基于注意力金字塔与监督哈希的细粒度图像检索
2023-03-27殷梓轩
殷梓轩,孙 涵
(南京航空航天大学 计算机科学与技术学院/人工智能学院,江苏 南京 211106)
0 引 言
细粒度图像检索是细粒度图像处理领域中的子方向,要求给定一张图片,算法能返回数据集中与该图片同属一个子类的图片。它与一般图像的检索不同,例如一般图像的检索要求在猫、狗、兔子中检索出来猫,细粒度图像检索则要求在波音737-300、737-400、737-500中找到波音737-400。可以看出细粒度图像具有类间差异小、类内差异大的特点。因此,通常在检索的范围内,所有图像在视觉上都是相似的,但它们会在一些局部的细节处存在微小的区别。这无疑是非常具有挑战性的。
图像检索的原理,其实就是计算数据库中所有图像与待检索图像在特征空间中的距离并进行排序,距离越近,说明该图像与待检索图像相似度越高。但在如今大数据时代,线性搜索显然是不现实的,不仅因为时间开销大,而且存储成本也高。而深度哈希[1-2]恰恰能解决这两个弊端,因为它可以把提取到的图像特征压缩成紧凑的二进制哈希码,从而减小存储空间,同时大大提升检索速度。因此,深度哈希方法受到了越来越多的关注。
深度哈希模型一般包含两个阶段:特征提取及特征编码。特征提取阶段其实就是要进行细粒度图像识别任务。现有的细粒度图像识别算法主要分两类[3]:带有定位-分类子网络的模型以及进行端到端特征编码的模型。但是现有的方法大部分只关注到了卷积神经网络中高层的语义信息,却忽略了低层的细节特征,该文则希望能把二者结合在一起。在特征编码阶段,深度哈希可以把图像特征映射为二进制形式的哈希码,从而在减小存储空间的同时大大提升检索速度。
具体地,该文提出了一个基于注意力金字塔与监督哈希的深度神经网络,用于解决大规模细粒度图像检索问题。它主要分为两大部分,分别是两阶段的特征提取网络以及哈希分类网络。在特征提取网络中,使用了一种双通路的金字塔结构,包含自上而下的特征通路以及自下而上的注意力通路,借此融合高层的抽象语义信息与低层的细节特征;与此同时,还在网络的两个阶段之间引入了一个中间层对输入图像进行细化。在哈希分类网络中,使用tanh(x)代替sign(x)作为激活函数,从而使学习到的哈希函数达到平稳分布;同时结合量化损失与分类损失,使生成的哈希码能更好地与原始输入图像的特征进行匹配。在两个标准细粒度图像数据集[4-5]上进行了大量实验,实验结果表明,提出的模型能进行高精度细粒度图像检索。同时还与当前的一些经典算法进行了实验比较,比较结果展示了该方法的优越性。
1 相关工作
1.1 细粒度图像检索
细粒度图像检索是近年来比较活跃的研究方向,其任务为:给定一个数据集,该数据集中的所有图片属于同一大类下的若干子类,要求输入一张待检索图片,系统能返回数据集中与其同属一个子类的若干张图片。现有方法可以分为两类:监督方法[6-7]和无监督方法。其中,监督方法中的代表方法是Zheng等人提出的度量学习方法[6]。为了更好地从背景中提取目标主体的部件特征,作者使用了一种弱监督的特征提取方式,通过由上到下的显著性分割目标轮廓。而无监督方法中的代表就是Wei等人提出的SCDA方法[8]。该方法首先从图片中定位目标主体,去除背景噪声并保留关键的深度描述子,接着再由这些深度描述子生成特征向量。
1.2 细粒度图像识别
细粒度图像检索是以识别任务为基础的,因为识别的准确性会直接影响后续分类网络的性能。现有的细粒度图像识别算法主要分为以下两类:(1)带有定位-分类子网络的模型[9-10]。如Zhang等人提出了一种学习部件级检测器的网络[9],Wei等人通过分割的方法[10]对关键部位进行定位。(2)端到端特征编码模型[11-12]。这一类方法对监督信息的依赖相对较低,它们一般仅要求提供图像级别的标注。其中最具代表性的是Lin等人提出的双线性卷积神经网络。
上述方法均能取得良好的效果,但它们都忽略了低层的细节信息。因为细粒度图像具有类间差异小、类内差异大的特点,因此低层的细节信息,如纹理、边缘等对识别任务是非常关键的。因此,受Ding等人AP-CNN[13]的启发,该文希望把高层的语义信息与低层的细节特征结合在一起。
1.3 深度哈希
深度哈希基于训练数据学习哈希函数,在还原原始数据空间距离顺序的同时生成更短的哈希码。这种紧凑的特征表示有利于存储大量样本并节省检索时间。依据是否使用标注信息,可以分为无监督方法和监督方法两类。前者如HashGAN[14]等在学习哈希函数时不需要监督信息,但是容易造成原始数据和哈希编码之间的语义鸿沟。而后者充分利用监督信息学习哈希函数并生成哈希码,具有更高的准确性,代表方法如KSH[15]等。
2 模型框架
2.1 网络基本架构
提出的网络分为特征提取以及特征编码两个阶段,如图1所示。其中特征提取是两阶段的:第一阶段为原始特征提取,以原始图片作为输入;第二阶段为细化特征提取,以第一阶段的输出作为输入。

