基于GAN 的红外与可见光单应性估计方法
2023-03-17罗银辉王星怡吴岳洲魏嗣杰
罗银辉, 王星怡, 吴岳洲, 魏嗣杰
(中国民用航空飞行学院 计算机学院, 四川 广汉 618307)
0 引言
单应性模型主要用于实现2 幅图像间的几何变换,被广泛用于图像配准领域[1]。 红外和可见光图像所具有的互补性克服了单传感器系统所固有的缺陷,二者的配准具有深远的研究意义[2]。
生成对抗网络(Generative Adversarial Network,GAN)因自身优势逐渐被应用到图像配准中,通过对抗来提升配准精度。 Hong 等[3]将GAN 用于预测掩码,以对预测的单应性施加共面约束。 但该方法并未直接将GAN 用作单应性矩阵输出的框架,仅是作为一个组件来对单应性进行约束。 Tanner 等[4]通过GAN 学习对称模态转换器,以将单模态图像配准算法用于多模态配准中。 Wang 等[5]提出二阶段变压器对抗网络(Transformer Adversarial Network,TAN),利用对抗性提升红外图像和可见光图像配准精度。 Kumari 等[6]利用具有空间变换器的GAN 实现了红外与可见光图像配准。
以上方法主要利用GAN 作为模态转换器或起约束作用的组件,并未将其直接用于单应性矩阵输出的框架。 因此,本文从另一个角度出发,直接将GAN 用作单应性矩阵输出的框架,以证明GAN 在单应性估计中的可用性,并可有效提升单应性估计的精度。 本文的主要贡献包括:
① 将GAN 直接用于单应性矩阵输出的主框架;
② 使用精细特征作为判别器的输入,而非像一般GAN 那样直接使用图像对作为输入,以将稳健的特征作为主要判决对象。
1 方法
1.1 单应性估计框架
本文提出了一个以GAN 为主框架的单应性估计方法,以有效实现红外与可见光图像的配准任务,网络框架如图1 所示。 单应性估计整体框架主体由3 部分构成:浅层特征提取网络f(·)、生成器G 和判别器D。 首先,给定一对大小为W×H的灰度红外图像Ir和可见光图像Iv作为网络输入,将其输入到浅层特征提取网络中得到图像的精细特征Gr和Gv,并用于后续的单应性估计和损失计算。 其次,将Gr和Gv在通道维度上进行级联,以作为生成器的输入,并分别输出单应性矩阵Hrv和Hvr。 然后,对单应性矩阵Hrv运用到灰度红外图像Ir上得到扭曲的红外图像I′r,并将其输入到浅层特征网络中得到精细扭曲特征G′r。 最后,将可见光特征Gv和扭曲红外特征G′r分别送入到判别器网络中,其目的是区分Gv和G′r。 同理,将红外特征Gr和扭曲可见光特征G′v输入到判别器中得到对应的预测标签。
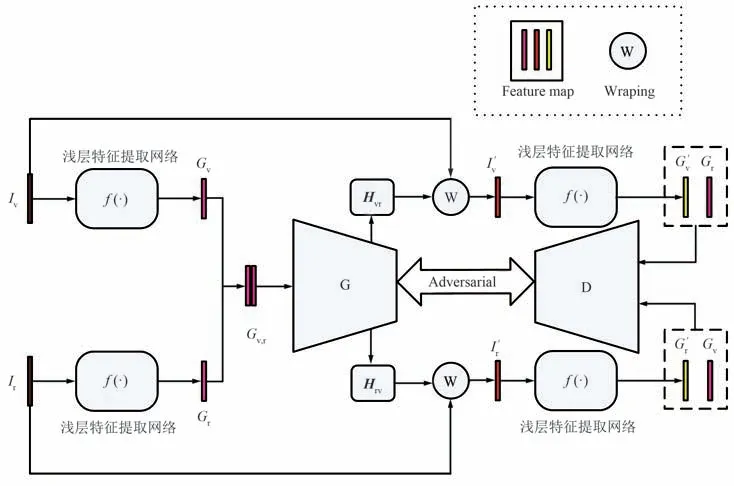
图1 基于GAN 的单应性估计总体框架Fig.1 Overall framework of GAN-based homography estimation
1.1.1 浅层特征提取网络f(·)
浅层特征网络由特征提取块(Feature Extraction Block,FEB)、特征细化块(Feature Refinement Block,FRB) 和特征整合块( Feature Integration Block,FIB)组成,以产生精细特征Gr和Gv。 特别地,4 个特征浅层提取网络均共享权重,网络框架如图2 所示。
