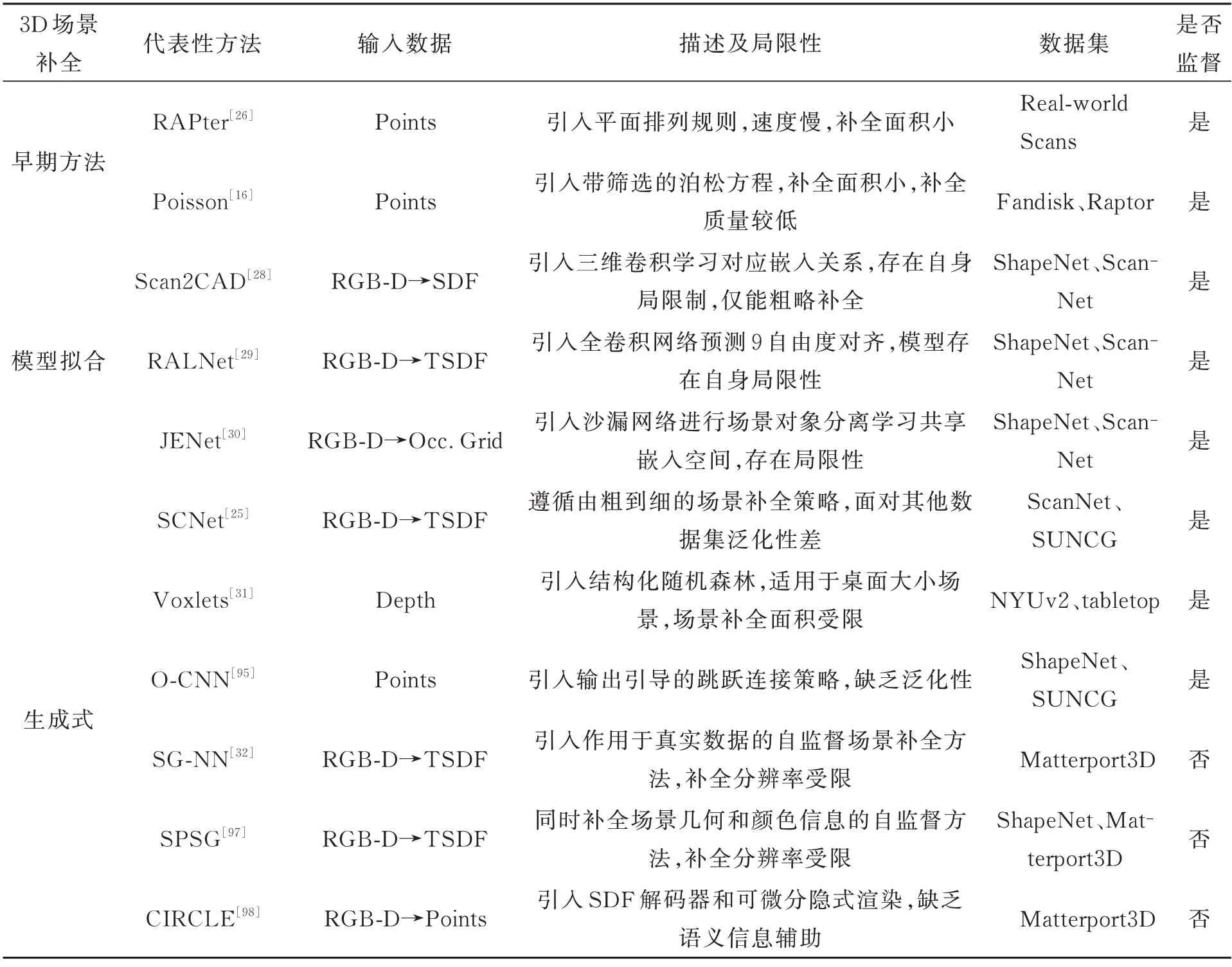
表4 三维场景补全主要方法对比Tab.4 Comparison of the main methods of 3D scene completion

表5 SUNCG 数据集上部分方法的定量结果Tab.5 Quantitative results of partial methods on the SUNCG dataset

图8 部分场景补全方法结果对比Fig.8 Comparison of the results of some scenario complementary methods
(1)对于三维场景补全任务,三维TSDF 矩阵是常用的场景表示形式。相较于模型拟合场景补全方法的自身局限性,基于生成式的场景补全方法表现出更好的优势。
(2)在场景补全任务中,由于合成数据集与真实数据集之间存在域差距,采用直接作用于真实数据集的无监督场景补全方法取得了令人振奋的结果。因此,基于无监督的场景补全方法仍然是接下来的重要研究方向。
(3)现有的场景补全方法大多在室内场景数据集上进行补全,在室外场景上的补全工作相对较少,希望在之后的研究中能有更多关于室外场景的补全工作。
(4)以上的场景补全方法没有考虑语义信息对场景补全的辅助,当补全的场景过于复杂时,补全的精度会下降,因此将语义信息和几何信息相结合的方式也是进一步研究的方向。这方面的工作在接下来的语义场景补全任务中将会介绍。此外,颜色信息也是场景补全任务中需要考虑的重要因素。
5 三维语义场景补全
三维场景的全面理解对许多应用领域而言都是至关重要的,如机器人感知、自动驾驶、数字孪生等。较早的场景理解工作大多是从语义分割或场景补全的角度分别展开研究。然而,文献[33]表明语义分割和场景补全并不是相互独立的,其语义信息和几何信息是相互交织耦合的,是相互促进的,并由此引出了语义场景补全(Semantic Scene Completion,SSC)的概念。语义场景补全是指从局部观测信息中推断出场景的完整几何信息与语义信息,实现与现实世界更好地交互。
目前,三维语义场景补全方法根据输入数据的不同类型,可以归纳为3 种主要类型:基于深度图的语义场 景补全方法[33,38-41,103-105]、基于深度图联合彩色图像的语义场景补全方法[106-113]和基于点云的语义场景补全方法[114-117],其发展历程如图9 所示。下面,本文将对研究发展进程中具有代表性的算法进行介绍和总结。
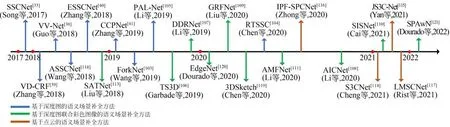
图9 三维语义场景补全方法发展历程Fig.9 Development history of 3D semantic scene complementation methods
5.1 基于深度图的语义场景补全方法
