融合图卷积神经网络和BiGRU-TextCNN的罪名预测模型*
2023-03-18江操安德智马雪洁
江操 安德智 马雪洁
甘肃政法大学 甘肃 兰州 730000
引言
随着人工智能的发展和司法信息化体系的构建,将人工智能引入到司法领域成为近年来研究热点。自2013年以来,中国司法部门通过互联网向公众开放了一系列裁判文件,以期通过社会的力量获得辅助法律判决预测的新方法。法律判决预测一般包括多类子任务:罪名预测、法条预测和刑期预测等[1]。本文主要关注于罪名预测任务,以刑事案件为研究对象,主要目标是基于刑事法律文书中的案情描述和事实部分,使模型能够准确预测案件所涉及的罪名。具有较大的应用价值[2]。
本文提出了一种融合了图卷积神经网络[3]和BiGRUTextCNN的罪名预测系统模型。本文利用训练好的词向量将文本序列化后输入到BiGRU-CNN模型中,提取到案情描述的特征,依此进行分类得到对测试集样本的各标签的分数。再将文本数据转化成结构化数据输入到GCN模型中,同样对测试集样本各标签进行评分,最后将二者的分数相加,取最高分作为最后的预测结果。
1 相关工作
1.1 数据预处理
对于BiGRU-CNN模型预测部分,需要对数据进行分词、去除停用词、构建词典、文本序列化。完成以上操作后即可输入到BiGRU-CNN模型中,而GCN模型只能处理结构化数据,因此对于案情描述文本需要将其转化为结构化数据,把每一条案情描述转变成图数据的邻接矩阵的形式,首先对分词去停用词后的案情描述进行词频统计如表1。

表1 部分词频统计表
选取出现最多的前一千个词,并根据这一千个词排列顺序,对分词去停用词后的案情描述进行替换,将每一条文字描述替换成相应的数字序列,流程如图1。
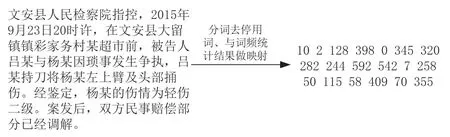
图1 文本转换流程图
这些序列中的每一个数字视为图结构中的点。本文需要依据数字序列构建包含文本结构信息的邻接矩阵。为了建立点与点之间的联系,本文将数字序列中相邻的两个点设为相关联,同时每个点也与自身相关联,以此为规则生成邻接矩阵中的坐标。同时考虑到在中文文本中每个词汇都是有相应的词性的,若是不区分词性将所有节点默认为一类将失去部分文本信息,因此本文依据中文词汇中的名词、代词、动词、形容词、数词、量词、区别词、副词、介词、连词、冠词、助词这十二种词性,将这一千个词代表的点分为了十二类。本文依据上述方式将文本数据转化成了图卷积神经网络可以处理的图数据。
1.2 图卷积神经网络
图数据的每个结点都受到其邻居节点的影响,图卷积神经网络就是利用邻居结点的信息来推导该结点的信息,从而得到图数据的特征。这一过程中又需要用到两个理论工具拉普拉斯矩阵与傅立叶变换。为了得到数据的图域卷积,需要先对图和卷积核做傅立叶变换后相乘,再傅立叶反变换回来,这样就得到了图域卷积。因此得到了图卷积的计算公式如式1。
