Incentive-Aware Blockchain-Assisted Intelligent Edge Caching and Computation Offloading for IoT
2023-03-22QinWngSigungChenMengWu
Qin Wng, Sigung Chen,*, Meng Wu
a Jiangsu Key Laborotary of Broadband Wireless Communication and Internet of Things, Nanjing University of Posts and Telecommunications, Nanjing 210003, China
b School of Internet of Things, Nanjing University of Posts and Telecommunications, Nanjing 210003, China
Keywords:Computation offloading Caching Incentive Blockchain Federated deep reinforcement learning
ABSTRACT The rapid development of artificial intelligence has pushed the Internet of Things(IoT)into a new stage.Facing with the explosive growth of data and the higher quality of service required by users, edge computing and caching are regarded as promising solutions.However, the resources in edge nodes(ENs)are not inexhaustible.In this paper, we propose an incentive-aware blockchain-assisted intelligent edge caching and computation offloading scheme for IoT, which is dedicated to providing a secure and intelligent solution for collaborative ENs in resource optimization and controls.Specifically, we jointly optimize offloading and caching decisions as well as computing and communication resources allocation to minimize the total cost for tasks completion in the EN.Furthermore, a blockchain incentive and contribution co-aware federated deep reinforcement learning algorithm is designed to solve this optimization problem.In this algorithm, we construct an incentive-aware blockchain-assisted collaboration mechanism which operates during local training, with the aim to strengthen the willingness of ENs to participate in collaboration with security guarantee.Meanwhile,a contribution-based federated aggregation method is developed,in which the aggregation weights of EN gradients are based on their contributions, thereby improving the training effect.Finally, compared with other baseline schemes, the numerical results prove that our scheme has an efficient optimization utility of resources with significant advantages in total cost reduction and caching performance.
1.Introduction
With the widespread popularity of the Internet of Things (IoT),our lives are undergoing a tremendous change,especially since the emergence of artificial intelligence (AI), which makes intelligence applications in an endless stream, such as smart transportation and smart healthcare.For instance, we can grasp all traffic conditions before trip and then choose a route with less traffic to the destination;we can also detect our physical states via smart wearable devices to achieve real-time monitoring of our health.These novel applications are being used by an increasing number of users and generate an enormous amount of data every day.According to Cisco statistics, approximately 2.5 exabytes (EB) of data is generated in one day [1].Generally, the caching and computing resources of these devices are extremely limited,and they transfer the data (executing code, etc.) to the resource-rich but remote cloud center for completing tasks, but this method cannot meet the users’ requirements for low delay and energy consumption.Edge computing effectively alleviates the above problems because the edge node (EN) is closer to users and equipped with much more resources than terminals.
Edge computing has become a promising computing paradigm in recent years,and how to efficiently utilize resources in the entire edge network is a hot topic[2].For example,by optimizing offloading decisions,Wu et al.[3]minimized the cost of energy and delay,which sufficiently enhances the service experience of users.In addition to computing resource,the EN is equipped with certain caching resources.Zhang et al.[4] considered caching some contents required for task computing in the EN to reduce the transmission time,which minimizes the delay of all computation tasks by jointly optimizing offloading decision,caching decision and resources allocation.In fact,there is usually more than one EN in the whole network, the resource usage and workload of each EN are different,these ENs can further improve resource utilization by collaborating with each other.For example,Zhang et al.[5]proposed a new idea from the perspective of edge-to-edge collaborative offloading,which utilizes edge-to-edge and cloud-edge collaborative computation offloading to complete AI-based computation tasks and achieves delay minimization and efficient utilization of resources.However,in realistic scenarios,each EN is selfish,and ENs with sufficient resources usually do not voluntarily provide their own resources for free.Zhao et al.[6] and Zeng et al.[7] designed incentive-based collaboration mechanisms for vehicle tasks offloading,which gives rental fees to adjacent vehicles or edge servers to encourage them to assist the requester in completing tasks.Finally,the optimal task allocation strategy is obtained to minimize the system cost.
In the above studies, the solving methods they designed are based on the principles of traditional mathematical programming,Lyapunov or genetic algorithms, which are either not suitable for dynamic and complex network environments or the solving process relies on complex and costly conditions.Deep reinforcement learning (DRL) is very popular due to its flexible autonomic learning ability,and it breaks through the limitation of traditional mathematical programming algorithms for problem solving.However,centralized training requires a strong computing capability that usually occurs in the cloud center,and it will also lead to frequent data transmissions[8].In addition,the node will inevitably be curious during collaboration,which brings about a risk of privacy leakage, especially for privacy-sensitive data such as diagnostic information of patients.As an emerging distributed learning method, federated learning (FL) provides a new perspective to overcome these problems.Instead of sharing the local original data, it only shares the gradient information to train the global model.Each agent (i.e., device or EN) utilizes local data for their own training,and then,they upload their gradients to the aggregation node, which is responsible for performing federated aggregation to update the global model.For example, Huang et al.[9]proposed a collaborative computation offloading scheme between small cell base stations based on federated DRL.By optimizing the offloading decision and interaction coordination, the minimum total energy consumption was obtained, which not only reduces the communication overhead in the training process but also protects the security of local training data in each small cell base station.In the research on edge computing for IoT, many good solutions for resource optimization are investigated,but the development of an intelligent, efficient, and secure resource optimization scheme still faces the following three challenges:
(1) Some of the current existing schemes have a simple optimization of resources and control factors.For example, they optimize offloading decision or caching decision with limited consideration of resources allocation;others have a more comprehensive consideration, but they are based on ideal scenarios.For example, the selected offloading nodes are always idle with no competitive relationship between them.Moreover, most of them assume that neighbor nodes voluntarily contribute their resources for free.
(2) Some schemes with collaboration considerations employ incentive mechanisms to strengthen the motivation of nodes to participate in collaboration.However, not all neighboring nodes are suitable as collaboration candidate nodes,that is,the collaborative nodes are not reasonably screened, thus reducing the quality of collaboration.In addition, the security of the collaboration is not guaranteed.
(3)Federated DRL-based algorithms in existing works are effective,but most of them employ simple average aggregation without accurately expressing the contribution of each agent to the system,and the training effect urgently needs to be improved.
Inspired by the above challenges, we propose a novel scheme,that is, an incentive-aware blockchain-assisted intelligent edge caching and computation offloading scheme for IoT, the specific contributions of which are as follows:
(1)With the aim of minimizing the total cost for completing all tasks in the EN,we jointly optimize the offloading decision,caching decision,computing resource allocation,and bandwidth allocation,in which the total cost includes delay, energy consumption, and collaboration costs.This approach achieves a comprehensive optimization of resources and control factors in the whole network and makes full use of collaboration between ENs to further improve resources utilization.Moreover, the pricing rule of collaboration cost based on task preference is more practical.
(2)Furthermore,we propose a blockchain incentive and contribution co-aware federated deep reinforcement learning (BICCFDRL)algorithm,with an incentive-aware blockchain-assisted collaboration mechanism developed for local training.This mechanism can encourage all ENs to actively participate in collaboration with security guarantee.In this mechanism, we design a novel incentive method with low communication cost,and all qualified candidate ENs compete to become the final collaborator to obtain benefits.
(3) Particularly, to express the contribution of each agent in an accurate and direct way during the federated aggregation of BICCFDRL, we present a contribution-based federated aggregation method.Through this method, the outstanding agents receive more attention.As a result, the training effect of the global model can be improved.
Finally, the experimental results verify that our proposed scheme has sufficient advantages in terms of caching performance,total cost reduction, and optimization utility.
The remainder of this article is organized as follows.Section 2 describes related works.The system model is constructed in Section 3, and the problem formulation is presented in Section 4.In Section 5,we design a BICC-FDRL algorithm.Subsequently,we present the performance evaluation in Section 6.Finally, conclusions are drawn in Section 7.
