基于低比特量化神经网络的红外目标识别方法及其FPGA 实现
2023-03-15武宏程黄家明张冰逸卫俊杰高子扬钮赛赛陈海宝
武宏程,黄家明,张冰逸,卫俊杰,高子扬,钮赛赛,陈海宝
(1.空军装备部驻上海地区第一代表室,上海 200235;2.上海交通大学 电子信息与电气工程学院,上海 200240;3.上海航天控制技术研究所,上海 201109)
0 引言
红外目标识别系统在军事和民用领域有非常广泛的应用,如遥感探测、航空航天、目标监视等。在军事领域,智能化红外目标识别跟踪系统已成为现阶段和未来武器系统的重要组成部分,是制导武器变得更加具有精确性和智能化的一个重要指标,也是成像制导和高分辨率武器设备中的一种关键技术。在民用领域,红外目标识别跟踪也有着广泛的应用前景,已经是自主机器人、防碰撞车辆等智能化系统中起着重要作用的一项功能。因此,对智能化红外目标识别跟踪进行理论和应用研究,具有重大的理论和实际意义。
当前国内外传统的红外目标识别一般采用基于特征融合匹配的统计模式识别方法,实效性较强。但该类算法在红外目标运动特性变化较快和红外目标过小等情形下,无法有效实现目标的检测与识别。图像目标识别和检测的深度学习算法和架构设计是近年计算机视觉领域研究的重点。卷积神经网络不需要人工设置特征,深度学习算法能够在训练时通过设计好的模型直接从图像中提取所需要的特征来进行目标识别,这种方式能够提高特征质量进而极大地提高识别精度。相比于人,机器提取特征更加迅速、更加准确,例如SSD[1]、faster R-CNN[2]和YOLO[3]算法。
卷积神经网络的训练过程离不开图形处理器(Graphics Processing Unit,GPU)的支持。网络模型训练完毕后,继续使用GPU 进行神经网络的前向推理,无疑会增加整体系统的功耗。得益于较低的运行功耗与灵活可配置的硬件资源,在现场可编程门阵列(Field Programmable Gate Array,FPGA)上完成卷积神经网络的前向推理并进行加速,逐渐成为近年来的研究热点[4-7]。
许多先前工作表明深度学习的网络模型通常具有很大的冗余[8-10],压缩深度神经网络的方法大致可以分为五类:参数剪枝、参数量化、低秩参数分解、卷积核压缩变换、知识蒸馏。参数剪枝关键在于移除模型中冗余或者不重要的参数,而参数量化则集中于压缩权重的占用空间,如从浮点数压缩为定点数或者整数。低秩分解使用矩阵或张量分解技术,将一个较大的卷积核分解为几个较小的卷积核,从而减少参数存储所需的空间。基于紧凑型卷积滤波器的方法依赖于巧妙设计的结构性卷积滤波器,从而减少存储和计算复杂度。知识蒸馏的方法是尝试提取一个更加紧凑的模型来产生和一个更大的网络同样地输出结果。其中,参数量化是一种常用且具有前景的深度神经网络压缩方法,尤其是将量化精度限制在低比特时,相比浮点形式存储,权重和激活值的比特数同时减少,从而极大地节省模型在硬件平台运行的存储占用。
本文为了解决卷积神经网络在嵌入式FPGA上部署面临的软硬件协同设计难题,以红外目标识别的YOLO 网络为研究对象,使用通道级量化策略和反量化训练过程,并将BN 层与前一卷积层进行融合,将其进行权重的2 bit 量化和特征图的8 bit 量化,并将量化后的网络使用Xilinx HLS 进行高层次系统设计。考虑到采用PYNQ-Z2 作为硬件设备可能面临资源不足等问题,本文提出一个可灵活配置的、归一化并行卷积计算单元,可以对不同尺寸、不同卷积核大小的卷积层进行加速。通过对FPGA的资源和网络计算特性进行分析,得到一个最优的并行度。
1 红外目标识别网络
1.1 目标识别网络选择
