基于深度强化学习的智能空战决策与仿真
2023-03-28周攀黄江涛章胜刘刚舒博文唐骥罡
周攀,黄江涛,*,章胜,刘刚,舒博文,3,唐骥罡
1.中国空气动力研究与发展中心 空天技术研究所,绵阳 621000
2.中国空气动力研究与发展中心,绵阳 621000
3.西北工业大学 航空学院,西安 710072
近年来,随着无人机技术的不断发展,无人作战飞行器(Unmanned Combating Air Vehicle, UCAV)在战场上发挥着越来越重要的作用。与传统有人机相比,UCAV 具有成本低、安全风险系数小、可承受过载大等优点,可以预见UCAV 将成为未来空战的主角之一。然而,想要充分发挥UCAV 的性能,实现高强度空战对抗,UCAV 必须脱离地面控制,具备高度自主决策能力。与此同时,深度神经网络与机器学习的结合则掀起了人工智能新的研究热潮。2016 年,AlphaGo[1]击败了人类围棋冠军,引起了全世界的关注,AlphaGo 的胜利一方面将强化学习推上了历史舞台,另一方面还验证了强化学习在博弈问题中的应用潜力。 在DARPA(Defense Advanced Research Projects Agency)于2020 年8 月份举办的“AlphaDogfight trials”人机对抗赛中,美国苍鹭公司设计的智能飞行自主决策系统驾驶F-16 战机以5∶0 的比分完胜了F-16 的飞行教官[2],吸引了全世界军事强国的目光,飞行器智能空战决策已成为当今各军事强国的研究热点。
国内外针对智能空战展开了大量研究。现有的空战自主决策方法大致可以分为基于博弈理论的方法、基于优化理论的方法和基于人工智能的方法[3]。Park 等将微分博弈方法用作可视范围内空对空作战UCAV 的自动机动生成算法[4]。Weintraub 等使用微分博弈方法解决空战中格斗双方的追逃博弈问题[5]。McGrew 将动态规划方法用于一对一空战机动决策[6]。Kaneshige 等使用进化算法和遗传算法进行战斗机的机动决策[7]。薛羽等提出了一种用于空战决策的启发式自适应离散差分进化(H-SDDE)算法[8]。基于人工智能的空战自主决策方法包括基于规则的专家系统和机器学习。Burgin 基于专家系统实现了无人机在空战对抗中的自主决策功能[9]。但由于空战状态空间的连续性和复杂性,基于博弈理论的方法和基于优化理论的方法均存在求解困难的问题,难以满足实时性需求[3]。
目前,智能飞行发展的主要方向是将深度强化学习方法与UCAV 结合起来。左家亮等采用启发式强化学习方法解决动态变化的空战机动决策问题[10];张耀中等基于深度确定性策略梯 度(Deep Deterministic Policy Gradient, DDPG)算法建立了人工神经网络模型,该模型能够控制无人机群执行对敌方来袭目标的追击任务[11];杜海文等提出了一种将优化思想与机器学习相结合的机动决策模型,该模型以多目标优化方法为核心,在多目标优化的基础上通过强化学习方法训练评价网络进行辅助决策[12];施伟等提出了一种基于深度强化学习方法的多机协同空战决策流程框架(Deep-Reinforcement-Learning-based