2.Related work
In recent years, edge computing for IoT has surged in popularity, and extensive works about its performance improvement via resource optimization have emerged.From the perspective of optimization variables (control and allocation of network resources),Refs.[10-15] minimized the cost of task completion.With joint optimization of offloading, computing and communication resources, Chen et al.[10] minimized the energy consumption of completing tasks by using a dynamic voltage scaling technique and alternating minimization algorithm.Similarly, Malik and Vu[11] integrated wireless charging and computation offloading to minimize the energy consumption of the system.In view of the limited caching resource in EN, Liu et al.[12] developed a popular data caching scheme in edge computing that can find the approximate maximum caching revenue of a service provider by optimizing the caching decision.From a more comprehensive perspective,Refs.[13-15] took full advantage of computation offloading and caching to improve system performance.To minimize the average energy consumption of all users, Chen and Zhou [13] proposed a scheme with optimal offloading and caching decisions by employing a dynamic programming-based algorithm.Bi et al.[14] and Zhang et al.[15] jointly optimized offloading, service caching,and allocation of computing and communication resources.To minimize the weighted sum of delay and energy consumption, Bi et al.[14]solved the optimization problem in two steps:First,they derived a closed expression with optimal resource allocation and then optimized offloading and caching decisions with an alternate minimization algorithm.For multiusers with a multitask mobile edge computing system,Zhang et al.[15]investigated an algorithm based on semidefinite relaxation and alternating optimization to minimize system cost.The above studies improve the efficiency of task completion by utilizing the computing and caching capabilities of the EN, but the capability of a single EN is limited.In addition,if each EN only provides services for its local users,it will lead to an imbalanced workload and waste of resources.
To fill the above gap, Refs.[16-19] leveraged collaboration between ENs to further improve the utilization rate of resources and balance the workload.Ma et al.[16] and Zhong et al.[17]aimed to minimize the completion time of tasks.Ma et al.[16]investigated collaborative service caching and computation offloading among ENs, which optimizes the caching decision and offloading ratio of the task by a Gibbs sampling-based iteration algorithm.This scheme can adapt well to the heterogeneity of ENs.The collaboration scheme proposed in Ref.[17] is similar to that in Ref.[16], with additional consideration of resource allocation,and a modified generalized Benders decomposition algorithm was proposed to solve the optimization problem.To minimize the total delay and energy consumption of all users, Feng et al.[18]studied the collaborative data caching and offloading of neighboring ENs that can share caching data and computing resource, thus improving quality of service for users.Unlike the previous conventional collaboration caching between ENs, Yuan et al.[19] focused on the optimal number of collaborative ENs and forwarding groups, and an improved alternating direction multiplier method was proposed that can obtain the maximum cache hit rate with the constraint of low collaboration cost.These studies improve the utilization rate of network resources, but they assume that the service providers volunteer to provide computing or caching services to the requester.In fact,they are less motivated to participate in the collaboration process without an incentive.
In light of the shortcomings in the above studies, incentive mechanisms were designed in Refs.[20-24] to improve the collaborative motivation of users, ENs or clouds, which allows participants to benefit from it.An incentive mechanism between the cloud service operator and edge server was developed in Ref.[20]; furthermore, the authors designed a computation offloading scheme by jointly optimizing the offloading decision of the cloud operator and the payment of the edge server, so that it can maximize their utilities and achieve Nash equilibrium.Hou et al.[21]presented an edge-end incentive-driven task allocation scheme to maximize the system utility.In terms of the profiles and importance of the task in the device,it could be offloaded to its local edge server, a neighboring edge server, or a device cluster within the coverage of the same local edge server.In Ref.[22], the authors made full use of the computing resources of idle edge gateways and mobile devices, which formed edge clouds.Specifically, a resource trading model between edge clouds and mobile devices was built, which aims to maximize the profits of edge clouds and meet the computing requirements of mobile devices by leveraging market-based pricing and auction theory.Luo et al.[23] designed an efficient incentive mechanism in a device-to-device (D2D) network.According to the coalitional game, it established multiple micro-computing clusters among devices to achieve collaborative task computing, which enables each device to benefit from assisting in computing or relay and effectively reduces the global cost of the system.Additionally, for a D2D network, Zhang et al.[24]investigated a collaborative cache based on a multi-winner auction, which can obtain the maximal content caching revenue of all users with the optimal offloading and payment strategies and guarantee the profit fairness of auction winners.These schemes arouse network motility by designing an incentive mechanism(i.e., the nodes in the network can actively interact and make full use of the resources).However,the solving methods they proposed are all based on traditional iterative mathematical programming or game theory, the prerequisite of which is strict to obtain the optimal solution, making it unsuitable for dynamic and complex network environments.In addition, collaboration between nodes is neglected.
To construct a security- and intelligence-enabled network for adapting to dynamic and complex network, a machine learningbased approach was introduced.In Refs.[25-29], they combined the autonomous learning ability of DRL and the secure distributed computing of FL, which can overcome the drawbacks of the above schemes.For example, Refs.[25-27] proposed a double deep Qnetwork based FL algorithm.Zarandi and Tabassum [25] regarded a device as the agent and performed federated aggregation at the EN, it achieves task completion cost minimization on the terminal side by jointly optimizing offloading decision and the allocation of computing and communication resources.Study in Ref.[26]is similar to Ref.[25], and it had more detailed research and analysis on DRL and FL.Moreover, it gave additional consideration to caching optimization.Ren et al.[27]designed a reward and penalty mechanism between ENs and devices (i.e., devices will pay rewards to the EN that provides computing service, but the EN will be punished for task computing failure).This mechanism achieves the minimization of device payment by optimizing offloading decision and the allocation of energy units.Although FL can protect data privacy by keeping data locally,agents are vulnerable to malicious attacks in the process of uploading gradients.To further enhance data privacy protection,Cui et al.[28]introduced blockchain technology into FL and designed four smart contracts for each agent to ensure the security of their data.In addition, they compressed the gradient information uploaded by agents to reduce the communication overhead of aggregation and finally obtain excellent performance on the cache hit rate and security by optimizing the caching decision.The incentive idea also exists in blockchain technology,and Yu et al.[29] mentioned in their future work that the utilization of incentive idea in blockchain for resource borrowing not only strengthens the security of participant interactions but also plays a role in efficient resource utilization.
Based on the analysis of the aforementioned studies,we can see that they have their own advantages and provide us with great inspiration.However, these schemes still have room for improvement in the efficient utilization of resources and solution effects.It is not only necessary to comprehensively optimize the resources and control in the entire edge network but also very important to provide a secure and intelligent collaboration scheme with coexistence of competition and collaboration, which will bring about a significant improvement to system performance.
3.Network model
With the rapid development of IoT and AI techniques, various intelligent applications have been developed extensively, such as vehicle routing optimization in smart transportation and health monitoring in smart healthcare.These applications have led to the explosive growth of data generated by sensors, and users appear to have more stringent requirements for service delay and privacy protection [30].Inspired by this, we design an incentive-aware blockchain-assisted intelligent edge computation offloading and caching model.As illustrated in Fig.1, this model includes three layers: the user layer, edge layer, and cloud layer.The coverage area of the entire network is divided into M subareas,and each subarea includes N users and one EN,therefore,there are M×N users in the user layer and M ENs with certain capabilities of caching and computing in the edge layer.