Song 等[33]开创性地提出语义场景补全网络SSCNet。该网络以单张深度图作为输入,使用扩展上下文卷积模块同时进行场景的体素网格占用和语义标签预测。该算法对深度图的体素编码采用翻转的截断符号距离函数(Flipped Truncated Signed Distance Function,f-TSDF)。普通的TSDF 容易在离物体表面较远的地方出现强梯度,基于投影的截断符号距离函数(Projective Truncated Signed Distance Function,p-TSDF)有严重的视角依赖性,而f-TSDF 在离物体较近的表面进行强梯度引导,如图10 所示。该算法在其提出的SUNCG 数据集[33]上取得了当时最好的结果。

图10 TSDF 变体Fig.10 TSDF variants
Guo 等[38]提出视图-体 素卷积网络VV-Net,该网络将2DCNN 与3DCNN 相结合。相较于SSCNet 直接使用3DCNN 对TSDF 编码的体素网格进行特征提取,VV-Net 先使用2DCNN 从深度图中提取几何特征并投影为三维体素网格,从而降低了一定的计算量。Zhang 等[39]将密集条件随机场(Conditional Random Field,CRF)引 入SSC 任务中,首先将深度图通过f-TSDF 编码为体素矩阵。其次,将SSCNet 输出的概率图与经过CRF 处理后的深度图相结合,组成VD-CRF模 型。该算法分别 在SUNCG、NYUv2 和NYUCAD 数据集上验证了其有效性,并分别取得了2.5%、3.7%和5.4%的提升。Zhang 等[40]提出通过高效的空间分组卷积(Spatial Group Convolution,SGC)来加速密集任务的计算。为了避免3DCNN 过大的计算量,目前常用的方法是通过稀疏卷积网络[118]或闵可夫斯基卷积网络[119]进行特征提取。然而,与这些方法不同,SGC 是沿着空间维度来创建组,同时使每个组中的体素网格更加稀疏,进一步降低网络的计算量。为了便于对比分析,文中将该方法简称为ESSCNet。Zhang 等[41]提出级联上下文金字塔网络CCPNet,该算法不仅改进了金字塔上下文中的标签一致性,还提出了基于引导的残差细化(Guided Residual Refinement,GRR)模块渐进式地恢复场景的精细化结构,在SUNCG 和NYUv2数据集上取得了有竞争力的结果,尤其在场景细节的生成方面更具优势。
Wang 等[103]提出多分支结构的语义补全网络ForkNet,该网络包括1 个共享的编码器分支和3 个独立的解码器分支,3 个分支分别预测不完整的表面几何形状、完整的几何体积和完整的语义体积。此外,该方法还引入多个判别器来提升语义场景补全任务的准确性和真实性。Chen等[104]提出一种融合特征聚合策略(Feature Aggregation Strategy,FAS)与条件预测模块(Conditioned Prediction Module,CPM)的实时语义场景补全算法RTSSC。首先,该方法通过具有扩张卷积的编码器来获得较大的感受野。其次,利用分阶段FAS 融合全局上下文特征。最后,采用逐步CPM 进行最终结果预测。该算法在单张1080Ti GPU 上实现了110 FPS 的速度。Li 等[105]提出具有位置重要性感知损失的语义场景补全网络PAL-Net。该算法通过考虑局部各向异性来确定场景内不同位置的重要性,有利于恢复对象的边界信息和场景角落信息。实验表明所提出的位置重要性感知损失在训练过程中收敛速度更快,可以取得更好的性能。
