基于机器学习的中药材种类及产地鉴定模型分析
2023-04-07张晓丽
张晓丽
(运城师范高等专科学校 数学与计算机系,山西 运城 044000)
中药材来源广泛并且品种繁多,但由于其鉴别技术研究基础薄弱,技术尚未成熟,致使中药材产地与种类的鉴别一直困扰着中药产业的健康发展.郝丹丹等[1]通过采用定性与定量结合的数学分析方法,奠定了道地药材的客观标准评价体系基础;郑司浩等[2]认为应结合基因组学与分子生物学技术研究中药材品种和产地的鉴别;刘杰等[3]则认为应使用DNA遗传标记并结合组织形态三维定量分析以及中药化学指纹图谱和生物效价检测新技术,综合分析中药材的道地性.随后,陈晓丽等[4]指出应以临床疗效为基准,针对道地药材的形成及过程影响因素的动态变化,建立道地药材溯源系统并进行标准化种植.
从上述研究来看,中药材种类及产地的研究一直备受关注,且随着中药材产业的不断发展,近年来一些新的技术和方法被广泛综合应用于中药材的种类及产地鉴别研究,虽然方法很多,但各有利弊,并没有哪一种是最佳的.由于不同种类的中药材会因其无机元素的化学成分和有机物等因素的差异性,导致药材在光谱照射下表现出不同的光谱特征,通过对光谱进行区别比较,便可完成中药材的种类鉴别.所以,近红外和中红外光谱技术对中药质量、种类及产地的分析有广阔的应用前景[5-6].因此,本文试图从大数据分析的角度,利用K-Means聚类、人工神经网络(简称ANN)和K近邻算法(简称KNN)分别完成对不同类别、不同数据量和不同光谱特征的中药材产地及种类的鉴别.
1 数据分类及处理
本文数据源于2021年全国数学建模大赛E题中的部分数据.由于中药材种类及产地鉴别的类别标签较多,为使数据分析结果更加精准全面,这里将样本数据分成三类.其中一类、二类和三类数据对应下文中模型1、模型2和模型3的构建分析.具体分类如下.
一类数据(药材种类):给出425种中药材的中红外光谱数据,需通过药材编号、光谱波数以及吸光度来鉴别不同中药材的种类.通过描述统计分析,发现样本数据中存在3个异常值(均为数值偏大),编号分别是64号(所有数值在0.8以上),136号(所有数值在0.7以上)和201号(所有数值在0.5以上),因异常值对模型效果会产生很大影响.因此,建模前需进行异常值处理,考虑样本数据充足,这里选择直接剔除;同时,因数据间相似度较高,在此还需对数据进行主成分降维,即将多个变量通过线性变换只选出较少的重要变量来替代原始变量.
二类数据(药材产地):给出一组不同产地同一种中药材的673个中红外光谱数据,数据量比较充足,但给定的数据中有一些中药材的产地信息缺失,需对数据中药材产地信息完整的药材进行分类后,再来预测数据中缺失药材的产地信息.因此,在预测前需从给定的样本数据中先筛选出产地信息完整的658个数据作为训练集;而后将产地信息缺失的15个不同编号的样本数据作为预测集.为使分类结果更加精准,在此还需对数据进行主成分降维处理.
三类数据(药材产地):给出两组不同产地同一种中药材的255个中红外和近红外光谱数据,数据量较少,但数据类别标签较多,且给定的两组数据中都存在10个不同编号的药材产地信息缺失.因此,在分析之前,需在主成分降维基础上,将样本数据中缺失的这10个不同编号的样本数据筛选出来作为预测数据,其余数据作为训练数据.
注意:虽然二类和三类数据均为药材产地数据,但二类数据只有一组中红外光谱数据;三类数据有中红外和近红外两组光谱数据,且两类数据量均不相同.
2 模型算法分析
结合上述一类、二类和三类数据特点,这里采用不同的机器算法对其进行分析,具体如下.
模型1常用的聚类算法包括系统聚类和K-Means聚类.通过对比发现,系统聚类主要采用合并法或分解法,通过Ward法计算类间距,将距离最近的两类合并为一个新类,层层合并,直到类别个数为1,结束聚类.该方法只适用于数据量较小的情况,当数据量较大时,系统聚类速度较慢.而K-Means聚类主要采用层层迭代和不断修正聚类中心的方法,随机选择初始聚类中心,通过计算每个样本点到各个聚类中心的距离,再将其分配到距离最近的类别中,使聚类结果合理稳定为止.该方法适合数据量较大的模型构建,速度快且准确率高.结合第一类数据特点,其数据海量,规模之大,无缺失信息,如果采用系统聚类,会因计算量大而导致系统运行特别缓慢,甚至很难给出最终结果.因此,选择用K-Means聚类算法对本题进行建模求解.
模型2第二类数据总量较大,光谱特征明显,但数据相似度高,且有少量数据产地信息缺失.人工神经网络作为监督式学习中的一种,在模拟处理复杂问题方面具有得天独厚的优势.由于中药材产地类别多,数据量大且类别间相似度较高,这直接增加了中药材鉴定的难度.而人工神经网络拥有大量神经元节点,通过对内部连接节点间的调整建立信息反馈机制,形成模式识别.因此,人工神经网络可通过模式识别对事物特征或现象的各种信息进行处理和分析,以便对事物和现象进行识别、预测和分类.目前,人工神经网络在临床药学、中药鉴定学和中药分类等医学领域应用广泛并取得了一些成果[7-8].因此,这里采用人工神经网络(ANN)对其进行分类预测.
模型3第三类数据由两组不同类型的产地数据组成,数据总量较少,数据类别标签较多,且少量数据产地信息缺失.此时,若单纯使用其中某一组数据进行分类预测,其结果都不会太准确.经分析,KNN算法更适用于稀有事件的分类预测问题,它主要是靠周围有限的邻近样本,而不是靠判别类域的方法来确定所属类别.因此,对于类域的交叉或重叠较多的待分类样本数据来说,KNN算法较其他方法更为合适[9],且模型预测准确率较高.
3 模型建立与结果分析
3.1 药材种类鉴定模型1
(i)由于一类数据量大,且数据间相似度较高,在做K-means聚类之前需先进行主成分降维,选出具有代表性的新生变量替代原始变量进入下一步的分析.

