面向医疗数据的隐私保护方法研究
2023-03-24徐云山贺丹严贞龙李永立丘振钢杨秋鸿
徐云山 贺丹 严贞龙 李永立 丘振钢 杨秋鸿

关键词: 隐私保护;匿名化;医疗数据;等价类;数据脱敏
1 引言
随着大数据、云计算、人工智能等信息技术的飞速发展,为医疗信息系统的发展带来了新的机遇[1]。电子病历和医疗信息系统的出现,是信息化进程中重要的一个环节,电子病历让病历的记录和存储更加方便,医疗信息系统为患者数据的管理和存储带来了便利。同时,医疗数据的日益累积,为医疗数据的管理带来了较大的挑战,尤其是随着医疗数据共享和数据传输日益频繁,医疗数据的隐私保护问题也日益突出[2-3]。在医疗数据的使用和传输过程中,不可避免地发生患者隐私泄露的情况,这为患者的正常生活带来了较大影响,尤其是当患者不希望自身疾病信息被公之于众时,因此保护医疗数据的隐私成为一个研究热点[4-6]。国家也逐渐意识到信息安全的重要性,并于2020年12月14日发布了《信息安全技术健康医疗数据安全指南》,该安全指南对健康医疗数据进行了定义,提出了健康医疗数据分类体系,并对健康医疗数据的使用提出了一系列指南,该指南从2021年7月1日正式实施。国家在“十三五”规划中也提出了加强医疗信息安全防护体系建设的要求,医疗数据的隐私保护问题已经成为医疗信息化发展过程中亟须解决的问题之一。
2 医疗数据隐私保护现状
2.1 隐私保护问题描述
患者的医疗数据通常包括身份信息、诊疗信息、其他信息三部分,身份信息主要是用来标识患者的个人身份,主要包括:诊疗号、身份证号、社保卡号、姓名、性别、年龄等信息;诊疗信息主要是记录患者就诊和治疗的相关信息,主要包括:病史、心率、血压、疾病、脉象、过敏史等信息;其他信息主要是与身份信息和诊疗信息无关的信息,主要包括:就诊医院、就诊时间、就诊医生、工作单位等信息。通过患者的身份信息可以分成主标识符和非主标识符,其中主标识符是可以唯一确定患者身份的属性,如诊疗号、身份证号、社保卡号等,非主标识符是不能唯一确定患者身份的属性,如姓名、性别、年龄这些属性不能确定患者身份,但是一旦将这些属性与其他属性进行结合就能推断出患者的身份信息,例如将患者的姓名与患者的工作单位相结合,就有可能推断出患者的身份信息。
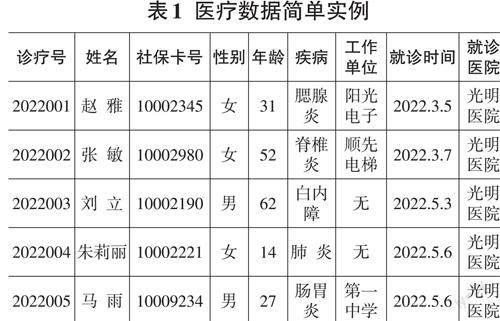
在《信息安全技术健康医疗数据安全指南》中明确指出在医疗数据的获取、收集、存储、处理、传输、发布、销毁等过程中要严格保护患者的隐私,不能随意泄露患者的身份信息和诊疗信息,也不能通过身份信息、诊疗信息、其他信息之间的关联性准确推断出某条就诊记录是哪个就诊人所有。就诊信息中的疾病信息是关系到患者隐私的敏感信息,如果疾病信息被泄露,将对患者的基本生活和工作带来非常大的负面影响,一些特殊的疾病(如癌症、抑郁症等)甚至会让患者受到旁人的歧视和区别对待。表1是医疗数据的简单实例。
2.2 隐私保护问题研究现状
国内外学者针对医疗数据的隐私保护问题进行了广泛研究,通过对已有研究成果进行分析和总结,根据研究方法的不同,可以将医疗数据的隐私保护方法分成匿名化、加密算法、身份认证、差分隐私等四类。文献[7,8]提出了一种针对电子病历的隐私保护模型,该模型中的主要使用差分隐私算法实现对电子病历的隐私保护;文献[9]提出了随机k匿名化的隐私保护方法,采用聚类的方法将原始医疗数据划分成几个数据集,再将子数据集划分成等价类;卲华西[10]提出了三种基于T-Closeness的分布式大数据脱敏算法,三种不同的分布式算法具有不同的应用场景,可以实现不同场景的数据脱敏。