Multi-Aircraft Cooperative Air Combat Decision Framework, DRL-MACACDF),并针对近端策略优化(Proximal Policy Optimization, PPO) 算法, 设计4 种算法增强机制[13];张强等提出了一种基于Q-network 强化学习的超视距空战机动决策方法[14];李银通等提出了一种基于逆强化学习的空战态势评估方法[15]。然而,从公开发表的文献来看,现阶段基于人工智能方法开展的近距空战自主格斗算法研究主要针对简单动作和典型动作进行验证,复杂对抗问题尤其是人机对抗问题系统性研究鲜为少见。
针对近距空战格斗问题,开展基于深度强化学习(Deep Reinforcement Learning, DRL)方法的近距空战自主决策训练系统研究。首先建立基于双延迟确定性策略梯度算法(Twin Delayed Deep Deterministic policy gradient, TD3)的 强化学习算法框架。在此基础上,针对空战强化学习中的稀疏奖励问题,采用一种针对近距空战格斗问题的奖励函数;针对智能体容易被对手诱导坠地问题,提出有效纠正改进措施;针对深度强化学习中随机取样带来的算法收敛速度慢问题,发展基于价值的样本优先度排序方法,提升算法的收敛速度。综合以上环节,进行马尔科夫决策过程建模,开展博弈训练,进一步对训练得到的智能体进行数字仿真验证和人机虚拟对抗仿真验证。
1 近距空战问题建模
1.1 动力学方程
建立如图1 所示的地面坐标系Oxyz,取地面某点作为坐标原点O,Ox轴指向正东方向,Oy轴指向正北方向,Oz轴沿竖直方向,向上为正。在图1 所示的惯性坐标系下,UCAV 动力学方程为

图1 飞行器运动模型Fig. 1 Aircraft motion model
式 中:v为速度;T为发 动机推 力;α为迎角;D为阻力;m为飞行器质量;g为当地重力加速度;γ为航迹倾角;L为升力;μ为速度滚转角;ψ为 航向角。
飞机的气动力模型采用某型飞机真实气动力模型,升力系数和阻力系数的计算公式为
式中:k1~k8为参数。
飞行器所受气动力和推力的计算公式如下:
式中:L、D、T分别是飞机所受的升力、阻力和推力;ρ是空气密度;S是飞机参考面积;Tmax是飞机发动机最大推力;δ∈[0,1]是油门大小。
采用迎角α、滚转角μ和油门δ作为控制量对无人机的运动行为进行控制。其中迎角的取值范围是[ -10°,30°],滚转角的取值范围是[ -80°,80°],油门的取值分为是[0.2,1]Tmax。
1.2 运动学方程
飞机的运动学方程为
式中:x、y、z分别为3 个方向的坐标。
1.3 近距空战场景