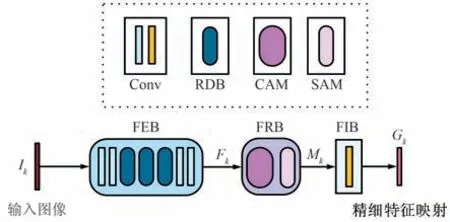
图2 浅层特征提取网络Fig.2 Shallow feature extraction network
特征提取块由4 个卷积块和3 个残差密集块(Residual Dense Block,RDB)[7]组成,以提取红外与可见光图像的深层次特征,网络结构如图3 所示。具体来说,首先,通过2 个3×3 的卷积块提取图像的浅层特征。 其次,利用3 个RDB 提取图像的深层次特征,并且每个RDB 均进行局部特征融合以自适应地学习来自先前和当前局部特征中的更有效特征。 最后,利用全局性融合将多个RDB 的分层特征融合到一起,并利用全局残差学习将浅层特征和深层特征结合到一起以得到全局密集特征。 这一过程的计算如下:
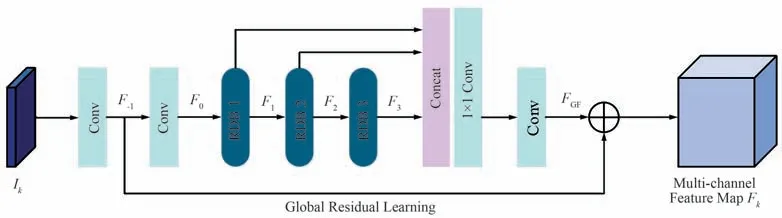
图3 特征提取块Fig.3 Feature extraction block
式中,F-1表示浅层特征映射;Fi表示第i个RDB 提取到密集特征映射,i∈{1,2,3};HGFF(·)表示所有RDB 的融合计算。
特征细化块由卷积注意力机制模块(Convolutional Block Attention Module,CBAM)[8]构成,它对通道和空间2 个维度进行注意力映射,以得到密集特征中对单应性求解有意义的特征。 具体来说,特征细化块首先利用特征的通道间关系生成通道注意力映射,以使网络集中于输入图像中有意义的地方。其次,利用特征之间的空间关系生成空间注意力,以侧重于图像中的信息部分。 这一过程的计算为:
式中,Mck和Msk分别表示空间注意力和通道注意力。
特征整合块由1 个卷积块组成,其主要目的是将多通道特征的通道数转换为1,以降低后续网络中的运算量。
1.1.2 生成器G
本文将文献[9]中单应性估计器用作GAN 的生成器G,以产生单应性矩阵,网络框架如图4 所示。 生成器以ResNet-34[10]作为主干,通过将红外图像和可见光图像的精细特征Gr和Gv进行通道级联以作为输入。 然后,生成器以4 个集合向量作为输出,并利用直接线性变换(Direct Linear Transformation,DLT)[11]得到单应性矩阵。
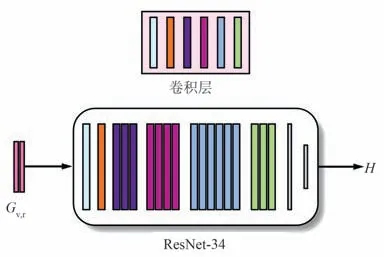
图4 生成器网络框架Fig.4 Generator network framework
1.1.3 判别器D
受红外与可见光图像融合方法的启发,本文使用文献[12]中的判别器作为单应性估计方法中的判别器D,网络框架如图5 所示。 相较于文献[12]中的判别器,本文删除了其倒数第2 个模块,其中包含2 个通道数为512 的卷积。 同时,还将最后一个模块的输出通道数修改为1,用于判断输入精细特征映射对齐的概率。
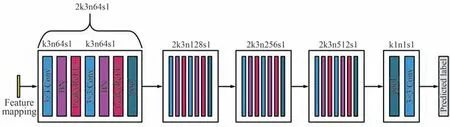
