融合多种语言的语音情感识别
2023-03-20张可欣刘云翔
张可欣,刘云翔
(上海应用技术大学计算机科学与信息工程学院,上海 201418)
语音情感识别广泛应用于教育行业、服务行业、辅助驾驶行业以及刑事侦查行业。不仅国内人们对语音情感识别展开深入的研究,语音情感识别在国外也受到了重视[1-3]。1997 年,麻省理工大学的教授提出了“情感计算”的概念[4]。前人在语音特征值的选择与提取、去除冗余特征、语音情感数据库的选择以及构建分类器方面实现了很大的进展。然而,跨语言的语音情感识别准确率低,还有待于提高。语言的差异,会导致识别率较低。为了解决这一个问题,Zheng W L 提出的使用一种用于跨语料库多时话域自适应的多尺度差异对抗网络方法[4],文献[5]提出了基于域自适应最小二乘回归的跨语料库语音情感识别方法。和以上研究相比,该文的优点在于实现了语音—文本,文本—语音的相互转化。通过相互转化,可以起到灵活消除差异、提取关键词的作用,这样可以避免大量情感无关的信号降低识别效率。
1 相关研究
在语音情感识别方面,前人多数关注于提取语音特征、去除冗余特征、构建分类器这三个方面。对前人做过的语音情感识别的研究进行总结。语言情感的特征值包括基于谱的相关特征,韵律学特征以及音质特征。基于谱的特征可以正确地反映人们的声道变化,根据声谱变化,推断人们的情感。常见的谱特征有MFCC、LPC。梅尔频谱是根据人耳听觉产生的特征参数。MFCC 频谱的优点在于可以有效地降低高频率的噪声干扰[6-11]。韵律学特征描述了说话语音的声调、快慢、音高的变换。不同的情感状态下,这些状态有所不同。韵律学特征包括短时能量、基频、短时过零率、语速。当人们情绪高涨时,短时能量增大、语速加快;相反,当人们心情处于低谷期时,短时能量减小、语速减缓。短时过零率是指单位时间内,每一帧经过零值的次数,反映了语音信号的频率。通过观察说话者语音的声调、快慢及音高的变换,就可以对说话者的情绪进行判断。韵律学特征比频谱特征更加简单,无需提取频率波,但是缺点在于具有偶然性和主观性。音质特征的目的是判断语音的纯净度。当人们悲伤难以平复时,他们的音质中会出现喘息、哽咽。选取共振峰为音质特征,共振峰描述了不同情感下的声道共鸣差异,因此共振峰的位置会产生差异。文献[12]提出句级特征是以一句话为单位,特征不是等长的。帧级特征是把语音信号分为等长的部分。对于帧级特征的预测需要整合所有帧的结果,作为最后的预测结果。该文介绍了帧级特征和句级特征各自的优势。帧级特征的优点在于语音信号具有平稳性,缺点在于标签分配的合理性不足。文献[13]对CNN和BLSTM 进行了融合,该文提取了语谱图和语音特征。语谱图作为CNN的输入,语音特征作为BLSTM 的输入,最后将两者的结果进行融合,在IEMOCAP 数据库上准确率得到了提高。