本文构建的一对一近距空战场景中,博弈双方驾驶性能完全相同的两架飞机,红机(智能体)的初始位置坐标为RR(0,0,6) km,速度指向正东,蓝机(敌方)在一个以红机为中心的矩形位置区域内随机出现,速度指向随机。双方速度是一个随机量v∈[100,180] m/s。在一对一近距空战博弈中,敌我双方在机载雷达等传感器设备的支援下,获得对方的运动状态信息、综合战场态势,通过机动到达各自的有利态势,达到目标锁定与武器发射条件,从而实现有效消灭对方、同时保存自身的作战目的。近距空战对抗中的态势优势包括攻击角度优势、速度优势、高度优势和距离优势等。
2 深度强化学习
深度强化学习(Deep Reinforcement Learning, DRL)是强化学习[16](Reinforcement Learning, RL)与深度学习[17](Deep Learning, DL)的有机结合,突破了传统表格型(Tabular)强化学习方法只能使用低维输入的限制,而且比其他函数拟合方法具有更好的特征提取能力,被视为人工智能领域最有潜力的发展方向。
2.1 强化学习基本理论
强化学习可以抽象为一个马尔可夫决策过程(Markov Decision Process, MDP),智能体在t时刻观察到自身状态St,根据策略π选取动作at。环境反馈给智能体下一时刻的奖励rt+1,智能体进入新的状态St+1。
根据学习目标的不同,强化学习算法可以分为基于价值(Value-based)的强化学习算法和基于策略(Policy-based)的强化学习算法两类。基于价值的强化学习算法的目标是学习一个最优动作状态价值函数Q*(s,a),其典型算法包括Q-learning[18]、SARSA[19]等。基于策略的强化学习算法的目标是学习一个最优策略π*,其典型算法包括TRPO[20]、PPO[21]等。在这两种方法的基础上,Konda 和Tsitsiklis 提出了一种Actor-Critic 算法[22],Actor-Critic 算法将基于价值(对应Critic) 的方法与基于策略(对应Actor) 的方法进行结合,同时学习策略函数和价值函数。与基于策略和基于价值的强化学习算法相比,Actor-Critic 算法具有样本利用率高、价值函数估计方差小和训练速度快等优点。
2.2 TD3 算法
深度强化学习以强化学习为核心,在此基础上借助人工神经网络强大的拟合能力去拟合策略函数π和状态动作价值函数Q(s,a)。深度确定性策略梯度算法(Deep Deterministic Policy Gradient, DDPG)[23]将Actor-Critic 算法和深度Q网络算法(Deep Q-Network, DQN)[24]相 结合,是一种典型的深度强化学习算法。DDPG 算法在Actor-Critic 算法框架上加入了目标网络,网络训练更加稳定。然而,DDPG 算法中存在高估计、高方差等问题。
针对DDPG 算法中存在的问题,TD3 算法[25]在DDPG 算法的基础上做出了以下改进。为了解决DDPG 算法中Critic 网络的高估计问题,TD3 算法引入了第2 个Critic 网络,因此TD3 算法采用两个Critic 网络(Critic1 网络和Critic2 网络)拟合智能体的动作状态价值函数Q(S,A)。每次对动作状态价值函数进行评估时,两个Critic 网络同时进行评估,最终选取最小的评估值作为智能体的动作状态价值。TD3 算法中动作状态价值的更新方式如下:
式 中:Qθ'1(s',πϕ(s'))和Qθ'2(s',πϕ(s'))分 别 是2 个Critic 网络的估计值。
DDPG 算法中存在的高方差问题会造成学习速率降低、学习表现力降低和学习过程不稳定等不利影响。TD3 算法通过引入正则化方法解决了高方差问题,即在智能体的动作中引入随机噪声,加入随机噪声后的智能体动为
式中:πϕ'(s')是Actor 网络输出的动作;ϵ是一个随机噪声。
TD3 算法采用梯度下降的方式进行更新,其中策略网络的梯度公式如下所示:
式中:Qθ1(s,a)是动作状态价值;πϕ(s)是智能体的策略;∇是求梯度符号。
然而,在传统强化学习算法中,每次更新会从经验池中进行随机抽样,利用抽取的样本对神经网络进行更新,样本的选择直接决定了算法的收敛速度和收敛结果。本文在将样本存入样本池前加入一道筛选步骤,每一幕结束之后,计算所有样本状态的动作价值q(s,a),当2 个样本状态较为接近时,即|S1-S2|<ε时,将S1和S2中动作价值较高的存入样本池,舍弃动作状态价值较低的样本,从而提高算法收敛速度,其中ε是一个常数。
3 近距空战智能决策机设计
3.1 决策机神经网络结构
Actor 网络的主要功能是接收战场态势信息,利用神经网络对这些信息进行处理,最终输出智能体的动作。本文智能体可以获取的战场态势信息包括双方位置信息和速度信息, Actor网络的输入参数包括对抗双方的相对位置RRB、对抗双方的相对速度VRB、对抗双方的速度夹角φV、红机的攻击角φattR和蓝机的逃逸角φescB,其中。Actor 网络的输出参数是红机的动作信息,包括迎角α、滚转角μ和油门δ,见图2。

图2 空战态势描述Fig. 2 Air combat description
Critic 网络通过对状态行为价值进行评估,指导Actor 网络进行训练。Critic 网络接收战场态势信息和智能体动作,输出动作状态价值。战场态势信息包括对抗双方的相对位置RRB、对抗双方的相对速度VRB、对抗双方的速度夹角φV、红机的攻击角φattR和蓝机的逃逸角φescB。智能体动作参数为迎角α、滚转角μ和油门δ。Critic 网络的输出参数为智能体的状态价值Q(s,a)。
本文人工神经网络均采用全连接前馈神经网络,网络结构如图3 所示。Actor 网络由1 个输入层、9 个隐藏层和1 个输出层组成,其中输入层包含10 个神经元,每个隐藏层包含256 个神经元,输出层包含3 个神经元。Critic 网络由1 个输入层、9 个隐藏层和1个输出层组成,其中输入层包含13个神经元,每个隐藏层包含256 个神经元,输出层包含1 个神经元。激活函数采用ReLU 函数,ReLU 函数具有计算高效、缓解神经网络的梯度消失问题和加快梯度下降的收敛速度等优点。
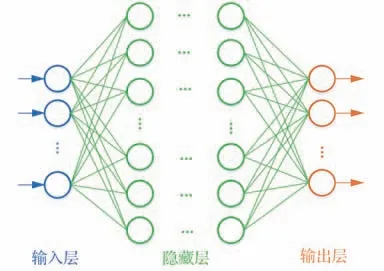