本文选取YOLO 网络用于红外目标识别,YOLO 网络将物体检测作为回归问题求解,是一个单独的端到端的神经网络,可完成从原始图像的输入到物体位置和类别一同输出的整个过程。不同于两阶段的目标识别网络,YOLO 作为单阶段网络没有使用子网络求取目标候选框,极大地减小了网络模型的复杂程度,同时也减小网络模型在FPGA 端的部署难度。
YOLOv3-Tiny 网络的输入为分辨率为416×416,三通道的RGB 图像或灰度图像。前六个卷积层均是“卷积—池化—ReLU”级联结构,第六层的输出特征图尺寸为13×13×512,用作第七层的输入,第七层至第十层取消池化,维持尺寸为13×13的感受野,第十层也为第一个检测层,卷积结果不经激活函数直接输出。图中,“3×3×3×16”前两个值为卷积核的尺寸,第三个值为卷积核的输入通道数,最后一个值为输出通道数。“2×2-s-2”中前两个值为下采样滑动窗口的尺寸,最后一个值为滑动窗口的步长。YOLOv3-Tiny 模型如图1 所示。
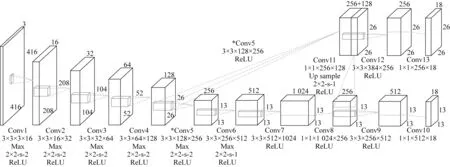
图1 YOLOv3-Tiny 模型Fig.1 Diagram of the YOLOv3-Tiny model
图1 中,上半部分为第二个检测层结构。第五层卷积层的输出不经池化得到一个尺寸为26×26×256 的特征图,与第八层输出特征图经过第十一层维度为1×1×256×128 的权重,卷积并上采样后得到的尺寸为26×26×128 的特征图在通道方向进行级联,得到一个尺寸为26×26×384 的特征图,作为第十二层的输入。第十三层作为检测层给出感受野尺寸26×26×18 的输出结果,与下方感受野尺寸为13×13×18 的检测层相比,该检测层的输出尺寸更大,具有更大的感受野。该网络的预测结果取两个检测层中置信度较高者。与传统方法对比,神经网络无需人工提取特征;与两阶段方法比,YOLO 在准确率与网络规模间达到平衡,且使用两个尺度不同的检测层,有效地解决红外小目标识别的难题。
1.2 低比特量化
本文使用通道级低比特量化替代层级量化,具体范围如图2所示。

图2 通道级量化与层级量化Fig.2 Channel-level quantization and layer-level quantization
将卷积层中的参数逐通道提取最大最小值,并使用最大最小值量化方法将各通道参数从32 位浮点型量化为8 bit 或2 bit 整型,实现卷积层参数存储空间的压缩和卷积运算方式的优化。相比于层级量化,通道级量化能够适应同一卷积层中各个通道的不同参数范围。在卷积层当中,各个通道独自对输入特征值进行卷积,形成输出中的一层,因此,卷积层中通道内差异小于通道间差异。对卷积层进行通道级量化,能够使量化区间更好地适应卷积层中的参数分布,达到减小量化损失的目的。
图2 中,WL、WH为当前通道卷积核权重范围的最小值和最大值。通道级量化方法在每次更新后统计每一层内各通道权重的最大、最小值,并将该通道权重参数量化为预先设置的位数,实现权重从浮点型到低比特整型的转换。同时记录训练中每一层各通道特征值的最大和最小值,在测试时使用训练中记录的特征值数据进行量化。权重按如下方式进行量化与反量化:
式(1)为权重量化方式,对于第i层第j个通道的权重Wi,j,使用该通道对应的极小值和极差进行量化,将权重从32 位量化到bw位。量化后权重变为低比特整型,能够便于卷积运算和压缩存储。权重需要进行全精度更新,式(2)为权重反量化方式,对于第i层第j个通道的量化参数,使用该通道对应的极小值和极差进行反 量化,将权重从bw位恢复到32 位。由于量化中存在取整过程,反量化后将不同于Wi,j,因而会造成量化损失。特征值按如下方式进行量化:
式(3)为特征值量化方式,对于第i层第j个通道的特征值Ai,j,使用该通道对应的极小值和极 差进行量化,将特征值从32 位量化到bA位。量化后特征值变为低比特整 型。同样地,由于量化中存在取整过程,反量化后参数将不同于Ai,j,因而会造成量化损失。由于卷积生成中间值的量化区间不同于偏置的量化区间,模型在卷积后需要将中间值进行反量化,便于后续的偏置相加。中间值按如下方式进行反量化:
式(4)为中间值反量化方式,中间值;使用其对应的极小值和极差计算得到进行反量化,将参数恢复到32 位。的计算依赖于的分布情况,为了使中间值恢复更加简便,视情况将量化后参数的均值差校准到0。
通道级量化算法如下:算法输入为第i层输入特征值Ai,第i层第j个通道权重Wi,j,第i层偏置Bi,量化位数bA、bW;算法输出为输出特征值Aout。
算法 1通道级量化算法。
2 FPGA 神经网络加速器实现
传统卷积神经网络中的计算部分通常集中在卷积层和全连接层,其中卷积层属于计算密集型,权重参数相对少,但可复用程度高,获取一次权重可以参与多次运算;全连接层属于存储密集型,每个权重参数只参与一次乘加运算,权重不存在可复用性[11-14]。在嵌入式FPGA 上进行全连接层的实现,需要不断取出需要的权重,相比卷积层会导致更为频繁的片下内存访问,增加网络运行的能耗。考虑到FPGA 加速器设计难度和最终的硬件实现效能。在硬件设备上进行卷积层的加速,主要是使用循环重排、展开和分块等方法,合理利用有限的硬件资源实现可能的最大加速效果。本文提出的FPGA 设计使用一个计算核心来满足不同配置下卷积层的计算,因此适用于类似YOLO 这类无全连接层的卷积神经网络。
FPGA 设计层面,可以通过调整硬件系数,即循环分块系数来拓展至其他型号的FPGA 上[15-16],卷积循环优化如图3 所示。

图3 卷积循环优化Fig.3 Schematic diagram of convolutional loop optimization
为了提高FPGA 加速器的计算性能,多数设计采用全流水线架构,即对一个网络中所有卷积层分别进行优化设计,每个卷积层各自使用其计算单元与存储单元,从而实现高并行度、高吞吐率[17-20]。然而此类加速器实现所使用的FPGA 均具有大量的硬件资源且价格昂贵,能耗较高,无法满足嵌入式使用场景的低功耗要求[21],整体架构如图4所示。
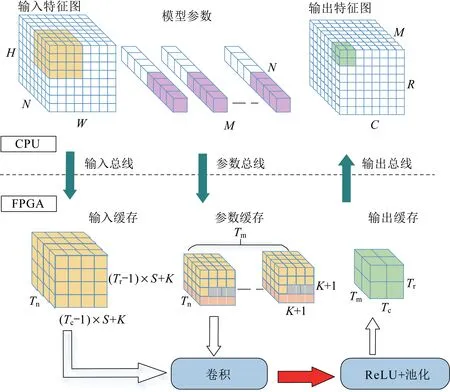
图4 整体架构Fig.4 Overall architecture
本文实现的卷积神经网络加速器是一个嵌入式ARM 核CPU 与FPGA 协同工作的硬件系统,该系统的卷积循环优化如图3 所示,整体架构如图4 所示。其中,R、C、M分别为输出特征图的高度、宽度和通道数,Tr、Tc、Tm分别为R、C、M的分块系数,K为该层的卷积核尺寸,N为输入特征图的通道数,Tn为其对应的分块系数。输入数据及网络模型参数从CPU 端传输至FPGA 计算后得到网络模型的推理结果,最后CPU 端对该结果进行读取。由于网络模型参数与网络模型推理过程中产生的特征图无法全部存储至嵌入式FPGA 的片上存储器,需要将每层的输出特征图存回CPU 端的DDR 存储器中,执行下一层计算时,需要将该输出特征图重新读取至片上进行处理,无法做到网络模型中层与层之间的流水线处理。本文选用YOLOv3-Tiny,一个轻量级神经网络作为FPGA加速器部署目标,并完成低比特量化,为了充分利用硬件资源,使用同一个卷积计算单元,执行网络不同层所需的计算任务。卷积计算单元的内部是一个高度并行的计算核心,用于完成神经网络中核心的乘加运算。整体架构可用于计算不同参数配置下的卷积层和池化层。
3 实验结果
3.1 低比特量化结果