2 自然语言处理
2.1 词法分析
在自然语言处理领域中,词是最小的部分,正确的分词是理解自然语言的重要步骤。常见的分词方法有基于规则的正向分词匹配法、逆向分词匹配法、双向最大匹配法,以及基于统计的统计分词法。在将语音转化为文本后,使用Jieba 工具进行分词处理。Jieba 工具融合了基于规则和基于统计的两种方法。Jieba 工具功能丰富,在进行分词的同时还可以进行词性的标注,为之后的句法分析和关键词的提取提供了良好的基础,还可以支持多种编程语言。Jieba 工具使用精确模式将句子精准分开,适合文本分析。使用全模式可以将句子中所有的词都扫描出来,速度非常快。使用搜索引擎模式可以对长词再次进行切分,提高了召回率。分词结束之后,再进行词性标注。词法分析过程如图1 所示。
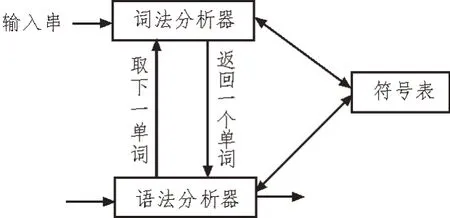
图1 词法分析过程
2.2 句法分析
句法分析的主要任务就是识别句子中包含的句法成分以及句子成分之间的关系。一般使用句法树表示句法分析的结果。句法分析的问题在于存在歧义和搜素空间巨大的局限性,因此需要设计良好的句法分析算法。该文使用基于最大间隔的马尔可夫网络的句法分析,它是支持向量机和马尔可夫网络的结合,共同吸取了两者的优点,能够处理复杂耗时的句法分析,也可以在消除歧义方面起着重要的作用。这是一种判别式的句法分析,其判别函数为:
式中,∅(x,y)表示与x相对应的句法树y的特征向量,w表示特征权重。句法分析过程如图2 所示。
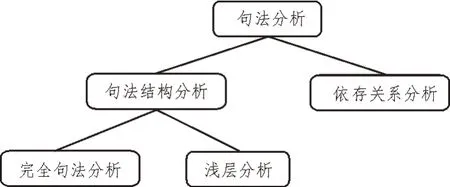
图2 句法分析过程
2.3 关键词的提取
词向量在文本情感分类中起着重要的作用。词向量是指把文本表达成方便语义理解的向量的形式,以向量的形式提取无标注文本中的有用信息。词向量的表达决定着文本情感分类的效果。该文使用向量化BOW 模型,核心思想是上下文相似的词语义也相似。为了提高文本情感识别的准确性,需要从文本中提取关键词。文中使用LSA 算法提取关键词,该算法以向量的形式进行特征值提取。首先把词向量拼成文档矩阵(m×n),其次,对文档矩阵进行奇异值分解([m×r]·[r×r]·[r×n]),最后,矩阵映射到更低维度k([m×k]·[k×k]·[k×n]),通过计算相似度,取相似度最高的作为关键词。
2.4 文本-语音的转换
