基于改进Faster R-CNN的手部位姿估计方法
2023-03-15郑涵田猛赵延峰王先培
郑涵,田猛,赵延峰,王先培
(武汉大学电子信息学院,武汉 430072)
手作为人体上重要部分之一,是人类与外界传递信息的重要方式。手部位姿估计作为人机交互技术的热点项目之一,广泛应用于虚拟现实(virtual reality,VR)和增强现实(augmented reality,AR)等应用中。手部检测和手部位姿估计助力于体感游戏的发展和实现,精确的手部位姿估计算法可以提高用户游戏体验,并为后续更为高深的技术提供基础支持。手部位姿估计在3D建模领域也有广泛的应用,现在已经有一些工作能实时建模出手部模型。但是由于存在手关节自由度高,检测目标小,以及手部的自遮挡等问题,已有手部位姿估计算法存在精度低鲁棒性较差等问题。
当前常用的手势姿态估计方法主要分为3类[1-2]。第一类是生成方法,该方法计算量大,鲁棒性差。Boukhayma等[3]采用编码器来生成手模型的形状,姿势和视角参数,以获得手的3D网格参数及其底层 3D 骨架。第二类是判别方法,该方法需要大量的数据支持,随着深度学习的发展,该方法逐渐被推广使用[4]。刘家祥[5]采用深度学习从3个方面研究三维手势估计方法。Kulon等[6]使用循环结构的网格卷积解码器来恢复 3D 手网格和手部姿态。第三类是混合式方法,该方法结合了两种方法的优点[7-8],既不需要建立复杂的手部模型,也不依赖于模型初始化,手部模型的约束可以减少不合理的预测动作,减小计算量,提高检测的鲁棒性。Liu 等[9]利用对武术三维手势特征进行提取和分类;然后,利用手部形态拓扑结构模拟手部关节的依赖性,得到手部关节的三维坐标。最后,利用姿态回归模块实现武术手势动作的姿态估计。
手部检测是完成手部位姿估计算法重要的一步。手部检测算法可以分为传统的检测识别方法和基于深度学习方法。传统的手部检测方法主要依赖于颜色特征[10-11],或其他先验知识提取的目标特征,受环境影响大,鲁棒性差。唐文权等[12]基于肤色进行人手检测,先对基于光补偿的肤色模型估算和纠正,再进行非线性转换得到椭圆肤色模型,再进行一系列操作连接人手候选区域。基于深度学习的方法具有识别速度快,识别精度高的优点。其中具有代表性的是基于候选区域的卷积神经网络,Faster R-CNN对目标检测的速度做了很大的提升,很多研究者将该算法应用于手部检测。马鹏程[13]在Faster R-CNN的基础上使用特征金字塔(feature pyramid networks,FRN)代替区域生成网络(region proposal network,RPN),并且在ROI Pooling层加入注意力机制,提高了检测精度和速度。张勋等[14]采用Faster R-CNN网络对建议框做目标检测和分类实现手势端到端的识别。刘壮等[15]在原有的Faster R-CNN检测框架的基础上,增加了Depth通道,并在特征层面上将其余RGB通道信息进行融合,实现手部检测。但是Faster R-CNN网络在小目标检测等方面还存在缺陷。
