基于卷烟陈列识别和品牌文本表示的销量预测方法
2023-03-17刘雁兵刘晓蓉王义新汪伟飞吴凌翔
刘雁兵, 肖 骏, 刘晓蓉, 王义新, 汪伟飞, 吴凌翔
(1.广西中烟工业有限责任公司, 广西 南宁 530001;2.广东烟草广州市有限公司, 广东 广州 510610;3.武汉人工智能研究院, 湖北 武汉 430074)
0 引言
在现代零售行业,智能营销是提升渠道[1]掌控力和商品销售的关键性环节。 运用数据挖掘技术和大数据分析方法挖掘这些数据背后隐藏的信息,能促进烟草行业从传统的批发模式升级为数据驱动的烟企商户利益共同体模式[2-6]。 在烟草销售环节,卷烟的陈列方式、不同的摆放位置往往会影响卷烟销量。 穆建军[7]为了解决商户经营面积小、陈列困难等问题,创新地采用立体陈列方式来克服客户选购不便的缺陷。 刘薇[8]探究卷烟陈列标准,为卷烟的陈列方式、陈列模型设立了原则要求与具体标准,来达到合理摆放、激发消费者购买意愿的目的。 对零售终端陈列的各种卷烟进行识别[9]与统计,分析其销售情况进行评估,不仅对卷烟的品牌营销[10]具有指导意义,更有助于智能化零售终端系统的探究。
在卷烟陈列与销量的分析中,主要面临2 个挑战。 一个挑战是数据质量,零售终端系统(POS 机)作为数据触点,承载着信息采集和消费跟踪等重要功能,然而部分客户规范使用终端信息系统意识不强,导致零售终端数据的采集及其质量难以保证[11]。 目前烟草行业普遍采用的方法是选定少数经营较为规范的客户作为信息采集点,但这些信息采集点数量占比非常低,通过这些少量的市场样本去分析市场状态、制定货源投放策略以及开展品牌营销等,可能会造成决策上的失误。 另一个挑战是多源特征的表达。 为预测销量,涉及到陈列位置特征、品牌名称特征、价格和地区等特征。 以陈列特征为例,由于卷烟品牌种类繁多,部分商品图案相似难以区分,陈列特征难以获取;以品牌名称为例,需要基于文本的品牌嵌入式表达等。 提取卷烟的不同属性作为特征,对训练销量预测模型至关重要。
为解决以上问题,本文提出一套卷烟销量预测方法,包含样本质量筛选、销量预测模块,后者又包含卷烟识别和文本表达等网络。 在样本质量筛选阶段,设计了POS 机使用质量评估准则,构造数据集;为了更强的可解释性,选择随机森林模型,训练POS机质量分类器,并通过特征选择,过滤掉冗余特征。基于POS 机信息系统登录、在线、商品扫码和支付等环节的数据、商品进销存数据,结合异常值检测,建立了一套量化的零售终端运行质量评估体系,结合日级评分和月级评分,将零售终端运行质量分为5 类,并以此为训练数据。 最终选择高质量的商户,作为下游销量预测模块的样本点。
