基于LDA主题模型与Apriori算法的旅游数据挖掘
2023-03-22叶程轶
涂 晨,李 鑫,叶程轶
(江西理工大学 信息工程学院,江西 赣州 341000)
0 引 言
随着近年来互联网和自媒体的繁荣,旅游业不断发展的同时也面临着诸多需求,特别是每年的旅游市场现状及未来规划因得不到有效游客信息而无法充分分析和改善。由于新冠疫情的原因,在线旅游(Online Travel Agency, OTA)和游客的用户生成内容(User Generated Content, UGC)数据成为了解旅游市场现状的重要信息来源。要使用OTA和UGC的数据内容对某一特定旅游目的地进行研究,数据挖掘及分析则成了必要手段。但在研究中发现,OTA和UGC数据极为分散和碎片化,尤其是对于旅游城市来说,OTA和UGC数据包括且不仅限于微信公众号文旅文章、酒店评论、景区评论以及游记攻略。对于如此碎片化的数据,如何从中提取出旅游产品及其热度和关联性,从而进行良好的数据分析,以此根据旅游产品热度及关联性对景区酒店等进行一系列分析规划,成为了“互联网+旅游”的一大难题。
高新波等人[1]提出的基于社会媒体的旅游数据挖掘与分析方法初步反映了上述问题。目前,不少相关学者对此现象进行了深入研究,提出了多种解决方法。例如,以改进朴素贝叶斯分类[2]、支持向量机[3]、逻辑回归、LSTM与CNN[4]、改 进 CNN 与 LSTM[5]、ERNIE-CNN[6]、Bootstrapping[7]、FMNN融合多神经网络[8]、改进TF-IDF和ABLCNN[9]等机器学习模型[10]以及基于向量空间模型[11]来解决文本分类问题;以基于情感词典、传统机器学习[12]、深度学习等方法来解决情感分析问题[13];闫婷婷等人[14]开展的中文情感分析研究则在中文信息处理领域综述了方法及不足;张昊旻等人[15]提出用权值算法来解决中文情感分析问题;唐慧丰等人[16]开展了基于监督学习的中文情感分类技术比较研究等;以基于Apriori算法[17]的关联规则挖掘技术[18]改进FP-growth算法[19]的模型来解决关联分析。同时,随着BERT模型在自然语言处理各领域的广泛应用,又激起了关于预训练模型的一系列研究,例如BERT-TECNN文本分类[20]。然而,由于该数据集类别失衡、无标注且质量参差不齐,其在各模型上的表现均得不到很好的效果,具体表现为精度极低、极早过拟合等情况。
为此,针对数据集类别失衡、无标注等根源情况,本文采用无监督学习的LDA主题模型中的主题分布进行文本相似度计算,以此对文本是否属于同一类别进行区分,便于游客获得指定分类信息的准确性;在解决提取产品问题中,采用TextRank关键词算法对其进行关键词提取;而在热度分析问题中,建立以产品评论为基准、文本情感分析为辅的多维度产品热度分析模型;同时采用关联分析算法(Apriori)的思想,借由产品在文本间所存在的频率,根据从指定数据中提取出的相关产品,对在总次数中产品出现次数与出现产品A且可能出现产品B的概率等进行加权求和计算关联度,说明旅游产品间的关系。
1 研究方法
本文主要运用基于LDA的文本分类模型、基于TextRank的关键词提取和中文情感分析的热度分析以及基于频率的产品关联度分析技术,具体思路总结如下。
1.1 LDA模型
LDA(Latent Dirichlet Allocation,隐含狄利克雷分布)[21]是一种主题模型,它可以将文档集中每篇文档的主题按照概率分布的形式给出[22]。LDA模型算法是一种无监督模型算法,旨在通过无监督的学习发现文档中隐含的主题信息,通过文档中词和词之间的共有特征来发现文档的主题结构。同时它也是一种经典的词袋模型,通过词袋把文档看作一个词频向量[23],词和词之间没有先后顺序之分。其含义通常是指,文档到主题服从多项式分布,主题到词服从多项式分布。
假设有D个文档,其中包含了K个主题,每个文档的主题分布各不相同,且主题分布是多项分布,满足Dirichlet分布,参数为α;每个主题的词分布也各不相同,词分布也是多项式分布,同样满足Dirichlet分布,参数为β。那么在语料库中,α和β是Dirichlet分布的参数,θ是关于文档D的主题分布,即一个K维的向量。对于第i篇文档Di,其主题分布为θi,词分布为γij。运用Gibbs采样得到所有词的主题,通过主题数得到每个主题的γij;再统计D中各个文档里词的主题数,从而得出每个文档的主题分布。
简化 Dirichlet公式:
计算文档主题条件分布:
其中:为参数;表示在第d个文档中第k个主题词所对应的多项式分布计数。
基于上述内容,联系实际数据集,本文采用LDA主题模型求解主题分布,再根据主题分布所转化的向量进行运算,得到主题相似度[24],由所求出的主题相似度进行文本分类。
1.2 情感分析
情感分析(sentiment analysis)是自动判定文本中观点持有者对某一话题所表现出的态度或情绪倾向性的过程、技术和方法。情感分析全称为文本情感分析,其主要归纳为3项主要任务:情感信息抽取、情感信息分类以及情感信息的检索与归纳[25]。
中文情感分析属于情感信息分类这一模块,即指在中文数据集上利用模型进行训练,在广大数据评论中将其分类并进行标注。常见任务如酒店评论为好评或差评。
在文本情感分析中,常见的情感分析大致有3类方法:基于情感词典的情感分析、基于传统机器学习的情感分析和基于深度学习的情感分析[13]。
对于中文情感分析来说,最简要的模型莫过于基于情感词典的情感分析。本文采用Cnsenti模块,导入情感词典,利用情感分析对产品数据评论进行好评、差评区分。简要步骤如图1所示。