表1 主成分降维后新生变量累积贡献率
由表1可知,第1个新生变量的累计贡献率达79.25%,加入第2个新生变量后的累计贡献率达96.74%,其余新生变量对模型贡献率不高.因此,这里只节选前两个变量进行下一步的聚类分析.
(ii)对选取的前两个新生变量进行K-Means 聚类分析.
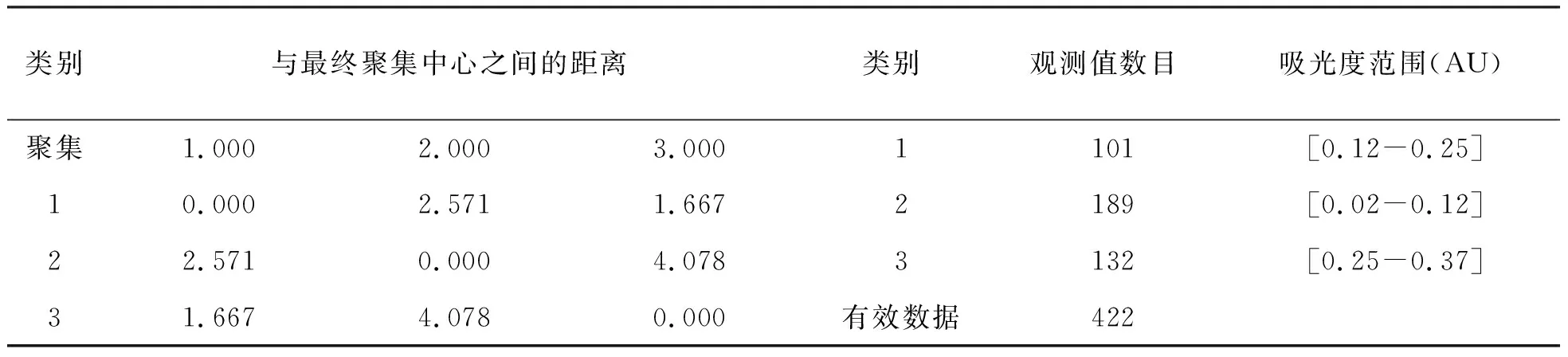
表2 K-Means聚类分析结果
从表2来看,模型中药材种类被分成3类,第一类有101个样本,第二类有189个样本,第三类有132个样本.药材种类不同其特征也不相同,第一类药材的所有变量指标范围在[0.12-0.25AU],对应波段光谱照射下的吸光度在全部药材中属于比较居中的一类;第二类药材的所有变量指标范围在[0.02-0.12AU],对应波段光谱照射下的吸光度是全部药材指标中最小的一类;第三类药材的所有变量指标范围在[0.25-0.37AU],对应波段光谱照射下的吸光度是全部药材指标中最大的一类.说明第三类药材的质量最好,其次是第一类药材,质量最不好的是第二类.最终利用K-Means聚类完成药材种类鉴定.
3.2 药材产地鉴定模型2
(i)模型2只给出一组中红外光谱数据且数据间相似度较高,为提高模型预测准确率,在分析之前需对样本数据进行主成分降维处理,选出新生变量替代原始变量进入下一步的分析.