在销量预测过程中,通过基于深度学习的图像识别检测技术对卷烟位置进行精准定位与品牌识别。 利用品牌文本表达、视觉信息和价格等多维度信息,结合大数据分析方法研究卷烟品牌、陈列位置和卷烟销量之间的关联关系,研究卷烟陈列与消费选择行为之间的内在机理,综合评估卷烟陈列不同区域价值,为终端陈列优化和智能化管理提供指导。针对某个规格的卷烟,绘制其在不同摆放位置的陈列价值图,从而为商家提供陈列最优决策。 最后,构建BERT-MLP 模型来预测卷烟销量,分析卷烟规格、位置和价格对销量的影响。
1 高质量样本筛选
1.1 零售终端运行质量评估体系及数据集构建
本文提出了一种融合日级评分和月级评分的评估体系,首先通过规则设计的方式构建质量评估数据集。 基于对实际业务的调研,设计可量化的统计特征,结合统计学中的异常值分析方法和专家的经验设计相关评估准则。 通过对日级评分和月级评分进行加权得到综合评分,将零售客户按数据采集质量分为5 类,从而建立起零售终端运行质量评估体系。
本文的分析数据源包括销售信息、商品信息、登录日志和店铺信息等,关键指标定义如表1 所示。
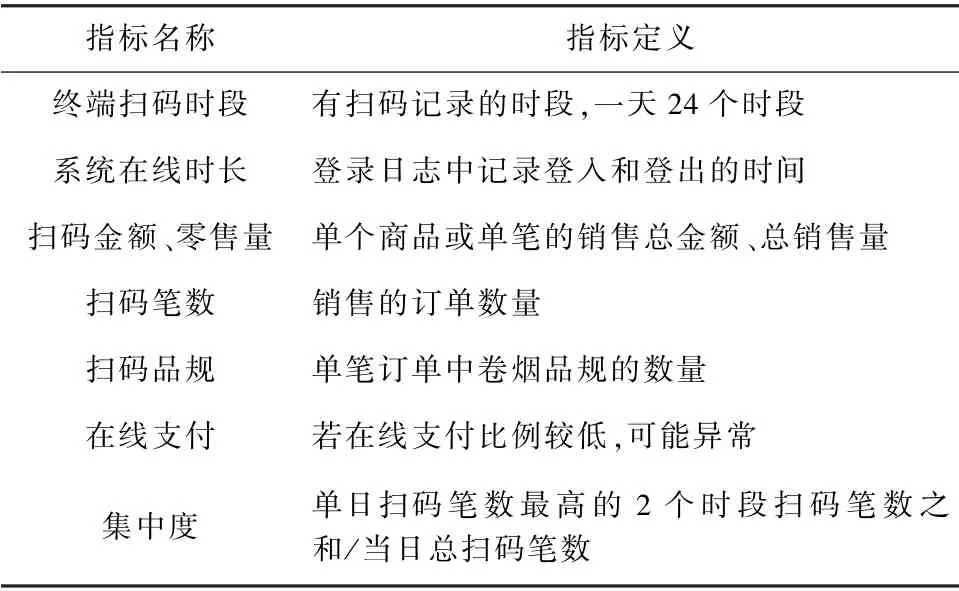
表1 评估指标Tab.1 Evaluation indicator
评估规则实际上是对上述评估指标的具体化,为了更加全面具体地评价零售终端的运行质量,从日和月时间维度来设计评估规则。 日级评估规则主要对每日零售终端可能存在的在线异常、漏刷、集中补刷和价格异常等情况判断,规则涉及的指标包括在线时长、销售时段、扫码间隔、日卷烟销量、单笔销量、卷烟扫码笔数和卷烟销售价格等,记为n1,n2,n3,…,n20。
月级评估规则通过对每月零售终端销售数据进行分析,判断零售终端可能存在的异常,规则涉及的指标包括月均扫码时段、日均扫码笔数、在线时长、卷烟销售宽度、在线支付占比和卷烟销量同比波动等,记为m1,m2,m3,…,m9。
