基于RoBERTa-BiLSTM-CRF的简历实体识别
2023-03-24刘慧敏熊菲王国庆
刘慧敏 熊菲 王国庆
关键词:简历实体识别;RoBERTa模型;词向量;BiLSTM-CRF模型
1 概述
在大数据时代,人才的竞争非常激烈,如何在海量的简历中快速地识别、发现与企业需求相符合的求职者成了一个亟待解决的问题。传统的方式是花费大量的人力物力从各大招聘平台的简历中进行人工筛选,该方法不仅实效性差,并且很容易出现招聘人员与岗位不匹配的后果。
为解决该问题,诸多学者也展开了相应研究,发现人才简历的分析与命名实体识别技术具有密不可分的关系。在CoNNL-2003会议[1]中,学者们对多种命名实体识别方法进行了评测,为命名实体识别的研究奠定了基础。2004年廖先桃等[2]使用隐形马尔可夫模型(Hidden Markov Model, HMM) 与自动规则提取相结合实现了中文命名实体提取技术。2009年彭春艳等[3]使用条件随机场CRF(Conditional Random Field) ,结合单词构词特性的距离依赖性,对生物命名实体进行了研究。2016年G Lample等人[4]将长短期记忆的循环神经网络LSTM(Long Short-Term Memory)在命名实体上的应用进行推广,首次提出了双向长短期记忆网络BiL?STM(Bidirectional Long Short-Term Memory) 和CRF结合的神经网络模型,表明该模型能够获取上下文的序列信息, 因此在命名实体识别中得到了广泛的应用。
但上述方法只关注了词或者词之间的特征提取,忽略了上下文的语义。为解决此问题,Devlin等人[5]引入了一种称为BERT (Bidirectional Encoder Repre?sentation from Transformers)的新模型对词向量进行表征,该模型借助Transformers结构可以得到上下文的语义信息。Liu Y等人[6]于2019年提出了RoBERTa(ARobustly Optimized BERT Pretraining Approach) 模型,RoBERTa在BERT模型的基础上增加了大量训练参数和训练数据,且在语言表征中使用了双字节编码,提高了词汇表征的准确度和执行效率。
受上述文献的启发,本文建立了基于RoBERTa-BiLSTM-CRF模型的中文实体识别方法,并将该方法应用于大数据人才简历分析中。具体做法是利用本文建立的RoBERTa-BiLSTM-CRF模型对脱敏后的求职简历进行测试。结果表明,本文建立的模型具有较强的识别效果。相关研究结果为企业更高效地招纳人才提供了一个广义的框架,同时对于中文命名实体识别技术的研究具有一定的指导意义和参考价值。
2 理论方法
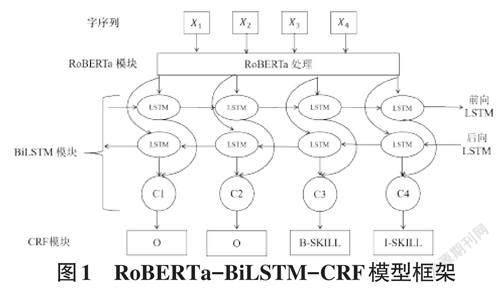
本文建立了RoBERTa-BiLSTM-CRF 模型,该模型是端到端的语言模型,能够较好地捕捉文本中存在的语法和语义特征,并且能够自动理解上下文的关联性。模型主要由三个模块构成,分别是RoBERTa模块、BiLSTM模块和CRF模块,各层的功能和原理如图1所示。
2.1 RoBERTa 模块
由于计算机只能识别数字、向量或者矩阵,故如何将文字向量化是诸多研究者关注的重点。文本向量化的研究先后经历了one-hot、Word2Vec、BERT。其中one-hot模型在字典比较大时,会出现维度灾难的问题。而Word2Vec 虽然可以学习词语之间的关系,但不能解决一词多义的问题。BERT模型虽具有较强的语义表征优势,但采用的是静态掩码,无法兼顾更多的语言信息。相较于BERT模型,RoBERTa采用了动态编码,且在特征编码阶段借助了双向Trans?former[7],通过该网络结构可以得到同一个句子中的词与词之间的关联程度调整权重系数矩阵,进而获取词的表征向量。与循环神经网络(Recurrent Neural Neu?ral Network,RNN) 相比,它可以更充分地利用上下文信息,能捕捉到更长距离的依赖关系。
RoBERTa预训练语言模型是BERT的一种变种。与经典的BERT模型相比,RoBERTa引入了更多的训练数据,增大了mini-batch的同时,去除了NSP任务,提升了优化速度和性能。RoBERTa模型采用了动态掩码,针对每一次输入序列都会动态生成新的掩码模式。模型会不断地适应不同的掩码策略,学习不同的语义表征。
2.2 BiLSTM 模块