本文使用平均精度均值(Mean Average Precision,mAP)作为最终评分标准。mAP 的计算主要由精确率、召回率和交并比(Intersection over Union,IoU)阈值构成。精确率是算法检测正确的物体/检测框的总个数;召回率是算法检测正确的物体/图像中的总物体;交并比即模型预测的检测框与真实框的交集与并集之比;平均精度(Average Precision,AP)是综合了交并比、精确率与召回率三个指标的评价标准。TP 代表一个正确的定位结果,即预测框和真值框之间的交并比大于规定的阈值。FP 表示一个错误的结果。FN 表示此处有一个物体,但检测系统将其判断为背景。TN 表示检测系统成功地将背景判断为背景。精确率为TP/(TP+FP),召回率为TP/(TP+FN),本文采用0.5的交并比阈值。在AMCOM 红外装甲车目标检测数据集中验证了移植后目标检测模型的实际效果。目标检测数据集可视化检测结果如图5 和图6所示。

图5 红外装甲车目标检测数据集可视化检测结果Fig.5 Visual detection results of the detection dataset for infrared armor vehicle objects

图6 红外飞行器目标检测数据集可视化检测结果Fig.6 Visual detection results of the detection dataset for infrared flight vehicle objects
本节使用在VOC 数据集上进行预训练的模型,并在AMCOM 红外装甲车目标检测数据集上进行微调。本节中以0.001、0.000 1、0.000 01 的学习率依次各训练了2 000 个批次,最终得到了0.939 的平均精度,可以看出移植后的目标检测模型依然有着极强的检测能力。
步骤1~3 依次添加了:1)权重的通道级量化;2)分步骤重训练方案;3)特征值的通道级量化。基础模型为权重、特征值层级量化、常规训练方案。红外飞行器目标检测数据集测试结果见表1。

表1 红外飞行器目标检测数据集测试结果Tab.1 Test results of the detection dataset for infrared flight vehicle objects
3.2 FPGA 性能分析
本文使用Xilinx 的Vivado 工具套件进行硬件系统的开发与测试,FPGA 实现平台选型为撼讯科技的PYNQ-Z2 FPGA Development Kit。该平台使用的FPGA 芯片为ZYNQ XC7Z020-1CLG400C,该SoC 芯片同时还集成了一颗双核Cortex-A9 嵌入式CPU。嵌入式CPU 负责产生对FPGA 的控制信号以及DDR 存储器的管理,网络模型的参数及推理阶段产生的中间特征图全部存储在片下DDR 内存中。
本文对提出的设计进行测试及验证基于Xilinx的Zynq-7000 SoC,该SoC 使用不同种类、不同速率的接口和一些互联路由结构,将嵌入式ARM 核以及传统外设控制器(Processing System,PS)与FPGA 可编程逻辑(Programmable Logic,PL)相连。
基于该架构,开发者可以使用FPGA 大量的逻辑门资源,设计出高速并行的加速逻辑,部署在PL端;PS 端则负责初始化具体的任务逻辑,将繁杂的计算任务交给PL 端,PS 端进行任务调度与控制。PS 端与PL 端进行交互的接口主要分为三类。
1)EMIO(Extendable Multiuse I/O):用于将某些接口连接至PL 端的外设,这些外设控制器位于PS 端,通过EMIO 进行连接。