以基于改进的Faster R-CNN的手部位姿估计算法为研究背景,通过对目前存在的难点分析,将手部位姿估计分为手部检测和手部关键点检测。首先提出一种改进的 Faster R-CNN 网络用于手部检测。将深度相机采集的原始深度图进行预处理,与 RGB 图图像通道保持统一尺度[16],从而初步过滤掉背景信息,然后提出深度特征提取网络,来替换 Faster R-CNN 的特征提取模块,使算法能够适应多通道多尺度的图像数据,最后在网络的头网络中增加 handside分支来区分左手和右手,进而获得精度更高的手部检测结果,解决手部在图像中检测目标较小的问题。
在改进 Faster R-CNN 网络基础上增加了头网络分支用以训练输出 MANO (hand model with articulated and non-rigid deformations)手部模型的姿态参数和形状参数,并根据手部特征重新设计了两个损失函数用来约束 MANO 参数的训练。MANO 手部模型是一种参数化的手部网格模型,通过网络回归得到的姿态参数和形状参数能控制MANO 生成手部模型,进而得到手部的关键点三维坐标,从而有效解决手部自遮挡等问题。
1 基于改进Faster R-CNN的手部检测算法
1.1 改进的Faster R-CNN网络模型
如图1所示,改进后的手部检测算法包括特征提取模块、RPN、特征图的分类预测、包围框预测,与基于Faster R-CNN的目标检测算法类似。现改进特征提取网络,提出深度特征融合网络来将RGB图像的语义特征与深度图像的位置特征进行融合,解决手部检测中存在的遮挡问题和尺度问题。并将Faster R-CNN算法中的ROI最大值池化更改为ROI Align,提高了算法的运行速度及小目标检测的准确性。

图1 手部检测算法基本网络框图Fig.1 Basic network block diagram of hand detection algorithm
1.2 图像预处理
深度相机直接获得的深度图不可避免地包含噪声甚至异常值,如果直接用来训练网络,可能会导致预测结果偏差。因此,在训练之前需要对深度图进行去噪和归一化处理。本文中使用双边滤波进行深度图降噪,使用最大最小标准化对深度图进行归一化处理,与 RGB 图图像通道保持统一尺度,从而初步过滤掉背景信息。
1.3 特征提取网络
Faster R-CNN在进行特征提取时,选择了 VGG16 网络的最后一层输出来做提取出的特征图。在卷积的过程中,小目标的语义特征大概率作为背景而被抛弃。导致了Faster R-CNN难以提取小目标。
FPN可以信息融合将低层特征图的位置信息与高层特征图的语义信息进行融合。基于此思想,将含有丰富的位姿信息的深度图特征和含有丰富语义信息的 RGB图特征进行数据层融合,提出了一种新的特征融合网络来联合提取 RGB-D 图像特征。深度特征融合网络如图2所示。

图2 深度特征融合网络Fig.2 Deep feature fusion network
1.4 ROI Align
将传统Faster R-CNN网络中的对ROI的最大值池化,更改为 ROI Align,即通过双线性插值的方法来使特征图像素级对齐。文献[17]证明,这种做法不仅可以提高整体运算速度,还可以提高对小目标的检测准确性。