图3 全连接前馈神经网络模型Fig. 3 Fully connected feedforward neural network model
前馈神经网络采用误差反向传播算法和梯度下降方法更新参数,其中损失函数采用Huber-Loss 函数,相较于均方误差(Mean Square Error, MSE)和平均绝对误差(Mean Absolute Error, MAE)等损失函数,HuberLoss 函数具有在误差较大时对离群点不敏感、误差较小时收敛速度快等优点。HuberLoss 函数如式(8)所示,其图像如图4 所示。
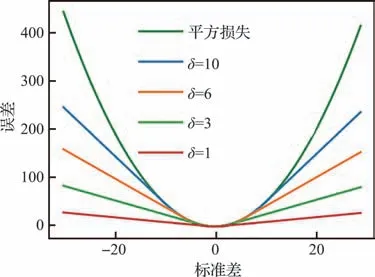
图4 HuberLoss 函数Fig. 4 HuberLoss function
式中:f(x)是网络的估计值;y是真实值;δ'是一个常参数。
3.2 奖励函数设计
在近距空战格斗态势评估中,需要综合考虑攻击角度优势奖励函数、速度优势奖励函数、高度优势奖励函数和距离优势奖励函数。
3.2.1 攻击角度优势奖励函数
建立如图2 所示的右手坐标系Oxyz,取地面某点作为坐标原点O,Ox轴指向正东方向,Oy轴指向正北方向,Oz轴沿竖直方向,向上为正。图中红机的位置坐标为RR(xR,yR,zR),速度矢量为VR(vRx,vRy,vRz);蓝机的位置坐标和速度矢量分别是RB(xB,yB,zB) 和VB(vBx,vBy,vBz)。目 标 线RRB=RB-RR指从红机到蓝机的连线。
智能体的攻击角度优势奖励函数如式(9)所示[26]:
式中:
3.2.2 速度优势奖励函数
智能体的速度优势奖励函数如下所示[15]:
当vopt>1.5vB时
当vopt≤1.5vB时
式中:vR=|VR|和vB=|VB|分别是红蓝机双方的速度大小;vopt是最佳空战速度,本文取vopt=200 m/s。
3.2.3 高度优势奖励函数
高度优势奖励函数如下所示[15]:
式中:HR和HB分别是红机和蓝机的高度;Hopt是最佳空战高度,本文取Hopt=6 km。
如图5 所示,在仿真过程中,当对抗双方高度较低时,智能体有一定的概率在敌机的诱导下坠地。为了使智能体具备在高度过低时自主纠正高度的能力,在高度优势奖励函数中引入一个校正量,校正后的高度优势奖励函数如式(15)所示:

图5 智能体坠地Fig. 5 Agent falls
式中:vRz是红机速度在竖直方向上的分量;H0是一个常数参量,用来调整高度奖励函数的梯度。
引入的校正量动态权重的图像如图6 所示。由图6 可以看出,当飞机高度较大时,校正量权重较小。当飞机高度较小时,校正量的权重较大,此时奖励函数对高度变化比较敏感,飞机会增加高度从而获得更大的奖励,从而避免对手的高度诱导。
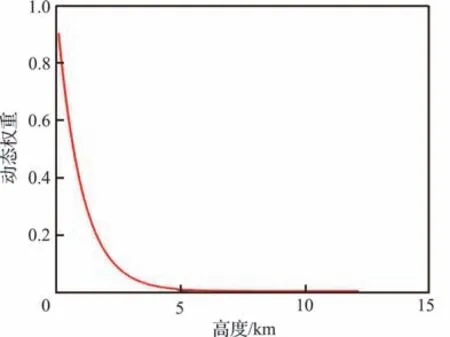
图6 高度奖励函数校正量Fig. 6 High return function correction amount
校正后的飞行效果如图7 所示,从图中可以看出,当敌机高度过低时,智能体在对抗过程中会保持一定飞行高度,避免了在敌机诱导下坠地的问题。