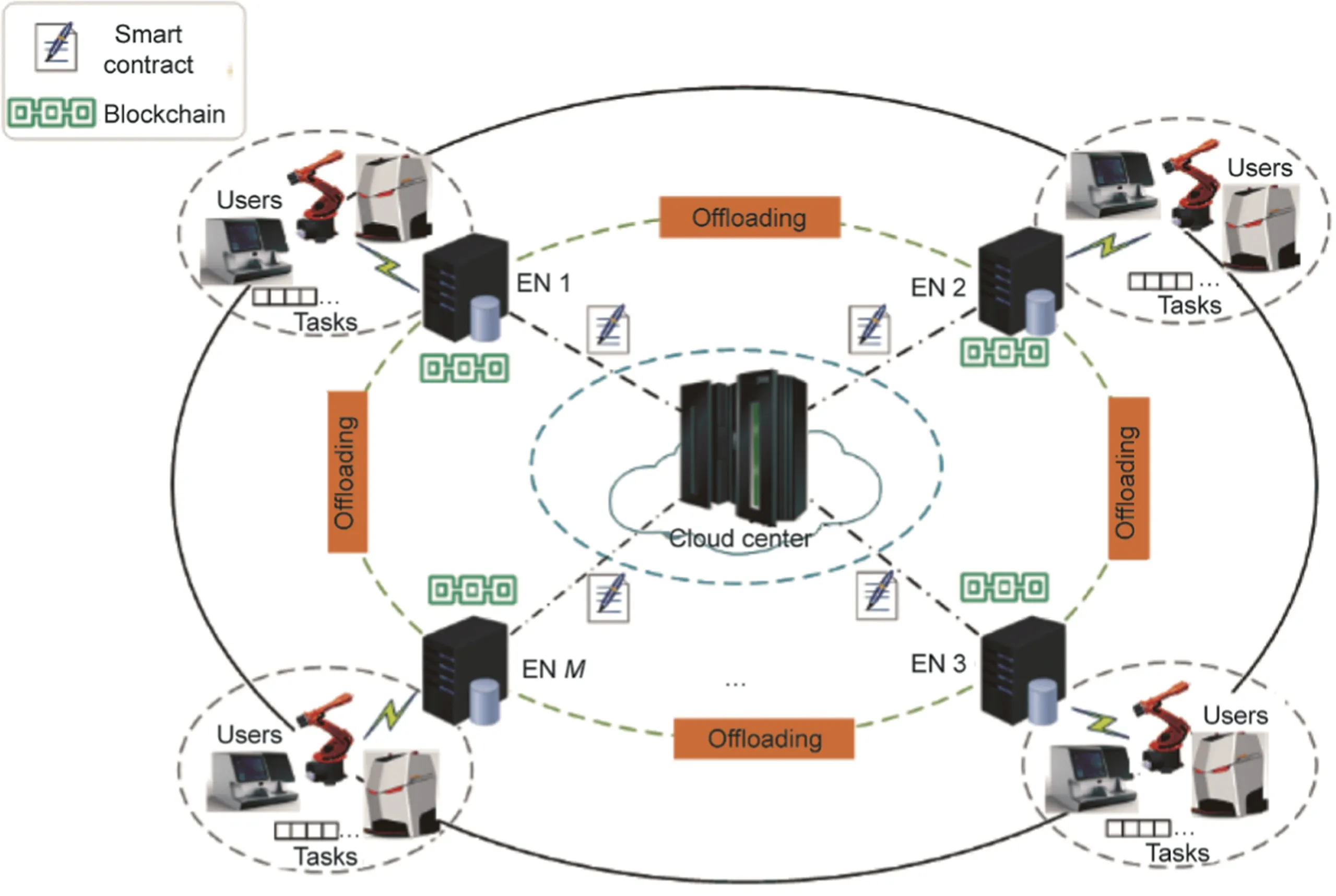
Fig.1.Incentive-aware blockchain-assisted intelligent edge computational offloading and caching model.M: the number of subareas.
When each user sends task requests to its local EN over the wireless link,the EN can either directly provide services to its local users or send requests for result sharing/computation offloading to the neighboring EN, because neighbors can collaborate with each other.Moreover, to improve their motivation to participate in a beneficial and secure manner, incentive-aware blockchainassisted collaboration is formed between ENs.In the process of their collaboration, the cloud center in the cloud layer will deploy the corresponding smart contract, which sets the trading rules for result sharing and computation offloading.The specific functions of each layer are defined as follows.
(1) User layer.Each user can generate one computation task at time slot t,and the same category task can be generated by multiple users.We denote that the task set generated by the whole user layer at a time slot t is Γ= 1,2,··· ,F{ }, that is, there are F categories of tasks.Due to the limited capabilities of users themselves,these tasks may be sent to their local ENs for efficient processing,so we define that the task set received by the EN m is Γm,m ∈M= 1,2,··· ,{M}, M is the set of ENs.
(2)Edge layer.The edge layer is composed of M ENs,which are equipped with servers that have certain caching and computing capabilities.Here, ENs are regarded as agents, and they can use information collected from local users for model training.As the capability of a single EN is limited,neighbors can assist each other in improving the efficiencies of task processing and resource utilization, and it is beneficial for ENs that apply an incentive-aware blockchain-assisted collaboration model to this process.Specifically,when the EN receives the service request from the local user layer,if the result has been cached,then it will be returned directly to the user (i.e., a cache hit).Otherwise, the EN will send the request to the cloud center to seek result sharing from neighboring ENs, as a result, it will obtain an address of a tradable EN.According to the smart contract,it will pay the corresponding result sharing payment to the neighbor EN after receiving the result.If the result of the task is not cached anywhere, then the EN will decide whether to process it locally or offload to a neighboring EN.If the task needs to be offloaded,then it is similar to the process of cache sharing (i.e., sending a request to the cloud center for offloading task to a neighboring EN).Eventually,the EN will obtain the result and return it to the user.After each EN trains its model with local data, it uploads its model parameters to the cloud center for aggregation.
(3) Cloud layer.The cloud center of the cloud layer has two main functions: ① It assists collaborations between ENs and deploys smart contracts for them,which can be executed automatically, and ②it aggregates the model parameters of each EN.Specifically, when an EN sends a request of result sharing or computation offloading, the cloud center will broadcast its request to the entire blockchain network after its identity is verified to be legitimate and return the address of a tradable neighbor to the requesting EN.At the same time,the corresponding smart contract(trading rules) is deployed for the transaction between them.In addition, the cloud center is responsible for aggregating the training model parameters collected from ENs and then forwarding the aggregated parameters to each EN,which aims to update the local models in ENs.
3.1.Caching model
To return results to users as soon as possible and relieve the computing pressure of the EN, caching some results in the EN is a good approach.Furthermore, caching the computation result rather than the task itself not only saves the caching space but also improves the privacy protection of the users’ original data.However, due to the limited caching space of the EN, it is impossible to cache all the computation results.Therefore,we consider results sharing between ENs to alleviate the above problem.Moreover, to improve the cache hit rate of results, they will be replaced regularly in ENs according to their popularities and preferences.The caching decision of task f is defined as, then it indicates caching the result of task f in EN m; otherwise,αfm=0.The detailed model of global popularity and EN preference for tasks are presented as follows.
In the beginning, the EN will cache computation results with high popularity in its cache pool in advance.The global popularity of tasks across the network follows the Mandelbrot Zipf distribution [31], which is defined as
where Pfis the global popularity of task f.Ofand Oirepresent the ranking of the results for tasks f and i in descending order of global popularity, respectively.τ is denoted as the plateau factor,σ is the skewness factor, and i is the ith category task in Γ.

3.2.Local model

3.3.Offloading model


4.Problem formulation

To ensure the quality and efficiency of service,the delay and energy consumption for completing task f should be constrained(i.e.,constraints Eq.(13a) and Eq.(13b)).Because the limited resources(caching,computing, and bandwidth) of the EN are shared by multiple tasks, we give constraints Eqs.(13c)-(13e) that the total network resources allocated to all tasks do not exceed the maximum value.From a practical view,constraint Eq.(13f)demonstrates that task f can only be offloaded to at most one neighbor EN, and constraint Eq.(13g) means that the caching state and offloading decision of task f cannot be 1 simultaneously.The constraint Eq.(13h)indicates that caching decision αfmand offloading decisionare both restricted to either 0 or 1.
Obviously, the above optimization problem is a mixed integer nonlinear optimization problem,and the variable dimension will be high when the network environment changes dynamically, and the number of users increases over time.As a result,it is difficult to solve directly by conventional methods, such as the gradient descent mathematical programming method and alternating direction method of multipliers.Recently,machine learning became a popular and vital artifice to solve this kind of resources allocation and decisions optimization problem in dynamic and time-varying networks, and it is viewed as an effective intelligent solving method.In view of the benefits of DRL and FL, which combines their characteristics of autonomic learning in complex and dynamic network environment, and the secure distributed computing, respectively,we will integrate these two machine learning ideas to solve the optimization problem Eq.(13).
5.BICC-FDRL
In this section,we propose a novel solving algorithm(i.e.,BICCFDRL algorithm, to achieve intelligent edge caching and computation offloading in the IoT).Inspired by the ideas of blockchain incentives,advantage actor-critic(A2C)and FL,the proposed algorithm mainly includes two parts: incentive-aware blockchainassisted local training and contribution-based federated aggregation, the detailed framework of which is depicted in Fig.2.
