单级特征图融合坐标注意力的视觉位置识别方法*
2023-03-25刘子健张军刘元盛路铭宋庆鹏
刘子健 张军 刘元盛 路铭 宋庆鹏
(北京联合大学,北京市信息服务工程重点实验室,北京 100101)
主题词:自动驾驶 视觉位置识别 回环检测 坐标注意力 局部聚合向量网络 三元组损失
1 前言
自动驾驶汽车基于同步定位与建图(Simultaneous Localization and Mapping,SLAM)[1]构建自主导航系统。在长期运行中,定位系统会产生累积误差,导致定位失效。实践中,自动驾驶汽车先存储已访问过场景的表征向量,再在汽车运动时匹配当前环境的表征向量解决定位问题,即回环检测与重定位。随着自动驾驶汽车的发展,以视觉位置识别(Visual Place Recognition,VPR)[2]技术为代表的回环检测与重定位方法受到关注。VPR 以环境中的视觉特征为基础,计算形成环境表征向量[3]。目前应用于VPR技术的视觉特征主要分为基于规则设计的手工特征和基于数据驱动的学习特征。
基于规则设计的角点和描述子组合的ORB(Oriented FAST and Rotated BRIEF)[4]局部特征具有尺度和旋转不变性,对图像噪声及透视变换具有鲁棒性。因此,ORB特征能准确地描述和检索稳定不变的环境信息。但此类方法可能受到视角转换、光照和季节变换等因素影响,产生当前观测的环境信息与数据库中已知的环境信息存在较大差异的现象,最终导致位置识别结果的准确率降低等问题。
基于数据驱动的卷积神经网络(Convolutional Neural Networks,CNN)[5]具有强大的图像表示能力。为在现有VPR方法的识别精度下提高定位系统的鲁棒性和实时性,本文针对环境中的视觉特征空间关系学习和高层特征学习两方面进行改进:在骨干网络中融合坐标注意力,获得视觉特征的空间位置关系和显著的空间位置信息;利用多重扩张卷积和局部聚合向量网络,构造多尺度特征融合的特征编码器,获得单级特征图在不同尺度下的视觉特征向量。最后,将该方法在公开数据集上进行验证。
2 本文方法
本文基于残差网络(Residual Networks,ResNet)[6]提出一种弱监督训练的VPR 方法,实现高效的视觉位置识别:输入图像集或图像序列,通过本文搭建的神经网络得到特征匹配结果,最终输出检索结果。系统流程如图1所示。

图1 系统流程
2.1 特征提取
2.1.1 残差网络
深层CNN 存在参数爆炸、梯度消失等问题。ResNet 通过短路连接解决深层网络梯度消失带来的学习退化问题。当理论残差为零时,残差结构只做恒等映射以确保实际残差不会为零,同时保持当前网络性能,结构如图2所示。

图2 残差结构
本文采用ResNet-50 作为提取图像特征的骨干网络。自动驾驶汽车采集的视觉信息在ResNet中经过卷积(Convolutional,Conv)层、批归一化(Batch Normalization,BN)层、激活函数和池化层完成预处理,随后再经过4组瓶颈(Bottleneck)层提取特征信息。
2.1.2 坐标注意力网络
坐标注意力(Coordinate Attention,CA)[7]网络将输入的二维全局池化转化为单个特征向量的过程,分解为水平方向和垂直方向一维特征编码过程,将聚合的方向信息嵌入特征图中。通过级联捕获的2 个空间方向的依赖关系和位置信息,经BN 层和非线性变换生成空间信息的特征图。沿着水平和垂直方向切分特征图得到注意力权重,使网络捕获到特征的位置关系。网络结构如图3所示。