LSTM是一种改进的RNN,LSTM模型有效地解决了RNN训练时产生的梯度爆炸或梯度消失问题,同时也实现了对长距离信息的有效利用[8]。与RNN的主要区别在于,它在算法中增加了一个“处理器”来判断信息是否有用,处理器的结构称为“门”。LSTM单元中有三个“门”,分别是遗忘门、输入门和输出门,以及记忆cell。其中输入门决定着是否有信息输入到记忆cell,输出门决定着是否有信息从记忆cell输出,遗忘门判断丢弃哪些信息。
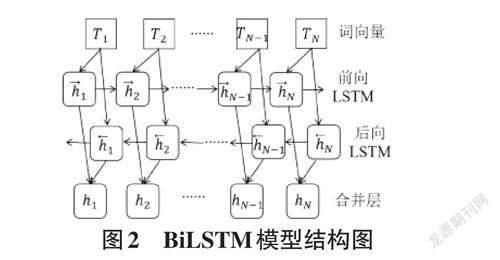
由于LSTM只能从前往后接收待识别的文本,而通过研究发现,下文信息也有很重要的参考价值。为了能够同时获得上下文信息,双向长短期记忆网络(BiLSTM) 就应运而生。BiLSTM由两个LSTM层组成,分别用来训练前向和后向的序列。这种结构可以将过去的信息和未来的信息同时在输出层进行综合输出。所以BiLSTM的最终输出既包括了过去的隐藏信息也包括了未来的隐藏信息,其结构如下:
2.3 CRF 模块
在命名实体识别任务中,由于BiLSTM模型无法处理相邻标签之间的依赖关系,而条件随机场(CRF)能通过相邻标签关系得到一个最优的预测序列[9]。为保证最终预测结果的可信度。需要在CRF层加入损失函数,区别于常规的损失函数计算方法,CRF损失的函数由实际路径的分数和所有路径的分数组成,而真实路径分数也应该是所有路径中分数最高的。假设每种可能的路徑分数为Pi,共有N 条路径,则总路径分数就是:
3实验结果与分析
3.1 数据来源及参数设置
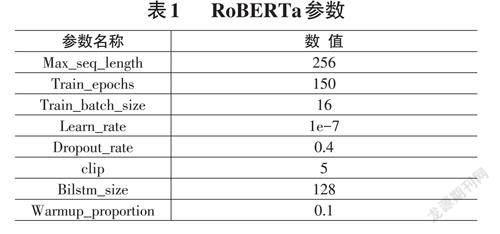
本文数据主要收集了求职简历952份,有601562个字作为语料库作为实验的数据集,进行应聘岗位、应聘公司、工作职位、工作单位、学历、专业等内容的识别。实验过程中把语料库随机分成训练集、测试集和评估集。本次实验采用的预训练语言模型为Ro?BERTa模型,具体模型训练参数如表1所示。
3.2 语料标注与评价指标
命名实体识别的语料标注有以下几种模式:BIO模式、BIEO模式、BIOES模式以及BMEO模式,本次工作采用的标注方式为BIO模式,其中B代表实体开始位置,I表示实体的非开始位置,O代表其他位置[10]。对简历中需要识别的命名实体进行标注,标注实体主要包括12个类别,实体名以及标注名称如表2所示:
在实际的命名实体预测过程中,实体预测正确的条件需要实体的边界以及实体的类型两个条件都正确才算是完成了一个有效的命名实体识别的任务。在本次工作中,对命名实体识别性能的判别采用了正确率P、召回率R 和F1 值作为命名实体的评价指标,具体定義如下:
式中,a 为识别出的正确的实体个数,A 为识别出的正确实体个数,B 为所有标注的实体个数。
3.3 实验结果与分析
本文所有的实验均在相同的语料、相同配置的环境下进行,最后得到如表3的实验结果:
通过表3可以看出,模型对姓名、应聘公司、应聘岗位、学历以及学校的识别结果是非常优异的,但对职称、技能方面的识别并不理想,具体是因为职称数据非常少,导致训练样本无法学习到其相应的信息,而技能识别结果不理想则是因为技能之间存在简写或者缩写,或者有指代歧义的现象,该部分问题也是后续研究的重点,训练过程中准确率和损失率如图3、图4所示:
从图3和图4可以看出,随着训练轮数的增加,整个模型的准确率在升高,而损失在下降的,证明模型对于简历的命名实体识别任务的效果一直在提升的。说明RoBERTa预训练模型可以很好地胜任该任务,且对字所表达出的多义性有较好的处理,对文本特征提取的性能也很好。
3.4 模型测试
本节对RoBERTa-BILSTM-CRF训练出的模型进行测试,选用隐去姓名、电话,邮箱、地址等信息的求职简历,进行简历命名实体识别的模型调用和测试,具体结果如表4所示:
从表4 可以看出,本文建立的RoBERTa-BiLSTM-CRF模型对简历的命名实体识别具有较好的鲁棒性,说明RoBERTa模型相比其他模型,其特征提取能力更强。
4 总结与展望
本文的工作虽然在一定程度上取得了一些成果,但仍存在进一步改善的空间。主要集中在以下几点:1) 没有充分利用到领域专业的知识,不能对实体的缩写进行很好地表征。下一步将会在实体的缩写以及实体消歧方面进行进一步研究。2) 本文的实验数据量虽然是特定的领域,但语料的规模并不是特别大,导致最终的数据结果不是太理想。并没有对模型的性能和多领域的应用场景进行探索,接下来将会在命名实体识别的构建方法以及泛化能力上进行研究。3) 并未考虑实体间的相关关系,以及实体间的内在逻辑,下一步将尝试将命名实体识别和知识图谱相结合。