其中, 为邻接矩阵与单位矩阵的和, 为 的度矩阵,H是每一层的特征,W是权重矩阵,再经过非线性激活函数σ就得到了图卷积提取的图数据特征。
1.3 BiGRU
GRU是LSTM网络的一种效果很好的变体,它继承了LSTM模型和RNN模型的特性,一定程度上解决了RNN的梯度问题,同时解决了梯度反传过程由于逐步缩减而产生的梯度消失问题,能够学习长期的规律。而BiGRU 是由两个反向的GRU 组成的神经网络模型,BiGRU能够提供额外的上下文特征信息,有助于捕捉时间序列里长期的依赖关系。在GRU模型中只有两个门:分别是更新门和重置门。具体结构如下图2所示:
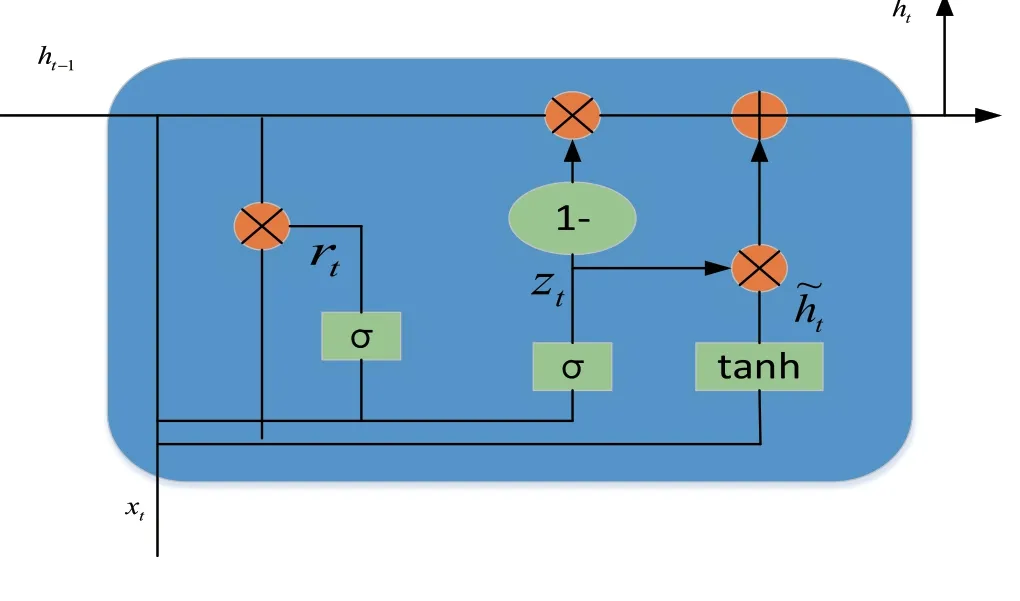
图2 GRU结构单元
计算过程如式2、3、4、5。
而双向GRU(BiGRU)BiGRU是由单向的、方向相反的、输出由这两个 GRU 的状态共同决定的 GRU组成的神经网络模型,这种形式能获取某一时刻前、后两个方向的数据信息并加以利用,使得预测值更加接近真实值。
1.4 Text-CNN
卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习的代表算法之一。卷积神经网络具有表征学习能力,能够按其阶层结构对输入信息进行平移不变分类,因此也被称为“平移不变人工神经网络”。图像上的CNN模型主要是依靠输入图片的平移不变性,利用卷积核提取图片特征,而在文本上CNN模型种卷积核提取的是相邻两个或多个个单词向量的特征,与传统的CNN卷积核相比Text-CNN的卷积核不是正方形的,宽度跟词向量维度相等。文本分类模型text-CNN与传统CNN网络相比网络结构上没有任何变化。
2 模型架构
本文使用BiGRU-TextCNN模型和GCN模型分别完成对数据的预测,再将二者的结果汇总成最后的预测结果。这里是两个模型分别进行训练预测的过程如图3,首先将文本数据传入到BiGRU-TextCNN模型中得到预测的分数,再将文本数据处理成图数据放入GCN模型中得到该模型的预测分数,最后将2个预测的分数相加,选取最大的作为最后的预测结果。
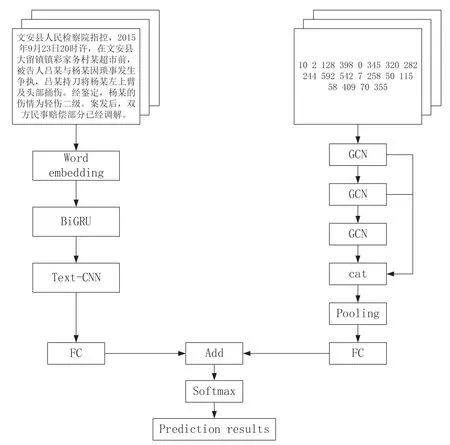
图3 模型结构图
2.1 BiGRU-TextCNN模型预测
这一部分使用了 BiGRU-TextCNN模型对数据集进行特征提取训练和预测,首先将数据分词去停用词,再经过词嵌入层获得文本的向量表示,这时就可以输入到BiGRU中进行特征提取,再将提取出来的时序特征传入下层的Text-CNN模型中再次提取特征,最后经过全连接层得到一个包含了预测结果的向量。
2.2 GCN模型预测