按照日级和月级2 个维度,对评估规则中涉及到的量化指标进行聚合分析,按照3σ 法则、箱线图和专家经验相结合的方法确定评估规则的边界,判断是否触发,进而对其进行评分。 在日级评估环节,采用满分扣分制度,日级规则的初始分为100,每触发一个日常监控规则扣5 分;在月级量化评估环节,按照月的时间维度对终端POS 机的使用情况进行评分,每满足一条规则加10 分。 最后,对日级评估均分和月级评分进行加权求和,最终得到该零售终端的月度综合评分。 评分与样本分类对应关系如表2 所示。
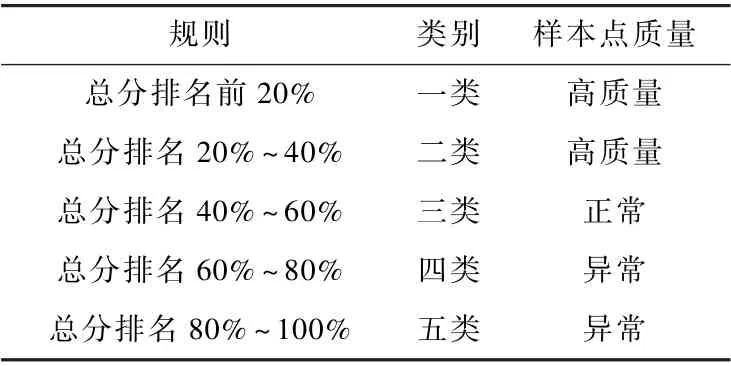
表2 终端质量等级划分Tab.2 Terminal quality classification
1.2 质量分类模型
基于前文构造的数据,训练零售终端运行质量分类模型,包含3 类:高质量样本点、正常样本点和异常样本点。 考虑到商业分析中更注重可解释性以及特征筛选的需求,质量分类模型选择随机森林模型。
备选特征共29 个,如表3 所示。

表3 特征含义Tab.3 Feature meanings
为去除无关特征和冗余特征,采用递归特征消除法(RFE)结合相关系数热力图筛选特征。 通过RFE 方法删除4 个特征:每月触发日级规则的D5,D15 和D16 的次数,以及是否满足月级规则M2。 经过RFE 筛选出与目标变量有较高相关性的特征,在此基础上,通过Pearson 相关分析剔除冗余特征。经双层特征筛选,将特征数量缩减为19 个。 具体筛选过程、模型细节及特征重要性详见3.1.1 节。
2 卷烟销量预测
2.1 卷烟识别模型
零售终端的卷烟陈列识别需要采集卷烟陈列前柜图片作为数据,识别陈列位置pos=(x,y,w,h),其中,(x,y)表示卷烟盒左下顶点的坐标,(w,h)表示烟盒的宽度与高度。 采用了复杂深度耦合网络模型,并利用多元组排序方法作为损失函数来训练该精细化识别模型。
复杂深度耦合网络在骨架网络中加入了注意力机制,同时设计了深度耦合结构,其主要由3 个模块组成:骨架网络(Backbone)、特征金字塔[12](Feature Pyramid Network,FPN)以及深度耦合预测头(Coupling Head),框架如图1 所示。 骨架网络中含注意力模块[13-14]。
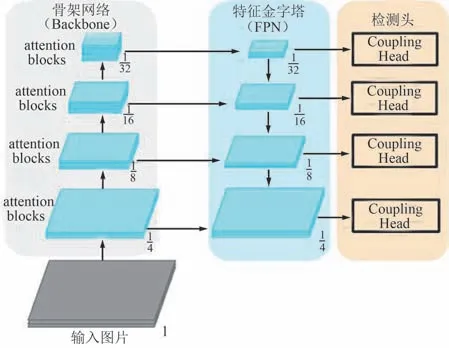
图1 复杂深度耦合网络示意Fig.1 Schematic diagram of complex deep coupling network