First, as an independent agent, each EN uses local information to train the local model by integrating the A2C concept.During the local training,an incentive-aware blockchain-assisted collaboration mechanism is developed to select appropriate collaborative neighbor EN,which will improve EN’s motivation for participation in a beneficial and secure manner.We assume that the total rounds of local training in EN m is Tm, after EN m completes Tmtraining rounds, all ENs will send their local model parameters and corresponding average cumulative rewards to the cloud center simultaneously, which are utilized for aggregation operation and global model update.The cloud center calculates the contribution ratio of each EN as the aggregation weight of their model parameters and then aggregates the parameters to obtain new global model parameters.Finally, global model parameters are forwarded to all ENs to update their respective models.The detailed design and explanation of the above scheme are given in the following parts.
5.1.Incentive-aware blockchain-assisted local training
In general, we regard the joint optimization problem in the EN as a Markov decision process.It simulates an agent (i.e., EN) performing an action in the environment according to the current state so that it can change the environment state and obtain a reward.The process includes three key elements, which are defined as follows:

In our scheme,each EN acts as a DRL agent and trains its model based on local information.Inspired by the A2C concept, the designed network architecture of the local model in Fig.2 consists of two subnetworks(i.e.,the actor network and the critic network).The actor network will select action according to the current state and then interact with the environment.Then, the environment will give reward rm(t ) and transfer to the next state.Particularly,reward rm(t ) is obtained according to action Am(t ) and A2C blockchain-assisted collaboration mechanism.The critic network is responsible for the action evaluation of actor network based on the current and next states.Unlike the traditional A2C design,our critic network uses the advantage function to evaluate actor performance instead of a simple value function.Because the evaluation of the action is not just based on how well it is but also depends on the environment improvement with the action.
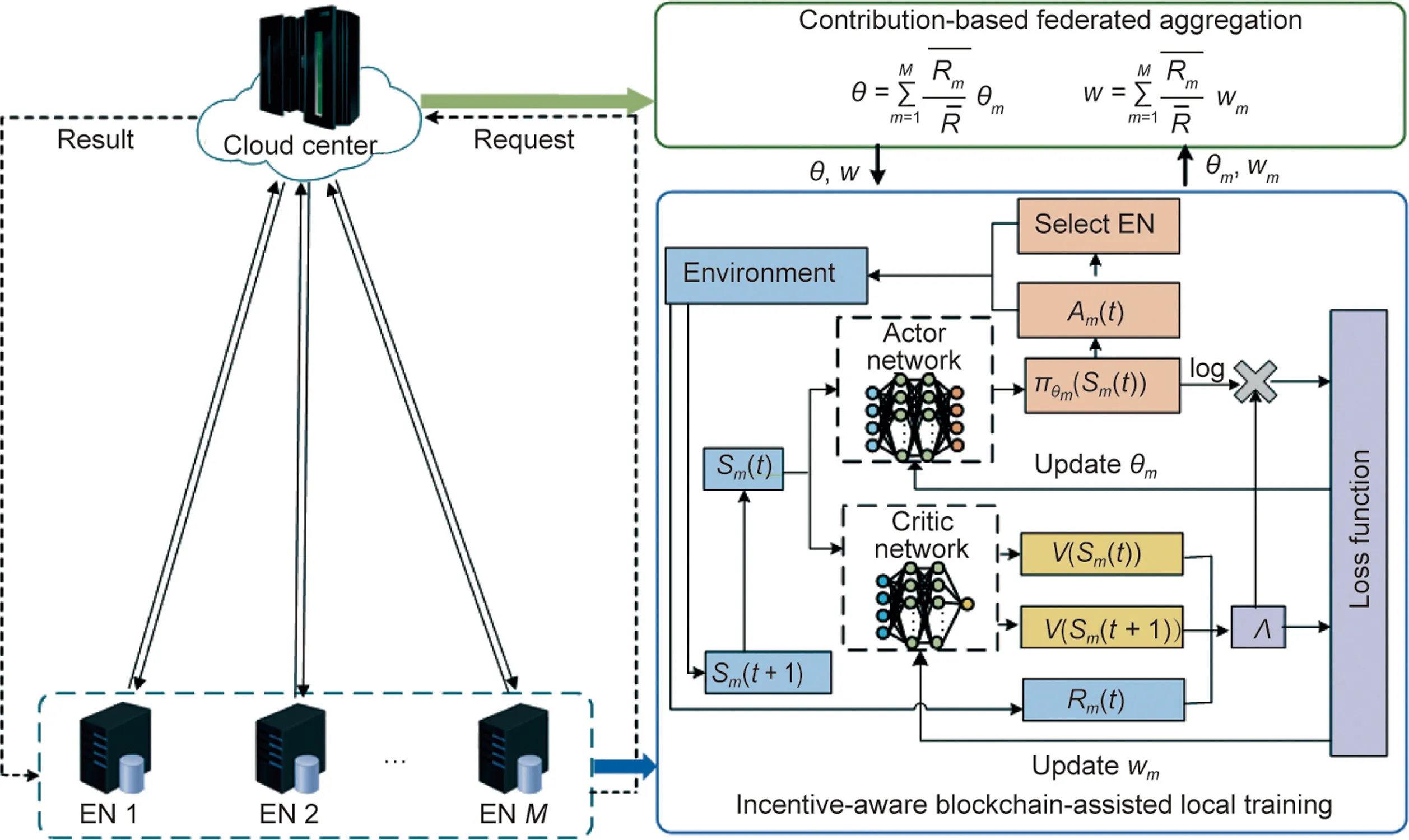
Fig.2.The framework of the BICC-FDRL.: the average cumulative reward of completing tasks in EN m;R: the sum of the average cumulative rewards of all edge nodes;θm:the parameter of actor network in EN m;wm:the parameter of critic network in EN m;θ:the parameter of actor network in the global model;w:the parameter of critic network in the global model; Sm (t ): the state space of EN m at time slot t; Sm (t+1): the state space of EN m at time slot t+1; Am (t ): action space of EN m at time slot t;πθm (Sm (t )):the policy generated by actor network;Rm (t ):the cumulative reward of EN m at time slot t;V (Sm (t )): the value function of the current state;V Sm (t+1)( ):the value function of the next state; Λ: the advantage function.
At time slot t, the actor network generates policy πθm(Sm(t ))based on the current state Sm(t )of local EN m.Because the outputs of the actor network are continuous values, the decisions of caching and offloading in Am(t ) are discrete variables.Therefore, we need to approximate the policy πθm(Sm(t )) so that the caching and offloading decisions in it are converted into discrete values,which are defined as
With the aim of inspiring each EN to participate in result sharing and computation offloading processes in a beneficial and secure manner,we develop an incentive-aware blockchain-assisted collaboration mechanism as described in Fig.3.This mechanism will select one neighbor EN that can provide service to local EN, and the value ofwill be determined.

(1) Result sharing.By encouraging each EN to cache its preferred task results, this incentive-aware blockchain-assisted collaboration can not only meet the local demand but also help other neighbors, thus improving cache utilization.
When the result is not cached in the local EN, the local EN will send a request of result sharing to the cloud center.The cloud center will broadcast its request across the whole blockchain network after verifying that its identity is legitimate so that it can know which neighboring ENs cache this result, that is,t( )=1,n ∈M{m}.These neighboring nodes will become candidates, which are sorted according to the preference of task f from low to high.

(2) Computation offloading.By encouraging the local EN to select the tradable neighboring EN with a similar preference or more sufficient computing resources for computation offloading,this incentive-aware blockchain-assisted collaboration will improve the task completion efficiency.