尽管以上基于深度图的语义场景补全算法取得了不错的结果,但RGB 图像包含的丰富颜色信息和纹理信息并没有被充分地利用。接下来,将介绍基于深度图联合彩色图像的语义场景补全方法。
5.2 基于深度图联合彩色图像的语义场景补全方法
RGB 图像具有丰富的颜色信息和纹理信息,可以作为深度图的重要补充,进一步提升三维语义场景补全的性能。
Garbade 等[106]提出基于双流卷积的语义场景补全网络 TS3D,该方法首先使用Resnet101[122]对RGB 图 像进行语义分割。其 次,将图像的语义分割结果映射到由深度图生成的3D 网格上,得到不完整语义体。最后,使用具有上下文感知的3DCNN 推断出完整的语义场景信息。实验表明,引入RGB 图像作为输入可以显著地提高SSC 任务,在NYUv2 数据集上相较于第2 名提升了9.4%。Li 等[107]提出一种轻量级的维度分解残差网络DDRNet。该方法通过引入维度分解残差(Dimensional Decomposition Residual,DDR)模块降低网络的参数。同时,使用多尺度融合策略提升网络对不同大小物体的适应能力。相较于SSCNet 算法,该方法仅使用了21%的参数量。Li 等[108]提出各向异性卷积的语义场景补全网络AICNet。相较于标准3DCNN的固定感受野,该算法使用提出的各向异性卷积(Anisotropic Convolution,AIC)模块将三维卷积分解为三个连续的一维卷积实现各向异性的三维感受野,每个一维卷积的核大小是自适应的。实验表明,叠加多个AIC 模块,可以进一步提升该算法在SSC 任务上的性能。
Liu 等[109]提出首个使用门控循环单元(Gated Recurrent Unit,GRU)的语义场景补全的网络GRFNet。该方法根据DDRNet 网络进行扩展,改进了多尺度融合策略,并构建具有自主选择和自适应记忆保存的多模态特征融合模块。此外,通过引入非显著性参数融合不同层级特征并进一步提出多阶段的融合策略。该算法在SSC 数据融合方面显示出优越的性能。Cai 等[110]提出场景到实例与实例到场景的迭代语义补全网络SISNet。具体而言,场景到实例指通过编码实例对象的上下文信息,将实例对象与场景解耦,以此得到更多细节信息的高分辨率对象。而实例到场景指将细粒度的实例对象重新集成到场景中,从而实现更精确的语义场景完成。该算法在合成数据集和真实数据集上均表现出良好的性能。
Li 等[111]提出基于注意力机制的多模态融合网络AMFNet。该算法使用2D 分割结果指导SSC 任务。值得一提的是,相较于以前直接从深度图中提取几何信息的方法,该方法先将深度图转换成3 通道的HHA 编码格式再进行特征提取。HHA 编码图像[112]的三个通道依次代表水平视差、高于地面的高度和像素的局部表面法线与重力方向的倾角,如图11 所示。该算法在SUNCG 和NYUv2 数据集上分别有2.5% 和2.6%的相对增益。Liu 等[113]提出一种解纠缠的语义场景补全网络SATNet。该方法首先使用编码-解码网络结构得到语义分割图像。其次,通过2D 到3D 重投影变换得到不完整场景的语义体素表示。最后,通过3DCNN 得到完整场景的语义体素表示。实验结果表明该算法在合成数据集和真实数据集上均表现出良好的性能。