这一部分使用了GCN模型对数据集进行特征提取训练和预测。因为GCN只能处理非欧式数据,所以需要根据前文所述的方法将文本转化成图数据的形式。数据处理完成后将其输入到GCN模型中,本文使用的模型有三个图卷积层,将三组特征相拼接组合成了最后的特征,输入到池化层中,本文使用的是基于自注意力的池化机制的思想,是通过图卷积从图中自适应地学习每个节点的重要性。最后一样经过全连接层得到一个包含了预测结果的向量。
2.2 特征融合
特征融合是模式识别领域的一种重要方法,主要应用于计算机视觉中的图像识别上,特点是实现多特征的优势互补增加结果的准确性,特征融合的方式有两种分别是早融合和晚融合。
本文采用的是晚融合的特征融合方法,即通过GCN模型和BiGRU-Text-CNN模型分别预测出两个包含结果的向量大小为128×10,将这两个向量按40%和60%的比重对应相加得到融合二者的新的预测向量,经过激活函数后得到最后的预测结果。
3 实验验证与分析
3.1 数据集介绍
本次实验使用了法研杯2018的数据集,该数据包含了20多万条各种罪名文本,每一条数据由8个部分组成,包括事实描述、被告、罚款、罪名、相关法条、是否死刑、是否无期、有期徒刑刑期。本文主要使用了事实描述和罪名部分,选取了数据集中出现最多的十种犯罪罪名,包括盗窃、抢劫、故意伤害、非法持有或私藏枪支弹药、诈骗、危险驾驶、制造贩卖传播淫秽物品、交通肇事、受贿、组织强迫引诱容留介绍卖淫,数据集结果如下表2。
表2 数据集组成
3.2 模型评价标准
本文采用了宏平均来评价模型首先分别计算各自分类的Precision和Recall如式6、7、8,得到各自的F1值,然后取平均值得到Macro-F1,其中TP表示将正类预测为正类的个数,FN表示将正类预测为负类的个数,FP表示将负类预测为正类的个数,TN表示将负类预测为负类的个数。
3.3 实验结果分析
实验是对2018年法研杯数据集进行训练和测试,按照数据集中文本个数的80%进行训练和20%进行测试的规则进行数据划分,分别对Text-CNN模型、RNN模型、LSTM模型、RNNAttention模型,BiGRU模型、BiGRU-Text-CNN模型和本文使用的GCN-BiGRU-Text-CNN模型进行了实验,实验结果如下表3。

表3 各算法实验结果
从实验结果来看,Text-CNN模型的效果要优于RNN模型,但是融合了注意力机制后RNN-Attention模型要比RNN模型强一些。BiGRU模型继承了LSTM模型和RNN模型的特性,一定程度上解决了RNN的梯度问题。BiGRU-TextCNN模型融合了CNN和BiGRU的特点有了更好的结果,本文使用的模型在此基础上还另外融合了GCN模型,在最后的实验数据上有一定的提升,证明的本文提出的方法的可行性。
4 结束语
本研究由甘肃省教育厅创新基金项目(2022CYZC-57)资助。本文使用的融合图卷积神经网络和BiGRU-CNN的模型,较以往的方法F1有所提升,往后对二者进行特征融合达到更好的结果是我们未来的研究方向。