图1 网络结构
网络接收到一张图片后,首先使用骨干网络生成特征金字塔,其信息流动方向是自上而下的。然后引入注意力机制,得到注意力金字塔,其信息流动方向是自下而上的。以上是网络的第一阶段。使用中间层对原始图像进行细化,并输入二阶段网络。网络第二阶段的工作流程与第一阶段是相同的,并最终得到两个注意力金字塔,对它们做连接操作后即可用于后续的特征编码。
2.2 双通路金字塔
2.2.1 自上而下的特征金字塔
一般地,原始图像输入经过卷积神经网络的处理会得到具有高层语义信息的特征表示,但这会使低层的许多细节特征被丢失,不利于细粒度图像的处理。为了能保留这些细节特征,受FPN网络[16]的启发,该文设计了一条自上而下的特征通路来提取不同尺度的特征。
原始的输入图像在经过若干卷积块后可以得到若干特征图,把这些特征图表示为{B1,B2,…,Bl},这里l表示卷积块的数量。很多针对粗粒度图像处理的方法会直接把最后一块的输出Bl用于分类,但该文希望尽量利用好每一个Bi。由于越靠近低层,特征的抽象层次越低,如果要利用每一个卷积块的输出,将不可避免带来巨大的成本开销,因此选择其中的后N个输出并生成对应的特征金字塔。具体如图2所示。最终得到的特征金字塔为{Fl-N+1,Fl-N+2,…,Fl}。

图2 特征金字塔
2.2.2 自下而上的注意力通路
得到特征金字塔后,该文设计了一条自底向上的注意力通路,其中包含空间注意力以及通道注意力。空间注意力[17]用于定位输入图像在不同尺度上具有辨识度的区域。其形式化描述为:
(1)
式中,σ为sigmoid激活函数,*代表反卷积操作,而K代表卷积核。通道注意力[18]用于加入通道之间的关联,并同时把低层的细节信息一层一层传递给高层。其形式化描述如下:
(2)

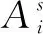

图3 注意力金字塔
(3)
2.3 中间层
2.3.1 ROI金字塔

2.3.2 基于ROI的图像细化

2.3.3 细化特征提取阶段

(4)
并把Foutput用于后续的分类。
2.4 深度哈希
2.4.1 稳定分布与量化损失
受DSHSD[20]的启发,该文引入了p稳定分布。记输入图像从欧几里德空间到汉明空间上的损失为量化损失,当量化损失较小时,可以认为哈希函数是一个p稳定分布,否则是不稳定的。因此,为了使量化损失尽可能小,选择tanh(x)作为激活函数,使用‖tanh(xi)-tanh(xj)‖p代替‖xi-xj‖p来保证分布一致性。tanh(x)不仅梯度容易计算,而且对于反向传播算法来说是友好的:
(5)
于是量化损失可以写成:
(6)
(7)
(8)
式中,S为相似性标签的集合,m为阈值参数且m>0,‖·‖2表示L2范数并用于衡量哈希码之间的距离。
2.4.2 分类损失
除了量化损失以外,为了使哈希码能保留图像特征中的分类信息,还引入了分类损失。不同于以前的一些方法,为了不引入额外的变量,该文并没有对hi施加二值化约束,这也符合奥卡姆剃刀原理。于是分类损失的形式化表示如下:
Lc(Y,H)=L(Y,WTH)
(9)

最后,结合公式6与公式9就可以得到总的损失函数:
L(Y,S,H)=Lc+εLd
(10)
式中,ε是控制量化损失的权重参数。
3 实验结果与分析
在FGVC-Aircraft以及Stanford Cars两个标准细粒度数据集上进行了实验验证。其中FGVC-Aircraft数据集包含了10 200张飞机的图片,共有102种不同的机型,其中训练集有6 667张图片,测试集有3 333张图片。Stanford Cars数据集包含了16 185张汽车的图片,共有196种不同型号的汽车,其中训练集有8 144张图片,而测试集有8 041张图片。该文使用mAP作为度量指标。
3.1 实现细节
该文使用ResNet-50作为骨干网络,并在ImageNet上进行预训练。选择ResNet-50的后3个残差块输出的特征图建立特征金字塔,没有选择conv1和conv2主要是因为它们的抽象层次较低,若参与特征金字塔的构建将带来较大计算开销。所有图片在输入网络时大小均会被调整为448×448。该文并没有使用数据集提供的bounding box标注信息,因为在实际问题中,bounding box的获取成本较高,过于依赖它会使方法存在较大局限性。