由于卷烟规格具有多样性,每种规格之间差异性比较小,个别规格之间只有些许文字或者图案上的差异,给规格的精细化识别带来了巨大的挑战。针对上述问题,本文提出了一种基于多元组排序学习[15]的卷烟精细化识别方法,如图2 所示,通过度量学习的方法学习更加精准的特征,来增强算法的分类能力。
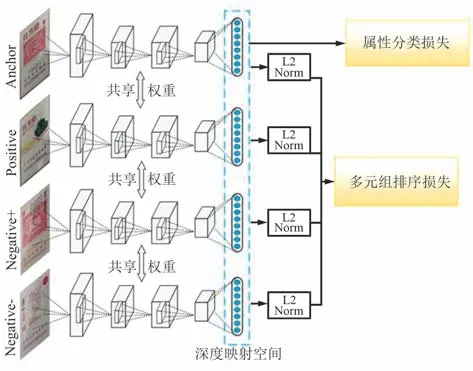
图2 基于多元组排序学习的精细化识别示意Fig.2 Schematic diagram of refined recognition based on multivariate group sorting learning
针对具体任务,设计合理的目标损失函数用来监督深度神经网络的训练,可以学到一个高效的映射空间,在该空间中,目标被映射为一个有效的特征表示,使得特征之间的欧式距离可以直接反映目标之间的语义相似性。 多元组排序学习采用排序损失[16]作为目标损失函数来训练CNN(Convolutional Neural Network)模型。 以三元组为例,定义排序损失函数为:
该损失包含一个目标图像三元组,其中Ia与Ip属于同一个类别,In来自不同类别,该排序损失致力于减小特征空间中f(Ia)与f(Ip)之间的欧式距离,同时要求f(Ia)与f(In)之间的欧氏距离至少要比前者大。 该损失隐含的排序特性非常适合于精细分类任务,而且可以有效减小目标的类内差异,同时增大类间差异,学到更加具有判别力的特征映射空间。
2.2 陈列-销量初步分析
卷烟摆放位置与销量息息相关,即使是相同的卷烟,在不同的摆放位置也会产生不一样的效果,探究特定的卷烟品牌在不同位置上的销量有助于智能化零售终端系统的更优决策。 给定卷烟陈列图片与零售终端获取到的卷烟销售数据,智能化卷烟识别与陈列分析系统利用图像识别技术得到卷烟位置与规格数据,并结合来自零售终端的卷烟销售数据进行分析。
以某店铺为分析对象,绘制其卷烟陈列图谱,如图3 左上图所示。 从图中可以看出,红褐色的位置销量较好;对于同一品牌,卷烟的不同陈列位置一定程度上会影响卷烟的销量。 为了更加直观地展示卷烟品牌受欢迎程度,基于月销量数据,绘制了卷烟规格的词云图,从图3 左下图可以看出,苏烟(五星红杉树)、双喜(硬蓝红玫王)较受消费者欢迎。