图1 情感词典情感分析简要流程
进行情感分析以后,针对所得到的已经贴好标签的好评和差评数据,则可建立一个由产品评论总数、好评指标和差评指标决定的多维度热度分析模型,从而进行年份产品热度计算。
1.3 关联分析
关联分析(association analysis)是从大量数据中发现频繁项集间的关联和相关关系,常用于数据挖掘,从整体数据中挖掘潜在关联。
关联分析运用范围极广,例如常见的大数据推送、QQ中可能认识的人等,都可利用关联分析来实现;同理,在处理游记攻略过程中,也可以利用关联分析对指定城市中景区、酒店、餐饮等旅游相关产品的关联程度进行分析,进而为城市未来旅游产业提供有效建议。
较为典型的关联分析算法是Apriori算法。求产品关联度可以尝试基于该算法实现。Apriori算法旨在利用项集的支持度,由频繁项集生成关联规则,该算法基本步骤如图2所示。

图2 Apriori算法简要步骤
在Apriori算法中,把所有相互之间包含了关联规则的产品作为集合,然后从最小k项集开始筛选支持度,得到候补频繁k项集,再将其集合进行合并,再循环,直到得不到集合为止。
在本文中,采用关联分析算法,利用产品支持度、置信度以及提升度进行加权计算,得到最终关联度。
2 研究准备
2.1 数据预处理
通过观察数据发现,微信公众号文章数共6 296,且微信公众号正文与微信公众号标题分开,秉持数据完整的原则,将正文及其标题合并。文章内容包含奇异字符、电话号码等噪音数据,且停用词较多,会对分类模型产生影响。因此需要对所有文章进行去停用词以及中文分词处理,随后统一存放。同时发现景区评论中有少数噪音数据(景区地点未在该旅游城市)。针对此类噪声数据,应寻找方法将其去除,避免产生影响。采用百度POI对景区地点进行定位,去除噪声数据。
在进行关联分析时,所得到的数据过多过杂,有效项集少,候补频繁项集难以捕获,需要进行数据筛选。
2.2 数据清洗
根据上述所发现的噪声数据,针对各种不同情况,进行以下处理。
2.2.1 中文分词
中文分词是指将一个中文句子视作一个由汉字组成的序列,为方便计算机理解,故而将该序列按一定规则进行重新切分,再重新组成序列的过程。常用的中文分词工具有jieba、SnowNLP、NLPIR 等。
需要注意的是,如果仅仅是直接进行分词,则可能导致专有名词的切分错误,例如“放鸡岛”,则会被分成['放','鸡','岛']。因此,在分词时,一定要注意专有名词的导入,避免专有词的分词出错。
2.2.2 去停用词
在数据集中,存在大量常用语气助词、副词、介词等无意义词汇,为提高关键词密度,应该尽可能将停用词消去,减少其出现频率。在本文中,直接采用了几个常见的停用词放入列表进行消除,如图3所示。

图3 数据处理示例
2.2.3 POI景区定位
采用百度POI地点查询,利用Selenium模块的模拟浏览器访问,指定城市;然后进行景区搜索,返回指定地点的具体位置,根据其返回结果即可判定是否在该城市中。
2.2.4 频繁集项获取
将所得到的所有产品ID存入一个列表,产品ID与之对应的产品名称置入另一个列表。
设有文本总数为D,那么当前文本为Di,项集为Z,对其进行遍历,如果产品存在,则将其产品名称所对应的索引值在产品ID表中求出,放入新的列表。每遍历完一个文本Di,就会得到一个项集ZDi,该项集即可作为产品的候补频繁集。
假设有产品ID[1,2,3,4,5],与之对应的产品名称为[A,B,C,D,E]。文档D1=[A,D,G,H],文档D2=[A,B,C,F]。那么在文档D1中存在产品ID候补频繁集ZD1={1,4},文档D2中存在产品ID候补频繁集ZD2={1,2,3}。
3 建立研究模型
针对本研究背景,建立以三个分块模型为核心的研究模型,将所得到的OTA和UGC数据输入模型后,可根据不同需求,获取不同输出。具体模型示意图如图4所示。