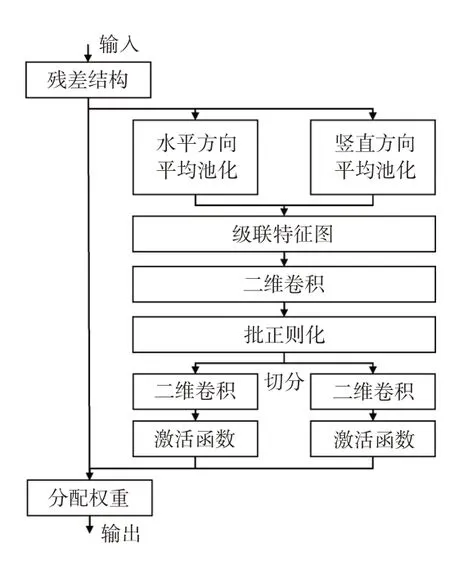
图3 坐标注意力网络结构
2.1.3 融合CA的ResNet特征提取网络
视觉特征的相对位置关系对于位置识别结果至关重要。为了在开放环境中保持定位系统的鲁棒性,需要网络模型具备筛选重要的环境特征和获取视觉特征坐标的能力。为弥补ResNet 对图像特征的空间关系不敏感的缺陷,本文在其残差结构中引入CA,构建新的特征提取网络。通过捕获环境特征的空间位置关系,获得特征间的依赖关系和精确的位置信息。
CNN 的浅层输出边缘和色彩等具体的图像特征,随着网络层数的加深,输出的特征图尺寸逐渐减小,视觉信息逐渐抽象和语义化。ResNet 的Conv5 特征图包含对图像变化足够鲁棒的视觉特征,同时具有丰富的语义信息。因此,本文在Conv5的短路连接和瓶颈层之间引入CA,将生成的特征图编码为一组方向感知和位置敏感的注意力热图,促使网络学习到特征间隐含的空间结构关系,帮助模型准确定位感兴趣的目标,增强特征图表达能力。改进后的网络利用CNN提取图像的局部信息,发挥了CA对全局信息建模的能力,有效提高视觉特征的表达能力。改进后的网络结构如图4所示。

图4 改进的坐标-残差结构
2.2 特征编码
对环境的局部视觉特征进行建模,不足以区分局部特征相似的场景,需要联系上下文信息和环境的整体信息对场景进行同一性判断。特征金字塔(Feature Pyramid Network,FPN)是获取多尺度特征的经典网络,但车载设备的算力普遍较低,导致基于FPN 的VPR 方法移植到车载设备存在实时性差的问题。扩张卷积(Dilated Convolution,DC)[8]具有仅增加1 个参数即可获取更广视野范围特征图的特点。因此,本文基于DC 和局部聚合向量网络(Vector of Locally Aggregated Descriptors Network,NetVLAD)构造图像编码器,利用DC-NetVLAD 对Conv5 卷积层输出的单级特征图进行视野扩张,然后对不同视野下的图像特征进行聚合得到图像的描述向量,在不失精度的前提下节约计算成本,提高系统的实时性。
2.2.1 局部聚合向量网络
基于局部特征解决VPR 问题,需要对特征矩阵进行聚类处理以压缩数据维度。相比视觉词袋(Bag of Word,BoW)编码,局部聚合描述符向量(Vector of Locally Aggregated Descriptors,VLAD)不仅保存每个特征点到离它最近的聚类中心的距离,还记录了特征点在不同维度的取值,避免了信息损失问题。VLAD 的计算公式为:
式中,Xi为输入的数量为N的局部特征向量;V(J,K)为输出的聚类后的特征向量;K为聚类中心的数量;J为第k个特征向量的维度;xi(j)为第i个局部特征的第j个特征值;ck(j)为第k个聚类中心的第j个特征值;ak(Xi)为二值的符号函数,对每个属于聚类中心ck的特征向量xi,ak的值取为1,否则为0。