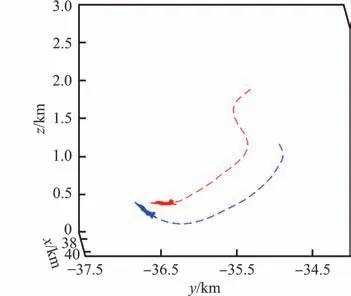
图7 智能体近地攻击Fig. 7 Agent proximity attack
3.2.4 距离优势奖励函数
距离优势奖励函数如下所示:
式中:d=|RRB|是双方飞机之间的距离;Dopt是最佳空战距离;D0是一个常数参量,用来调整距离优势奖励函数的梯度。本文取Dopt=0.2 km,D0=2 km。
3.2.5 空战态势奖励函数
最终奖励函数如下所示:
式中:Rφ、RV、RH和RD分别是攻击角度奖励、速度奖励、高度奖励和距离奖励;ωφ、ωV、ωH和ωD分别是攻击角度奖励、速度奖励、高度奖励和距离奖励的权重。
3.3 智能决策机训练
训练过程中使用智能体与专家系统进行对抗获得训练样本,将得到的样本放入经验池中,根据优先度在样本池中进行抽样,使用抽样得到的样本对智能体进行训练。分别通过智能体的平均奖励和Critic 网络的残差对训练效果进行监测。
对加入样本筛选前后的算法性能进行对比,结果如图8 所示。由图中可以明显看出,在加入样本筛选之后,算法收敛速度明显加快,最终性能有明显提升。
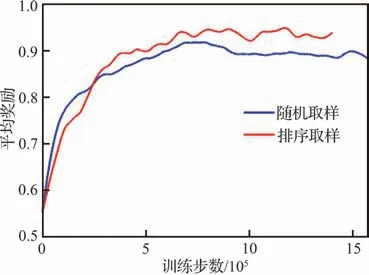
图8 不同取样方法的平均奖励Fig. 8 Average reward of different sampling methods
智能体的平均奖励和Critic 网络的残差分别如图9 和图10 所示。图9 是训练过程中智能体的平均奖励,横坐标是训练步数,纵坐标是平均奖励。图中蓝线是平均奖励统计的真实值,红线为对统计数据平滑处理后得到的结果。图10 是训练过程Critic 网络的残差,横坐标是训练步数,纵坐标是网络残差,图中蓝线是网络残差统计的真实值,红线为对统计数据平滑处理后得到的结果。

图9 智能体的平均奖励Fig. 9 Average reward of agent
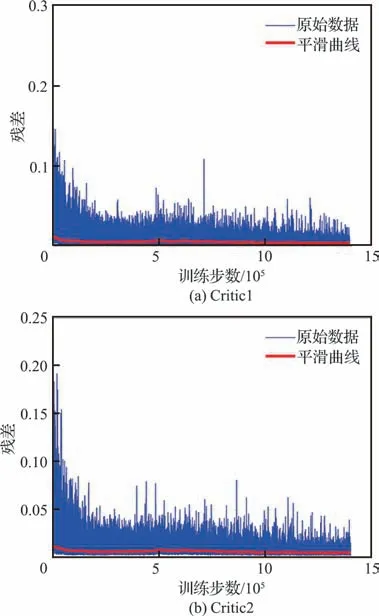
图10 Critic 网络残差Fig. 10 Critic network residual
由图9 可以看出,在算法的训练过程中,智能体的平均收益以比较平稳的速度缓慢上升,说明智能体的决策能力在不断提高。当训练次数达到77 500 次时,智能体的平均奖励达到峰值,随后趋于稳定。
4 近距空战对抗仿真
为了充分检验智能体的性能,分别设计3 个场景进行仿真试验:①简单动作对抗;②红机与基于专家系统的蓝机进行近距空战博弈;③红机与人类飞行员控制的蓝机在人机对抗仿真平台上进行近距空战博弈。
4.1 简单动作对抗
在简单动作对抗仿真中,红机(智能体)采用智能空战自主决策算法进行控制,蓝机分别做匀速直线运动和水平盘旋运动,速度大小为200 m/s。红机的初始位置坐标为RR(0,0,6) km,蓝机在一个以红机为中心的矩形区域内随机出现,该矩形区域的长宽高分别为12、12、4 km。