图4 研究模型流程
3.1 主题分类模型
采用LDA主题模型进行文本分类,根据该任务中所涉及到的一些特征词直接建立LDA模型。该主题模型所涉及公式、词、文档以及主题关系为:
在此模块中,主要模型流程如图5所示。

图5 基于LDA主题模型的文本分类简要流程
先进行数据清洗后,建立主题模型并保存,再对每个文本进行主题分布的计算,将得到的文本主题分布以向量的形式进行内积等计算,得到文本相似度。若相似度大于0,则视作该文本与LDA模型中涉及到的主题相关,最后进行分类。
3.2 热度分析模型
采用多维度热度评价模型,针对评论数据进行产品的热度分析。本文基于TextRank算法提出一种运用Chinese Sentiment模块进行处理的热度分析模型。以公式(4)进行计算:
其中:Wi和Wj分别表示评论为好评、坏评时的权值;C为该产品评论数;S为产品评论最大值。也可以根据图6的流程,将公式转化为:

图6 热度分析模型简要流程
其中:CG、SG为好评数及其最大值;CB、SB为差评数及其最大值。
由此,本文建立了一个以总评论数、好评、差评为自变量的热度评价模型。
3.3 关联分析模型
在建立模型之前,介绍Apriori关联分析算法中的三个概念如下:
(1)支持度:是指某项集在数据集中出现的概率,以A、B项集为例,支持度表示A和B同时发生的概率,即:
(2)置信度:是指在某前提条件下,用关联规则推出结果的概率,项集A发生则项集B发生的概率,即:
(3)提升度:表示A、B同时发生的概率与只发生B的概率之比,它表示为关联规则中A与B的相关性,可表示为:
相关性根据提升度值可分为如下三种情况:正相关,Lift(A,B)>1;不相关(相互独立),Lift(A,B)=1;负相关,Lift(A,B)<1。因此,本文以下面的公式计算关联度:
4 结果分析
4.1 主题分类模型输出
对数据集中的文章采用LDA模型分类后,将计算出的文本相似度转化为指定标签,并以“.csv”的格式保存下来,如图7所示。
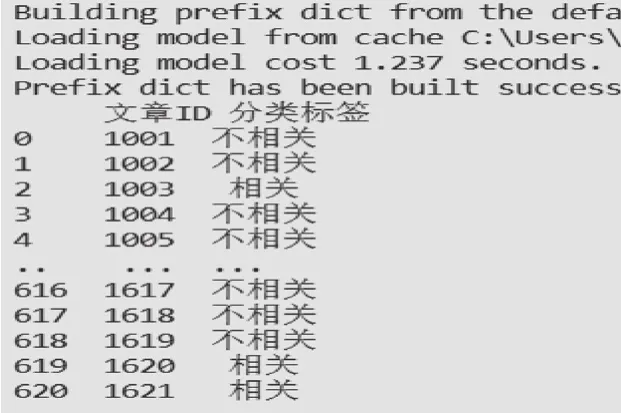
图7 主题分类模型输出结果
4.2 热度分析模型输出
将经过TextRank分词处理和热度分析处理后所得到的产品以及该产品在指定年份中的热度以“.csv”格式保留下来,如图8所示。

图8 热度分析模型输出结果
4.3 关联分析模型输出
将所相关的产品及关联度保存在csv文件中,根据所得到的csv文件,进行图谱可视化生成。本文采用networkx进行生成,以产品ID作为两个点,关联度作为其权值进行图谱可视化,得到该图谱。
4.4 模型结果分析
根据模型所得到的输出数据,得到了有效且清晰的文本分类标签,使其可以根据指定主题来获取更相关的文本集;对于热度分析模型所得到的数据,主要依据评论总数以及好差评指标来进行热度计算并排名,由此则可以依据该模型来获取产品热度排行榜,对热度低的文旅相关产品可以更有效地进行分析和整改;由关联分析模型可以更好地了解产品间所存在的关联性以及关联模式,从而给予更有效的文旅产品关联推送及市场关联分析。
5 结 语
本文基于LDA文本分类和热度分析方法以及产品关联度分析模型,将目前所遇到的困难拆解为建模和解决两个部分。在建模阶段,选取了最适宜数据集无标注的方法,创新地选用了LDA主题模型进行文本分类模型的构建,极大地避免了数据少、无标注等情况;考虑到需要在所给评论数据基础上对产品进行多维度的热度分析,采用了中文情感分析模型进行评论分类,从而作为指标进行评估;在求解关联度任务中,采用了基于Apriori算法的关联分析思想,从支持度、置信度、提升度的角度对产品之间的关联度进行评估。
在未来的工作中,将做出以下改进:
(1)迁移学习:采用迁移学习[26]的思想将所给训练数据集用相同高频词的训练集替代,使数据集有更好的分布特征,进而可采用自监督学习的神经网络进行处理。
(2)改进模型:在关联分析Apriori算法上进一步改进,尝试刘木林等人[27]提出的基于Hadoop的关联规则挖掘算法进行关联分析计算,继而提升数据分析的效果。