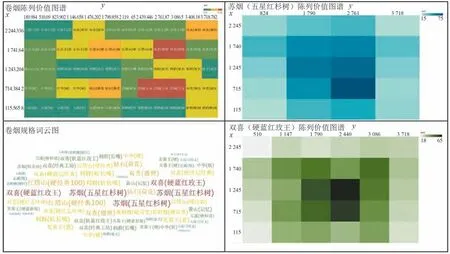
图3 卷烟销量分析Fig.3 Cigarette sales analysis
2.3 卷烟销量预测
本节进一步以卷烟的规格、陈列位置和价格等因素为特征,基于中文BERT 预训练模型[17-18]和全连接神经网络[19]来预测卷烟的销量。
本文提取卷烟的不同属性作为特征来训练模型。 对于卷烟规格,用BERT 获取其文本特征;对于其他特征,本文将卷烟的位置和价格特征拼接到BERT 预训练模型获取卷烟规格的词向量上,作为模型最终的输入特征。
BERT 预训练模型是从大量无标记的语料中训练得到的预训练语言模型,在2018 年由谷歌团队提出,其网络结构由若干个双向Transformer[20-21]的编码器模块堆叠组成。 如图4 所示,卷烟规格经过多层Transformer 之后输出为字符级向量。 本文采用了BERT 的预训练的模型BERT-Base,它含有12 个网络层数,768 个隐藏层,12 个注意力头数,模型参数量为1.1 亿。 BERT 输入表示是字符嵌入向量和位置嵌入向量的和,字符嵌入向量的开头和结尾分别用起始符和分隔符表示,中间部分用文本中的单个字符表示,位置嵌入从0 开始代表文本中每个字符的位置信息。
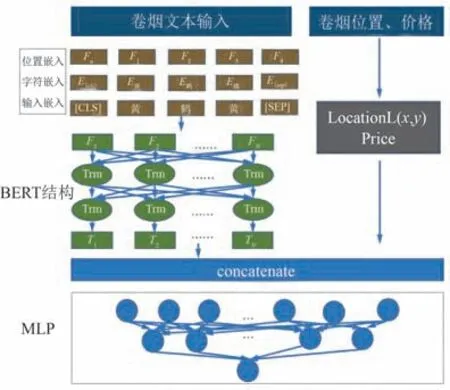
图4 BERT-MLP 模型结构Fig.4 BERT-MLP model structure
最后,将BERT 预训练模型得到的特征向量与位置特征以及价格特征拼接,并对拼接后的特征作归一化处理。
3 实验及结果分析
3.1 质量评估模型
3.1.1 特征选择
首先,结合交叉验证,确定最优特征数量为23。之后,通过递归式特征消除(Recursive Feature Elimination,RFE),每次删除一个特征,得到最终特征选择状况的布尔型表达和特征重要性排序。 RFE 方法删除了4 个特征:每月触发日级规则的D5 的次数、每月触发日级规则D15 的次数、每月触发日级规则D16 的次数、是否满足月级规则M2。