图11(a)给出了蓝机做直线运动时对抗双方获得的态势奖励,图11(b)为空战博弈某时刻段战场态势信息,图11(c)为完整仿真轨迹。通过仿真数据可知,初始时刻敌机占据高度优势,智能体根据敌方位置调整视线角;但由于智能体高度较低,智能体向右转弯的同时拉起机头提升高度,从第20 s 开始对敌方形成攻击条件并保持。
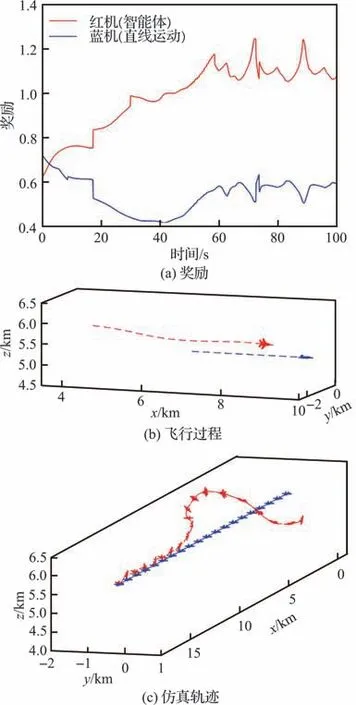
图11 直线运动Fig. 11 Linear motion
图12(a)给出了蓝机做水平盘旋运动时对抗双方获得的态势奖励,图12(b)和图12(c)分别给出了空战博弈不同阶段战场态势信息。通过仿真数据可知,初始时刻敌机占据高度优势并具有攻击条件,智能体拉起机头,在提升高度的同时降低速度,形成有效攻击条件并保持攻击优势。
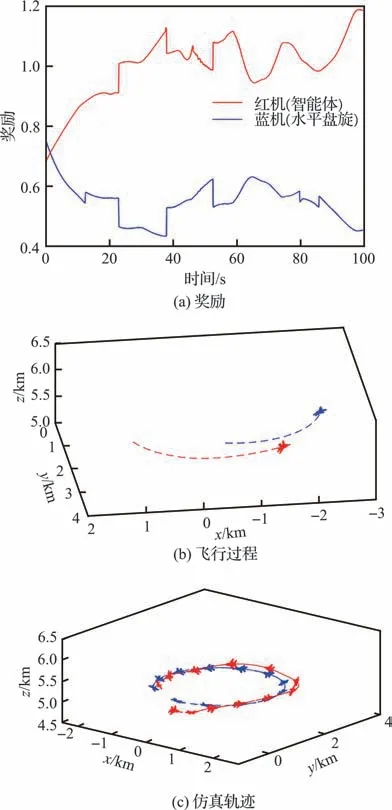
图12 水平盘旋运动Fig. 12 Horizontal circling movement
4.2 与专家系统对抗博弈
在智能体与专家系统的空战对抗仿真中,红机(智能体)采用智能空战自主决策算法进行控制,蓝机由专家系统[27]进行控制,双方进行近距空战博弈,红机的初始位置坐标为RR(0,0,6) km,蓝机在一个以红机为中心的矩形区域内随机出现,该矩形区域的长宽高分别为12、12、4 km。仿真时长为200 s。图13 给出了智能体与专家系统进行空战格斗的胜率随训练次数的变化趋势。图14~图18 分别给出了最终的智能体分别在初始优势和劣势条件下与专家系统进行空战对抗的仿真结果。

图13 智能体胜率随训练次数变化趋势Fig. 13 Changing trend of agent’s winning rate with number of training
图14给出了空战对抗双方获得的态势奖励,图15 给出了空战博弈过程中智能体的部分操作指令信息,图16(a)~图16(e)分别给出了空战博弈不同阶段战场态势信息。通过仿真数据可知,初始智能体处于不利态势,智能体选择向右机动的同时俯冲加速;俯冲的过程中速度增大,双方距离减小,15 s 左右时取得对敌机的有效攻击条件并保持;敌机分别采取俯冲加速和筋斗机动,均未能摆脱劣势。
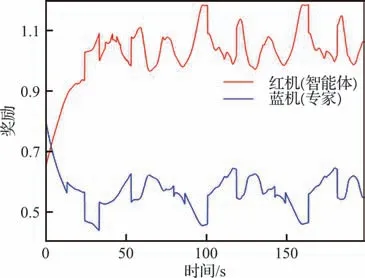
图14 博弈双方的奖励(初始劣势)Fig. 14 Rewards for both sides of game(Initial disadvantage)
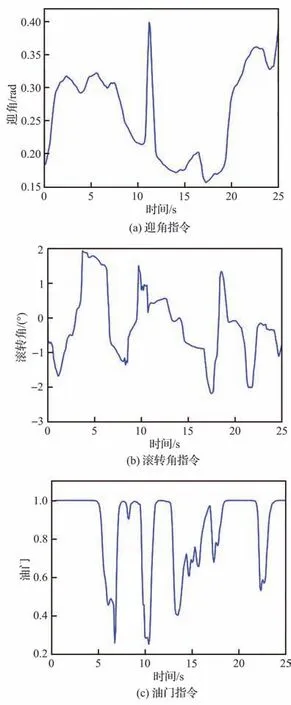
图15 智能体操作指令Fig. 15 Operational order of agent

图16 战场态势(初始劣势)Fig. 16 Battlefield situation(Initial disadvantage)
在智能体初始占据优势的条件下再次进行仿真验证。双方获得的态势奖励如图17 所示,空战博弈不同阶段战场态势信息如图18 所示。由仿真数据可知,在初始占优的情况下,敌机在整个仿真过程中都处于智能体的有效攻击区内;200 s 时仿真结束,智能体获胜。