图11 HHA 图像Fig.11 HHA map
尽管基于深度图联合彩色图像的语义场景补全方法具有较好的性能。然而,基于体素的三维表示仍然受到分辨率和内存的限制,当在室外场景下时,其内存缺陷尤其明显。接下来,将介绍基于点云的语义场景补全方法。
5.3 基于点云的语义场景补全方法
Cheng 等[114]提出基于点云输入的语义场景补全网络S3CNet。由于雷达点云具有的稀疏性导致直接提取其空间特征较为困难。因此,该算法首先将点云依次通过球形投影算法、扩展算法[123]、基于修改的f-TSDF 编码方法得到高效的稀疏三维张量。其次,将稀疏3D 张量投影的鸟瞰图进行语义分割。最后,将得到的2D 分割结果用于强化3D SSC。值得一提的是该方法对体素的融合是动态的,抵消了对3D 卷积的显著内存要求。
Yan 等[115]提出上下文形状先验的稀疏雷达点云语义分割框架JS3C-Net。该方法将雷达获取的多帧进行配准合并,其合并结果不仅可以作为场景补全任务的参考真值,还可以捕获那些显著对象形状的先验信息,而这些得到的形状先验信息有利于进一步的语义分割任务。此外,该算法还引入了点云-体素交互(Point-voxel Interaction,PVI)模块,用于语义分割和语义场景补全之间的隐式信息融合。该算法分别在SemanticKITTI 和SemanticPOSS 基准上提升了4%和3%。Zhong 等[116]提出一种融 合RGB 图像纹理信息与点云几何信息的场景补全网络IPF-SPCNet。该算法首先使用2D 分割网络得到语义分割图像。其次,将分割图像的语义信息重投影到对应的点云上,得到包含语义信息的不完整场景点云。最后,再通过基于点云的观测编码器和遮挡解码器得到完整的语义场景补全点云。实验结果表明该算法在场景补全和语义场景补全任务上均表现良好。Rist 等[117]提出基于局部深度隐式函数的语义场景补全网络LMSCNet。该方法与之前的场景补全方法不同,采用非体素化的连续场景表示,并引入自由空间信息作为监督信号,在室外场景数据集Semantic KITTI 上得了较好的实验结果。然而,该方法在不确定性估计方面仍然还有提升的空间。
尽管上述基于点云的语义场景补全方法在大规模室外场景数据集上表现出了良好的性能,但这方面的研究工作仍然较少。此外,现有的点云处理方法尚没有统一认可的特征提取范式,还没有一种点云特征提取算法能够像CNN 或Transformer 在图像领域获得那么高的认可度。尽管近几年基于点云的特征提取方法蓬勃发展,但是人们依然还是使用相对较早的点云特征提取算法,如:PointNet[61]和DGCNN[87]。
5.4 分析与小结
分析不同类型的语义场景补全方法,并根据表6、表7 和图12 所示的部分方法对比结果,得出下列结论:

图12 部分语义场景补全方法结果对比Fig.12 Comparison of the results of some semantic scene completion methods

表6 三维语义场景补全主要方法对比Tab.6 Comparison of the main methods of 3D semantic scene completion