After the above process, reward rm(t ) is given by the environment, and the environment state transfers to the next state Sm(t+1).Next, we input the current state and the next state into the critic network, and their value functions V (Sm(t )) and V(Sm(t+1)) arethe outputs.Based on these, we can calculate advantagefunction Λ as
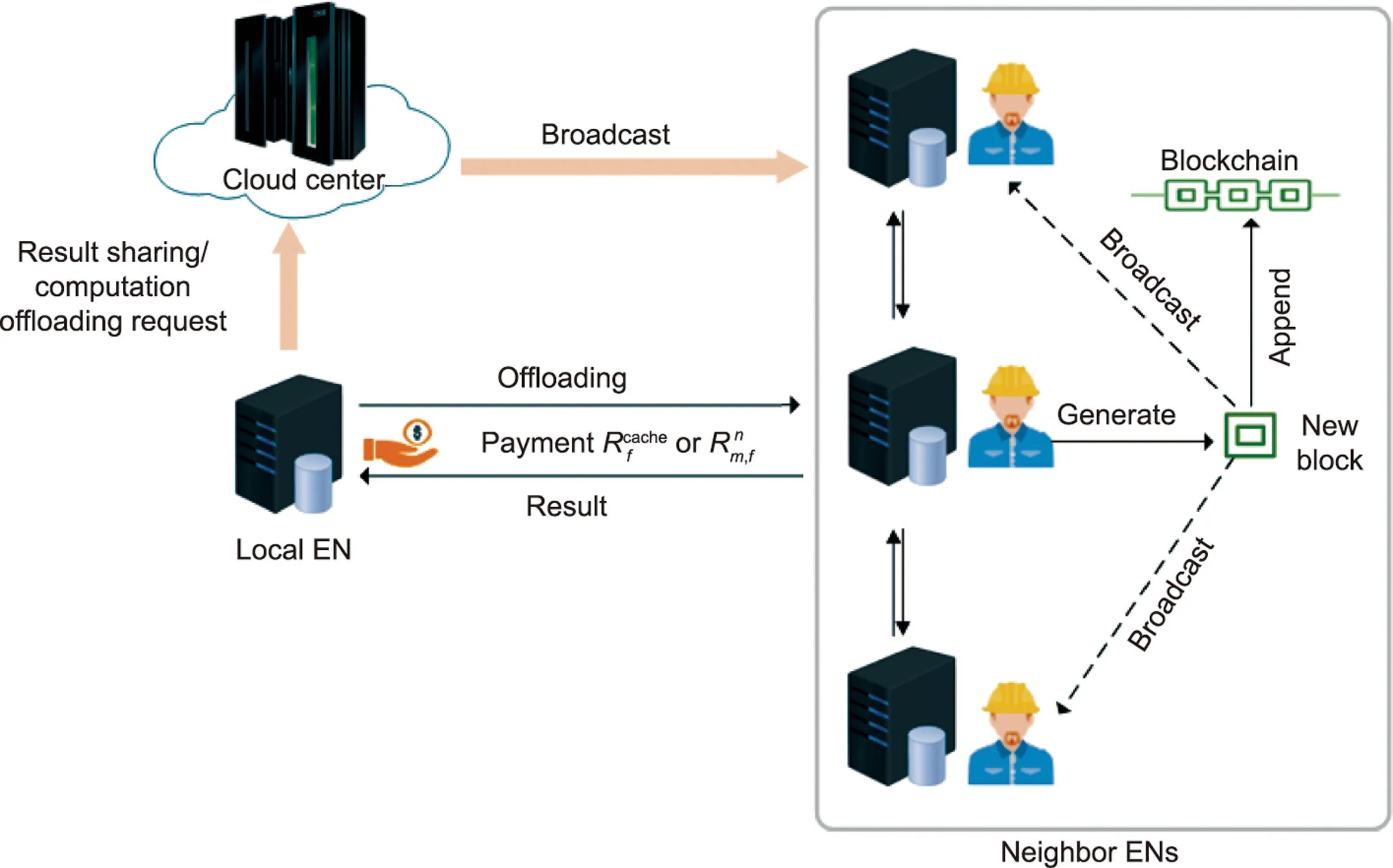
Fig.3.Incentive-aware blockchain-assisted collaboration mechanism.
where Q t( )represents the expected value function after performing action Am(t ) at the current state Sm(t ), and ρ is a discount factor.If Λ >0, then it means that performing action Am(t ) will bring a positive incentive to the system state.Moreover,the larger the Λ value is,the greater the improvement in the network.In addition,the utilization of the advantage function can reduce the variance in evaluation and accelerate the convergence rate.
During the training, we use the Adam optimizer to update the model parameters.The gradient of the policy loss function in the actor network is expressed as Λ∇θmlogπθm(Sm(t )),and the gradient of the value loss function in the critic network is expressed as Λ∇wmV (Sm(t ).Finally, the update processes of these two networks are described as
where η and μ are the learning rates of the actor network and critic network, respectively.
5.2.Contribution-based federated aggregation
An important step in FL is the aggregation of model parameters.That is,when each EN has been trained for several rounds,the ENs that participated in FL will upload their trained model parameters to the cloud center for aggregation simultaneously.
The most classic aggregation method is federated averaging(FedAvg) aggregation [32], proposed by Google, which adopts a simple average aggregation based on the training sample size of the EN.The model parameter aggregation operation of FedAvg is shown as follows:
where θ and w are parameters of the actor network and critic network in the global model,respectively.We assume that there are M ENs participating in FL and the sample size of agent m is Km.
Generally, sample size is used as the basis for aggregation because more training samples will introduce a better model training effect.However, it is not inevitable.To depict the model training effect of ENs more accurately, we consider utilizing a more direct method (i.e., cumulative reward Rm).A higher cumulative reward indicates that the network model parameters of EN are better, and a greater contribution will be made to the performance improvement of the future global model.

After the process of aggregation, the cloud center will forward the aggregation parameters of the global model to each EN for updating their local model.Each EN keeps learning until the model converges to the optimal strategy.
To provide a clearer understanding of the solution processing for the objective, we summarize it as Algorithm 1.

Algorithm 1.BICC-FDRL algorithm for edge caching and computation offloading.Input: the total rounds of local training Tm the total episodes of global training T the global popularity of tasks Pf the probability δf m of service request for task f Output: Minimum total cost with optimal Am*Initialization: θm =θ, wm =w For episode l=1 to T do For each EN m ∈M do For t =1 to Tm do Based on Sm (t ), perform Am (t );Select collaborate neighbor EN n based on Am t( ) and costf of incentive-aware blockchain-assisted collaboration mechanism;Obtain rm (t ) and transfer to next state Sm (t+1)Perform Sm (t )=Sm (t+1)Calculate Λ, the gradient of policy loss function Λ∇θm logπθm (Sm t( )) and the gradient of value loss function Λ∇wmV (Sm (t )Update θm and wm with Eqs.(24)and(25),respectively End for End for Perform contribution-based federated aggregation based on Eqs.(28) and (29)Forward global model parameters to each EN, that is,θm =θ, wm =w End for Obtain the minimum total cost with optimal Am*
6.Performance evaluation
In this section, we will evaluate the performance of the proposed scheme by conducting simulation experiments, which mainly consist of two parts: convergence analysis of the BICCFDRL algorithm in Section 6.1 and advantage analysis of the proposed scheme in Section 6.2.
To construct simulations, we set M =7 ENs and N =25 users within the communication coverage of each EN.For convenience,each EN has the same computing capability and caching size (i.e.,2·5 Gcycles·s-1and 6 Mb, respectively), and the bandwidth between ENs is uniformly set to 100 MHz.There are F =50 tasks generated by the whole user layer at time slot t, the range of the task size is [30,50] Mb, and the range of its result size is[3 00,500]Kb.Moreover,the plateau factor and the skewness factor of task popularity are set to τ=-0·95 and σ=0·50, respectively.Particularly, we configure that the ENs have different preferences and demands, this differentiated consideration can reflect the heterogeneity of ENs.
For each EN, its actor network and critic network are both three-layer fully connected neural networks, and the hidden layer with 64 units have a rectified linear unit (ReLU) activation function.In the output layer of the actor network, the offloading and caching decisions use softmax as their activation function, while others use a sigmoid activation function.In addition, we add a two-layer fully connected neural network as the shared input layer for the actor and critic networks,which is used to abstract complex system states.The computational complexity of DRL mainly depends on the structure and the parameter number of the neural network, which is measured by the requirement of floating-point operations (FLOPs).In this paper, all the neural networks in our algorithm requires 0·20 million FLOPs (MFLOPs) to process a state input.
6.1.Convergence analysis of BICC-FDRL algorithm
In Fig.4, we study the convergence of cumulative reward for different learning rates of the actor network.It can be seen from the figure that the convergence speed of the curve with η=10-5is obviously lower than that of the other two curves with a higher learning rate.Although the cumulative reward with η=10-4converges slower than that when η=10-3,the former is slightly more stable, and their final convergence values are extremely close.Actually, after many experiments, we find that the rapid learning rate will become trapped in the local optimal solution and the slow learning rate will not converge to the optimal solution in a finite time.Therefore, in the following experiments, we set the learning rate of the actor network to 10-4.