图4 波音747与布加迪威龙16.4图片检索示例
自适应NMS算法中的阈值t1和t2分别设置为0.05和0.9。公式8中的阈值m设置为2k(k为哈希码位数且k={16,32,64})。公式3中的权重参数α设置为0.5,公式10中的ε设置为0.1。在模型训练的过程中,该文使用的优化算法为Adam算法,其中学习率设置为10-5,β1设置为0.9,β2设置为0.999。
3.2 对比实验
文中方法与其他4种State-Of-The-Art方法在2个数据集、3种哈希码长度下的对比结果如表1所示。从表中可以看出,文中方法无论在16位哈希码、32位哈希码以及64位哈希码中都能达到最高的准确率,这验证了该方法的准确性。具体地,在FGVC-Aircraft数据集中,文中方法在三种长度哈希码下的准确率比第二名的DCH分别提升了33.0%、15.9%以及27.8%。在Stanford Cars数据集中,文中方法在三种长度哈希码下的准确率比DCH分别提升了16.4%、30.8%以及33.9%。这得益于在哈希层中使用了tanh(x)作为激活函数,可以保证哈希变换过程中的分布一致性,使哈希码可以更好地保留图像的特征信息。
图5展示了5种方法在FGVC-Aircraft数据集上的mAP随哈希码位数的变化。可以很直观地观察到,文中方法在16位、32位以及64位长度的哈希码上效果都大幅优于其他四种方法,同时,哈希码长度的改变并不会显著影响文中方法的准确度。

图5 mAP随哈希码位数的变化
总体上,5种方法的mAP基本会随着哈希码位数的增加而增加,这很容易解释,因为哈希码的位数越高,它的特征表示能力也越强。但也有例外,如DCH在FGVC-Aircraft数据集中,当哈希码长度由32位变成64位时,mAP反而从68.4%下降到了64.4%。
图6展示了5种方法在FGVC-Aircraft数据集上的PR曲线。可以直观地看出,文中方法的PR曲线所围成的面积是最大的,这证实了该方法的有效性。

图6 PR曲线对比
3.3 消融实验
在特征提取网络中,该文结合了特征金字塔与注意力金字塔。为了分别验证它们的作用效果,使用32位哈希码设计了如下消融实验。
在表2中,Baseline即ResNet-50,FP表示只使用特征金字塔,FP+AP表示既使用特征金字塔,也使用注意力金字塔。可以看出,特征金字塔能在Baseline的基础上较大地提升模型准确率,而注意力金字塔能让准确率有进一步的提升。

表2 不同特征提取网络下的mAP对比 %
接下来,验证了中间层中使用到的Dropblock算法以及背景噪声去除算法的作用效果,消融实验同样是基于32位哈希码设计的。由表3可知,Dropblock算法迫使网络学习不同区域的特征,从而能较大提升网络性能。而背景噪声去除算法作为一种辅助手段,虽然提升效果不如Dropblock算法,但也可以在一定程度上提升网络性能。

表3 不同特征提取网络下的mAP对比 %

由表4可以看出,在分类损失与量化损失中,分类损失起主要作用,同时也可以看出使用tanh(x)作为激活函数的巨大优势。

表4 各哈希方法的对比
4 结束语
细粒度图像检索是一个在日常生活中有着广泛应用、但却充满挑战性的任务。该文提出了一种基于注意力金字塔和监督哈希的深度神经网络。通过两阶段的特征提取网络构建双通路金字塔,把高层语义信息与低层细节特征充分结合,同时引入了一个中间层对图像进行细化;在哈希编码阶段结合了量化损失与分类损失,并使用tanh(x)代替sign(x)作为激活函数,使学习到的哈希函数达到平稳分布的要求,减少了反向传播过程中量化损失的偏差,从而使生成的哈希码更好地与原本图像的特征进行匹配。为了验证模型的有效性与准确性,在两个标准的细粒度数据集上进行了大量实验。通过在16位、32位以及64位三种长度的哈希码上与四种SOTA方法进行对比,证实了该模型的有效性,同时通过一系列消融实验验证了不同算法组件的作用效果。
