基于改进DeepLabv3+的室外交通场景识别
2023-03-21王中华
李 阳,李 猛,王中华
(济南大学 自动化与电气工程学院,山东 济南 250024)
0 引言
随着人工智能时代的到来,智慧无人驾驶技术能够帮助我们释放双手、摆脱乏味,已然成了不可阻挡的时代潮流,而对交通道路场景的识别能力作为智能驾驶的基础与前提条件,其效果的可靠性、有效性起着举足轻重的作用。
基于深度学习的卷积神经网络(CNN)的应用使得计算机视觉得到了快速发展,其在交通道路场景识别中有着出色的表现。Pan Xingang等人认为卷积网络在利用图像中跨行列之间信息的能力不足,影响了车道线、路灯等目标的分割效果,基于此提出了SCNN网络,解决了传递特征图上的空间关系,在公开数据集上表现优秀[1]。针对交通场景中车辆行人等相互遮挡的情况,李轩等人提出了一种遮挡的回归损失函数Occlusion loss,搭配目标检测算法YOLO v3不仅可以提高目标检测的精度,还能够避免同一检测框内出现多个被检测目标,从而有效防止漏检,并且拥有更强的鲁棒性[2]。谭睿俊等人针对语义分割网络在提取特征时下采样池化操作会损害特征图分辨率的情况,为提升其在交通场景下的分割效果,构建了一种双层残差网络和跳跃特征融合网络相结合的语义分割模型,更加全面充分地学习图像特征,使网络达到了较高的提取特征能力和识别效果[3]。
作为当前图像语义分割领域中主流的具有编码-解码结构的网络模型,DeepLabv3+网络中引入了扩张卷积,可以获取更多的上下文信息,表现十分出色[4]。然而,在面对交通场景中一些小目标物体的分割时,分割效果不明显,且总体分割精度有待提高。针对上述问题,该文将基于DeepLabv3+网络进行改进,提升其精度及分割效果。
1 算法改进及相关内容介绍
1.1 总体框架
该文改进的DeepLabv3+的图像语义分割算法,主要是利用了结构重参数化方法和混合损失函数实现的。采用结构重参数化方法,用具有多分支结构的DBB模块重构模型中解码部分的网络结构[5]。在交叉熵作为损失函数的基础上,结合Dice损失函数组成混合损失函数,引导网络训练学习,弥补单个损失函数在数据出现不均衡时的不足问题,进一步提升网络的分割精度。
1.2 结构重参数化
多分支的结构相当于使网络增加了不同尺度的感受野,相较于单层递进式的网络结构拓宽了网络的宽度、增加了学习参数,有利于网络性能的提高,但网络的多分支化会不可避免地带来网络在使用时的大参数量以及内存消耗。2021年,Diverse Branch Block(DBB)模块被提出,图1为DBB模块示意图。其核心理念是通过多分支网络结构(包含卷积序列、多尺度卷积及平均池化)来丰富卷积块的特征空间,从而增强了单卷积的表示能力,为卷积神经网络带来更大的改善。通过结构重参数化思想,DBB模块还可以将复杂得多的分支结构等价转化为一个单分支结构,如此可以使得转化后的网络不仅拥有了在转换前的优良性能,而且结构简单。
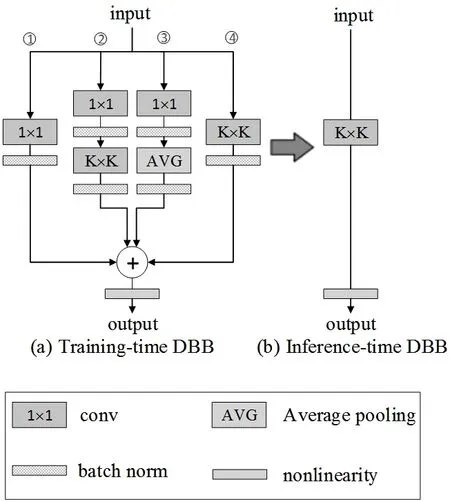
图1 Diverse Branch Block(DBB)示意图
要将复杂多分支结构转化为一个单分支结构,其融合过程需要涉及多个步骤,包括将BN层与卷积层的融合、不同尺寸的卷积融合等。
首先是BN层和卷积层的融合。已知卷积变化、BN操作分别如公式(1)(2):
则输入x经过卷积层和BN层的过程可以表示为:
式中,γ和β——BN层自身训练学习到的比例因子和偏置项;µB和σB——均值和方差。令
由(3)(4)可得:
式中,ωˆ和bˆ——经融合后的卷积核的权重与偏置。经过以上变换,就实现了将卷积层和BN层融合为一个单一卷积块的过程。
对于分支融合。由文献[6]可知,两个或多个配置相同的卷积是具有可加性,即可以先将不同的分支都转化为相同配置的卷积,再把它们利用可加性合并为一个卷积,这就是分支融合的原理。
如图1(a)所示,第①条支路中1×1卷积和BN层进行融合后,使用0进行填充至K×K大小;第②条支路中结构为1× 1Conv-BN-K×KConv-BN,先分别将1×1卷积与对应的BN层以及K×K卷积与对应的BN层进行融合,得到的结构为1× 1Conv-K×KConv。其次以F1∈RD×C×1×1作为1×1Conv的卷积核、F2∈RE×D×K×K作为K×KConv 的卷积核,它们的偏置分别为b1∈RD和b2∈RE。则输出O'是:
式中,I——输入,*——卷积运算。由于我们需要得到
由文献[7]可知,可以用转置后的F1对F2进行卷积得到F'、b1与F2相乘后与b2相加得到b',注意,对于需要进行0填充的K×KConv,方法是在模型训练时对第一个BN后的结果填充b1,至此将第②条支路转化成K×K大小的卷积。第③条支路中先将平均池化层等价转化为同样大小和步长的卷积,之后按照第②条支路的处理对该条支路转换为K×K大小的卷积;第④条支路中K×K卷积只和BN层融合。最后将转化后的四条支路进行分支融合,得到图1(b)所示的单一结构卷积块。
1.3 Dice Loss
在网络训练阶段,该文提出了一种混合损失函数,即将交叉熵损失与Dice损失相结合。Dice Loss[8]可以有效地应对数据中正负样本不平衡造成的分割效果不理想的场景,其计算公式如式(8)所示:
式中,pi——预测图中的像素点;gi——标签图中的像素点;pigi——二者交集。由式(8)中可以看到Dice Loss表示一种区域性代价函数,也就是说影响某像素点的训练损失及梯度值的原因不仅和该点的预测值及对应标签值有关,其他点的预测值及相应标签值也会做出干扰,即网络的所有输出都会影响该像素的梯度,这就避免了模型在背景像素数目大于目标像素数目的情况下严重偏向于背景而导致模型分割效果不好的情况,因此图像中的数据不均衡问题可以得到缓解。
2 实验与分析
2.1 实验环境及训练方法
该文的实验环境为深度学习框架为Pytorch1.10,处理器是Intel i9-10980XE,GPU为NVIDIA GeForce RTX 3080。该文使用迁移学习策略,将预训练模型Resnet101网络作为算法的初始化权重主干特征提取网络,以提升网络的泛化能力。训练分为两个阶段。阶段一为冻结主干特征提取网络阶段,学习率为0.007,批处理大小和epoch分别为8和50。阶段二是解冻主干网络阶段,学习率为0.000 07,批处理大小和epoch分别为4和50。采用SGD作为优化器,学习率衰减策略为余弦退火。
训练时,在网络解码结构用DBB模块替换部分卷积去训练,并且配合混合损失函数计算梯度信息进行反向传播训练网络模型。推理测试阶段利用结构重参数化方法,将DBB模块构转化成简单卷积。
2.2 实验数据集及评价指标
该文采用Cityscapes数据集[9]对所提算法进行试验和验证,由于官方并没有给出测试集对应的标签图,所以该文使用的数据集是训练集加验证集共3 475图片,并随机划分,取3 175张图片用于训练、348张图片用于验证及后续的测试。该文选择使用平均交并比(MIoU)和平均像素精度(MPA)为验证图像语义分割算法性能的评价指标。
2.3 实验结果与分析
该文对所改进算法进行了消融实验,模型语义分割结果如表1所示。
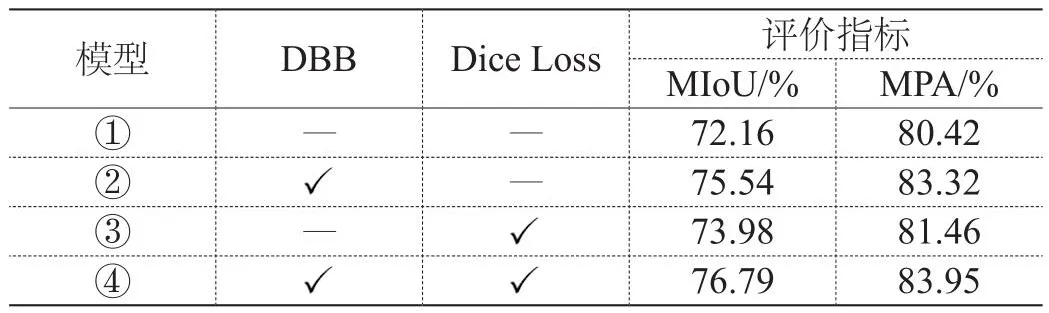
表1 各模型的图像语义分割结果评估
从表1中的结果对比可以看出,在原算法的基础上,仅在特征提取阶段利用DBB模块替换卷积结构或仅加入混合损失函数,都使得MIoU和MPA得到了有效提高;而在原有基础上同时DBB模块和混合损失函数,使得MIoU值提高了4.63个百分点、MPA提高了3.53个百分点。
使用模型①和④对Cityscapes数据集中的测试集进行语义分割,实验对比结果如图2所示。可以看出,在交通场景下进行场景识别时,原DeepLabv3+算法在分割成像占比较小的柱子、人等物体时明显存在分割不均衡、遗漏的现象,该文所改进的算法的分割效果更为明显。实验结果表明,所改进算法对于目标背景的边界分割能力有明显提升,细化目标边界,轮廓更加清晰,改善了数据不平衡分割不好的问题,并改善了语义分割效果。

图2 分割结果对比图
3 结论
针对交通场景下语义分割性能精度低以及对小目标物体分割效果较差的问题,该文提出了一种改进的DeepLabv3+网络的语义分割方法,首先利用结构重参数化方法,在训练阶段用DBB模块重构网络的解码架构,推理阶段再等价转化成一个简单卷积块,使模型在具有复杂多分支结构表现出来的良好分割性能的同时兼具单分支结构的简洁特征;其次,使用Dice损失函数和交叉熵损失函数结合的混合损失函数应用到算法中,可以有效地改善出现正负样本不平衡时分割效果不理想的情况。通过使用Cityscapes数据集进行的消融实验表明,所提算法相比原DeepLabv3+算法对图像的分割准确度有了很大的提升,拥有更好的效果。