2)GP(General Purpose)端口:使用AXI4 Lite协议,多用作低速传输,常用于控制总线,负责读取、写入状态与数据寄存器等。
3)HP(High Performance,HP)端口:使用AXI4 协议,多用作高速传输,常用于数据总线,负责PL 端的片上缓存与DDR 存储器的数据交互。
加速器设计的硬件部分完全使用Xilinx HLS高层次设计工具进行实现,并将其封装为一个IP,软件调用部分使用的平台是ARM 嵌入式CPU 上的Linux 系统。Xilinx 在这款SoC 的Linux 驱动内核上,添加了Python 对底层外设的映射和相关硬件控制,用户可以访问SoC 的Linux 内核,编写Python脚本,实现PS 端的控制。为了给FPGA 即PL 端传输数据,需要在PS 端将数据以合适的格式进行打包,并存储在DDR 存储器中。在本文中,FPGA 片上缓存与DDR 存储的数据交换的控制者为PL 端,PS 端只负责将相关的数据地址及需要读取的数据的长度告知PL 端,PL 端通过直接内存访问(Direct Memory Access,DMA)片下的DDR 存储,并读写相关数据。PS 端在DDR 存储器中,开辟虚拟地址与实际地址一致连续的内存空间。这样一来无需PS 端的控制,PL 端即可访问DDR 中正确的存储位置。
本文所使用的 FPGA PYNQ-Z2(ZYNQ XC7Z020-1CLG400C)含 有280 个BRAM、220 个DSP48E、106 400 个FF 硬件资源和53 200 个LUT资源,开发板提供最高25.6 Gbit/s 的传输带宽。
在硬件资源和带宽的限制下,选择分块系数(Tm=8、Tn=4、Tr=32、Tc=38)作为最终的加速器主要设计参数。卷积神经网络加速器设计在该FPGA 板上的资源使用情况见表2。

表2 FPGA 综合后硬件资源消耗情况Tab.2 Hardware resource consumption after FPGA synthesis
在表2 中,BRAM(Block RAM)代表FPGA 中专用的RAM 块资源,DSP(Digital Signal Process)代表FPGA 中的数字信号处理单元,FF(Flip Flop)代表触发器,LUT(Look-Up Table)代表查找表。从表中可以看出,DSP 和LUT 的资源利用率均在90%以上,这两种资源多用于计算单元的组成,其利用率越高,说明卷积计算的并行度越高,系统能够达到的峰值计算性能也就越高。
由于网络中每一层需要等待前一层完成计算才可以运行,YOLOv3-Tiny 中每个卷积层所需计算量和达到的计算性能可以独立评估。第12 个卷积层达到90.6 GOP/s 的峰值性能,平均性能为65.6 GOP/s。低比特量化大大减少了数据交换带来的带宽消耗,最终系统的功耗为2.5 W。
4 结束语
本文提出了低比特量化的YOLOv3-Tiny 算法,在对不同数量、不同大小的复杂场景下的红外目标识别任务上,当权重量化至2 bit 时仍保持高识别率,并在PYNQ-Z2 嵌入式FPGA 开发板上进行加速器实现。在低比特量化条件下取得优异的压缩效果,原理上在无须改变量化算法与FPGA 加速器架构的前提下,即可拓展至各类针对目标识别任务及多分类任务的卷积神经网络上。得益于低比特量化,提出的神经网络加速器所需带宽大幅降低,即使增大并行度,每个时钟周期数据交换的次数增加,仍能保证系统在150 MHz 的工作频率下运行;同时采用行缓存和窗口缓存实现滑动窗口处理方式,大幅提高卷积计算并行度,达到了90.1 GOP/s 的峰值性能。与其他相关工作对比,本文提出的FPGA 加速器具有优异的能效表现,为嵌入式红外目标识别系统提供一种能效高、识别精度高的解决方案。