1.5 损失函数设计
原始的 Faster R-CNN 的损失函数包括两个部分,即分类损失函数Lcls和回归损失函数Lreg。
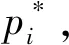
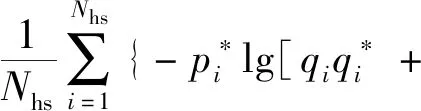
(1)

综上,本文提出的改进Faster R-CNN算法的总损失函数为
Ltotal=Lcls+Lreg+Lhs
(2)
2 基于MANO手部模型的手部关键点提取
2.1 手部关键点提取算法网络框架
图3所示为一个由MANO[18]模型生成的手部网格。根据MANO的手部模型,可以很容易地根据稀疏权重关系获得除了5个手指指尖以外的16个控制手部整体运动的骨骼关节点。MANO也根据左右手镜像的先验知识,从右手的模型中生成了左手模型,保证了左右手模型的一致性。MANO手部模型一共有778个参数,为了简化计算难度,降低计算复杂度,引入形状参数β和姿势参数θ来控制手部模型的位姿。由此可以得到MANO手部模型的计算公式为
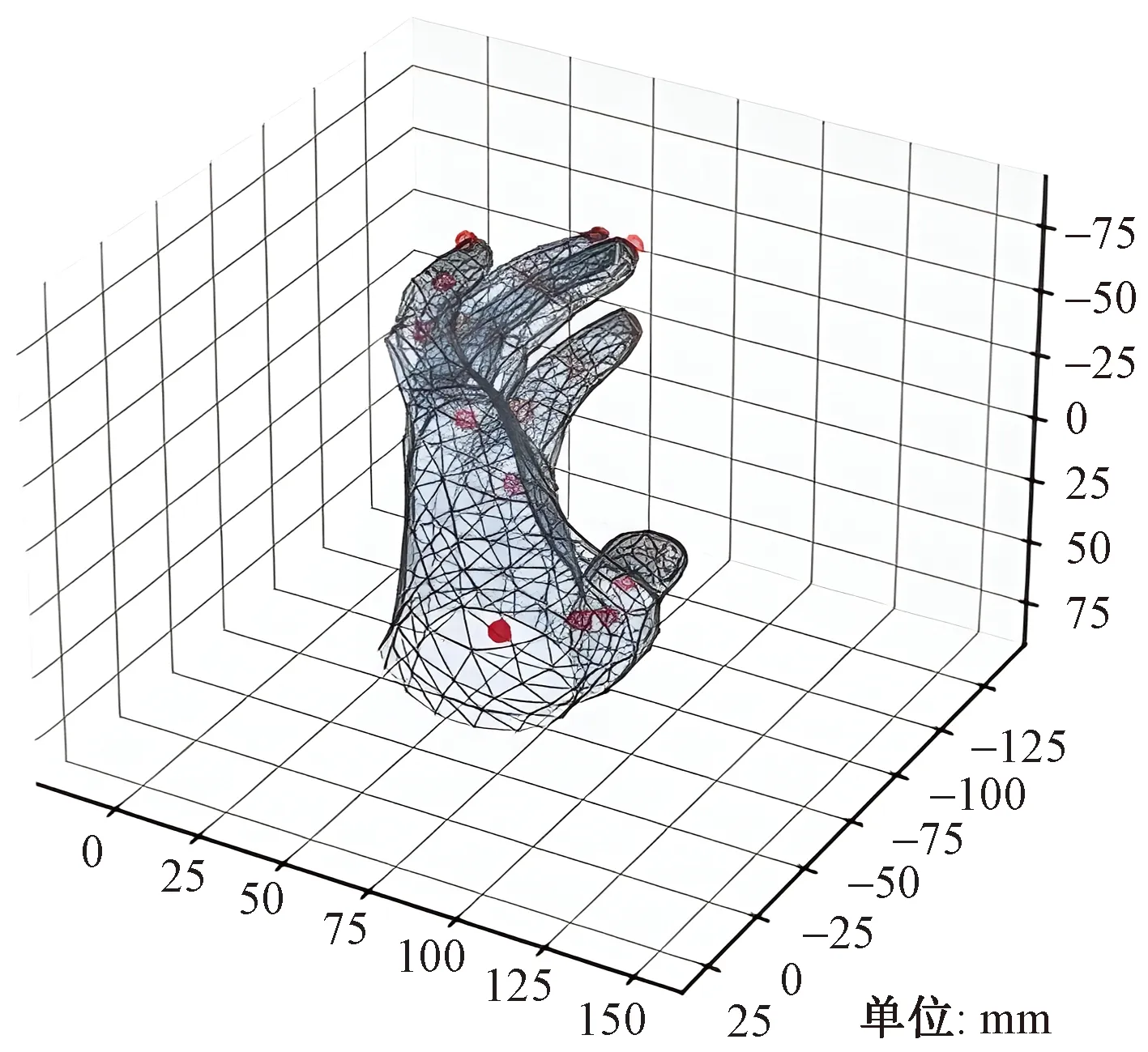
图3 MANO手部模型Fig.3 MANO the model of hand
(3)
M(β,θ)=f[T(β,θ),θ,W,J(θ)]
(4)
J(θ)=F[T+Bs(β)]
(5)
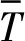
由式(3)~式(5)可以看出,只需要给定形状参数β和姿势参数θ,就可以从标准手部模型中生成对应形状与姿态的手部模型。
由此设计出一个基本的网络框架,如图4所示。

图4 基于MANO的手部位姿估计基准网络框架Fig.4 A benchmark network framework for hand pose estimation based on MANO
将手部检测后分割出的手部图片直接输入到手部位姿估计网络框架中得出手部关键点信息。但是使用两个不同的深度学习网络,不仅导致训练时复杂,预测的结果难以控制,也会进行过多不必要的计算(例如进行了两次特征提取),使运行速度过慢。
针对上述问题,借鉴多任务网络思想,将手部位姿估计基本网络框架加入到本文改进的 Faster R-CNN中,改进后的网框架如图5所示。
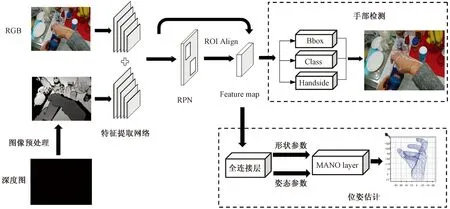
图5 多任务手部位姿估计网络基本框图Fig.5 Basic block diagram of multi-task hand pose estimation network
2.2 损失函数设计
MANO手部模型为了训练自己定义了两个损失函数,分别为形状损失Lβ和姿态损失Lθ[17]。
然而本文选用的数据库,大部分真值标注都不包含姿态参数θ和形状参数β,因此 MANO 模型并不适用目前大部分的主流的手部位姿估计数据库。但是如果不对形状参数进行约束,MANO 网络模型可能会出现过粗或者过细的手部模型,从而影响从手部模型中提取的骨骼关节点结果。如果不对姿态参数进行约束,MANO 网络模型可能会出现异常姿态的手部模型。