使用名为pyttsx 的python 包可以把提取出的带有情感关键词的文本转化为语音。若没有pyttsx 包,要先安装,安装的代码为pip install pyttsx,然后就可以进行文本-语音的转化。转化好音频后提取它的MFCC 特征,在下面介绍的分类器中完成语音情感识别。
3 情感分类模型
3.1 DNN卷积神经网络
卷积神经网络模型如图3 所示。卷积神经网络的激活函数选取ReLu 函数,损失函数选取交叉熵损失函数,然后设置卷积层和池化层。特征图是通过对输入图像进行卷积计算和激活函数计算得到的。卷积过程就是用一个大小固定的卷积核按照一定步长扫描输入矩阵进行点积运算。卷积核是一个权重矩阵,特征图通过将卷积计算结果输入到激活函数内得到,特征值的深度等于当前层设定的卷积核个数。假设语谱图的长为M、宽为N,卷积核W的长为I、宽为J,偏置大小为b,激活函数为f,用卷积核提取语谱图的计算公式为:
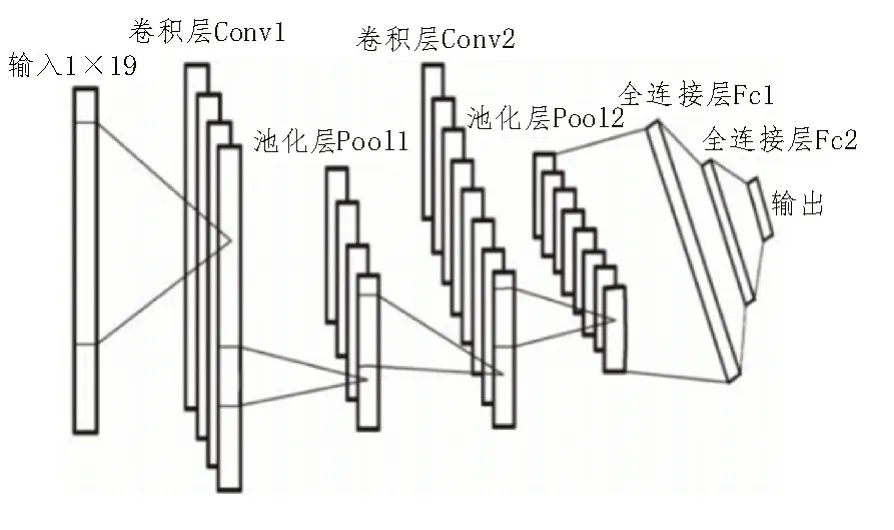
图3 卷积神经网络模型
式中,ym×n表示输出提取的语谱图的特征图。池化层在卷积层之后,池化操作将相似的特征合并起来,并选取区域的最大值和平均值,池化操作的作用是缩小特征图的尺寸,减少计算量。对于特征值多的图像,可以去除图像的冗余信息,提高图像处理效率,减少过拟合。该文的卷积神经网络是为了提取语谱图的特征值,使用两个卷积层、两个全连接层,经过softmax 激活层变化,得到预测结果。
3.2 BLSTM神经网络
有时信息既可以由前面的序列决定,也可以由后面的序列决定,因此引入了BLSTM 模型,用于实现信息的双向记忆。语音信号序列记为[x(1),x(2),…,x(T)],输出信号记为[r→(T),r←(T)],r→(T)代表正向特征输出,r←(T)代表反向特征输出。BLSTM 网络解决了RNN 不能实现双向记忆的问题。BLSTM 的循环神经网络结构图如图4 所示。
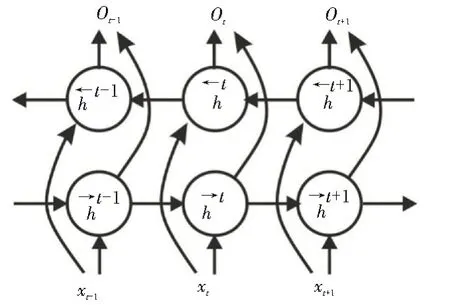
图4 BLSTM的循环神经网络结构图
4 实验设计
4.1 情感数据库的设计
该文选取Berlin 情感数据库和CASIA 汉语情感数据库做跨语言的语音情感识别实验。Berlin 情感数据库是由柏林工业大学录制的德语情感语音库,由10 位演员(5 男5 女)对10 个语句(5 长5 短)进行七种情感(中性、生气、害怕、高兴、悲伤、厌恶、无聊)的模拟,共包含800 句语料,采样率为48 kHz(后压缩到16 kHz),16 bit 量化。