通过皮尔逊(Pearson)相关分析剔除冗余特征。由图5(a)共线性处理前的相关系数热力图可知,n1与n2,n7,m5,m7 之间的相关性分别为0. 99,-0.98,-0. 86,-0. 86;n2 与n1,n7,m5,m7 之 间 的相关性分别为0.99,-0.97,-0. 85,-0. 87。 考虑删除每月触发日级规则D2 的次数、每月触发日级规则D7 的次数、是否满足月级规则M5、是否满足月级规则M7,处理后的热力图如图5(b)所示。 最终入模特征有19 个,包括n1,n3,n4,n6,n8,n9,n10,n11, n12, n13, n17, n19, n20, m1, m3, m4, m6,m8,m9。
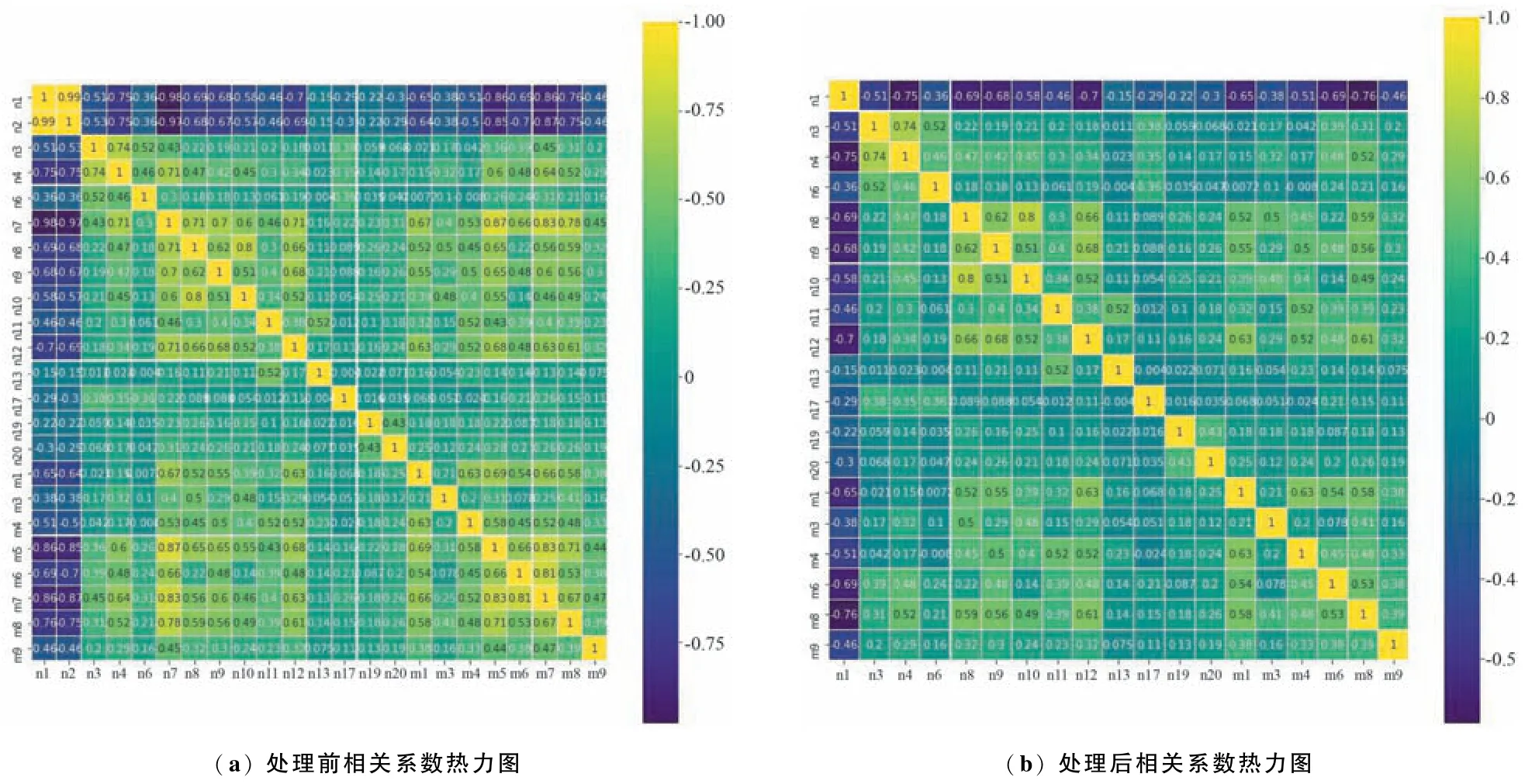
图5 Pearson 相关系数热力图Fig.5 Thermodynamic diagram of Pearson correlation coefficient
3.1.2 质量分类模型
质量分类模型测试集混淆矩阵及接受者操作特性曲线( Receiver Operating Characteristic Curve,ROC)如图6 和图7 所示,其中图7 的横纵坐标分别表示假正率和真正率。 模型宏平均ROC 下面积AUC(Area Under Curve)和微平均AUC 分别是0.97和0.99。 为了分析每个特征对于终端运行质量分类的重要程度,本文按照gini 指数计算特征的重要性,排序如图8 所示。
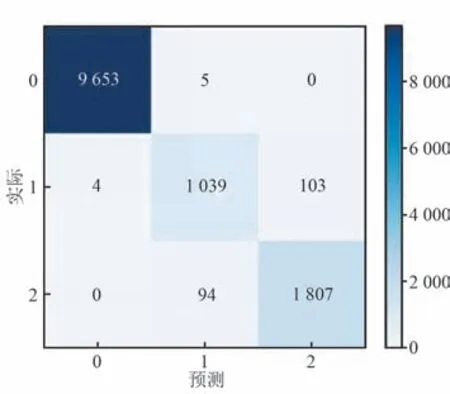
图6 随机森林模型的混淆矩阵Fig.6 Confusion matrix for the random forest model
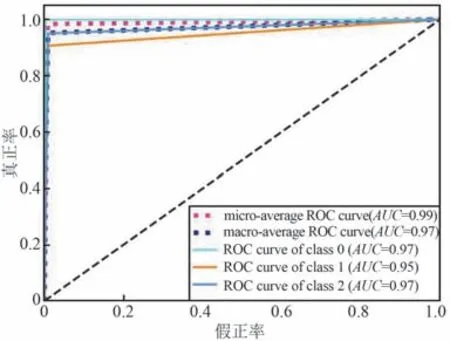
图7 随机森林模型的ROC 曲线Fig.7 ROC for the random forest model
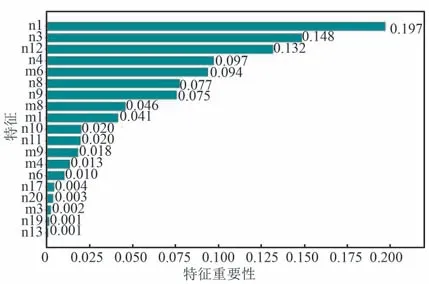
图8 特征重要性排序Fig.8 Sorting of feature importance
由图8 可以看出,特征重要性较高的是n1 和n3,即每月有扫码数据的天数和每月有零售记录的时段小于8 h 的次数这2 个特征对于终端运行质量的分类较为重要。
3.2 销量预测模型
3.2.1 实验设置