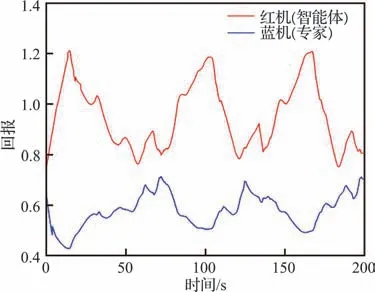
图17 博弈双方的奖励(初始优势)Fig. 17 Rewards for both sides of game(Initial advantage)
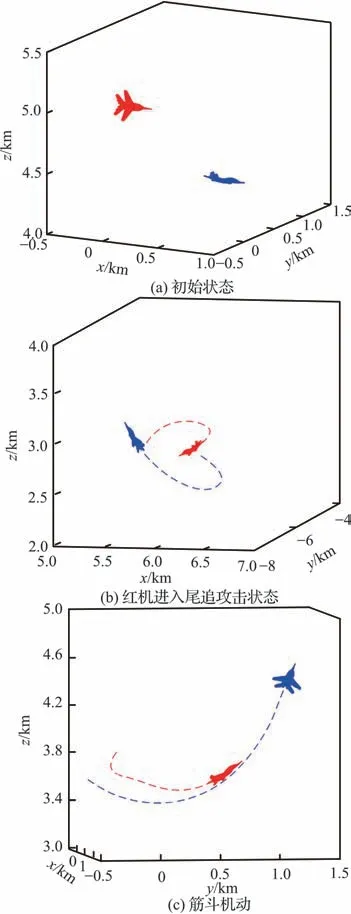
图18 战场态势(初始优势)Fig. 18 Battlefield situation(Initial advantage)
由4.1 节和4.2 节可知,所训练的智能q 体能够较好地应用于近距空战博弈任务。智能体都能做出光滑且合理的决策,在较短时间取得对敌机的有效攻击条件并保持。为进一步验证算法的可行性,将所训练的智能体移植到人机对抗仿真平台中与驾驶员进行空战博弈。
4.3 人机对抗仿真
为验证智能体性能,建立了人机对抗仿真平台,该平台由飞行员驾驶位、智能体载体、态势展示平台和仿真节点4 部分组成。这4 部分通过局域网进行数据传输。飞行员驾驶位和态势展示平台分别如图19 和图20 所示。

图19 驾驶位Fig. 19 Pilot cockpit
图20 态势展示平台Fig. 20 Situation display platform
人机对抗仿真过程如图21 和图22 所示。图21 给出了空战对抗过程中对抗双方的态势奖励。图22(a)~图22(d)是不同时刻战场态势,图22(e)是飞行员驾驶飞机的场景。在对抗初始阶段,智能体占据高度优势,此时对抗双方距离较远,驾驶员与智能体均选择相向而行,拉近双方距离;当距离缩短后,对抗双方为形成有效攻击条件,进行协调转弯;由图22(b)可知智能体首先取得对敌机的有效攻击条件,此时驾驶员为脱离智能体的攻击范围,分别进行筋斗机动和水平转弯,智能体针对敌机机动动作做出合理应对,驾驶员未能脱离劣势。

图21 对抗双方的奖励Fig. 21 Reward for confrontation

图22 人机对抗仿真Fig. 22 Human-machine confrontation simulation
5 结 论
针对近距空战博弈问题,提出了基于深度强化学习的智能空战自主决策算法,同时为验证建立的智能空战自主决策系统的性能,还建立了人机对抗仿真平台来验证算法性能。结论如下:
1)针对近距空战博弈构建了综合考虑攻击角度优势、速度优势、高度优势和距离优势的态势评价函数。所建立的奖励函数可以引导智能体向最优解收敛,避免了强化学习中的稀疏奖励问题。在高度奖励函数引入的动态权重校正项解决智能体在敌机引诱下坠地的问题。
2)基于TD3 算法,提出的基于价值的经验池样本优先度排序方法在保证算法收敛的前提下,显著提高了算法收敛速度。
3)在人机对抗仿真平台开展仿真试验,结果表明所训练的智能体不仅能够在不同仿真环境下完成空战博弈任务,还能够在人机对抗仿真平台上击败人类飞行员,为真实环境中无人机近距空战博弈提供了一种新的思路。
在进一步的研究工作中,可以将本文的算法扩展到多智能体空战中,能够更加接近战场的真实情况。