采用CASIA 汉语情感数据库对比验证识别效果。CASIA 情感数据库是由中科院录制的,环境信噪比为35 dB,2 男2 女录制50 句,包含高兴、中性、愤怒、悲伤、害怕、吃惊六种情感,采样频率为16 kHz,量化为16 bit。进行跨语言的情感数据库设计,从CASIA 汉语情感数据库和Berlin 情感数据库中分别挑选500 句,挑选的句子包含两个情感数据库共有的情感,有中性、生气、害怕、高兴、悲伤。数据库设计的具体信息如表1 所示。
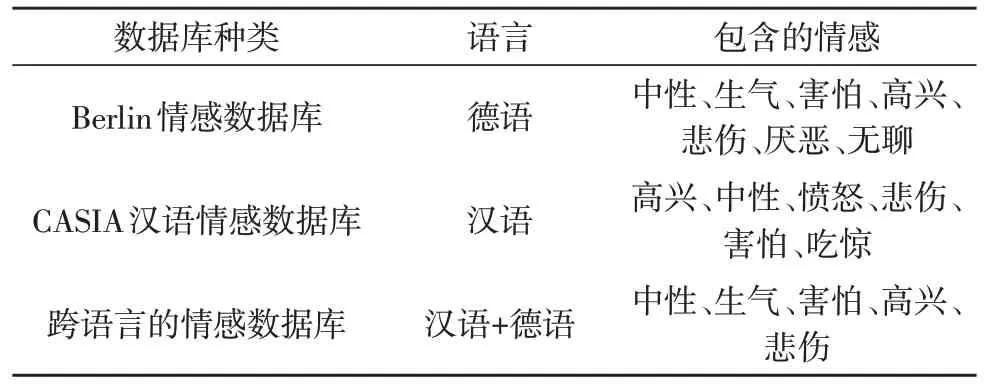
表1 数据库信息
4.2 详细实验步骤
实验运行环境选取pycharm 软件,用python 编程。首先,在python 中导入Google Speech,选用开源API 下的Google Speech,将两个情感数据库的语音转化成文本信息。然后将Berlin 情感数据库的语音转化为德语文本,使用百度进行翻译,将其翻译成汉语,实现了两者语言的统一。接着使用自然语言处理领域的技术,对两个数据库的文本进行词法分析、句法分析及LSA 算法提取情感键词。然后将提取到的情感关键词的文本使用pyttsx 的python 包提取出带有情感关键词的文本转化为语音。深度学习框架选取tensorflow 和kears,在python 中导入tensorflow 和kears 两个模块。该文的卷积层设置为三层,池化层设置为两层,全连接层设置两层。利用DNN 提取深层次的特征值,然后将DNN 的输出作为BLSTM 模型的输入,提取前向和后向的序列信息,将BLSTM 的输出作为最后的分类结果。
语言情感的特征值包括基于谱的相关特征、韵律学特征、音质特征及语谱图。这里频谱特征选取MFCC,将语音情感信号频谱的频率转换成梅尔刻度,再进行频谱的转化,就得到了梅尔频谱。梅尔频谱的计算公式如下:
MFCC 频谱的优点在于可以有效地降低高频率的噪声干扰,因此能够很好地描述语音情感。韵律学特征描述了说话语音的声调、快慢、音高的变换。在不同的情感状态下,这些特征有所不同。韵律特征选取短时能量、基频、短时过零率。然后再提取它们各自的统计学特征,包括最大值、最小值、均值及变化率。然而选取的特征值过多,容易造成维数灾难,导致过拟合,因此需要对特征值进行降维。该文选取Fisher 准则,提取对情感识别贡献度最大的特征值。Fisher 准则的思路:Fisher 准则根据均值和方差判断数据的优劣,Fisher 的计算公式为:
式中,μ1d、μ2d代表两个不同类别的d维向量的均值,和代表两个不同类别的d维向量的方差。Fisher 值越大,说明对情感分类的贡献度越高。因此,在语音情感分类的实验中,应该选取Fisher 值较大的特征。通过计算结果可知,MFCC 和语谱图征贡献度最大,因此提取它们作为这次情感分类识别的特征值。提取语音特征值时调用python 的librosa 包,用于提取语音特征值。
选取最佳的参数能够达到更好的分类效果,常见的参数选择方法是网格搜索法。用网格搜索的方法选取卷积神经网络的卷积层,池化层的卷积核大小、步长和深度、隐藏层卷积核大小的最佳参数。学习率设置为0.01,dropout 设置为0.5。经过网格搜索后,选取的最佳参数如表2 所示。
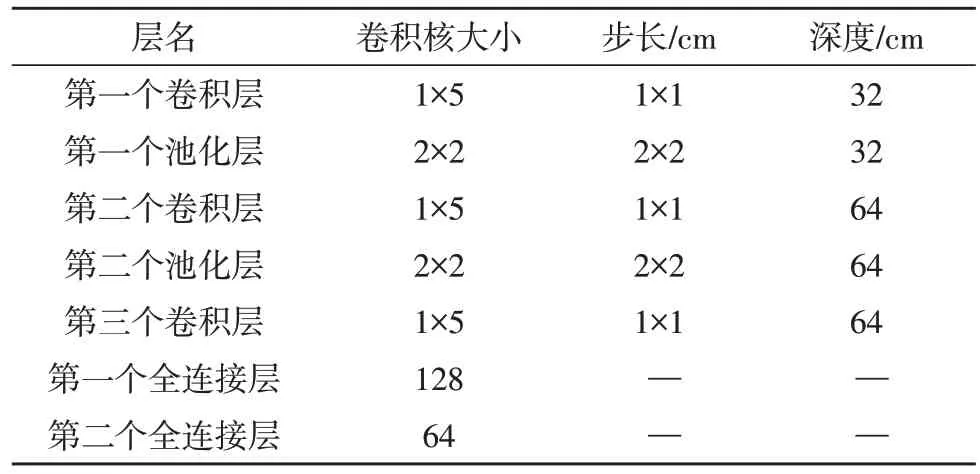
表2 神经网络的参数
4.3 实验结果
采用该文方法、使用一种用于跨语料库多时话域自适应的多尺度差异对抗网络方法和基于域自适应最小二乘回归的跨语料库语音情感识别方法进行对比实验。计算和对比非加权平均数(UAR)和加权平均数(WAR),实验结果表明,与一种用于跨语料库多时话域自适应的多尺度差异对抗网络方法和基于域自适应最小二乘回归的跨语料库语音情感识别方法相比,该文方法明显有所提升,分别提高了大约4%和8%。实验结果如表3 所示。
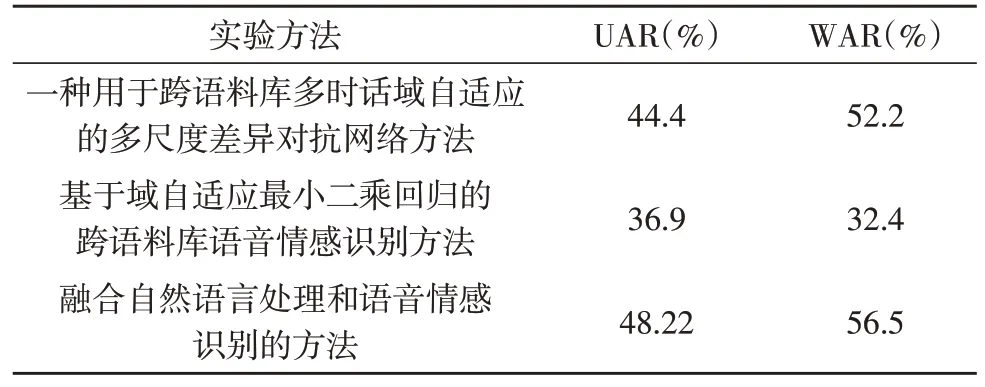
表3 实验结果
5 结束语
该文提出了跨不同语言的情感数据库的语音情感识别方法,解决了跨语言情感数据库语言的差异造成识别率低的问题。自然语言处理和语音情感识别是两个密不可分的领域,前人的研究很少把这两个领域相结合。该文交叉融合了自然语言处理和语音情感识别两个领域,实现了交叉领域知识的结合。首先,选取Berlin 语音情感数据库和CASIA 语音情感数据库,从两个数据库中分别挑选200 条语音;然后选用开源API 下的Google Speech,实现语音文本的转化,然后使用机器翻译,将其统一翻译成中文,利用自然语言处理的词法分析、句法分析、LSA的关键词提取算法,提取出表达情感的关键词,对提取出来的关键词再使用SpeechLib 工具包将提取过特征值的文本转化成语音,提取MFCC 特征;最后构建DNN+BLSTM 模型,实现语音情感的分类[15]。
使用语音—文本转化,文本—语音转化、词法分析、句法分析、关键词提取的方法是前人在语音情感识别中没有提到的创新之处。然而不足之处在于目前的语音情感识别领域还有以下方面需要进一步研究解决:使用的自然数据库较少,使用的情感数据库大都是经过训练的,具有不自然的缺点[16-17]。