原始的VLAD为不可导函数,为得到端到端的特征聚类结果,Arandjelovic等[9]在VLAD算法的基础上,用归一化指数函数(Softmax)代替原始方法中的最近邻二值函数ak,提出NetVLAD 算法。NetVLAD 设定的聚类的数量为K,计算局部特征在这些聚类的差值分布得到全局特征,使VLAD算法中需要手工聚类获得的参数改为通过网络训练获取。系数(Xi)的计算公式为:
2.2.2 基于DC和NetVLAD构造特征编码器
首先去掉ResNet-50 网络最后的全局平均池化和全连接层,利用1×1卷积对残差网络输出的特征图进行通道压缩减少计算量,然后经过3个并联的具有不同扩张率参数的扩张卷积,得到不同视野下的图像特征。为避免扩张卷积中心点不连续,本文的扩张率参数分别设定为6、12和18。在NetVLAD中,经过激活函数Softmax和局部聚合层的池化获得VLAD特征,通过类内正则化对每个聚类中心的所有残差分别进行正则化,最后将所有VLAD 特征共同进行欧式范数正则化得到图像全局表示的特征向量。改进后的DC-NetVLAD 编码器结构如图5所示。

图5 本文改进的扩张卷积-局部聚合向量网络编码器
2.3 基于三元组损失训练网络
NetVLAD 算法首先将图像的局部特征聚类压缩,得到以聚类中心表示的全局特征图,然后将待查询图像的特征向量与数据库中的图像向量进行相似度计算,以余弦相似度为度量,距离越小的图像之间越相似。余弦距离的计算公式为:
式中,G、H分别为输入的2个特征向量;n为向量维度;gi、hi分别为G、H第i个维度的特征值。
针对环境中普遍存在着视觉特征相似场景的情况,本文使用三元组损失(Triplet Loss,TL)[10]训练网络来提高系统的查准能力。TL的输入是一组编码后的图像特征,包括正例、负例和基准图像。基于TL训练的网络能够优化图像与特征向量之间的映射关系,在新的特征空间中使负例到基准图像的距离尽可能大于正例到基准图像的距离,从而提升网络识别正例的能力,效果如图6所示。

图6 三元组损失
根据模型训练的需要设定边缘阈值β控制正、负样本的距离。TL目标函数的表达式为:
超参数β控制损失函数的结果:L>0 时取该值作为损失;L<0 时,表示负例与基准样本的距离大于正例与基准样本的距离,因此损失函数的结果记为0。
3 试验设置与结果分析
3.1 试验环境和数据集说明
本文的试验环境为Ubuntu 18.04 LTS 操作系统,硬件平台采用11代英特尔i7处理器、32 GB内存和英伟达RTX 2080Ti显卡。
采用Pitts30k 和Nordland[11]2 个公开数据集进行测试。Pitts30k 是谷歌公司制作的城市街景数据集,该数据集基于地理位置进行划分,包括训练、验证和测试部分,分别含有约7 000 张查询图像和10 000 张参考图像。Nordland 数据集采集自挪威北部地区,包含4个帧率为25 帧/s 的视频影像,展示长约728 km 的环路场景在四季变化下不同的视觉外观。
3.2 试验设计与评价指标
针对Nordland数据集,通过插值GPS数据实现时间同步,保证每个视频中任意帧的车辆位置都能够对应到其他3个视频中的同一帧。
以Pitts30k的训练集作为训练样本,设定10 m以内的图像为正例,25 m 以外的图像为负例。训练模型的输入图像组包括基准图像、1个正例和10个负例。
本文以召回率-查准率作为评价指标,与典型的VPR方法进行比较,包括手工聚类特征的算法DBoW2、本文工作的基线方法NetVLAD和同基线方法的先进成果Patch-NetVLAD[12]。具体规则如下:
a.基于Pitts30k 数据集的验证,规定如果召回的前Q张图像中,至少存在1张图像距离用于测试的基准图像在地理范围的10 m内,则认为图像已被正确检索。
b.基于Nordland数据集的验证,规定如果召回的前Q张图像中,至少存在1张图像距离用于测试的基准图像在10帧内,则认为图像已被正确检索。
c.试验的评价指标为召回率(Recall)和查准率(Precision):
式中,R为召回率;P为查准率;TP为真正例数量;FP为假正例数量;FN为假负例数量。
3.3 试验结果与讨论
3.3.1 特征降维试验
首先对本文方法在位置识别任务中的召回率进行测试,Q的不同取值条件下试验结果如表1所示。
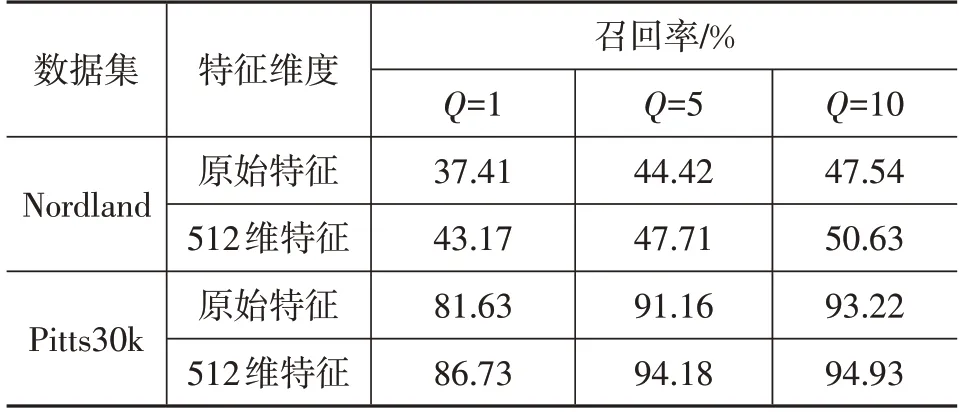
表1 本文方法的召回率
相比原始特征向量,经过主成分分析(Principal Components Analysis,PCA)降维的特征向量在位置识别任务中的召回率表现更好。在Nordland 数据集上的平均召回率提高4.05 百分点,在Pitts30k 数据集上的平均召回率提高3.28 百分点。提高平均召回率的主要原因是降维后的图像特征忽略了没有辨识度的特征区域,突出了图像中具有区分度的部分,产生更好的召回结果。
3.3.2 位置识别试验
为验证本文改进方法的有效性,将本文方法与近年来具有代表性的VPR 方法和同基线的方法进行对比。对不同方法得到的特征向量均降维到512维,使用召回率-查准率评价指标进行分析。本文方法和对比方法在Pitts30k数据集和Nordland数据集上的试验结果如图7所示。

图7 不同方法在2种数据集上位置识别任务中的召回率-查准率曲线
在侧重视角变化的Pitts30k 数据集上,NetVLAD 算法在召回率为30%时开始出现精度下降,DBoW2 和Patch-NetVLAD 算法在召回率为40%时开始出现精度的快速下降,本文方法在召回率为50%时才出现明显的精度下降。与DBoW2 和NetVLAD 算法相比,本文方法更快地检索到了所有正例图像;仅在召回率达到80%后,本文方法的召回精度与Patch-NetVLAD算法相比略有不足。
在具有季节变化和光照变化的Nordland数据集上,本文方法始终优于DBoW2 和NetVLAD 算法,与先进的Patch-NetVLAD 算法相比,在召回率达到70%前,本文方法也保持着更好的召回精度。
可以看出,相比DBoW2 和NetVLAD 算法,本文方法在试验中始终保持着更好的召回精度。这是由于融合的坐标注意力能够记录明显的空间特征位置关系,在视角变化的情况下,特征间的相对位置关系保持稳定,而不同视野特征图的组合编码能够覆盖不同视距下的观测结果。同时也可以观察到,本文方法在高召回率的场景中召回精度相比同基线的Patch-NetVLAD 算法略低。这是由于Patch-NetVLAD 算法采用基于区块尺度的图像特征和基于一致性评分的重新排序策略实现了召回精度的提升。相应地,此策略降低了Patch-NetVLAD 算法的检索速度,因此本文方法的检索速度与Patch-NetVLAD算法相比有19%的提升。视觉SLAM的实际测试中,常常需要快速实现场景重识别和回环检测,很少产生需要全部召回的现象,因此本文方法的实用性更强。