将构建的数据集按照7 ∶3 的比例划分为训练集和测试集。 本文搭建的BERT-MLP 模型由2 部分组成:第1 部分BERT 预训练模块采用中文“Chinese_L-12_H-768_A-12”网络框架;第2 部分多层感知机模块,主要包括2 个隐藏层和一个回归预测层。 模型的超参数设置如表4 所示。 激活函数选用ReLU,初始学习率设置为0. 001,并采用随机梯度下降法进行优化。
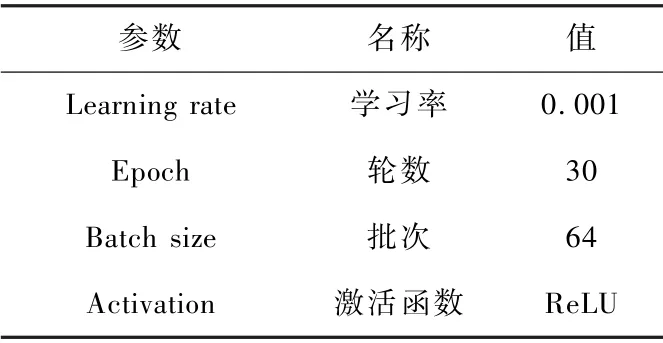
表4 模型超参数Tab.4 Hyperparameters of the model
3.2.2 模型评估
模型训练损失曲线如图9 所示。
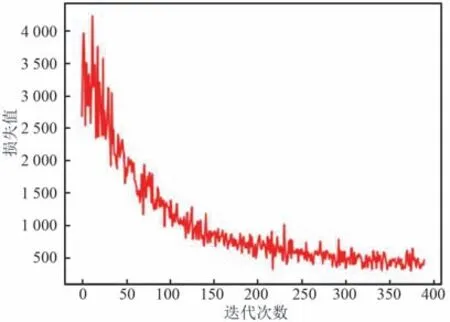
图9 模型训练的损失曲线Fig.9 Loss curve of model training
本文选择平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Square Error,RMSE)和决定系数(R2)作为评估模型性能的评价指标,计算公式如下:
式中,表示预测值;yi表示真实值。
模型在测试集上各个评估指标的结果如表5 所示。 此外,将真实值和预测值进行比较并可视化,如图10 所示。 可以看出模型具有较好的拟合效果,能够有效地预测卷烟销量。
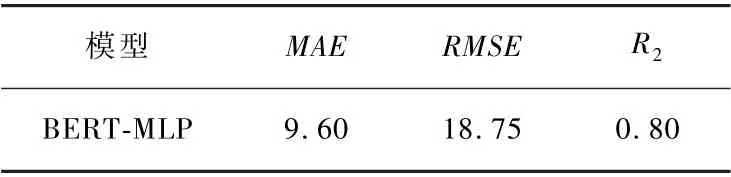
表5 不同评估指标的结果Tab.5 Results of different evaluation indicators
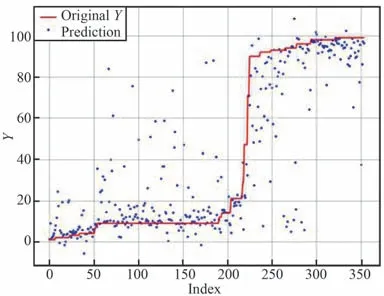
图10 预测值和真实值的比较Fig.10 Comparison between predicted value and actual value
4 结束语
本文搭建了卷烟销量预测方法,包含样本质量筛选、销量预测2 个主要阶段。 首先,建立了一套量化的零售终端运行质量评估体系,构建质量分类模型,筛选高质量样本点为后续所用。 在销量预测阶段,通过基于复杂深度耦合网络的深度学习模型识别卷烟陈列图片,较为准确地输出图片中卷烟的规格及位置,并结合终端卷烟的销售情况,绘制卷烟陈列价值图谱。 基于卷烟识别得到的数据,结合品牌文本表示,通过BERT-MLP 模型预测了卷烟的销量,分析了卷烟规格、陈列位置与销量之间的相关关系,可为终端陈列优化和智能化管理提供理论和决策支持。