为了约束形状参数,假定所有数据库中手部的形状都是标准大小,即人为设定数据库中所有的形状参数的真值β*=0。将Lβ重新定义为
(6)
根据先验知识,手部的姿态是由包括手指指尖在内的21个骨骼关键点来共同控制,因此通过获得MANO手部模型中21个骨骼关键点的空间位置信息就可以达到约束 MANO手部模型的姿态参数θ。选择了MANO模型上包括指尖在内的21个骨骼关节点三维位置与对应真值差值来计算姿态损失函数,计算公式为
(7)
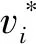
综上,本文提出的手部位姿估计算法的总损失函数为
Ltotal=λclsLcls+λregLreg+λhsLhs+λβL′β+λcoiLcoi
(8)
式(8)中:λcls、λreg、λhs、λβ、λcoi分别为对应损失函数的平衡权重。本文训练时,取值λcls=λreg=λhs=λβ=λcoi=1。
3 实验
3.1 实验环境与参数设置
所有的训练和验证都在NVIDIA Quadro RTX 6000显卡上运行,操作系统为Ubuntu18.04,CUDA 版本为10.2以及cudnn版本为7.5,初始学习率为 0.02,每回合下降4%。
3.2 三维手部位姿估计数据库选取及评价标准
本文主要研究集中在 NYU[19]、ICVL[20]、MSRA[21]、first-person hand action benchmark[22](F-PHAB)4个数据库。其中前3个主要是裸手的数据库,最后一个是手物交互的数据库。
在目前的三维手部位姿估计算法中,研究学者一般采用手部共21个骨骼关节点作为位姿估计的关键点。与之对应的,采用关键点坐标的均方误差值(key-point mean square error,KMSE)来评估算法的有效性。
关键点误差 KMSE 可以定义为图像上预测关键点坐标与对应真值坐标之间的欧式距离,公式为
(9)
(10)
式中:KMSE为所有关键点的总误差;I为关键点总数量;KMSE,i为第i个关键点的均方误差值;n为测试视频的总共帧数;(xij,yij,zij)为第j帧图像的第i个关键点的估计坐标值;(Xij,Yij,Zij)为第j帧图像的第i个关键点坐标值的真值。
3.3 实验结果展示与分析
3.3.1 手部检测算法
为了验证改进 Faster R-CNN 的方法的有效性,选择F-PHAB 数据库,并将原始的 Faster R-CNN 方法与本文改进的方法进行了对比。由于数据库中并没有手部的真值框,因此将骨骼关节点的三维坐标映射到二维图像上的最大包围框定义为真值框。为了扩充数据库,根据左右手镜像关系,将训练集数据进行镜像翻转处理。从不同场景中随机选择了40 000 张作为训练集,选择 10 000 张作为测试集,进行了对比试验。由于手部检测任务实际上有3类目标:左手、右手和背景,因此选择了准确率来作为评价标准。