高志强[11]等人对差分隐私技术的研究进展进行了全面总结,并提出了在新的差分隐私模型下的数据收集方法和数据分析方法。从现有研究方法可知,当医疗数据发布时,一方面要按照国家相关政策保证患者的隐私信息,另一方面要确保隐私保护之后的数据能满足实际的使用需求。当隐藏的信息过少时,从发布的数据很容易推断出患者的隐私信息,甚至能唯一确定患者的身份;当隐藏的信息过多时,会造成医疗数据无法使用。因此,需要一种既满足使用需求又满足隐私保护的方法,在保护患者隐私的同时尽可能地提供更多的可用信息。
3 医疗数据隐私保护方法
针对现有医疗数据隐私保护方法中存在的问题,本文提出一种基于聚类的数据隐私保护方法,通过为非主标识符构建多层泛化树的方法,并构造基于记录的等价类,从而实现匿名保护方法。
3.1 泛化树的构建方法
泛化是将属性的具体取值转化为一个取值范围,也就是将一个具体的值换成包含该值的区间,或者将一个取值范围较小的区间换成一个取值范围较大的区间。为了实现匿名化,泛化的属性将包含更少的信息。例如,社保卡号是“10002345”,将其执行域泛化为“1000234*”。域泛化满足每个域最多有一个直接泛化域,同时满足每个域中最大属性的属性值是唯一的。社保卡号的域泛化操作如图1所示。值泛化是满足在取值域中的每一个值,在泛化域中都有且只有一个泛化值与之对应,社保卡号的值泛化操作如图2所示,将这些泛化值进行组合,就得到了一棵泛化树。
泛化树的具体定义方式为:针对属性A,其取值范围为域D,D 是一个有限集,将树的节点集合表示为T={R, X1, X2, …, Xm, Y1, Y2, …, Yn},其中R表示的是泛化樹的根结点,Y1至Yn表示泛化树一共有n 个叶子结点,X1至Xm表示泛化树除了根节结点和叶子结点之外,一共有m 个中间结点。定义函数F 为集合T 到域D 的一个幂集映射,对于集合T 中的两个结点u 和v,当结点u和结点v 为父子关系时,满足:F(v)⊆F(u)。针对集合T中的根结点R 和叶子结点,满足:(1) |F(Yi)|=1,其中i 属于[1, n];(2) F(Y1)∪F(Y2)∪…F(Yn)=F(R);(3) F(R)⊂D。
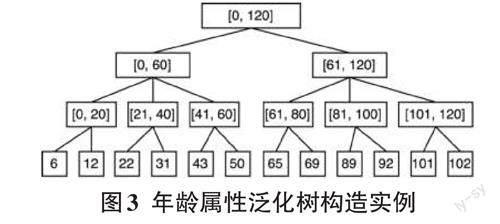
现以患者的年龄为例,构造其对应的泛化树,如图3所示。
3.2 聚类
针对医疗数据,本文采用聚类的方法构造等价类,从而减少医疗数据的信息损失。首先,将原始医疗数据集的数据映射到欧几里得空间,相似的医疗数据记录被聚类到同一个类中,于是同一个类中的记录构成一个等价类,同一个类中的记录相似度非常高,不同类中的记录相似度较低。在初次聚类时,根据经验选取几个聚类中心点,并根据医疗数据记录与聚类中心的距离将数据记录划分到相应的类中。在进行记录划分时,需要计算两条记录的相似性,于是将两条记录在属性A上的两个属性值a1和a2的相似性计算如下:
上式中Sim(a1,a2)表示属性值a1和a2的相似度,d表示泛化树的最大深度,p表示属性值a1和a2在泛化树上的最短路径上中间结点的个数。Sim(a1,a2)的计算值越大,则以图3中计算[21,40]和[41,60]的相似性为例,其中d 取值为4,因为泛化树的最大深度为4,p 的取值为1,因为从[21,40]到[41,60]在泛化树上的路径为:[21,40]->[0,60]->[41,60],路径上的结点个数为1,从而计算得到[21,40]与[41,60]的相似性为:Sim([21,40],[41,60])=-log(1/8)=0.903。同理,计算得到[21,40]与[81,100]的相似性为:Sim([21, 40], [81, 100]) =-log(3/8) =0.426。从计算结果可以看出,[21,40]与[41,60]更相似。