表3 主成分降维后新生变量累积贡献率
由表3可知,第一个新生变量的累计贡献率达86.13%,加入第二个新生变量后的累计贡献率达92.61%,加入第三个新生变量后的累计贡献率达95.32%,其余新生变量对模型的累计贡献率不是很高,因此,节选前三个新生变量替代原始变量进行下一步的分类预测.
(ii)从降维后的新生变量中选取产地信息完善的658个数据进行人工神经网络分析.

表4 人工神经网络建模结果
由表4可知,药材产地被分为11类,模型预测准确率Accuracy为0.933712接近于1,说明建模效果较好.同时,各类别中模型精确率Precision和召回率Recall这两个指标的数值均在0.9左右浮动,接近于1,这从不同角度描述了模型识别的精准度和广度;综合评分F1-score反映了精确率和召回率的综合情况,且综合评分越大说明模型分类效果越好.总之,不论是模型预测准确率还是各类别精确率、召回率和综合评分都说明了模型分类预测效果较好,可以直接将需要预测的药材编号数据导入模型中,直接给出产地预测结果即可.
(iii)为研究不同产地药材的特征及差异性.结合上述分类结果,从中选出具有代表性且区分度比较明显,来自11类不同产地的同一种药材的中红外光谱数据进行对比分析.
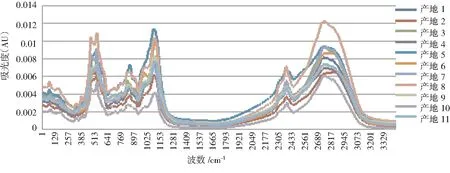
图1 某种药材11类不同产地的中红外光谱图
从图1可以看出,11类不同产地的中药材差异性整体比较明显,由3个波段构成,第一个波段在[373~621(cm-1)],第二个波段在[993~1223(cm-1)],第三个波段在[2357~3101(cm-1)].整体来看,产地5和产地8在对应波段下的吸光度都是最高的属于一等产地;产地10和产地11在对应波段下的吸光度是所有产地中最低的一类,属于三等产地;剩余产地比较容易区分,属于二等产地.说明模型分类效果良好,不同产地同一种药材区分明显.
3.3 药材产地鉴定模型3
(1)模型3给出了中红外和近红外两组光谱数据,在建模前我们先对这两组数据的特征及差异性进行图示对比分析.

图2 某种中药材17类不同产地中红外光谱图

图3 某种中药材17类不同产地近红外光谱图
从图2和图3可知,中红外和近红外两组光谱下不同产地同一种药材的吸光度是不同的.近红外光谱吸光度趋势基本趋同,重复叠加现象明显,数据间区分度较低,不适用于药材产地类别鉴定;而中红外光谱吸光度离散程度大,光谱距离远,数据区分度较高,不同产地同一药材差异性显著.因此,直接选用中红外光谱数据来完成接下来的建模分析.
(ii)因模型3数据量少,类别标签多.因此建模前需进行主成分降维,选出新生变量.

表5 主成分降维后新生变量累积贡献率
由表5可知,第一个新生变量的累计贡献率达82.53%,加入第二个新生变量后的累计贡献率达88.56%,加入第三个新生变量后的累计贡献率达93.87%,其余新生变量对模型的累计贡献率不是很高,因此,只节选前三个新生变量进行下一步的KNN分类.
(iii)从降维后的新生变量中选取产地信息完善的245个数据进行KNN分类.

表6 中红外光谱数据KNN分类结果
由表6可知,中药材产地被分为17类,类别间分类个数相差不大,说明来源于不同产地的同一药材的样本数据量均衡,结合上图2分析结果,说明不同产地的同一种中药材之间的差异性相对比较显著,模型分类效果很好,类别清晰,可直接将需要预测的药材编号数据导入模型中,直接给出产地预测结果.
4 结束语
虽然中药材的近红外和中红外不同光谱特征可以用于鉴别中药材种类及产地,但站在数据分析的角度,如果近红外和中红外光谱数据类别和数据量不同,则选取的模型分析算法也不同.因此,对药材种类鉴定时,如果样本数据量充足、无缺失值且类别标签较少,可直接利用K-means聚类来完成药材种类鉴定.对药材产地鉴定时,如果样本数据只有一组中红外或近红外光谱数据,样本数据量充足,但数据间相似度较高,数据信息存在缺失,可将其视为一个监督式的模型分类预测问题,在主成分降维的基础上通过人工神经网络分析,判别模型预测的准确率,实现药材产地鉴定;如果样本数据有中红外和近红外两组光谱数据,数据类别标签较多但数据量较少,数据信息存在缺失时,应先对药材的中红外和近红外两组光谱数据特征及差异性进行图示对比分析,再通过主成分降维进行KNN数据分析,结合图示分析和数据分析结果完成药材产地鉴定.