从表1可以看出,将深度图像作为 RGB 图像中的图像通道可以一定程度上提高遮挡情况下的手部检测结果,但是实际效果并不理想,而本文的方法在识别准确率上要全面优于Faster R-CNN。图6中,绿框代表预测为左手区域,红框代表预测为右手区域。场景一和场景二均为测试集数据,场景一中左手大部分区域都被物体遮挡,从图6中可以看出,无论输入数据是 RGB 图像还是RGB-D 数据,Faster R-CNN 只能检测到部分左手信息,而本文方法可以检测到几乎完整的左手信息。场景二中左手并没有完全在图内,Faster R-CNN 并不能检测到左手,而本文方法能有效的检测到左手。场景三取材于日常生活中,手部位置距离相机很近,Faster R-CNN 由于没有多尺度的特征提取网络,虽然检测到了手,但是无法精确定位。使用本文方法,手部信息大部分都在框内,只有大拇指中极少的部分在框外。在3种场景下,本文方法均有较好的识别结果。从定性和定量的角度来看,本文提出的改进方法相较于Faster R-CNN算法具有更好地检测结果。

表1 本文方法与Faster R-CNN的评价指标对比Table 1 Comparison of evaluation indicators between this paper and Faster R-CNN

图6 不同场景下手部检测结果Fig.6 Hand detection results in different scenarios
3.3.2 手部关键点提取
为了评估本章方法的有效性,将在3个常用数据库 ICVL、NYU、MSRA 上分别计算关键点平均误差 KMSE,并将结果与目前主流的算法进行比较。由表2所示,本文提出的算法在 NYU 和 ICVL 均与最优的方法相当,其中 ICVL 数据库由于遮挡较少,识别相对简单,因而达到了当前最优效果。相对而言,在 MSRA 数据集的误差与最优方法误差相差 0.3 mm,这与该数据库场景复杂,包含人员较多和自遮挡问题较严重有一定关系。综上所示,本文算法能够一定程度上解决手部位姿估计存在的高自由度、手部目标过小、手部自遮挡问题和尺度问题,较为准确地估计出图像中的手部位姿。手部位姿估计的可视化结果如图7所示。即使手部有部分被物体遮挡,依旧可以绘制出手部关键点信息。综上所述,本文算法能较好地解决手部遮挡问题,实现手部的位姿估计。

图7 手部位姿估计可视化结果Fig.7 The visualization results of hand pose estimation
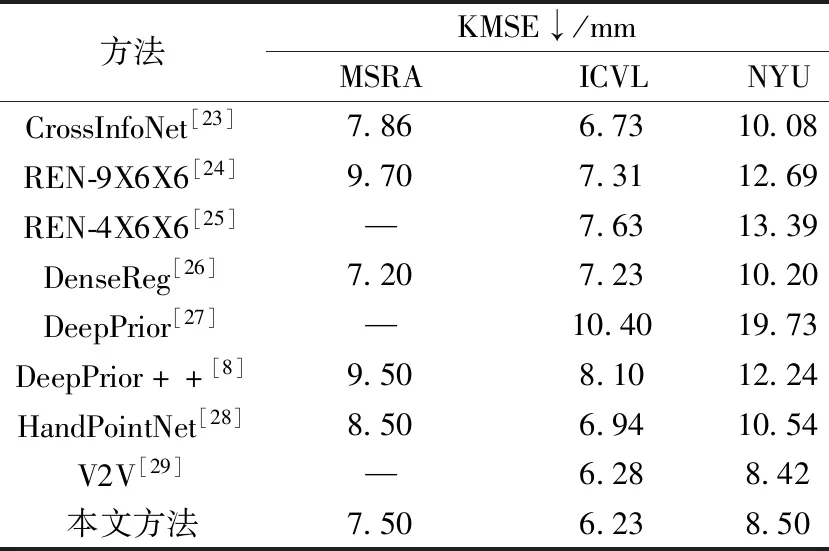
表2 本文算法与主流算法在不同数据集上的比较Table 2 Comparison of the algorithm in this paper and the mainstream algorithm on different data sets
4 结论
本文设计并实现了基于改进Faster R-CNN网络的手部位姿估计算法。提出了改进的Faster R-CNN网络进行手部检测,并在此基础上提出了基于MANO手部模型的手部位姿估计。实验表明,手部检测结果中存在的自遮挡和尺度问题得到了解决,并且检测结果的准确性有所提高。通过与主流算法的对比可以证明,本文算法能够较为准确地得到手部位姿估计的结果。在未来的工作中,将进一步对手部姿态估计中手部动作的意义进行理解。