图5 判别器网络框架Fig.5 Discriminator network framework
判别器D 的本质是一个分类器,通过从输入图像中提取特征映射来对其进行分类。 首先,通过浅层特征提取网络分别提取扭曲图像和目标图像的精细特征;然后,将精细特征作为判别器D 的输入,以对扭曲图像和目标图像进行区分;最后,通过在生成器G 和判别器D 之间建立对抗性博弈,使得扭曲图像和目标图像间的精细特征位置越来越接近。 在训练阶段,一旦生成器生成了判别器无法辨别的样本,本文就得到了可以配准的扭曲图像。
1.2 损失函数
1.2.1 配准损失
配准损失将鼓励扭曲图像的精细特征更加接近于目标图像的精细特征。 受文献[9]中Triplet Loss的启发,本文直接利用图像对的精细特征进行损失计算,以判别精细特征的对齐情况。 配准损失描述为:
式中,Ir和Iv分别表示灰度红外图像和灰度可见光图像;I′r表示对Ir使用单应性矩阵Hrv进行扭曲所得的图像;Gr和Gv分别表示Ir和Iv经过浅层特征提取网络后得到的精细特征;G′r表示I′r经过浅层特征提取网络后得到的精细特征。 同理,可得到另一配准损失Lreg(I′v,Ir)。
1.2.2 单应性损失
受文献[9]的启发,本文利用单应性损失来迫使Hrv和Hvr互为逆矩阵。 单应性损失描述为:
式中,Hvr表示由Ir和Iv的精细特征求解的单应性矩阵;Hrv表示交换Ir和Iv的精细特征后所求解的单应性矩阵;E 表示三阶恒等矩阵。
1.2.3 对抗损失
受文献[13]的启发,本文将图像融合中的生成器对抗损失迁移到图像配准任务中,以生成更能对齐的扭曲图像。 生成器中的对抗损失Ladv(G)是根据所有训练样本中判别器的概率确定的,其被描述为:
式中,G′r表示扭曲红外图像精细特征;logDθD(·)表示扭曲图像精细特征与目标图像精细特征对齐的概率;N表示网络中batch 的个数。 同理,可以得到另一生成器的对抗损失Ladv(G,G′v)。
受图像融合算法[12]中对判别器损失函数设计的启发,本文方法中判别器D 的对抗损失被描述为:
式中,a和b分别表示目标图像和扭曲图像的标签;Ladv(D,Gr,G′v)表示红外图像精细特征Gr和扭曲可见光图像精细特征G′v之间的损失函数;同理,可以得到另一对抗损失Ladv(D,Gv,G′r)。 在实验中,标签a设置为0.95~1 的随机数,标签b设置为0~0.05 的随机数。
1.3 目标函数
1.3.1 更新生成器G 的目标函数
生成器G 以一对精细特征Gv和Gr作为输入,并输出单应性矩阵。 模型根据损失函数的变化,使得扭曲图像中和目标图像之间的精细特征尽可能对齐,从而达到欺骗判别器的效果。 生成器G 的损失函数主要由3 部分组成:配准损失、单应性损失和生成器对抗损失。 因此,最终生成器的目标函数描述为:
式中,λ和μ表示平衡超参数。 在实验中,λ设置为0.01,μ设置为0.005。
1.3.2 更新判别器D 的目标函数
判别器D 作为二分类来区分真和假,以输出图像精细特征可以得到对齐的概率。 判别器应该尽可能地区分扭曲图像和目标图像之间精细特征的差异。 判别器D 的损失函数主要由判别器对抗损失组成。 因此,最终判别器的损失函数描述为:
2 实验设置与评价指标
2.1 数据集
针对目前红外与可见光场景下未配准的数据集较少、已配准的数据集较多的情况,本文选取了图像融合任务中较为著名的红外与可见光数据集用作本文的数据源。 特别地,这些数据集中图像对普遍较少,因此使用OSU Color-Thermal Database[14],INO 和TNO 三个公开数据集作为本文的数据源,从中共选取了115 对和42 对红外与可见光图像用于基础训练集和测试集。
同时,为了获得丰富的数据集,本实验采用了旋转、平移和剪切等数据增广的方式扩充训练集,最终共得49 736 对红外与可见光图像。 其次,为了获得未配准的数据,实验采用了DeTone 等[15]方法来制作数据集,最终产生大小为150×150 的未配准红外与可见光图像Ir和Iv以及红外真值图像IGT。
2.2 训练策略
网络框架基于 Pytorch 实现, 并在 NVIDIA GeForce RTX 3090 进行训练。 采用基于自适应动量估计(Adaptive Momentum Estimation,Adam)[16]作为网络优化器,指数衰减学习率初始化为1. 0×10-4,衰减因子为0. 8,衰减步长为1 个epoch。 另外,训练过程中设置了50 个epoch,batch_size 设置为8。
2.3 评价指标
为了验证所提算法的有效性,选取了平均角点误差(Average Corner Error,ACE)[17-18]和结构相似性(Structural Similarity,SSIM)[19]作为评估指标。
ACE 通过估计单应性和真值单应性来变换角点,然后计算角点之间的平均距离误差作为评估值。距离误差越小,表明配准效果越好。 ACE 描述为:
式中,ci和c′i分别表示估计单应性和真值单应性所变换的角点坐标。
SSIM 使用了图像亮度、对比度以及结构来衡量图像相似度,其值属于[0,1],值越大表示配准结果越好。 SSIM 描述为:
式中,x和y分别表示扭曲图像和真值图像;μx和μy分别表示x和y中所有像素点均值;σx和σy分别表示x和y中的标准差;σxy表示2 个图像的协方差;C1和C2表示维持稳定的常数。
3 实验结果及分析
3.1 主观评价
在测试集上与SIFT[20]+RANSAC[21],ORB[22]+RANSAC[21],BRISK[23]+ RANSAC[21],AKAZE[24]+RANSAC[21]以及CADHN[9]等算法进行了对比实验。 在对比算法中,仅CADHN 是基于深度学习的算法,其余均是基于特征的算法。 特别地,部分基于深度学习的方法难以在红外与可见光数据集上进行拟合,例如Nguyen 等[25]所提方法在红外与可见光场景下无法收敛。 Ye 等[1]和Hong 等[3]所提方法均使用了单应性流的思想,但红外与可见光图像本身所存在的较大灰度和对比度差异会造成单应性流变化不稳定,使得网络难以收敛。 因此,在基于深度学习的方法中,本文仅采用CADHN 作为对比算法。