经上述试验验证,本文方法在召回率-查准率的评价体系下明显优于DBoW2 和NetVLAD 算法,与先进的Patch-NetVLAD相比,本文方法牺牲较少的召回精度获得了检索速度的大幅提升,证明本文改进方法的有效性。
3.3.3 回环检测试验
回环检测是视觉定位中校正全局地图累积误差的重要手段。为验证本文方法在回环检测任务中的表现,设计一组基于旋风智能车[13]试验平台的应用测试。试验平台如图8 所示,其处理器为Jetson TX2,包含6 核CPU、256核帕斯卡(Pascal)架构GPU和8 GB内存。

图8 旋风智能车试验平台
利用ORB-SLAM2[14]算法在Nordland数据集的原始影像上提取用于建立回环地图的关键帧序列,以关键帧序列为数据集进行回环测试。将本文方法与DBoW2、NetVLAD 和Patch-NetVLAD 算法在回环检测任务中的表现进行对比,试验结果如图9所示。

图9 季节变化下的回环检测
由图9 可以看出,Nordland 数据集夏季序列和冬季序列之间存在较大的外观差异。相比DBoW2 和NetVLAD算法,本文方法和Patch-NetVLAD算法用于回环检测任务的结果更接近真实的回环位置,进一步说明本文改进方法的鲁棒性。统计几种方法在回环检测任务中平均闭环准确率和检测时间,结果如表2所示。
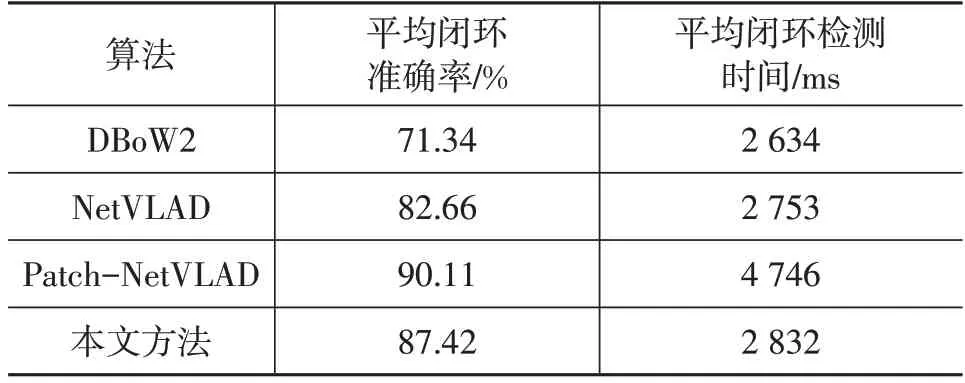
表2 对比方法在回环检测任务中的性能
由表2可知:相比DBoW2和NetVLAD算法,本文方法在回环检测任务中的平均闭环准确率有所提高;与Patch-NetVLAD 相比,本文方法的平均闭环准确率略低,但是在时间性能上具有明显优势。
3.4 消融试验
为探究本文所提出的改进点对试验结果的影响,在Pitts30k数据集上通过消融试验对两方面的改进进行验证,如表3所示。
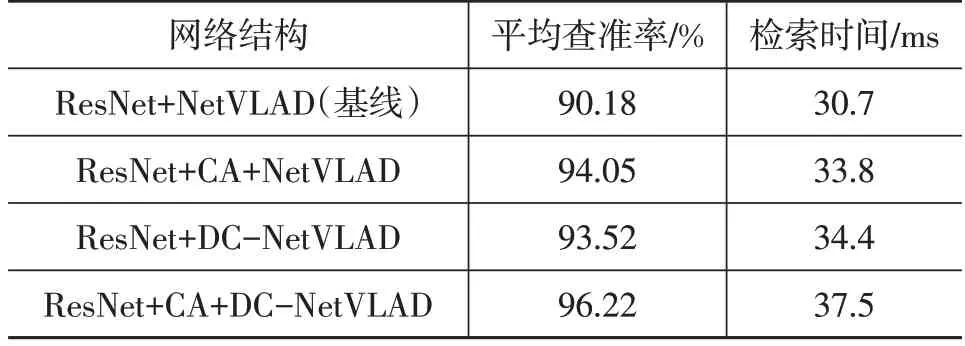
表3 消融试验结果
相比基线方法,本文改进方法获得了更好的平均精度,检索时间仅延长6.8 ms。其中,融合CA对网络的精度提升3.87百分点,使用DC-NetVLAD编码器对网络的精度提升3.34百分点。通过融合CA使特征间的位置关系得到利用,利用并联的DC-NetVLAD编码器发挥不同视野下特征图信息的互补性。最终的试验结果表明,同时采用2个模块对网络进行改进,平均精度提升6.04百分点,进一步提升了网络的位置识别能力,证明本文的2个改进点具有一定的互补性。
4 结束语
针对开放场景中的自动驾驶汽车的视觉定位和位置识别问题,本文在现有方法的基础上提出两点改进:基于残差网络融合坐标注意力提取图像特征,提高原始网络对图像特征位置关系的捕获能力;通过多重扩张卷积和NetVLAD 实现轻量的多尺度特征融合,编码图像的表征向量。试验结果表明:在季节、光照和视角等变化导致环境外观发生改变的场景中,本文提出的方法取得了96.22%的召回精度,单帧检索时间仅需37.5 ms,与同基线方法相比,显著提高了检索速度和召回精度。
针对视觉传感器捕获的信息模态较为单一,在视觉受限的场景容易产生系统失效的问题,后续将开展多源传感器融合定位的研究以及通过云端计算的方式缓解边缘设备的算力问题等相关工作,实现自动驾驶车辆的高精度定位。