The influence of different network learning rates on the convergence of loss is shown in Fig.5.The loss function value can reflect the training effect and stability of the model.As the model is trained increasingly better,the loss decreases and eventually stabilizes to a small value (the ideal loss is 0).When μ=0·050 and μ=0·010, their loss convergence performance is obviously better than that when μ=0·001.Similar to the above analysis, a higher learning rate has better convergence performance in a certain range.Finally, we set μ=0·050 after many experiments.
The convergence of loss for different aggregation methods is depicted in Fig.6.From the curves of the two aggregation methods,the loss of our proposed contribution-based federated aggregation is lower than that of FedAvg, which proves that our aggregation method has a better model training effect.Because in our aggregation method,the EN with a good learning effect has great reference value,it contributes more to the system and therefore has a greater aggregation weight, which improves the global training effect in the future and makes the policy more accurate.
The training effect with different numbers of aggregated ENs is depicted in Fig.7,that is,the number of ENs participating in federated aggregation is 3,5,and 7.The model with seven participating ENs has the highest cumulative reward.Furthermore, the oscillation amplitude of the three curves proves that more ENs participating in FL will make the model training more stable.As the number of ENs increases, the global model learns more information in the whole network (i.e., when more training samples are available,the training works better).However, if too many ENs participate in federated aggregation and upload their model parameters to the cloud center, then a communication burden will occur.Through more experiments, we find that the model convergence performance does not change significantly when the number of ENs reaches a certain value.In our network scenario, we set M =7 ENs.

Fig.4.The reward convergence of the actor network with different learning rates.
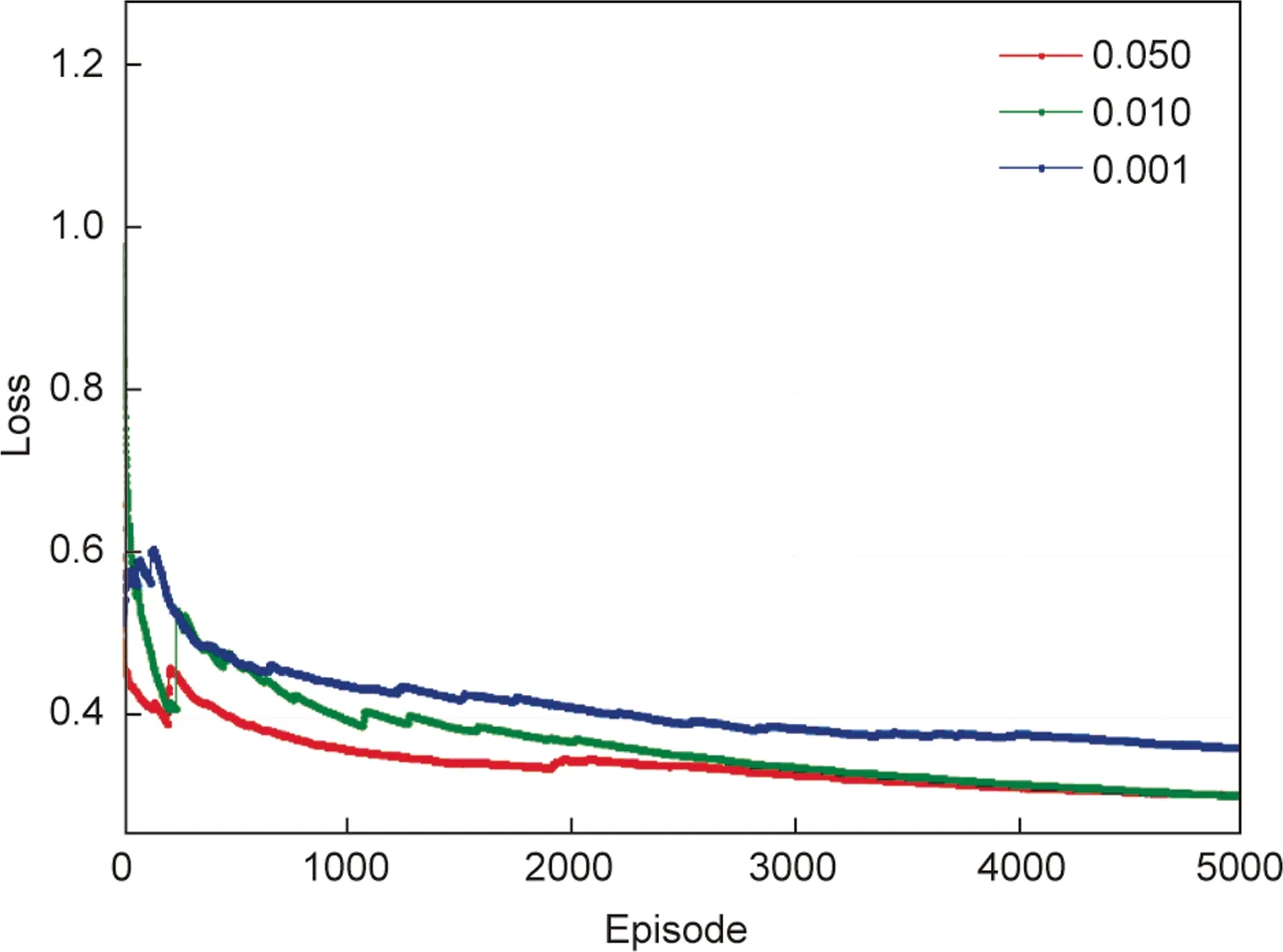
Fig.5.The loss convergence of the critic network with different learning rates.
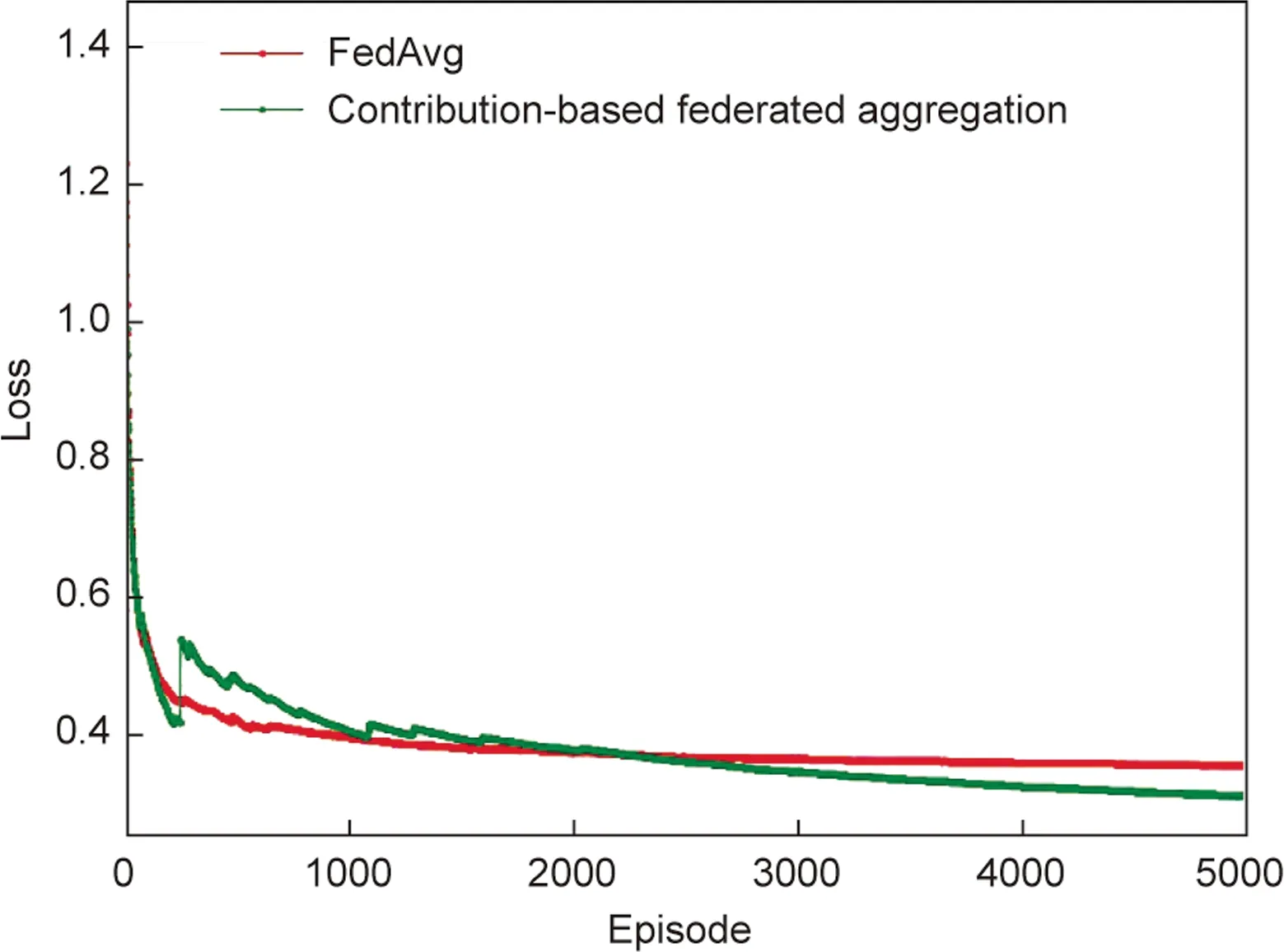
Fig.6.The loss convergence of different aggregation methods.