4 实验
为了验证本文医疗数据隐私保护方法的正确性,现通过实验验证本文方法的性能。本次实验采用Windows10 操作系统,实验设备的CPU 为Inter i5-7200U,用Python 3.9 开发程序、PyCharm 2021.2 为集成开发平台,搭建完整的实验环境。本实验采用的数据为真实的医疗数据,主要属性包括诊疗号、姓名、社保卡号、性别、年龄、疾病、过敏史、脉搏、血压、工作单位、就诊时间、就诊医院等。
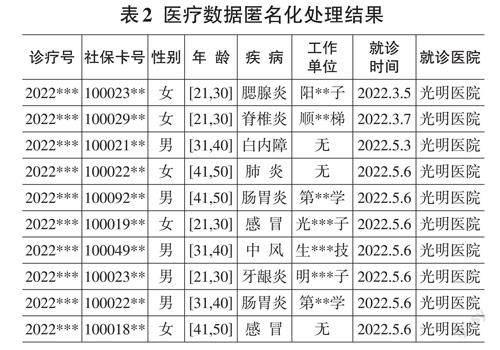
表2为医疗数据匿名化处理的结果,在该匿名化处理中以年龄作为准标识符。其中年龄在[21,30]之间的有4人,年龄在[31,40]之间的有3人,年龄在[41,50]之间的有3人。通过匿名化处理之后,每条记录是很难推测出患者的真实身份,同时,数据具有较高的可用性,不影响后续的数据使用。
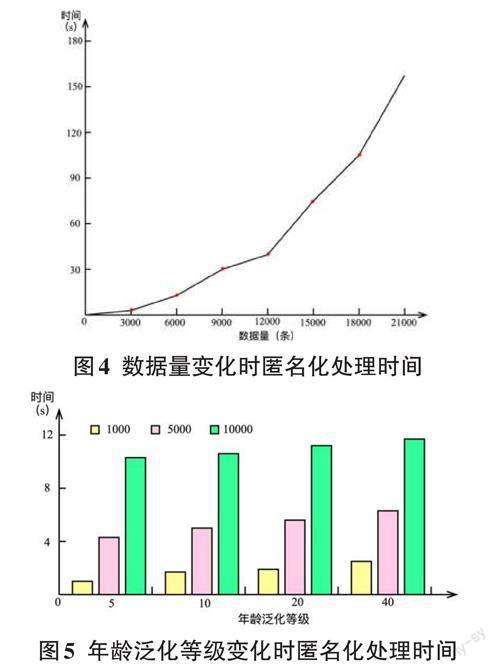
为了进一步验证本文隐私保护方法的性能,选取不同数据量的医疗数据进行实验。图4展示了当匿名化参数k=3,相似性阈值Sim(a1,a2)=0.65时,数据量从0变换到20000时,匿名化处理所需时间。图5展示了当数据量分别为1000、5000、10000,匿名化参数k=3,相似性阈值Sim(a1,a2)=0.65,年龄泛化等级分别为5、10、20、40时的匿名化处理时间。
从图4中可以看到,随着医疗数据量的增大,匿名化处理的时间也随之增加,当数据量分别为3000、6000、9000、12000、15000、18000、20000时,匿名化处理所需时间分别为5.2s、17.3s、32.5s、45.6s、78.5s、114.5s、174.6s,这是因为随着数据量的增加,聚类操作所需的迭代处理次数也随之增加,从而匿名化处理时间增加。从图5中可以看出,当年龄泛化等级相同时,随着数据集的增大,匿名化处理所需时间也逐渐增加,当年龄泛化等级为5,数据量分别为1000、5000、10000 时,数据匿名化处理所需时间分别为1.1s、4.2s、10.7s,这时随着数据量的增加,两条记录相似性的计算时间也增加,从而匿名化处理时间增长。此外,随着年龄泛化等级的增加,同一数据量的匿名化处理时间并未发生较大的变化,例如,当数据量为10000,年龄泛化等级分别为5、10、20、40時,匿名化处理所需时间分别为10.7s、10.9s、11.2s、11.5s,这是因为使用不同的年龄泛化等级时,聚类次数并未发生明显的变化,从而匿名化处理所需时间也没有明显增加。
5 结论
本文针对医疗数据在获取、收集、存储、处理、传输等过程中可能存在的患者隐私信息泄露问题,在充分考虑数据的安全性和数据的可用性的条件下,提出了一种基于聚类的数据匿名化方法,通过构建泛化树,并将原始数据聚类成等价类,在保证数据可用性的同时,最大力度地保护了患者的隐私信息。通过实验验证了本文提出方法的正确性和可行性,在后续的研究中,将研究算法复杂度更低的方法,减小聚类所需时间,并进一步提高隐私保护效率。