图6 显示了不同算法的扭曲图像对比,可以清晰地看出,基于深度学习的算法明显优于基于特征的算法。 如图6 所示,在这类测试场景下,AKAZE+RANSAC 完全失效,无法预测得出扭曲图像。 其余3 个基于特征的对比算法配准性能较差,扭曲图像发生严重畸变。 相比之下,基于深度学习的算法可得到完整的扭曲图像,且配准性能更优。

图6 不同算法扭曲图像对比Fig.6 Comparison of warp images of different algorithms
图7 显示了3 种场景下不同算法的配准结果,其配准结果是将扭曲红外图像的蓝色通道和绿色通道与真值红外图像的红色通道进行融合所得,其中红色重影和绿色重影代表未实现配准。 图7 中的“-”表示配准失效。 由图7 可知,SIFT+RANSAC 在这3 种场景下是完全失效的,而其余基于特征的算法仅在第3 种场景下完全失效,剩余2 种场景虽然可以产生扭曲图像,但配准效果较差。 造成这一结果的主要原因是红外图像和可见光图像具有较大的灰度差异,基于特征的算法难以获得足够较高质量的特征点对。 另外,由图7 可知,本文算法在这3 种场景下明显略优于CADHN,可以得到更多对齐的像素点。

图7 不同算法配准结果对比Fig.7 Comparison of registration results of different algorithms
3.2 客观评价
为了定量验证本文算法的有效性,本文使用评价指标ACE 对42 组测试图像进行评估,并说明了每类算法的失效率,结果如表1 所示。 失效率是由测试图像失效数与测试图像总数的比值所求得。 如表1 所示,基于深度学习的方法明显优于基于特征的方法。 传统基于特征的算法不仅有较高的算法失效率,而且ACE 较高,无法实现配准。 特别地,SIFT+RANSAC 虽然失效率是最高的,但其ACE 明显优于其余基于特征的算法。 另外,相较于CADHN而言,本文方法的ACE 从5.25 明显下降至5.15。但本文方法的SSIM 略低于CADHN,其主要原因是本文方法中扭曲图像的黑边多于CADHN,从而影响了SSIM 的计算。
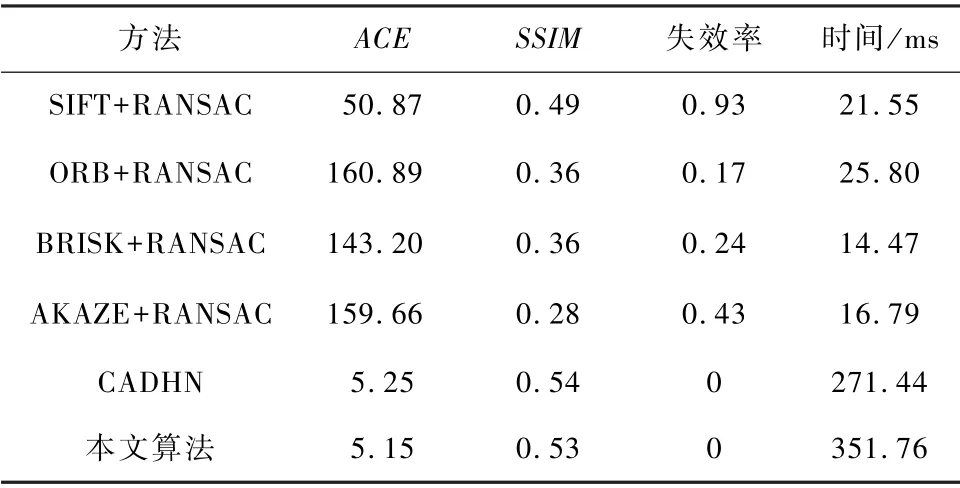
表1 不同算法的配准评估结果Tab.1 Registration evaluation results of different algorithms
同时,基于特征的算法耗时明显低于基于深度学习的算法,但其算法失效率和配准性能较差,难以适用于红外与可见光场景。 虽然CADHN 的耗时比本身算法低80.32 ms,但其ACE 却明显低于本文算法。 因此,本文所提模型可得到较好性能,且优于其余传统基于特征和基于神经网络的算法。
4 结束语
本文提出了一种将GAN 作为单应性估计主框架的红外与可见光单应性估计方法。 把图像的精细特征作为生成器和判别器的输入,使得网络更加关注于图像中的重要特征。 同时,通过在生成器和判别器之间建立对抗性博弈,使得扭曲图像和目标图像之间的精细特征越来越接近,从而提升单应性估计性能。 实验结果表明,相较于次优算法CADHN,本文方法不仅能够得到更为准确的扭曲图像,而且评估指标ACE 从5.25 明显下降至5.15。 未来将尝试在GAN 框架下对生成器进行进一步改进,以继续提升单应性估计性能。