6.2.Advantage analysis of the proposed scheme
We will analyze the cache performance advantage of our proposed scheme by comparing it with the other three caching schemes, that is, least recently used (LRU), LRU-2, and least frequently used (LFU).
As the hit rate and the total cost are the key evaluation metrics to show the performance of caching schemes, the following simulations will analyze the cache performance of the four schemes from these two aspects.The definition of hit rate H is as follows:

Fig.8 shows the hit rate of different caching schemes with varying EN cache sizes.As the cache size increases,EN can cache more results,so the hit rate of the four schemes increases gradually.The hit rates ranked from high to low are our proposed scheme,LRU-2,LFU,and LRU.The hit rate of LRU is the lowest,which is mainly due to the popular results being replaced by the accidental unpopular results.The third-ranked LFU caches the result with high request frequency, which indicates a high preference, but it takes a long time to learn well.The second-ranked LRU-2 combines the advantages of LRU and first in first out, but it still cannot cache popular results accurately.Our proposed scheme has the highest hit rate because of its ability to cache results based on result popularity and the preferences of different EN regions.Moreover, the incentive-aware blockchain-assisted collaboration mechanism is designed in our scheme, which motivates the willingness of ENs to share results and then improves the hit rate.
Fig.9 describes the total cost of different caching schemes with the cache size of EN varying from 1 to 6 Mb.Corresponding to Fig.8,the larger the cache size of the EN is,the higher the hit rate,which saves the cost of completing the task.Therefore, the total cost of the four schemes shows a decreasing trend, and our proposed scheme is the lowest compared with others.In addition,when the cache size reaches a certain value, the hit rate reaches convergence, so the total cost will be stabilized.
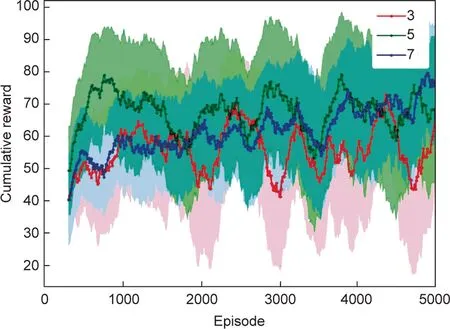
Fig.7.The training effect with different numbers of aggregated ENs.
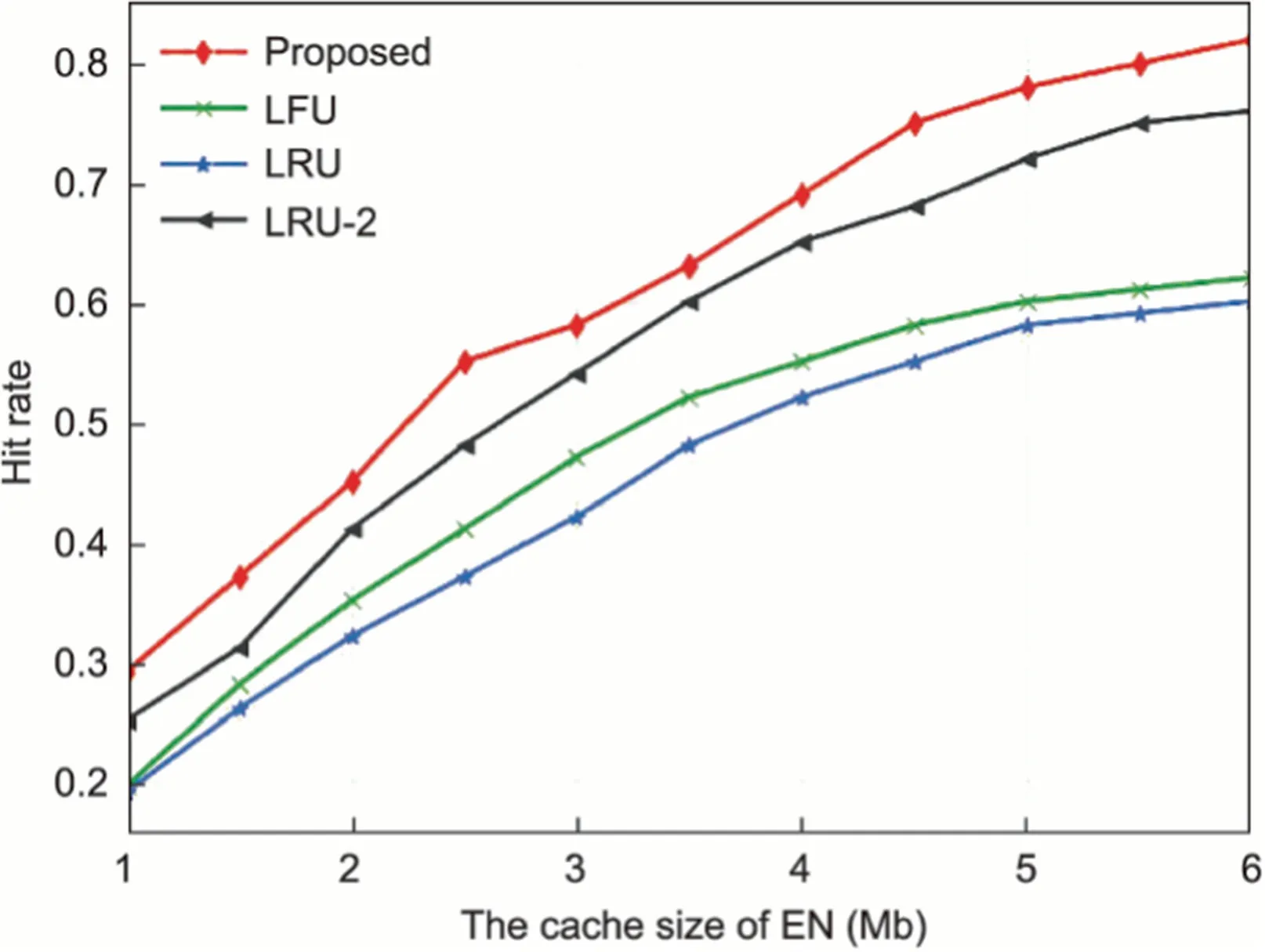
Fig.8.Hit rate of different caching schemes.
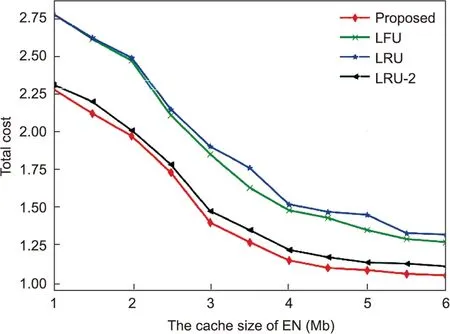
Fig.9.Total cost of different caching schemes.
According to the above simulations,we know that our proposed scheme has a better caching performance, which brings about a significant advantage to the total cost reduction.optimization.This finding occurs because our proposed scheme gives a more comprehensive consideration of optimization factors(i.e., joint optimization of offloading decision, caching decision,computing and communication resources allocation).Moreover,we design an incentive-aware blockchain-assisted mechanism that promotes collaboration between ENs and reduces collaboration costs.