表7 NYUv2 数据集上部分方法的定量结果Tab.7 Quantitative results of partial methods on the NYUv2 dataset
(1)现有的语义场景补全方法大多是通过3DCNN 对体素网格表示的三维空间进行特征提取。尽管其中有些算法使用了稀疏卷积、闵可夫斯基卷积或空间分组卷积来降低参数量,但当场景规模足够大时或者针对室外场景时,其内存和显存上的消耗仍然是致命的。
(2)最近,基于局部深度隐式的语义场景补全工作被提出,然而模型预测的不确定性问题还有待进一步的解决。
6 面临问题与研究趋势
尽管目前围绕三维形状补全、三维场景补全和三维语义场景补全的研究取得了一定的成果,但在现有的方法中,还存在一些亟待解决的问题,本节将对此进行深入分析,并从技术角度对三维补全未来的发展趋势进行展望。
6.1 三维补全面临的主要问题
(1)几何细节丢失问题:由于局部观测信息缺乏鲁棒的几何约束,现有的三维补全方法在对个体形状或大面积场景进行补全时,往往会丢失细节或无法预测正确的几何信息。尽管已有方法采用注意力机制[124]或Transformer 模型[82-83]实现细节生成,但其二阶计算量和内存复杂度极大地限制了它的可适用性。
(2)模型泛化性不足问题:现有的大部分三维补全方法存在泛化性差的问题,这主要可以归纳为两方面的因素,(a)依赖于缺失-完整匹配对的监督训练方式易导致模型过拟合和泛化性差。(b)不同合成数据集之间以及合成数据集与真实数据集之间存在域差距(Domain Gap)。
(3)计算资源受限问题:计算资源包括内存资源和显存资源,其受限的主要因素来源于场景表征的方式和场景数据的规模。由于大部分方法依赖于三维TSDF 矩阵或大规模点云来表征场景信息,虽然可以直接或间接使用3DCNN 进行特征提取,但是其计算量随分辨率呈立方增加。尽管有研究者通过和空间分组卷积[40]、稀疏卷积[125]和闵可夫斯基卷积[126]来缓解三维卷积参数量的问题,但当场景规模足够大时,其计算资源的缺陷仍然是致命的。此外,部分研究者使用图卷积神经网络对点云进行特征提取,但是这类方法需要耗费较长的模型训练时间和推理时间,对一些计算成本敏感和实时性较高的应用并不友好。
(4)实例区分模糊问题:针对三维形状补全或部分场景补全任务,本文关注到大部分方法都遵循编码器-解码器的范式,而这种范式易导致补全的不同实例存在区分性不足的问题。不同实例包括相同对象类别下的实例和不同对象类别下的实例。
(5)数据集类别不平衡问题:深度学习能够在大规模均衡数据集上取得显著成绩。但现有的三维补全数据集,特别是室外数据集,其类别分布存在严重的不平衡,如:Semantic KITTI 数据集[35]。这导致样本量少的类别包含的特征过少,模型学习效果大打折扣,难以完成高质量的补全任务。
6.2 未来的研究方向
针对上述三维补全研究存在的主要问题,并结合实际的应用场景和当下的研究热点,本文提出未来可能的研究方向:
(1)针对几何细节丢失问题,可以从以下两个层面展开研究:(a)常见的三维数据表示形式包括点云、体素和网格。点云表示具有存储空间小和表征能力强的特点,但它不能描述拓扑结构,亦不能产生水密的表面[65]。体素表示易受分辨率和计算存储空间的限制[69]。网格表示易受固定拓扑结构的限制[75]。相较于点云、体素和网格的离散表示形式,隐式函数能够支持以任意分辨率的形状恢复,处理不同的拓扑结构,并且输出结果是连续的。因此,基于隐式函数的三维补全是值得进一步探讨的研究方向。(b)通过引入几何先验信息、语义先验信息、颜色先验信息和场景图信息解开复杂场景中不同对象之间的纠缠和构建不同语义对象之间的关联,从而进一步提升几何信息预测的正确性,是值得进一步探讨的研究方向。
(2)针对模型泛化不足问题,可以从以下三个方面进行探索:(a)由于在真实世界中收集大量完整的3D 数据是耗时甚至是不现实的,因此,无需匹配对的无监督三维补全方法仍是接下来值得探讨的方向。(b)对于合成数据集与真实数据集之间存在的域差距,使用无监督域自适应方法缩小域差距是值得进一步探讨的方向。(c)现有的三维补全方法依赖于已经对齐的训练数据进行训练,其测试的数据也需满足与训练数据一致的对齐要求,否则训练好的模型在扩展到未对齐场景中时无法实现有效的补全。因此,实现三维补全算法在未对齐情况下的局部观测输入补全是值得进一步探讨的研究方向。
(3)针对计算资源受限问题,可以分别从以下两个角度深入挖掘:(a)使用隐式函数表征场景信息可以大幅降低内存的占用。但在场景补全任务中,模型预测的不确定性问题还有待进一步的解决。因此,结合概率统计学知识提升补全场景质量是很有价值的研究方向。(b)针对一些计算成本敏感的应用,通过模型压缩[127]或图浓缩技术[88]开发更轻便的实时应用模型是一个有趣和值得探讨研究方向。
(4)针对实例区分模糊问题,可以从以下两个方面进行探索:(a)从对比学习和实例持续学习的角度展开研究,实现不同实例的可区分性是值得进一步探讨的研究方向。(b)引入额外的语义信息来指导三维补全任务是值得进一步探讨的研究方向。例如,如果知道一个椅子缺失腿的数量是4 而不是3,那么模型在面对数据分布偏差时将提升预测结果的可靠性。
(5)针对数据集类别的不平衡问题,采用类别再平衡策略和主动学习策略缓解数据集类别的不平衡是值得进一步探讨的方向。
(6)现有的三维补全方法还停留在相对独立的领域展开研究,结合具体应用场景的工作相对较少。尽管已有相关工作将三维补全技术应用于目标检测这类高阶任务。然而,在高精度地形图构建、数字虚拟人重建、机械臂精确抓取等应用领域,三维补全作为一种辅助技术的潜力还未充分挖掘。因此,基于三维补全技术结合具体应用领域的研究是值得进一步探讨的方向。
7 结论
三维补全是计算机视觉研究的基础性课题,可以指导多种下游高阶视觉任务的学习,且具有重要的理论意义和广阔的应用前景,已成为计算机视觉领域的研究热点。本文分别从三维形状补全、三维场景补全和三维语义场景补全三方面对近年来的相关研究工作进行了梳理和小结,讨论了现有的三维补全方法所存在的问题,并从技术角度提出了未来的研究趋势。总而言之,深度学习为解决三维补全问题提供了新的技术,取得了较为显著的成果,但将其应用到真实场景中仍然存在很多问题。后续可以在计算资源、模型泛化性、补全质量等方面开展进一步的研究,这对于促进三维视觉领域的发展具有重要的意义。