From a more intuitive perspective,we will use the optimization utility to analyze the advantage of our proposed scheme, and the optimization utilities of the four schemes are defined as follows:

To analyze the advantage of our proposed scheme from a broader perspective, we compare it with three baseline schemes(i.e., federated deep reinforcement learning-based cooperative edge caching(FADE)[33],efficient and flexible management:a federated deep Q network approach(EFMFDQN)[34],and centralized A2C).In FADE,it adopts a popularity-based caching method similar to ours, but does not consider offloading decisions and other resource optimizations.EFMFDQN jointly optimizes the offloading decisions, bandwidth allocation ratio and transmit power by a deep Q-network based FL algorithm.It should be noted that centralized A2C is the optimal baseline scheme with minimum total cost under the ideal condition.Specifically, it regards the cloud center as an agent, which collects the information of the whole network to train the model centrally, and deploys the A2C algorithm to optimize the total reward.
For the above four schemes, their total costs under different numbers of tasks are compared in Fig.10.The performance of our scheme is close to that of centralized A2C and outperforms the other two schemes.Specifically, when there are few tasks,the caching resources of all ENs are sufficient to cache the results of these tasks without local or offloading computation.Therefore,the total cost of the other three schemes is lower than EFMFDQN,which does not consider cache optimization.With the increasing number of tasks, the advantages of our scheme become increasingly obvious.Since the caching space of EN is finite,the total cost of FADE is the highest, which only considers the caching decision
From Fig.11, we can observe that when the number of ENs increases, the optimization utility will increase.Obviously, the number of ENs increases implies that there are more caching and computing resources in the network,which enhances collaboration between ENs and then improves resource utilization.Moreover,as the number of ENs increases, the number of ENs participating in federated aggregation also increases, similar to Fig.7, the training effect will be improved.When there are nine ENs in the network,the utility of our scheme is almost equal to centralized A2C and significantly better than that of the other two schemes.This simulation reveals that our scheme efficiently utilizes caching,communication and computing resources.
It is worth noting that, despite the centralize A2C has optimal result in Figs.10 and 11, our scheme is still meaningful.Specifically,in our scheme,A2C algorithm is combined with FL,it can sink the training to the ENs,which alleviates the computing pressure of the cloud center and communication pressure.Meanwhile, owing to the training mode of FL, the model update only transmits the model parameters instead of the training data,which has the effect of privacy protection.
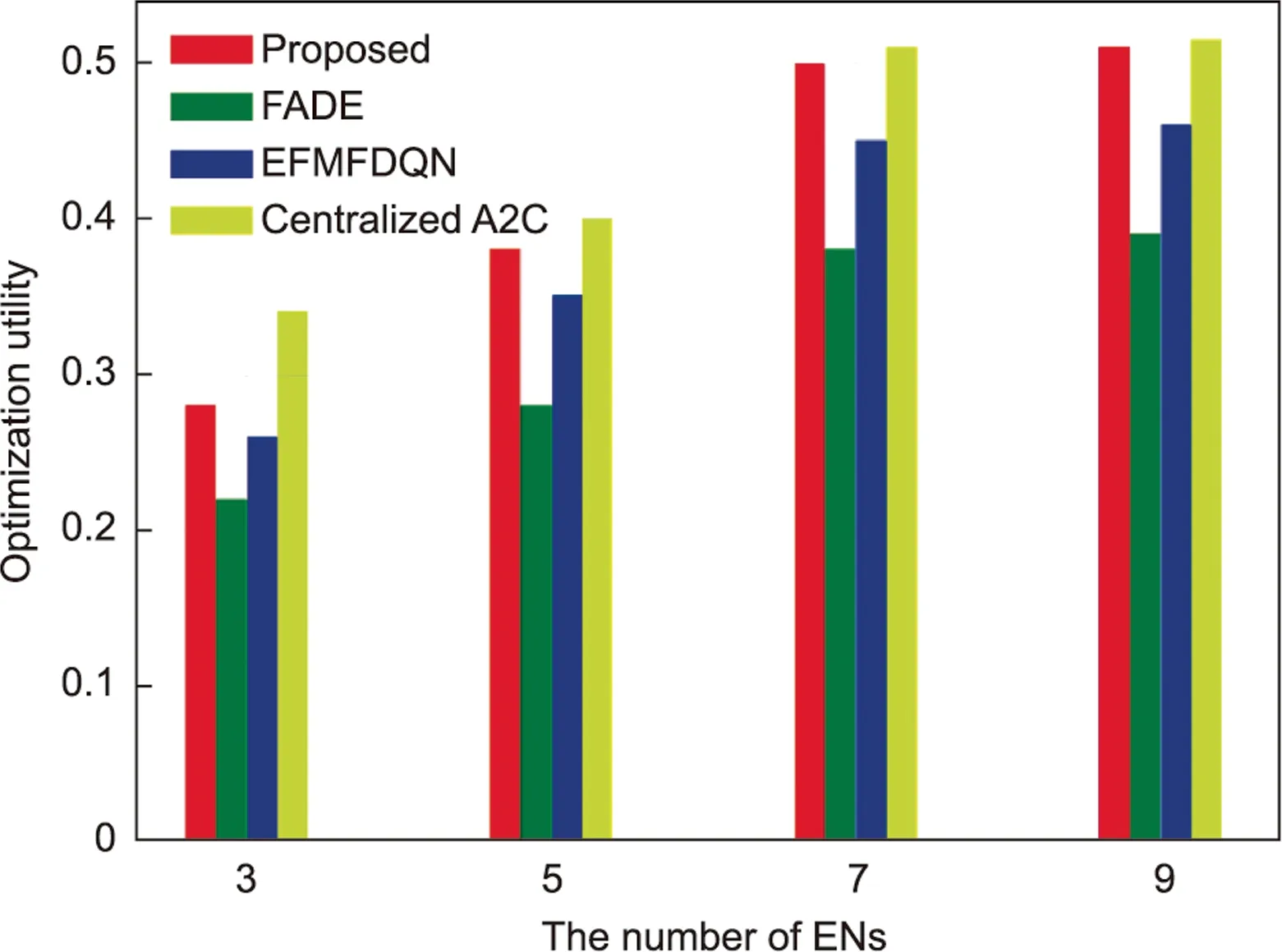
Fig.11.The optimization utility of different schemes under different sizes of the network.
7.Conclusions
In this paper, we propose an incentive-aware blockchainassisted intelligent edge caching and computation offloading scheme for IoT.To minimize the total cost of completing tasks in EN, we provide a comprehensive optimization of offloading, caching, and resources allocation.Particularly, task preference-based pricing rules are conducive for cost saving.Furthermore, to obtain the optimal solution, we develop a BICC-FDRL algorithm.In this algorithm, incentive-aware blockchain-assisted local training provides a secure incentive mechanism for encouraging ENs to collaborate, that is, incentive-aware blockchain-assisted collaboration mechanism, all ENs participate in result sharing and computation offloading actively for benefit.Moreover, for improving the training effect, we design a contribution-based federated aggregation method by paying more attention to ENs with large contributions.The numerical results indicate that our proposed scheme has significant performance advantages in terms of hit rate, total cost and optimization utility compared with other baseline schemes,such as FADE and EFMFDQN.The BICC-FDRL algorithm developed in our work is suitable for the scenario that all ENs have homogeneous learning models.However, this FL method has limitations when ENs have heterogeneous learning models.In future work,we will investigate a more efficient personalized FL with heterogeneous models.
Acknowledgments
This work was partially supported by the National Natural Science Foundation of China (61971235), the China Postdoctoral Science Foundation (2018M630590), the Jiangsu Planned Projects for Postdoctoral Research Funds (2021K501C), the 333 High-level Talents Training Project of Jiangsu Province,the 1311 Talents Plan of Nanjing University of Posts and Telecommunications,and the Jiangsu Planned for Postgraduate Research Innovation (KYCX22_1017).
Compliance with ethics guidelines
Qian Wang,Siguang Chen,and Meng Wu declare that they have no conflict of interest or financial conflicts to disclose.
杂志排行

Engineering的其它文章
- Global Top Ten Engineering Achivements 2023
- 2023 Global Engineering Fronts
- Will Massive Appetite for Minerals Stall Clean Energy Transition?
- Optical Microscopy Advances Reach Sub-Nanometer Resolution
- International Correlation Research Program: Cross-Fault Measurement for Earthquake Prediction
- A Systematic Perspective on Communication Innovations Toward 6G